使用scrapy-crawlSpider 爬取tencent 招聘
Tencent 招聘信息网站
创建项目
scrapy startproject Tencent
创建爬虫
scrapy genspider -t crawl tencent
1. 起始url start_url = 'https://hr.tencent.com/position.php'
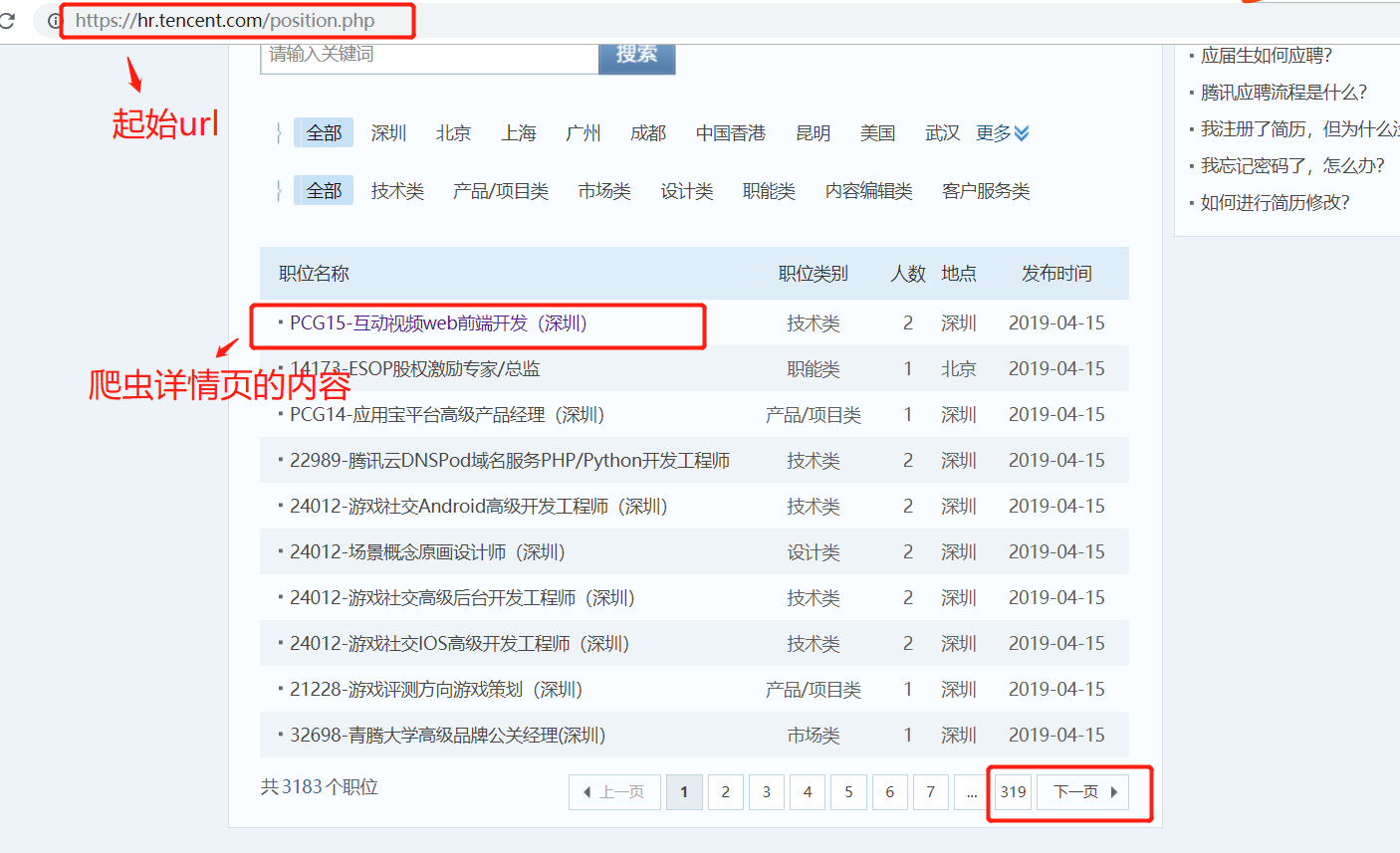
在起始页面,需要获取该也页面上的每个职位的详情页的url,同时需要提取下一页的url地址,做同样的操作。
因此起始页url地址的提取,分为两类:
1. 每个职位详情页的url地址的提取
2. 下一页url地址的提取,并且得到的页面做的操作和起始页的操作一样。
url地址的提取
1. 提取详情页url,详情页的url地址如下:
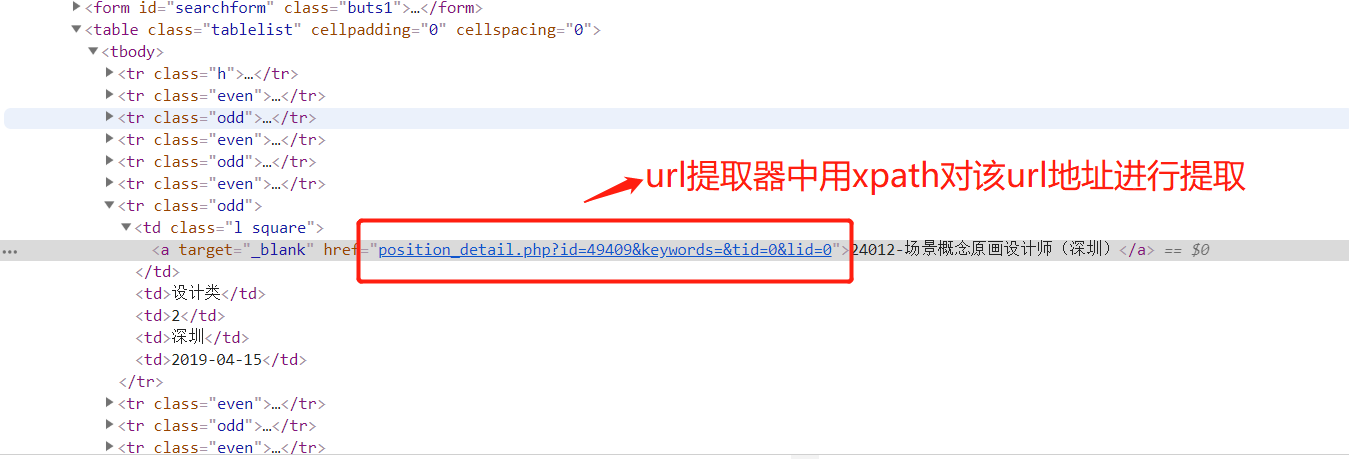
提取规则详情页的规则:
rules = (
# 提取详情页的url地址 ,详情页url地址对应的响应,需要进行数据提取,所有需要有回调函数,用来解析数据 Rule(LinkExtractor(restrict_xpaths=("//table[@class='tablelist']//td[@class='l square']")), callback='parse_item')
)
提取下一页的htmlj所在的位置:
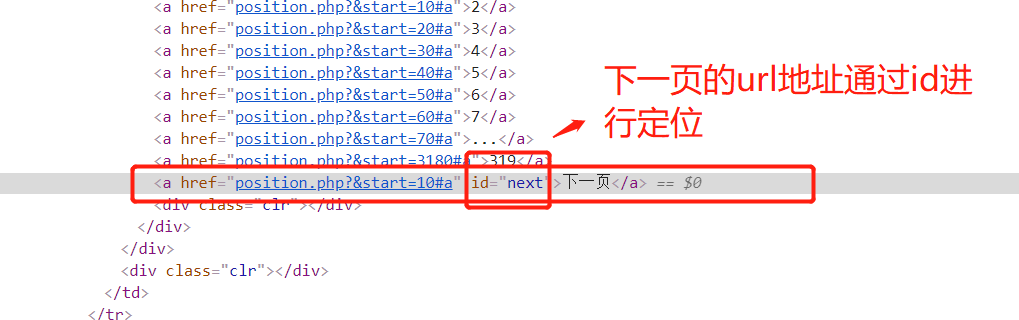
2 获取下一页的url 规则:
rules = (
# 提取详情页的url地址
# Rule(LinkExtractor(allow=r'position_detail.php?id=\d+\&keywords=&tid=0&lid=0'), callback='parse_item'), # 这个表达式有错,这里不用正则
Rule(LinkExtractor(restrict_xpaths=("//table[@class='tablelist']//td[@class='l square']")), callback='parse_item'),
# 翻页
Rule(LinkExtractor(restrict_xpaths=("//a[@id='next']")), follow=True),
)
获取详情页数据

1.详情数据提取(爬虫逻辑)
1.获取标题

xpath:
item['title'] = response.xpath('//td[@id="sharetitle"]/text()').extract_first()
2. 获取工作地点,职位,招聘人数
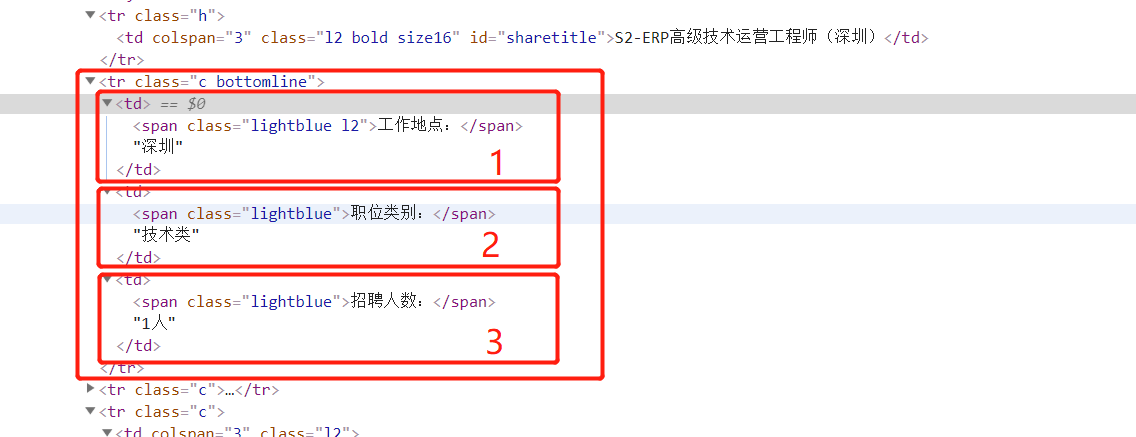
xpath:
