qemu-kvm内存虚拟化1
2017-04-18
记得很早之前分析过KVM内部内存虚拟化的原理,仅仅知道KVM管理一个个slot并以此为基础转换GPA到HVA,却忽略了qemu端最初内存的申请,而今有时间借助于qemu源码分析下qemu在最初是如何申请并管理虚拟机内存的,坦白讲,还真挺复杂的。
一、概述
qemu-kvm 模型下的虚拟化引擎,内存虚拟化部分要说简单也挺简单,在虚拟机启动时,有qemu在qemu进程地址空间申请内存,即内存的申请是在用户空间完成的。通过kvm提供的API,把地址信息注册到KVM中,这样KVM中维护有虚拟机相关的slot,这些slot构成了一个完成的虚拟机物理地址空间。slot中记录了其对应的HVA,页面数、起始GPA等,利用它可以把一个GPA转化成HVA,想到这一点自然和硬件虚拟化下的地址转换机制EPT联系起来,不错,这正是KVM维护EPT的技术核心。整个内存虚拟化可以分为两部分:qemu部分和kvm部分。qemu完成内存的申请,kvm实现内存的管理。看起来简单,但是内部实现机制也并非那么简单。本文重点介绍qemu部分。
二、涉及数据结构
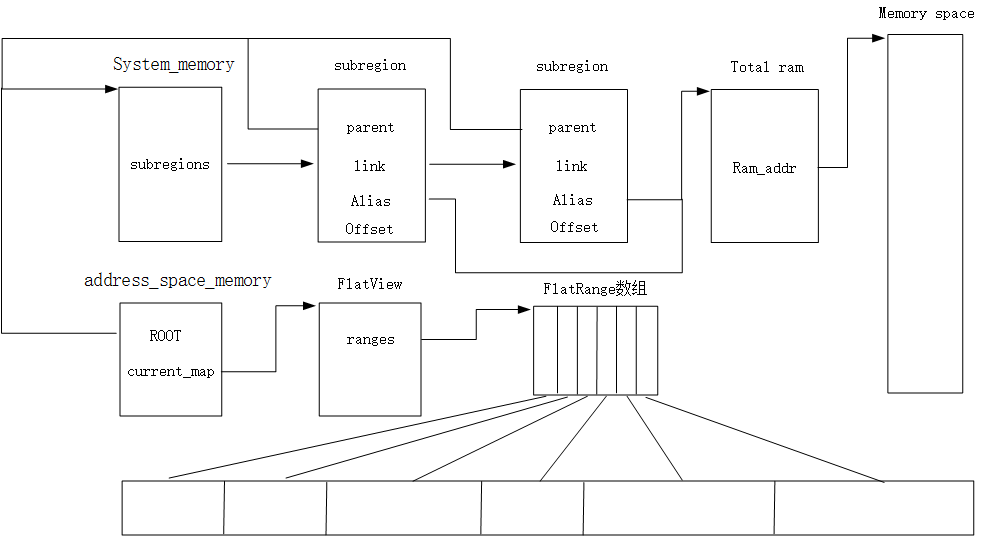
qemu中内存管理的数据结构主要涉及:MemoryRegion、AddressSpace、FlatView、FlatRange、MemoryRegionSection、RAMList、RAMBlock、KVMSlot、kvm_userspace_memory_region等
这几个数据结构的确不太容易滤清,一下是个人的一些见解。 怎么可以把qemu层的内存管理再分为三个层次,MemoryRegion就位于顶级抽象层或者说比较偏向于host端,qemu中两个全局的MemoryRegion,分别是system_memory和system_io,不过两个均是以指针的形式存在,在地址空间的时候才会对对其分配具体的内存并初始化。MemoryRegion负责管理host的内存,理论上是树状结构,但是实际上根据代码来看仅仅有两层,
struct MemoryRegion {
/* All fields are private - violators will be prosecuted */
const MemoryRegionOps *ops;
const MemoryRegionIOMMUOps *iommu_ops;
void *opaque;
struct Object *owner;
MemoryRegion *parent;//父区域指针
Int128 size;//区域的大小
hwaddr addr;
void (*destructor)(MemoryRegion *mr);
ram_addr_t ram_addr;//区域关联的ram地址,GPA
bool subpage;
bool terminates;
bool romd_mode;
bool ram;//是否是ram
bool readonly; /* For RAM regions */
bool enabled;
bool rom_device;
bool warning_printed; /* For reservations */
bool flush_coalesced_mmio;
MemoryRegion *alias;
hwaddr alias_offset;
int priority;
bool may_overlap;
QTAILQ_HEAD(subregions, MemoryRegion) subregions;//子区域链表头
QTAILQ_ENTRY(MemoryRegion) subregions_link;//子区域链表节点
QTAILQ_HEAD(coalesced_ranges, CoalescedMemoryRange) coalesced;
const char *name;
uint8_t dirty_log_mask;
unsigned ioeventfd_nb;
MemoryRegionIoeventfd *ioeventfds;
NotifierList iommu_notify;
};
MemoryRegion结构如上,相关注释已经列举,其中parent指向父MR,默认是NULL,size表示区域的大小;默认是64位下的最大地址;ram_addr比较重要,是区域关联的客户机物理地址空间的偏移,也就是客户机物理地址。alias表明该区域是某一类型的区域(先这么说吧),这么说不知是否合适,实际上虚拟机的ram申请时时一次性申请的一个完成的ram,记录在一个MR中,之后又对此ram按照size进行了划分,形成subregion,而subregion 的alias便指向原始的MR,而alias_offset 便是在原始ram中的偏移。对于系统地址空间的ram,会把刚才得到的subregion注册到系统中,父MR是刚才提到的全局MR system_memory,subregions_link是链表节点。前面提到,实际关联host内存的是subregion->alias指向的MR,其ram_addr是该MR在虚拟机的物理内存中的偏移,具体是由RAMBlock->offset获得的,RAMBlock最直接的接触host的内存,看下其结构
typedef struct RAMBlock {
struct MemoryRegion *mr;
uint8_t *host;/*block关联的内存,HVA*/
ram_addr_t offset;/*在vm物理内存中的偏移 GPA*/
ram_addr_t length;/*block的长度*/
uint32_t flags;
char idstr[];
/* Reads can take either the iothread or the ramlist lock.
