集成算法——Ensemble learning
目的:让机器学习效果更好,单个不行,群殴啊!
Bagging:训练多个分类器取平均
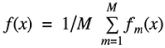
Boosting:从弱学习器开始加强,通过加权来进行训练

(加入一棵树,比原来要强)
Stacking:聚合多个分类或回归模型(可以分阶段来做)
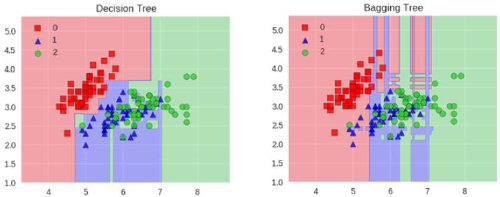
bagging模型
全称:bootstrap aggregation(说白了就是并行训练一堆分类器)
最典型代表:随机森林
随机:数据采样随机,特征选择随机
森林:很多个决策树并行放在一起
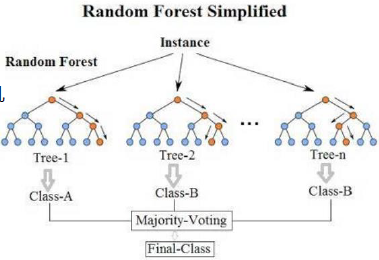
构造树模型
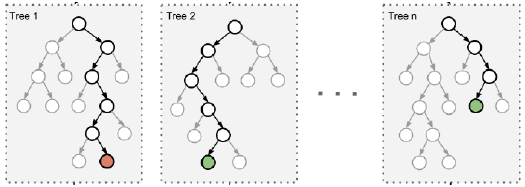
由于二重随机性,使得每个树基本上都不会一样,最终的结果也会不一样。
树模型:
之所以要进行随机,是要保证泛化能力,如果树都一样,就没有意义了。
随机森林优势
能够处理很高维度(feature很多)的数据,并且不用做特征选择
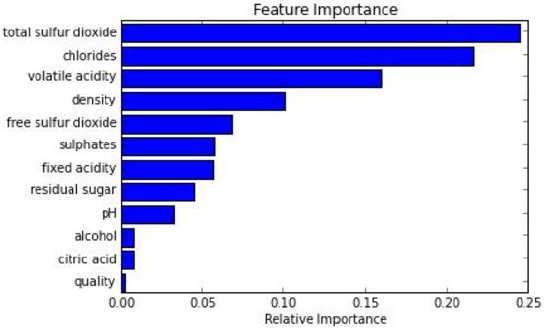
在训练完后,它能够给出哪些feature比较重要
容易做成并行化方法,速度比较快
可以进行可视化展示,便于分析
KNN模型
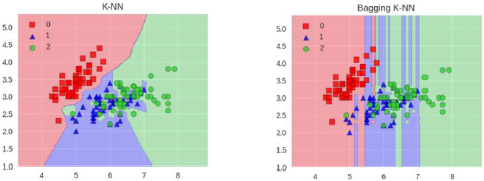
KNN就不太适合,因为很难去随机让泛化能力变强!
树模型
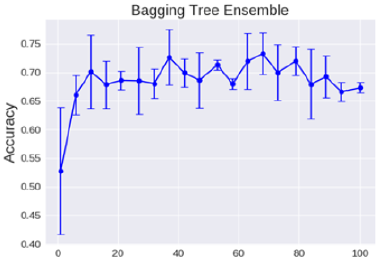
理论上越多的树效果会越好,但实际上基本超过一定数量就差不多上下浮动了。
Boosting模型
典型代表:AdaBoost,Xgboost
Adaboost会根据前一次的分类效果调整数据权重
如果某一个数据在这次分错了,那么在下一次就会给它更大的权重
最终结果:每个分类器根据自身的准确性来确定各自的权重,再合体
Adaboost工作流程
每一次切一刀
最终合在一起
弱分类器就升级了
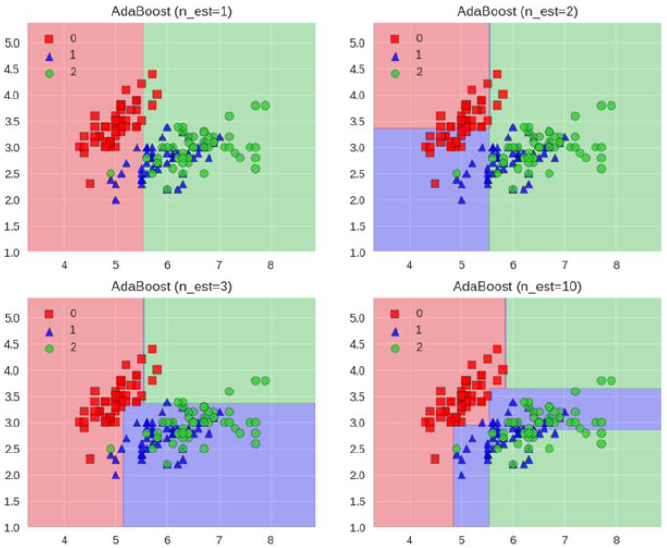
Stacking模型
堆叠:很暴力,拿来一堆直接上(各种分类器都来了)
可以堆叠各种各样的分类器(KNN,SVM,RF等等)
分阶段:第一阶段得出各自结果,第二阶段再用前一阶段结果训练
为了刷结果,不择手段!
