10.5ORM回顾(2)
2018-10-5 14:47:57
越努力越幸运!永远不要高估自己!
ORM的聚合和分组查询!!!
# #####################聚合和分组############################
#####################聚合
# 查询所有书籍的价格
from django.db.models import Sum, Count, Avg ret = models.Bool.objects.all().aggregate(price_sum=Sum("price"))
print(ret) # {'price_sum': 'Decimal('554.00')'}
# 查询所有作者的平均年龄
ret = models.Author.objects.all().aggregate(age_avg=Avg("age")) ####----------------------------------------分组
"""
单表分组 emp id name age dep
1 alex 22 保安部
2 egon 33 保安部
1 wenzhou 44 保洁部 sql
select Count(id) from emp group by dep; orm : 对象关系映射
models.emp.objects.values("dep").annotate(c=Count("id"))
# 哪个字段分组,就values谁,然候count 任意一个字段就好了 ######################################################## emp id name age dep_id
1 alex 22 1
2 egon 33 1
1 wenzhou 44 2 dep id name
1 保安部
2 保洁部 查询每一个部门的人数 sql:
select * from emp inner join dep on emp.dep_id= dep.id id name age dep_id dep.id dep.name
1 alex 22 1 1 保安部
2 egon 33 1 1 保安部
1 wenzhou 44 2 2 保洁部 select * from emp inner join dep on emp.dep_id= dep.id group by dep.id, dep.name ORM:
关键点:
1. query对象.annotate()
2. annotate进行分组统计,按照前面select的字段进行group by
3. annotate() 返回值依然是queryset对象, 增加了分组统计之后的键值对 # 先join 表 基表是dep ,然后得到emp里面拿到name数据,跨表 反向 写表名小写,,和queryset跨表查数据一样
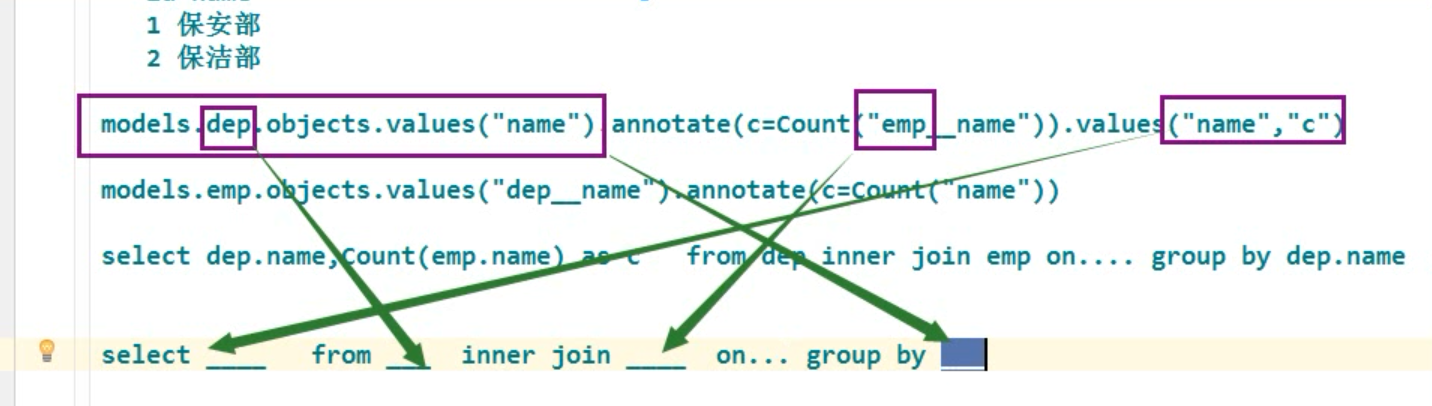
models.dep.objects.all().annotate(Count("emp__name")) models.dep.objects.values("name").annotate(c=Count("emp_name")).values("name", "c") # 反向查询 models.emp.objects.values("dep__name").annotate(c=Count("name")).values("dep_name", "c")) # 正向查询 sql
selcet dep.name, Count(emp.name) as c from dep inner join emp on .......... group by dep.name; 分组查询 先有个轮廓 select Count(emp.name) as c , dep.name from emp inner join dep on .... group by dep.name; select _____ from ____ inner join______ on ........ group by _______________ """ # 查询每一个作者的名字以及出版过的最高价格的书
from djang.db.models import Sum, Count, Max, Avg
ret = models.Author.objects.values("name").annotate(max_price=Max("book_price")).values("name",max_price) """
select Max(book.price) as max_price from author inner join book_authors on ....
inner join book on.....
group by author.name; """
# 查询每一个出版社出版过的书籍的平均价格 # 可以按字段.values("") 也可以直接 .all()
models.Publish.objects.all().annotate(avg_price=Avg("book__price")).values("name", "avg_price") # 查询每一本书籍的作者个数
modes.Book.values("title").annotate(c=Count("authors__name")).values("title","c") # 查询每一个分类的名称以及对应的文章数 models.Category.objects.all().annotate(c=Count("articles__title")).values("title", "c") # 统计不止一个作者的图书名称 """
sql:
# 先分组再统计
select book.title, Count(author.name) as c from book inner join book-authors on ....
inner join author on ....
group by book.id having c >1; """
# filter () 在这里翻译成 having 的意思,,以前的都翻译成 where
models.Book.objects.all().annotate(c=Count("authors__name")).filter(c__gt=1).values("title", "c")
10.5ORM回顾(2)的更多相关文章
- 10.4ORM回顾!