item['addr'] = response.xpath('//tr[@class="c bottomline"]/td[1]//text()').extract()[1]
item['position'] = response.xpath('//tr[@class="c bottomline"]/td[2]//text()').extract()[1]
item['num'] = response.xpath('//tr[@class="c bottomline"]/td[3]//text()').extract()[1]
3.工作要求抓取

xpath:
item['skill'] =response.xpath('//ul[@class="squareli"]/li/text()').extract()
爬虫的代码:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule from ..items import TencentItem class TencentSpider(CrawlSpider):
name = 'tencent'
allowed_domains = ['hr.tencent.com']
start_urls = ['https://hr.tencent.com/position.php'] rules = (
# 提取详情页的url地址
# Rule(LinkExtractor(allow=r'position_detail.php?id=\d+\&keywords=&tid=0&lid=0'), callback='parse_item'), # 这个表达式有错
Rule(LinkExtractor(restrict_xpaths=("//table[@class='tablelist']//td[@class='l square']")), callback='parse_item'),
# 翻页
Rule(LinkExtractor(restrict_xpaths=("//a[@id='next']")), follow=True),
) def parse_item(self, response): item = TencentItem() item['title'] = response.xpath('//td[@id="sharetitle"]/text()').extract_first() item['addr'] = response.xpath('//tr[@class="c bottomline"]/td[1]//text()').extract()[0] item['position'] = response.xpath('//tr[@class="c