* Writes must take both locks.
*/
QTAILQ_ENTRY(RAMBlock) next;
int fd;
} RAMBlock;
仅有的几个字段意义比较明确,理论上一个RAMBlock就代表host的一段虚拟 内存,host指向申请的ram的虚拟地址,是HVA。所有的RAMBlock通过next字段连接起来,表头保存在一个全局的RAMList结构中,但是根据代码来看,原始MR分配内存时分配的是一整块block,之所以这样做也许是为了扩展用吧!!RAMList中有个字段mru_block指针,指向最近使用的block,这样需要遍历所有的block时,先判断指定的block是否是mru_block,如果不是再进行遍历从而提高效率。
qemu的内存管理在交付给KVM管理时,中间又加了一个抽象层,叫做address_space.如果说MR管理的host的内存,那么address_space管理的更偏向于虚拟机。正如其名字所描述的,它是管理地址空间的,qemu中有几个全局的AddressSpace,address_space_memory和address_space_io,很明显一个是管理系统地址空间,一个是IO地址空间。它是如何进行管理的呢?展开下AddressSpace的结构;
struct AddressSpace {
/* All fields are private. */
char *name;
MemoryRegion *root;
struct FlatView *current_map;/*对应的flatview*/
int ioeventfd_nb;
struct MemoryRegionIoeventfd *ioeventfds;
struct AddressSpaceDispatch *dispatch;
struct AddressSpaceDispatch *next_dispatch;
MemoryListener dispatch_listener;
QTAILQ_ENTRY(AddressSpace) address_spaces_link;
};
对于该结构,源码的注释或许更能解释:AddressSpace: describes a mapping of addresses to #MemoryRegion objects,很明显是把MR映射到虚拟机的物理地址空间。root指向根MR,对于address_space_memory来讲,root指向系统全局的MR system_memory,current_map指向一个FlatView结构,其他的字段咱们先暂时忽略,所有的AddressSpace通过结构中的address_spaces_link连接成链表,表头保存在全局的AddressSpace结构中。FlatView管理MR展开后得到的所有FlatRange,看下FlatView
struct FlatView {
unsigned ref;//引用计数,为0时就销毁
FlatRange *ranges;/*对应的flatrange数组*/
unsigned nr;/*flatrange 的数目*/
unsigned nr_allocated;//当前数组的项数
};
各个字段的意义就不说了,ranges是一个数组,记录FlatView下所有的FlatRange,每个FlatRange对应一段虚拟机物理地址区间,各个FlatRange不会重叠,按照地址的顺序保存在数组中。FlatRange结构如下
struct FlatRange {
MemoryRegion *mr;/*指向所属的MR*/
hwaddr offset_in_region;/*在MR中的offset*/
AddrRange addr;/*本FR代表的区间*/
uint8_t dirty_log_mask;
bool romd_mode;
bool readonly;/*是否是只读*/
};
具体的范围由一个AddrRange结构描述,其描述了地址和大小,offset_in_region表示该区间在全局的MR中的offset,根据此可以进行GPA到HVA的转换,mr指向所属的MR。
到此为止,负责管理的结构基本就介绍完毕,剩余几个主要起中介的作用,MemoryRegionSection对应于FlatRange,一个FlatRange代表一个物理地址空间的片段,但是其偏向于address-space,而MemoryRegionSection则在MR端显示的表明了分片,其结构如下
struct MemoryRegionSection {
MemoryRegion *mr;//所属的MemoryRegion
AddressSpace *address_space;//region关联的AddressSpace
hwaddr offset_within_region;//在region内部的偏移
Int128 size;//section的大小
hwaddr offset_within_address_space;//首个字节的地址在section中的偏移
bool readonly;//是否是只读
};
其中注意两个偏移,offset_within_region和offset_within_address_space。前者描述的是该section在整个MR中的偏移,一个address_space可能有多个MR构成,因此该offset是局部的。而offset_within_address_space是在整个地址空间中的偏移,是全局的offset。
KVMSlot也是一个中介,只不过更加接近kvm了,
typedef struct KVMSlot
{
hwaddr start_addr;//客户机物理地址 GPA
ram_addr_t memory_size;//内存大小