堆叠在一起确实能使得准确率提升,但是速度是个问题
集成算法是竞赛与论文神器,当我们更关注与结果时不妨试试!
集成算法——Ensemble learning的更多相关文章
- 【Supervised Learning】 集成学习Ensemble Learning & Boosting 算法(python实现)
零. Introduction 1.learn over a subset of data choose the subset uniformally randomly (均匀随机地选择子集) app ...
- 笔记︱集成学习Ensemble Learning与树模型、Bagging 和 Boosting
本杂记摘录自文章<开发 | 为什么说集成学习模型是金融风控新的杀手锏?> 基本内容与分类见上述思维导图. . . 一.机器学习元算法 随机森林:决策树+bagging=随机森林 梯度提升树 ...
- 【软件分析与挖掘】Multiple kernel ensemble learning for software defect prediction
摘要: 利用软件中的历史缺陷数据来建立分类器,进行软件缺陷的检测. 多核学习(Multiple kernel learning):把历史缺陷数据映射到高维特征空间,使得数据能够更好地表达: 集成学习( ...
- 6. 集成学习(Ensemble Learning)算法比较
1. 集成学习(Ensemble Learning)原理 2. 集成学习(Ensemble Learning)Bagging 3. 集成学习(Ensemble Learning)随机森林(Random ...
- 第七章——集成学习和随机森林(Ensemble Learning and Random Forests)
俗话说,三个臭皮匠顶个诸葛亮.类似的,如果集成一系列分类器的预测结果,也将会得到由于单个预测期的预测结果.一组预测期称为一个集合(ensemble),因此这一技术被称为集成学习(Ensemble Le ...
- 7. 集成学习(Ensemble Learning)Stacking
1. 集成学习(Ensemble Learning)原理 2. 集成学习(Ensemble Learning)Bagging 3. 集成学习(Ensemble Learning)随机森林(Random ...
- 5. 集成学习(Ensemble Learning)GBDT
1. 集成学习(Ensemble Learning)原理 2. 集成学习(Ensemble Learning)Bagging 3. 集成学习(Ensemble Learning)随机森林(Random ...
- 3. 集成学习(Ensemble Learning)随机森林(Random Forest)
1. 集成学习(Ensemble Learning)原理 2. 集成学习(Ensemble Learning)Bagging 3. 集成学习(Ensemble Learning)随机森林(Random ...
- 4. 集成学习(Ensemble Learning)Adaboost
1. 集成学习(Ensemble Learning)原理 2. 集成学习(Ensemble Learning)Bagging 3. 集成学习(Ensemble Learning)随机森林(Random ...
随机推荐
- ClassOne__HomeWork
1,static类型 static类型定义有两类,一类是静态数据,另一类是静态函数. 静态数据跟成员变量不同,它可以通过类名直接访问,而不需要通过定义对象来访问.它的的生成也和成员变量不一样,它只生成 ...
- Linux基础命令---文本显示od
od 将指定文件的内容以八进制.十进制.十六进制等编码方式显示.此命令的适用范围:RedHat.RHEL.Ubuntu.CentOS.SUSE.openSUSE.Fedora. 1.语法 ...
- Django框架----用户认证auth模块
一.auth模块 auth模块:针对auth_user表 创建超级管理用户命令: Python manage.py createsuperuser添加用户名添加密码(至少8位)确认密码添加邮箱(可为空 ...
- Javaweb笔记—03(BS及分页的业务流程)
DAO部分:中间层声明该有的变量 pagerBook pageData sumRow sumPage求出总的记录数id唯一标识:select count(id) as rowsum from book ...
- FileReader 获取图片base64数据流 并 生成图片
<?php if(isset($_GET['upload']) && $_GET['upload'] == 'img'){ if(isset($_GET['stream_type ...
- php实现共享内存进程通信函数之_shm
前面介绍了php实现共享内存的一个函数shmop,也应用到了项目中,不过shmop有局限性,那就是只支持字符串类型的:sem经过我的测试,是混合型,支持数组类型,可以直接存储,直接获取,少了多余的步骤 ...
- Java类型信息
一.引言 最近在阅读<Java编程思想>,学习一下java类型信息,现在做一下总结.Java如何让我们在运行时识别对象和类的信息的.主要有两种方式:一种是传统的“RTTI”,它假定我们在编 ...
- py4CV例子2.5车牌识别和svm算法重构
1.什easypr数据集: ) ) ] all_label_list = temp[:, ] n_sample = , ) matcher = cv2.FlannBasedMatcher(flann ...
- 动态规划之132 Palindrome Partitioning II
题目链接:https://leetcode-cn.com/problems/palindrome-partitioning-ii/description/ 参考链接:https://blog.csdn ...
- 给自己的程序添加BugReport
转载:https://www.easyicon.net/(免费icon) 转载:https://www.codeproject.com/Articles/5260/XCrashReport-Excep ...