failed to launch: nice -n 0 /home/hadoop/spark-2.3.3-bin-hadoop2.7/bin/spark-class org.apache.spark.deploy.worker.Worker --webui-port 8081 spark://namenode1:7077
spark2.3.3安装完成之后启动报错:
[hadoop@namenode1 sbin]$ ./start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /home/hadoop/spark-2.3.3-bin-hadoop2.7/logs/spark-hadoop-org.apache.spark.deploy.master.Master-1-namenode1.out
datanode2: starting org.apache.spark.deploy.worker.Worker, logging to /home/hadoop/spark-2.3.3-bin-hadoop2.7/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-datanode2.out
datanode3: starting org.apache.spark.deploy.worker.Worker, logging to /home/hadoop/spark-2.3.3-bin-hadoop2.7/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-datanode3.out
datanode1: starting org.apache.spark.deploy.worker.Worker, logging to /home/hadoop/spark-2.3.3-bin-hadoop2.7/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-datanode1.out
datanode1: failed to launch: nice -n 0 /home/hadoop/spark-2.3.3-bin-hadoop2.7/bin/spark-class org.apache.spark.deploy.worker.Worker --webui-port 8081 spark://namenode1:7077
datanode1: Spark Command: /usr/java/jdk1.8.0_111/bin/java -cp /home/hadoop/spark-2.3.3-bin-hadoop2.7/conf/:/home/hadoop/spark-2.3.3-bin-hadoop2.7/jars/* -Xmx1g org.apache.spark.deploy.worker.Worker --webui-port 8081 spark://namenode1:7077
datanode1: ========================================
datanode1: full log in /home/hadoop/spark-2.3.3-bin-hadoop2.7/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-datanode1.out
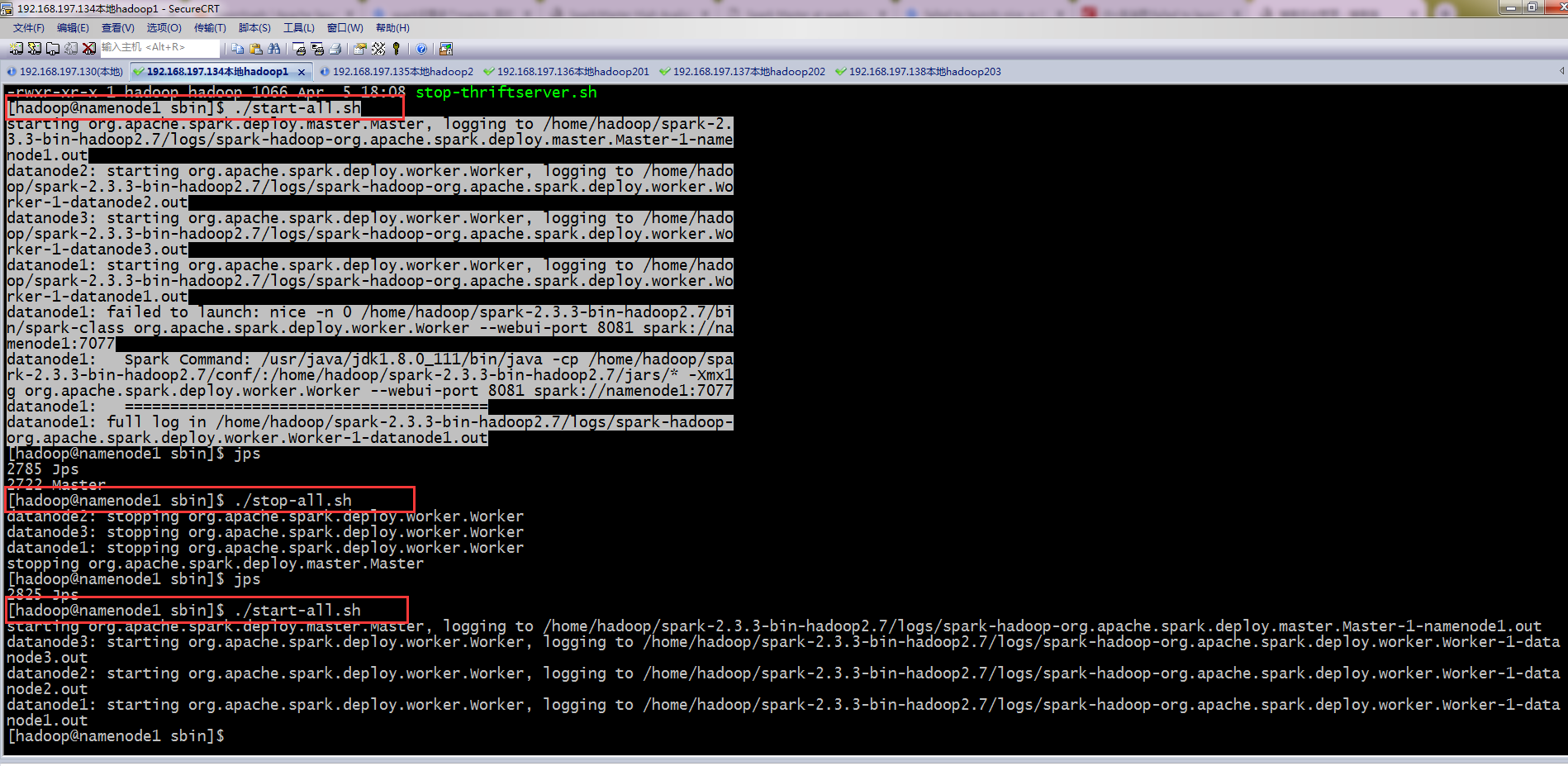
提示说完整的日志路径在哪里,用cat +路径的形式去查看,没有错误,只有警告,我选择stop-all然后重启,通常第二遍启动正常。
failed to launch: nice -n 0 /home/hadoop/spark-2.3.3-bin-hadoop2.7/bin/spark-class org.apache.spark.deploy.worker.Worker --webui-port 8081 spark://namenode1:7077的更多相关文章
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(四)针对hadoop2.9.0启动执行start-all.sh出现异常:failed to launch: nice -n 0 /bin/spark-class org.apache.spark.deploy.worker.Worker
启动问题: 执行start-all.sh出现以下异常信息: failed to launch: nice -n 0 /bin/spark-class org.apache.spark.deploy.w ...