void *ram;//HVA qemu用户空间地址
int slot;//slot编号
int flags;
} KVMSlot;
kvm_userspace_memory_region是和kvm共享的一个结构,说共享不太恰当,但是其实最终作为参数给kvm使用的,kvm获取控制权后,从栈中复制该结构到内核,其中字段意思就很简单,不在赘述。
整体布局大致如图所示
三、具体实现机制
qemu部分的内存申请流程上可以分为三小部分,分成三小部分主要是我在看代码的时候觉得这三部分耦合性不是很大,相对而言比较独立。众所周知,qemu起始于vl.c中的main函数,那么这三部分也按照在main函数中的调用顺序分别介绍。
3.1 回调函数的注册
涉及函数:configure_accelerator() -->kvm_init()-->memory_listener_register ()
这里所说的accelerator在这里就是kvm,初始化函数自然调用了kvm_init,该函数主要完成对kvm的初始化,包括一些常规检查如CPU个数、kvm版本等,还会通过ioctl和内核交互创建kvm结构,这些并非本文重点,不在赘述。在kvm_init函数的结尾调用了memory_listener_register
memory_listener_register(&kvm_memory_listener, &address_space_memory);
memory_listener_register(&kvm_io_listener, &address_space_io);
通过memory_listener_register函数,针对地址空间注册了lisenter,lisenter本身是一组函数表,当地址空间发生变化的时候,会调用到listener中的相应函数,从何保持内核和用户空间的内存信息的一致性。虚拟机包含有两个地址空间address_space_memory和address_space_io,很容易理解,正常系统也包含系统地址空间和IO地址空间。
memory_listener_register函数不复杂,咱们看下
void memory_listener_register(MemoryListener *listener, AddressSpace *filter)
{
MemoryListener *other = NULL;
AddressSpace *as; listener->address_space_filter = filter;
/*如果listener为空或者当前listener的优先级大于最后一个listener的优先级,则可以直接插入*/
if (QTAILQ_EMPTY(&memory_listeners)
|| listener->priority >= QTAILQ_LAST(&memory_listeners,
memory_listeners)->priority) {
QTAILQ_INSERT_TAIL(&memory_listeners, listener, link);
} else {
/*listener按照优先级升序排列*/
QTAILQ_FOREACH(other, &memory_listeners, link) {
if (listener->priority < other->priority) {
break;
}
}
/*插入listener*/
QTAILQ_INSERT_BEFORE(other, listener, link);
}
/*全局address_spaces-->as*/
/*对于每个address_spaces,设置listener*/
QTAILQ_FOREACH(as, &address_spaces, address_spaces_link) {
listener_add_address_space(listener, as);
}
}
系统中可以存在多个listener,listener之间有着明确的优先级关系,通过链表进行组织,链表头是全局的memory_listeners。函数中,如果memory_listeners为空或者当前listener的优先级大于最后一个listener的优先级,即直接把当前listener插入。否则需要挨个遍历链表,找到合适的位置。具体按照优先级升序查找。在函数最后还针对每个address_space,调用listener_add_address_space函数,该函数对其对应的address_space管理的flatrange向KVM注册。当然,实际上此时address_space尚未经过初始化,所以这里的循环其实是空循环。
3.2 Address_Space的初始化
涉及函数:cpu_exec_init_all() memory_map_init()
在第一节中已经注册了listener,但是addressspace尚未初始化,本节就介绍下其初始化流程。从上节的configure_accelerator()函数往下走,会执行cpu_exec_init_all()函数,该函数主要初始化了IO地址空间和系统地址空间。memory_map_init()函数初始化系统地址空间,有一个全局的MemoryRegion指针system_memory指向该区域的MemoryRegion结构。
static void memory_map_init(void)
{
/*为system_memory分配内存*/
system_memory = g_malloc(sizeof(*system_memory)); assert(ADDR_SPACE_BITS <= ); memory_region_init(system_memory, NULL, "system",
ADDR_SPACE_BITS == ?