bottomline"]/td[2]//text()').extract()[0] item['num'] = response.xpath('//tr[@class="c bottomline"]/td[3]//text()').extract()[0] item['skill'] =response.xpath('//ul[@class="squareli"]/li/text()').extract() print(dict(item)) return item
tencent.py
2. 数据存储
1.settings.py 配置文件,配置如下信息
ROBOTSTXT_OBEY = False
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
ITEM_PIPELINES = {
'jd.pipelines.TencentPipeline': 300, }
2. items.py 中:
import scrapy class TencentItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
addr = scrapy.Field()
position = scrapy.Field()
num = scrapy.Field()
skill = scrapy.Field()
3. pipeline.py中:
import pymongo
class TencentPipeline(object):
def open_spider(self,spider):
# 爬虫开启是连接数据库
client = pymongo.MongoClient()
collention = client.tencent.ten
self.client =client
self.collention = collention
pass
def process_item(self, item, spider):
# 数据保存在mongodb 中
self.collention.insert(dict(item))
return item
def colse_spdier(self,spider):
# 爬虫结束,关闭数据库
self.client.close()
启动项目
1.先将MongoDB数据库跑起来。
2.执行爬虫命令:
scrapy crawl tencent
3. 执行程序后的效果:

使用scrapy-crawlSpider 爬取tencent 招聘的更多相关文章
- Scrapy框架——CrawlSpider爬取某招聘信息网站
CrawlSpider Scrapy框架中分两类爬虫,Spider类和CrawlSpider类. 它是Spider的派生类,Spider类的设计原则是只爬取start_url列表中的网页, 而Craw ...