2018-10-4 17:41:52 继续优化一下我的博客项目!! 贴上orm参考连接:https://www.cnblogs.com/yuanchenqi/articles/8963244.html ...
- 数据库_11_1~10总结回顾+奇怪的NULL
校对集问题: 比较规则:_bin,_cs,_ci利用排序(order by) 另外两种登录方式: 奇怪的NULL: NULL的特殊性:
- IT168关于敏捷开发采访
1.我们知道敏捷开发是一套流程和方法的持续改进,通过快速迭代的方式交付产品,从而控制和降低成本.但是在实行敏捷初期,往往看不到很好的效果.这里面,您觉得问题主要出在哪?团队应如何去解决问题?金根:我认 ...
- 如何实现 C/C++ 与 Python 的通信?
属于混合编程的问题.较全面的介绍一下,不仅限于题主提出的问题.以下讨论中,Python指它的标准实现,即CPython(虽然不是很严格) 本文分4个部分 1. C/C++ 调用 Python (基础篇 ...
- "敏捷革命"读书笔记
最近看可一本书 书名叫<敏捷革命>外国著作中文翻译 本来想自己总结读后感但是本书后面都有本章的总结,所以下面都已摘抄为主,以备之后快速浏览 第一章 世界的运作方式已经打破 规划是有用的,而 ...
- C/C++ 与 Python 的通信
作者:Jerry Jho链接:https://www.zhihu.com/question/23003213/answer/56121859来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商 ...
- 《Redis设计与实现》
<Redis设计与实现> 基本信息 作者: 黄健宏 丛书名: 数据库技术丛书 出版社:机械工业出版社 ISBN:9787111464747 上架时间:2014-6-3 出版日期:2014 ...
- 关东升的《从零开始学Swift》3月9日已经上架
大家一直期盼的<从零开始学Swift>于3月9日已经上架,它是关东升老师历时8个月的呕心沥血所编著,全书600多页,此本书基于Swift 2.x,通过大量案例全面介绍苹果平台的应用开发.全 ...
- 关东升的《从零开始学Swift》即将出版
大家好: 苹果2015WWDC大会发布了Swift2.0,它较之前的版本Swift1.x有很大的变化,所以我即将出版<从零开始学Swift> <从零开始学Swift>将在< ...
随机推荐
- 如何让FireFox/chrome新打开的标签页在后台打开,而不是立即跳转过去
firefox: 地址栏输入about:config 找到下面三项,全部设为true browser.tabs.loadInBackground browser.tabs.loadDivertedIn ...
- autorelease' is unavailable
ARC forbids explicit message send of'release' 'release' is unavailable: not available inautomatic re ...
- [Python设计模式] 第8章 学习雷锋好榜样——工厂方法模式
github地址:https://github.com/cheesezh/python_design_patterns 简单工厂模式 v.s. 工厂方法模式 以简单计算器为例,对比一下简单工厂模式和工 ...
- 〖Android〗我的ADT Eclipse定制
1. 配置自动补全: Windows -> preferences -> 搜索assist,修改 java xml自动触发补全:.abcdefghijklmnopqrstuvwxyzABC ...
- 【tp5】ThinkCMF5框架,配置使其支持不同终端PC/WAP/Wechat能加载不同配置和视图
1.版本 5.0.18 2.在data/conf/ 新增config.php文件,内容如下: <?php //ThinkCMF5区别不同客户端加载不同配置文件和模块.视图 $default_mo ...
- 深入理解JS执行细节(写的很精辟)
来源于:http://www.cnblogs.com/onepixel/p/5090799.html javascript从定义到执行,JS引擎在实现层做了很多初始化工作,因此在学习JS引擎工作机制之 ...
- 安装Logtail(Linux系统)
Logtail客户端是日志服务提供的日志采集客户端,请参考本文档,在Linux服务器上安装Logtail客户端. 支持的系统 支持如下版本的Linux x86-64(64位)服务器: Aliyun L ...
- 安卓打印实现打印pdf文档
先声明一下,此处的打印非pos打印机打印和蓝牙打印机打印,如果想查找打印小票的pos打印机请进入下面的传送门,蓝牙打印目前没做过,有做过的请指教. pos打印机传送门: 1. https://www. ...
- Visual Studio开发工具升级注意事项
由于前几年公司开发的系统使用的开发工具版本不统一,现在后期维护升级在开发人员的电脑上要同时安装好几个不同的开发工具, 比如VS2008,VS2010,VS2012,甚至还有用VS2003开发的接口之类 ...
- Hyper-V 怎样拷贝文件至虚拟硬盘并附加到虚拟机上
对于大文件来说,通过远程桌面拷贝是件麻烦的事情,虽然简单,但速度受限太多,不推荐使用. 我工作中对于大文件的拷贝,通过创建一个新的虚拟硬盘(VHD),再把大文件拷贝至虚拟硬盘中,最后附加到虚拟机上. ...