UINT64_MAX : (0x1ULL << ADDR_SPACE_BITS));
/*初始化全局的address_space_memory*/
address_space_init(&address_space_memory, system_memory, "memory"); system_io = g_malloc(sizeof(*system_io));
memory_region_init_io(system_io, NULL, &unassigned_io_ops, NULL, "io",
);
address_space_init(&address_space_io, system_io, "I/O"); memory_listener_register(&core_memory_listener, &address_space_memory);
if (tcg_enabled()) {
memory_listener_register(&tcg_memory_listener, &address_space_memory);
}
}
所以在函数起始,就对system_memory分配了内存,然后调用了memory_region_init函数对其进行初始化,其中size设置为整个地址空间:如果是64位就是2^64.接着调用了address_space_init函数对address_space_memory进行了初始化。
void address_space_init(AddressSpace *as, MemoryRegion *root, const char *name)
{
if (QTAILQ_EMPTY(&address_spaces)) {
memory_init();
} memory_region_transaction_begin();
/*指定address_space_memory的root为system_memory*/
as->root = root;
/*创建并关联了一个FlatView*/
as->current_map = g_new(FlatView, );
/*初始化FlatView*/
flatview_init(as->current_map);
as->ioeventfd_nb = ;
as->ioeventfds = NULL;
/*把address_space_memory插入全局链表*/
QTAILQ_INSERT_TAIL(&address_spaces, as, address_spaces_link);
as->name = g_strdup(name ? name : "anonymous");
address_space_init_dispatch(as);
memory_region_update_pending |= root->enabled;
memory_region_transaction_commit();
}
函数主要做了以下几个工作,设置addressSpaceh和MR的关联,并初始化对应的FlatView,设置其名称。最后把address_space_memory加入到全局的address_spaces链表中,最后调用memory_region_transaction_commit()提交本次修改,关于memory_region_transaction_commit后imianzai做论述。回到memory_map_init()函数中,接下来按照同样的模式对IO区域system_io和IO地址空间address_space_io做了初始化。
3.3 实际内存的分配
前面注册listener也好,或是初始化addressspace也好,实际上均没有对应的物理内存。顺着main函数往下走,会调用到machine—>init,实际上对应于pc_init1函数,在该函数中有pc_memory_init()函数对实际的内存做了分配。我们直接从pc_memory_init()函数开始
FWCfgState *pc_memory_init(MemoryRegion *system_memory,
const char *kernel_filename,
const char *kernel_cmdline,
const char *initrd_filename,
ram_addr_t below_4g_mem_size,
ram_addr_t above_4g_mem_size,
MemoryRegion *rom_memory,
MemoryRegion **ram_memory,
PcGuestInfo *guest_info)
{
int linux_boot, i;
MemoryRegion *ram, *option_rom_mr;
MemoryRegion *ram_below_4g, *ram_above_4g;
FWCfgState *fw_cfg; linux_boot = (kernel_filename != NULL); /* Allocate RAM. We allocate it as a single memory region and use
* aliases to address portions of it, mostly for backwards compatibility
* with older qemus that used qemu_ram_alloc().
*/
ram = g_malloc(sizeof(*ram));
//分配具体的内存
memory_region_init_ram(ram, NULL, "pc.ram",
below_4g_mem_size + above_4g_mem_size);
//那mr中的name设置进block
vmstate_register_ram_global(ram);
*ram_memory = ram;
ram_below_4g = g_malloc(sizeof(*ram_below_4g));
/*对整体ram进行划分*/
memory_region_init_alias(ram_below_4g, NULL, "ram-below-4g", ram,
, below_4g_mem_size);
/******/
memory_region_add_subregion(system_memory, , ram_below_4g);
e820_add_entry(, below_4g_mem_size, E820_RAM);
if (above_4g_mem_size > ) {
ram_above_4g = g_malloc(sizeof(*ram_above_4g));
memory_region_init_alias(ram_above_4g, NULL, "ram-above-4g", ram,
below_4g_mem_size, above_4g_mem_size);
memory_region_add_subregion(system_memory, 0x100000000ULL,
ram_above_4g);
e820_add_entry(0x100000000ULL, above_4g_mem_size, E820_RAM);
} /* Initialize PC system firmware */
pc_system_firmware_init(rom_memory, guest_info->isapc_ram_fw); option_rom_mr = g_malloc(sizeof(*option_rom_mr));
memory_region_init_ram(option_rom_mr, NULL, "pc.rom", PC_ROM_SIZE);
vmstate_register_ram_global(option_rom_mr);
memory_region_add_subregion_overlap(rom_memory,
PC_ROM_MIN_VGA,
option_rom_mr,
); fw_cfg = bochs_bios_init();
rom_set_fw(fw_cfg); if (linux_boot) {
load_linux(fw_cfg, kernel_filename, initrd_filename, kernel_cmdline, below_4g_mem_size);
} for (i = ; i < nb_option_roms; i++) {
rom_add_option(option_rom[i].name, option_rom[i].bootindex);
}
guest_info->fw_cfg = fw_cfg;
return fw_cfg;
}