- Python爬虫【实战篇】scrapy 框架爬取某招聘网存入mongodb
创建项目 scrapy startproject zhaoping 创建爬虫 cd zhaoping scrapy genspider hr zhaopingwang.com 目录结构 items.p ...
- Python+Scrapy+Crawlspider 爬取数据且存入MySQL数据库
1.Scrapy使用流程 1-1.使用Terminal终端创建工程,输入指令:scrapy startproject ProName 1-2.进入工程目录:cd ProName 1-3.创建爬虫文件( ...
- 简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息
简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息 简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息 系统环境:Fedora22(昨天已安装scrapy环境) 爬取的开始URL:ht ...
- 爬虫07 /scrapy图片爬取、中间件、selenium在scrapy中的应用、CrawlSpider、分布式、增量式
爬虫07 /scrapy图片爬取.中间件.selenium在scrapy中的应用.CrawlSpider.分布式.增量式 目录 爬虫07 /scrapy图片爬取.中间件.selenium在scrapy ...
- scrapy-redis + Bloom Filter分布式爬取tencent社招信息
scrapy-redis + Bloom Filter分布式爬取tencent社招信息 什么是scrapy-redis 什么是 Bloom Filter 为什么需要使用scrapy-redis + B ...
- scrapy-redis分布式爬取tencent社招信息
scrapy-redis分布式爬取tencent社招信息 什么是scrapy-redis 目标任务 安装爬虫 创建爬虫 编写 items.py 编写 spiders/tencent.py 编写 pip ...
- python-scrapy爬取某招聘网站(二)
首先要准备python3+scrapy+pycharm 一.首先让我们了解一下网站 拉勾网https://www.lagou.com/ 和Boss直聘类似的网址设计方式,与智联招聘不同,它采用普通的页 ...
- 使用scrapy框架爬取自己的博文(2)
之前写了一篇用scrapy框架爬取自己博文的博客,后来发现对于中文的处理一直有问题- - 显示的时候 [u'python\u4e0b\u722c\u67d0\u4e2a\u7f51\u9875\u76 ...
随机推荐
- C# 字典常用方法
/* ######### ############ ############# ## ########### ### ###### ##### ### ####### #### ### ####### ...
- selinux 设置的彻底理解 并要 熟练经常的使用
只需要参考这篇文章就好了: http://www.jishux.com/plus/view-631994-1.html 注意 在linux中 两个术语 的严格区分和使用: 改变: change; 改变 ...
- 在Linux安装和使用LinuxBrew
简介 LinuxBrew是流行的Mac OS X的一个Linux叉自制包管理器. LinuxBrew是包管理软件,它能从源(在Debian / Ubuntu的如"易/ DEB",并 ...
- js希尔排序
function shellSort (arr) { var len = arr.length; var increment = Math.floor(len/2); while(increment! ...
- (转)Awsome Domain-Adaptation
Awsome Domain-Adaptation 2018-08-06 19:27:54 This blog is copied from: https://github.com/zhaoxin94/ ...
- center os
CentOS.Ubuntu.Debian三个linux比较异同 Center OS 7 安装 $$ center os 安装mysql5.6 Linux学习之Center os网络配置 Cent Os ...
- 「BZOJ2153」设计铁路 - 斜率DP
A省有一条东西向的公路经常堵车,为解决这一问题,省政府对此展开了调查. 调查后得知,这条公路两侧有很多村落,每个村落里都住着很多个信仰c教的教徒,每周日都会开着自家的车沿公路到B地去"膜拜& ...
- HDU 5791 Two(LCS求公共子序列个数)
http://acm.split.hdu.edu.cn/showproblem.php?pid=5791 题意: 给出两个序列,求这两个序列的公共子序列的总个数. 思路: 和LCS差不多,dp[i][ ...
- 理解ffmpeg中的pts,dts,time_base
首先介绍下概念: PTS:Presentation Time Stamp.PTS主要用于度量解码后的视频帧什么时候被显示出来 DTS:Decode Time Stamp.DTS主要是标识读入内存中的b ...
- Perl关联数组用法集锦
本文和大家重点讨论一下Perl关联数组的概念,创建Perl关联数组,从数组变量复制到Perl关联数组,元素的增删,用Perl关联数组循环等内容,相信通过本文的学习你对Perl关联数组的用法一定会有深刻 ...