- caffe 训练时,出现错误:Check failed: error == cudaSuccess (4 vs. 0) unspecified launch failure
I0415 15:03:37.603461 27311 solver.cpp:42] Solver scaffolding done.I0415 15:03:37.603549 27311 solve ...
- Hadoop - 操作练习之单机配置 - Hadoop2.8.0/Ubuntu16.04
系统版本 anliven@Ubuntu1604:~$ uname -a Linux Ubuntu1604 4.8.0-36-generic #36~16.04.1-Ubuntu SMP Sun Feb ...
- This server is in the failed servers list: localhost/127.0.0.1:16000 启动hbase api调用错误
api 调用发现错误 Mon Nov 18 23:04:31 CST 2019, RpcRetryingCaller{globalStartTime=1574089469858, pause=100, ...
- MongoDB 由于目标计算机积极拒绝,无法连接 2014-07-25T11:00:48.634+0800 warning: Failed to connect to 127.0.0.1:27017, reason: errno:10061
转载自:http://www.cnblogs.com/xiaoit/p/3867573.html 1:启动MongoDB 2014-07-25T11:00:48.634+0800 warning: F ...
- Spring Boot + Bootstrap 出现"Failed to decode downloaded font"和"OTS parsing error: Failed to convert WOFF 2.0 font to SFNT"
准确来讲,应该是maven项目使用Bootstrap时,出现 "Failed to decode downloaded font"和"OTS parsing error: ...
- 【MongoDB】2014-07-25T11:00:48.634+0800 warning: Failed to connect to 127.0.0.1:27017, reason: errno:10061 由于目标计算机积极拒绝,无法连接。
1:启动MongoDB 2014-07-25T11:00:48.634+0800 warning: Failed to connect to 127.0.0.1:27017, reason: errn ...
- Hadoop 新生报道(二) hadoop2.6.0 集群系统版本安装和启动配置
本次基于Hadoop2.6版本进行分布式配置,Linux系统是基于CentOS6.5 64位的版本.在此设置一个主节点和两个从节点. 准备3台虚拟机,分别为: 主机名 IP地址 master 192. ...
- Hadoop新生报到(一) hadoop2.6.0伪分布式配置详解
首先先不看理论,搭建起环境之后再看: 搭建伪分布式是为了模拟环境,调试方便. 电脑是win10,用的虚拟机VMware Workstation 12 Pro,跑的Linux系统是centos6.5 , ...
随机推荐
- 【BZOJ4553】【TJOI2016】【HEOI2016】序列
cdq和整体二分之间的关系好迷啊 原题: 佳媛姐姐过生日的时候,她的小伙伴从某宝上买了一个有趣的玩具送给他.玩具上有一个数列,数列中某些项的值 可能会变化,但同一个时刻最多只有一个值发生变化.现在佳媛 ...
- confluence 为合并的单元格新增一行
1,先将最后一个结构取消合并单元格 | | ___ | | | ___ | | _ | ___ | 2,在最后一行追加一行,将左侧合并 3,将上面取消合并的重新合并即可
- 开发工具idea背景及字体设置
背景设置: 按两下shift,在搜索框里输入set Background Image,选择set Background Image,如图所示: 设置图片的路径和透明度,如图所示: ★ 注意:idea ...
- 如何让你的 KiCad 在缩放时不眩晕?
如何让你的 KiCad 在缩放时不眩晕? 使用 KiCAD 第一感觉是打开速度非常快,而且 PCB 拉线也非常快,封装库又多. 但有一个问题,缩放时总给人一种眩晕,原来是因为鼠标自动跑到屏幕中间去了, ...
- MySQL 术语
MySQL 术语: MySQL 术语 含义 B-树 英文:Balance Tree:读音:B树(中间的横线,是分隔符的意思:注意:不读"B减树")
- TypeScript 之 声明文件的使用
https://www.tslang.cn/docs/handbook/declaration-files/consumption.html 下载 在TypeScript 2.0以上的版本,获取类型声 ...
- java JVM JRE JDK三者之间的关系
JDK在包含JRE之外,提供了开发Java应用的各种工具,比如编译器和调试器. JRE包括JVM和JAVA核心类库和支持文件,是Java的运行平台. JVM是JRE的一部分,Java虚拟机的主要工作是 ...
- Spring IOC(一)概览
Spring ioc源码解析这一系列文章会比较枯燥,但是只要坚持下去,总会有收获,一回生二回熟,没有第一次,哪有下一次... 本系列目录: Spring IOC(一)概览 Spring IOC(二)容 ...
- Hanlp在ubuntu中的使用方法介绍
HanLP的一个很大的好处是离线开源工具包,换而言之,它不仅提供免费的代码免费下载,而且将辛苦收集的词典也对外公开啦,此诚乃一大无私之举.我在安装的时候,主要参照这份博客: blog.csdn.net ...
- mysql的变量信息详解
mysql的变量详解 执行show variables命令可以查看MySQL服务器的变量 变量名 默认值 说明 对应的配置文件参数 auto_increment_increment 1 自增长类型的初 ...