从总体上来讲,该函数主要完成了三个工作:分配全局ram(一整个memory region),然后根据below_4g_mem_size、above_4g_mem_size分别对ram进行划分,形成子MR,并注册子MR到root MR system_memory 的subregions链表中。最后需要调用memory_region_transaction_commit()函数提交修改。具体而言,分配全局ram由memory_region_init_ram()完成,
void memory_region_init_ram(MemoryRegion *mr,
Object *owner,
const char *name,
uint64_t size)
{
memory_region_init(mr, owner, name, size);
mr->ram = true;
mr->terminates = true;
mr->destructor = memory_region_destructor_ram;
//为MemoryRegion分配ram 实际上是block.offset,指的是客户机物理地址空间的偏移即GPA
mr->ram_addr = qemu_ram_alloc(size, mr);
}
该函数实现很简单,首先调用memory_region_init对MR做初始化。然后进行简单的设置,最重要的还是最后的qemu_ram_alloc,咱们重点看下这个函数,该函数不过是qemu_ram_alloc_from_ptr函数的封装,该函数围绕RAMBlock结构,在函数起始对size进行页对齐,然后申请一个RAMBlock结构,之后对其字段进行一些设置如 指定MR 和offset,offset理论上需要调用find_ram_offset在已有的RAMBlock中找到一个可用的。但是此时实际上还没有其他block,所以这里应该直接返回0的。本部分最重要的莫过于设置其host了,其对应的宿主机虚拟地址空间的虚拟地址。在支持大页的情况下调用file_ram_alloc()函数进行分配,否则调用phys_mem_alloc()函数进行分配。二者分配其实都是利用mmap分配的,但是在支持大页的情况下需要传递参数mem_path,所以需要两个函数。在非大页的情况下,分配好内存尝试和相邻的block合并下。最后把block插入到全局的链表ram_list中,只是block保持从大到小的顺序。
经过上面的初始化,我们得到一个完整的ram,下面的vmstate_register_ram_global仅仅是吧MR的名字设置到对应的block中。此为全局的MR,根据ram_below_4g和ram_above_4g,全局的MR被划分为两部分,形成两个子MR。memory_region_init_alias()函数便对两个子MR进行初始化,这里就不在进行内存的申请,主要是设置alias和alias_offset字段,代码如下。
void memory_region_init_alias(MemoryRegion *mr,
Object *owner,
const char *name,
MemoryRegion *orig,
hwaddr offset,
uint64_t size)
{
memory_region_init(mr, owner, name, size);
memory_region_ref(orig);
mr->destructor = memory_region_destructor_alias;
mr->alias = orig;
mr->alias_offset = offset;
}
在初始化完毕,需要调用memory_region_add_subregion()函数把子MR注册到全局的system_memory。该函数实现是比较简单的,但是需要重点介绍下,因为这里执行了关键的更新操作。函数核心交给memory_region_add_subregion_common()函数实现,该函数同样比较简单,设置subregion->parent和system_memory的关联,设置其addr字段为offset,即在全局MR中的偏移。然后就按照优先级顺序吧subregion插入到system_memory的subregions链表中,这些都比较简单,目前我们添加了区域,地址空间已经发生变化,自然要把变化和KVM进行同步,这一工作由memory_region_transaction_commit()实现。
void memory_region_transaction_commit(void)
{
AddressSpace *as; assert(memory_region_transaction_depth);
--memory_region_transaction_depth;
if (!memory_region_transaction_depth && memory_region_update_pending) {
memory_region_update_pending = false;
MEMORY_LISTENER_CALL_GLOBAL(begin, Forward);
/*更新各个addressspace 拓扑结构*/
QTAILQ_FOREACH(as, &address_spaces, address_spaces_link) {
address_space_update_topology(as);
} MEMORY_LISTENER_CALL_GLOBAL(commit, Forward);
}
}
可以看到,这里listener的作用就凸显出来了。对于每个address_space,调用address_space_update_topology()执行更新。里面涉及两个重要的函数generate_memory_topology和address_space_update_topology_pass。前者对于一个给定的MR,生成其对应的FlatView,而后者则根据oldview和newview对当前视图进行更新。我们还是看下address_space_update_topology函数代码
static void address_space_update_topology(AddressSpace *as)
{
FlatView *old_view = address_space_get_flatview(as);
/*根据AddressSpace对应的MR生成一个新的FlatView*/
FlatView *new_view = generate_memory_topology(as->root); address_space_update_topology_pass(as, old_view, new_view, false);
address_space_update_topology_pass(as, old_view, new_view, true); qemu_mutex_lock(&flat_view_mutex);
flatview_unref(as->current_map);
/*设置新的FlatView*/
as->current_map = new_view;
qemu_mutex_unlock(&flat_view_mutex); /* Note that all the old MemoryRegions are still alive up to this
* point. This relieves most MemoryListeners from the need to
* ref/unref the MemoryRegions they get---unless they use them
* outside the iothread mutex, in which case precise reference
* counting is necessary.
*/
flatview_unref(old_view); address_space_update_ioeventfds(as);
}
在获取了新旧两个FlatView之后,调用了两次address_space_update_topology_pass()函数,首次调用重在删除原来的,而后者重在添加。之后设置as->current_map = new_view。并对old_view减少引用,当引用计数为1时会被删除。接下来重点在两个地方:1、如何根据一个MR获取对应的FlatView;2、如何对旧的FlatView进行更新。
前者自然少不了分析generate_memory_topology函数
tatic FlatView *generate_memory_topology(MemoryRegion *mr)
{
FlatView *view;
/*mR是system_memory*/
view = g_new(FlatView, );
flatview_init(view);
/*addrrange_make生成一个0-2^64的地址空间*/
if (mr) {
/*最初是让MR 按照基址为0映射到地址空间中*/
render_memory_region(view, mr, int128_zero(),
addrrange_make(int128_zero(), int128_2_64()), false);
}
flatview_simplify(view); return view;
}
首先申请一个FlatView结构,并对其进行初始化,然后调用render_memory_region函数实现核心功能,最后还调用flatview_simplify尝试合并相邻的FlatRange.static void render_memory_region(FlatView *view,MemoryRegion *mr,Int128 base,AddrRange clip,bool readonly)是一个递归函数,参数中,view表示当前FlatView,mr最初为system_memory即全局的MR,base起初为0表示从地址空间的其实开始,clip最初为一个完整的地址空间。readonly标识是否只读。
static void render_memory_region(FlatView *view,
MemoryRegion *mr,
Int128 base,
AddrRange clip,
bool readonly)
{
MemoryRegion *subregion;
unsigned i;
hwaddr offset_in_region;
Int128 remain;
Int128 now;
FlatRange fr;
AddrRange tmp; if (!mr->enabled) {
return;
} int128_addto(&base, int128_make64(mr->addr));
readonly |= mr->readonly;
/*获得当前MR的地址区间范围*/
tmp = addrrange_make(base, mr->size);
/*判断目标MR和clip是否有交叉,即MR应该落在clip的范围内*/
if (!addrrange_intersects(tmp, clip)) {
return;
}
/*缩小clip到交叉的部分*/
clip = addrrange_intersection(tmp, clip);
/*子区域才有alias字段*/
if (mr->alias) {
int128_subfrom(&base, int128_make64(mr->alias->addr));
int128_subfrom(&base, int128_make64(mr->alias_offset));
/*这里base应该为subregion对应的alias中的区间基址*/
render_memory_region(view, mr->alias, base, clip, readonly);
return;
} /* Render subregions in priority order. */
QTAILQ_FOREACH(subregion, &mr->subregions, subregions_link) {
render_memory_region(view, subregion, base, clip, readonly);
} if (!mr->terminates) {
return;
}
/*offset_in_region is distance between clip.start and base */
/*clip.start表示地址区间的起始,base为本次映射的基址,差值就为offset*/
offset_in_region = int128_get64(int128_sub(clip.start, base));
/***开始映射时,clip表示映射的区间范围,base作为一个移动指导每个FR的映射,remain表示clip总还没映射的大小*/
/*最初base=clip.start */
base = clip.start;
remain = clip.size; fr.mr = mr;
fr.dirty_log_mask = mr->dirty_log_mask;
fr.romd_mode = mr->romd_mode;
fr.readonly = readonly; /* Render the region itself into any gaps left by the current view. */
for (i = ; i < view->nr && int128_nz(remain); ++i) {
/*if base > addrrange_end(view->ranges[i].addr)即大于一个range的end*/
if (int128_ge(base, addrrange_end(view->ranges[i].addr))) {
continue;
}
/*如果base < = view->ranges[i].addr.start*/
/*now 表示已经存在的FR 或者本次填充的FR的长度*/
if (int128_lt(base, view->ranges[i].addr.start)) {
now = int128_min(remain,
int128_sub(view->ranges[i].addr.start, base));
/*fr.offset_in_region表示在整个地址空间中的偏移*/
fr.offset_in_region = offset_in_region;
fr.addr = addrrange_make(base, now);
flatview_insert(view, i, &fr);
++i;
int128_addto(&base, now);
offset_in_region += int128_get64(now);
int128_subfrom(&remain, now);
}
/*if base > rang[i].start,means overlap exists,need escape*/
now = int128_sub(int128_min(int128_add(base, remain),
addrrange_end(view->ranges[i].addr)),
base);
int128_addto(&base, now);
offset_in_region += int128_get64(now);
int128_subfrom(&remain, now);
}
/*如果还有剩下的clip没有映射,则下面不会在发生冲突,直接一次性的映射完成*/
if (int128_nz(remain)) {
fr.offset_in_region = offset_in_region;
fr.addr = addrrange_make(base, remain);
flatview_insert(view, i, &fr);
}
}
在此必须清楚MR和clip的意义,即该函数实现的是把MR的区域填充clip空间。填充的方式就是生成一个个FlatRange,并交由FlatView管理。基本管理逻辑理论上如图所示
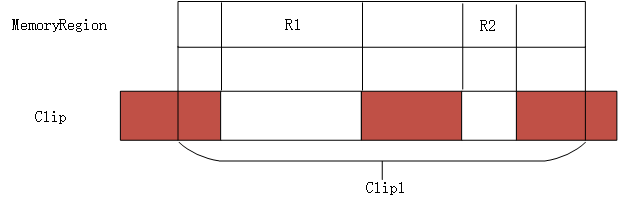
棕色部分意味着已经存在的映射,这种情况下只需要把R1和R2映射进来即可。最终FlatView中的FlatRange按照在物理地址空间的布局,依次排列。但是按照实际情况来讲,实际上传递进来的MR是整个地址空间system_space,所以像图中那样比较复杂的格局应该基本不会出现。不过咱们还是根据代码来看。首先获取了当前MR的区间范围,以base为起点。我们目的是要把MR的区间映射进clip中,所以如果两者没有交叉,那么无法完成映射。接着设置clip为二者地址区间重叠的部分,以图中所示,clip就成了clip1所标的范围。如果当前MR是某个subregion,则需要对其原始的MR进行展开,因为具体的信息都保存在原始的MR中。但是全局MR system_memory作为参数传递进来,那么这里mr->alias为NULL,所以到了下面对system_memory的每个subregion均进行展开。就这样再次进入render_memory_region函数的时候,MR为某个subregion,clip也为subregion对应的区域和原始clip的交集,由于其mr->alias指向原始MR,进入if判断,对原始MR的对应区间进行展开,再次调用render_memory_region。这一次就要进行真正的展开操作了,即生成对应的FlatRange。
顺着函数往下走,涉及几个变量这里先介绍下,offset_in_region为对应MR在全局地址空间中的偏移,base为一个移动指针,指向当前映射的小区间,指导每个FR的映射。now当前已经映射的FR的长度,有两种可能,第一可能是当前映射的FR,第二可能是已经映射的FR。remain表示当前clip中剩下的未映射的部分(不考虑已经存在的FR),有了这些再看下面的代码就不吃力了。
核心的工作起始于一个for循环,循环的条件是 view->nr && int128_nz(remain),表示当前还有未遍历的FR并且remain还有剩余。循环中如果MR base的值大于或者等于当前FR的end,则继续往后遍历FR,否则进入下面,如果base小于当前FR的start,则表明base到start之间的区间还没有映射,则为其进行映射,now表示要映射的长度,取remain和int128_sub(view->ranges[i].addr.start, base)之间的最小值,后者表示下一个FR的start和base之间的差值,当然按照clip为准。接下来就没难度了,设置FR的offset_in_region和addr,然后调用flatview_insert插入到FlatView的FlatRange数组中。不过由于FR按照地址顺序排列,如果插入位置靠前,则需要移动较多的项,不知道为何不用链表实现。下面就很自然了移动base,增加offset_in_region,减少remain等操作。出了if,此时base已经和FR的start对齐,所以还需要略过当前FR。就这么一直映射下去。
出了for循环,如果remain不为0,则表明还有没有映射的,但是现在已经没有已经存在的FR了,所以不会发生冲突,直接把remain直接映射成一个FR即可。
按照这个思路,吧所有的subregion都映射下去,最终把FlatView返回。这样generate_memory_topology就算是介绍完了,下面的flatview_simplify是对数组表项的尝试合并,这里就不再介绍。到此为止,已经针对当前MR生成了一个新的FlatView,接下来需要用address_space_update_topology_pass函数对old_view和new_view做对比。连续调用了两次这个函数,不过最后的adding参数先后为false和true。进入函数分析下
static void address_space_update_topology_pass(AddressSpace *as,
const FlatView *old_view,
const FlatView *new_view,
bool adding)
{
/*FR计数*/
unsigned iold, inew;
FlatRange *frold, *frnew; /* Generate a symmetric difference of the old and new memory maps.
* Kill ranges in the old map, and instantiate ranges in the new map.
*/
iold = inew = ;
while (iold < old_view->nr || inew < new_view->nr) {
if (iold < old_view->nr) {
frold = &old_view->ranges[iold];
} else {
frold = NULL;
}
if (inew < new_view->nr) {
frnew = &new_view->ranges[inew];
} else {
frnew = NULL;
}
/*int128_lt 小于等于*/
/*int128_eq 等于*/
/*frold not null and( frnew is null || frold not null and old.start <= new.start || frold not null and old.start == new.start) and old !=new*/
if (frold
&& (!frnew
|| int128_lt(frold->addr.start, frnew->addr.start)
|| (int128_eq(frold->addr.start, frnew->addr.start)
&& !flatrange_equal(frold, frnew)))) {
/* In old but not in new, or in both but attributes changed. */
/*if not add*/
if (!adding) {
MEMORY_LISTENER_UPDATE_REGION(frold, as, Reverse, region_del);
} ++iold;
/*if old and new and old==new*/
} else if (frold && frnew && flatrange_equal(frold, frnew)) {
/* In both and unchanged (except logging may have changed) */
/*if add*/
if (adding) {
MEMORY_LISTENER_UPDATE_REGION(frnew, as, Forward, region_nop);
if (frold->dirty_log_mask && !frnew->dirty_log_mask) {
MEMORY_LISTENER_UPDATE_REGION(frnew, as, Reverse, log_stop);
} else if (frnew->dirty_log_mask && !frold->dirty_log_mask) {
MEMORY_LISTENER_UPDATE_REGION(frnew, as, Forward, log_start);
}
}
++iold;
++inew;
} else {
/* In new */
/*if add*/
if (adding) {
MEMORY_LISTENER_UPDATE_REGION(frnew, as, Forward, region_add);
}
++inew;
}
}
}
该函数倒是不长,主体是一个while循环,循环条件是old_view->nr和new_view->nr,表示新旧view的可用FlatRange数目。这里依次对FR数组的对应FR 做对比,主要由下面几种情况:frold和frnew均存在、frold存在但frnew不存在,frold不存在但frnew存在。下面的if划分和上面的略有不同:
1、如果frold不为空&&(frnew为空||frold.start<frnew.start||frold.start=frnew.start)&&frold!=frnew 这种情况是新旧view的地址范围不一样,则需要调用lienter的region_del对frold进行删除。
2、如果frold和frnew均不为空且frold.start=frnew.start 这种情况需要判断日志掩码,如果frold->dirty_log_mask && !frnew->dirty_log_mask,调用log_stop回调函数;如果frnew->dirty_log_mask && !frold->dirty_log_mask,调用log_start回调函数。
3、frold为空但是frnew不为空 这种情况直接调用region_add回调函数添加region。
函数主体逻辑基本如上所述,那我们注意到,当adding为false时,执行的只有第一个情况下的处理,就是删除frold的操作,其余的处理只有在adding 为true的时候才得以执行。这意图就比较明确,首次执行先删除多余的,下次直接添加或者对日志做更新操作了。
总结:qemu内存虚拟化部分先介绍到这里,本来还想把kvm_region_add函数介绍下,但是考虑到篇幅,同时也正好利用该函数过渡到KVM中,不会显得突兀。由于笔者能力有限,文中不免有不对的地方,还望老师们多多指教,大家一起学习,共同进步!!!
参考:qemu源码 kvm源码
qemu-kvm内存虚拟化1的更多相关文章
- KVM 内存虚拟化
内存虚拟化的概念 除了 CPU 虚拟化,另一个关键是内存虚拟化,通过内存虚拟化共享物理系统内存,动态分配给虚拟机.虚拟机的内存虚拟化很象现在的操作系统支持的虚拟内存方式,应用程序看到邻近的内存 ...
- 2017.4.28 KVM 内存虚拟化及其实现
概述 KVM(Kernel Virtual Machine) , 作为开源的内核虚拟机,越来越受到 IBM,Redhat,HP,Intel 等各大公司的大力支持,基于 KVM 的开源虚拟化生态系统也日 ...
- KVM 介绍(2):CPU 和内存虚拟化
学习 KVM 的系列文章: (1)介绍和安装 (2)CPU 和 内存虚拟化 (3)I/O QEMU 全虚拟化和准虚拟化(Para-virtulizaiton) (4)I/O PCI/PCIe设备直接分 ...
- KVM(二)CPU 和内存虚拟化
1. 为什么需要 CPU 虚拟化 X86 操作系统是设计在直接运行在裸硬件设备上的,因此它们自动认为它们完全占有计算机硬件.x86 架构提供四个特权级别给操作系统和应用程序来访问硬件. Ring 是指 ...
- [原] KVM 虚拟化原理探究(4)— 内存虚拟化
KVM 虚拟化原理探究(4)- 内存虚拟化 标签(空格分隔): KVM 内存虚拟化简介 前一章介绍了CPU虚拟化的内容,这一章介绍一下KVM的内存虚拟化原理.可以说内存是除了CPU外最重要的组件,Gu ...
- Qemu/kvm虚拟化源码解析学习视频资料
地址链接:tao宝搜索:Linux云计算KVM Qemu虚拟化视频源码讲解+实践https://item.taobao.com/item.htm?ft=t&id=646300730262 L ...
- KVM 介绍(8):使用 libvirt 迁移 QEMU/KVM 虚机和 Nova 虚机 [Nova Libvirt QEMU/KVM Live Migration]
学习 KVM 的系列文章: (1)介绍和安装 (2)CPU 和 内存虚拟化 (3)I/O QEMU 全虚拟化和准虚拟化(Para-virtulizaiton) (4)I/O PCI/PCIe设备直接分 ...
- KVM 介绍(7):使用 libvirt 做 QEMU/KVM 快照和 Nova 实例的快照 (Nova Instances Snapshot Libvirt)
学习 KVM 的系列文章: (1)介绍和安装 (2)CPU 和 内存虚拟化 (3)I/O QEMU 全虚拟化和准虚拟化(Para-virtulizaiton) (4)I/O PCI/PCIe设备直接分 ...
- KVM 介绍(6):Nova 通过 libvirt 管理 QEMU/KVM 虚机 [Nova Libvirt QEMU/KVM Domain]
学习 KVM 的系列文章: (1)介绍和安装 (2)CPU 和 内存虚拟化 (3)I/O QEMU 全虚拟化和准虚拟化(Para-virtulizaiton) (4)I/O PCI/PCIe设备直接分 ...
- 基于KVM的虚拟化研究及应用
引言 虚拟化技术是IBM在20世纪70年代首先应用在IBM/370大型机上,这项技术极大地提高了大型机资源利用率.随着软硬件技术的迅速发展,这项属于大型机及专利的技术开始在普通X86计算机上应用并成为 ...
随机推荐
- numpy的介绍——总览
为什么有numpy这个库呢? 1. 准安装的Python中用列表(list)保存一组值,可以用来当作数组使用,不过由于列表的元素可以是任何对象,因此列表中所保存的是对象的指针.这样为了保存一个简单的[ ...
- 第三百九十六节,Django+Xadmin打造上线标准的在线教育平台—其他插件使用说,自定义列表页上传插件
第三百九十六节,Django+Xadmin打造上线标准的在线教育平台—其他插件使用说,自定义列表页上传插件 设置后台列表页面字段统计 在当前APP里的adminx.py文件里的数据表管理器里设置 ag ...
- xml 转map dom4j
http://ziyu-1.iteye.com/blog/469003 传过来一个xml文件,需要转换成Map,能够应对不用结构的xml,而不是只针对固定格式的xml. 转换规则: 1.主要是Map与 ...
- localhost兼容js不能用
- js中的hasOwnProperty
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 【CF566C】Logistical Questions 点分
[CF566C]Logistical Questions 题意:给你一棵n个点的树,点有点权,边有边权,两点间的距离为两点间的边权和的$3\over 2$次方.求这棵树的带权重心. $n\le 200 ...
- 【BZOJ2671】Calc 数学
[BZOJ2671]Calc Description 给出N,统计满足下面条件的数对(a,b)的个数: 1.1<=a<b<=N 2.a+b整除a*b Input 一行一个数N Out ...
- day_5.27python网络编程
开始进行python网络编程2018-5-27 20:27:30 Tcp/Ip协议
- ThinkPHP框架 祖辈分的理解 【儿子 FenyeController】继承了【父亲 FuController】继承了【祖辈 Controller】的
注:系统自带的Controller方法代表的是祖辈 FuController控制器是自定义的,代表父亲... FenyeController控制器就代表着儿子 [儿子 FenyeController] ...
- 洛谷P1908 逆序对【递归】
题目:https://www.luogu.org/problemnew/show/P1908 题意:给定一个数组,求逆序对个数. 思路: 是一个很经典的题目了.通过归并排序可以求逆序对个数. 现在有一 ...