PySpark理解wordcount.py
在本文中, 我们借由深入剖析wordcount.py, 来揭开Spark内部各种概念的面纱。我们再次回顾wordcount.py代码来回答如下问题
对于大多数语言的Hello Word示例,都有main()函数, wordcount.py的main函数,或者说调用Spark的main() 在哪里
数据的读入,各个RDD数据如何转换
map与flatMap的工作机制,以及区别
reduceByKey的作用
WordCount.py 的代码如下:
from __future__ import print_function import sys
from operator import add # SparkSession:是一个对Spark的编程入口,取代了原本的SQLContext与HiveContext,方便调用Dataset和DataFrame API
# SparkSession可用于创建DataFrame,将DataFrame注册为表,在表上执行SQL,缓存表和读取parquet文件。
from pyspark.sql import SparkSession if __name__ == "__main__": # Python 常用的简单参数传入
if len(sys.argv) != 2:
print("Usage: wordcount <file>", file=sys.stderr)
exit(-1) # appName 为 Spark 应用设定一个应用名,改名会显示在 Spark Web UI 上
# 假如SparkSession 已经存在就取得已存在的SparkSession,否则创建一个新的。
spark = SparkSession\
.builder\
.appName("PythonWordCount")\
.getOrCreate() # 读取传入的文件内容,并写入一个新的RDD实例lines中,此条语句所做工作有些多,不适合初学者,可以截成两条语句以便理解。
# map是一种转换函数,将原来RDD的每个数据项通过map中的用户自定义函数f映射转变为一个新的元素。原始RDD中的数据项与新RDD中的数据项是一一对应的关系。
lines = spark.read.text(sys.argv[1]).rdd.map(lambda r: r[0]) # flatMap与map类似,但每个元素输入项都可以被映射到0个或多个的输出项,最终将结果”扁平化“后输出
counts = lines.flatMap(lambda x: x.split(' ')) \
.map(lambda x: (x, 1)) \
.reduceByKey(add) # collect() 在驱动程序中将数据集的所有元素作为数组返回。 这在返回足够小的数据子集的过滤器或其他操作之后通常是有用的。由于collect 是将整个RDD汇聚到一台机子上,所以通常需要预估返回数据集的大小以免溢出。
output = counts.collect() for (word, count) in output:
print("%s: %i" % (word, count)) spark.stop()
Spark 入口 SparkSession
Spark2.0中引入了SparkSession的概念,它为用户提供了一个统一的切入点来使用Spark的各项功能,这边不妨对照Http Session, 在此Spark就在充当Web service的角色,程序调用Spark功能的时候需要先建立一个Session。因此看到getOrCreate()就很容易理解了, 表明可以视情况新建session或利用已有的session。
spark = SparkSession\
.builder\
.appName("PythonWordCount")\
.getOrCreate()
既然将Spark 想象成一个Web server, 也就意味着可能用多个访问在进行,为了便于监控管理, 对应用命名一个恰当的名称是个好办法。Web UI并不是本文的重点,有兴趣的同学可以参考 Spark Application’s Web Console
加载数据
在建立SparkSession之后, 就是读入数据并写入到Dateset中。
lines = spark.read.text(sys.argv[1]).rdd.map(lambda r: r[0])
为了更好的分解执行过程,是时候借助PySpark了, PySpark是python调用Spark的 API,它可以启动一个交互式Python Shell。为了方便脚本调试,暂时切换到Linux执行
# pyspark
Python 2.7.6 (default, Jun 22 2015, 17:58:13)
[GCC 4.8.2] on linux2
Type "help", "copyright", "credits" or "license" for more information.
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
17/02/23 08:30:26 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/02/23 08:30:31 WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.0
17/02/23 08:30:31 WARN ObjectStore: Failed to get database default, returning NoSuchObjectException
17/02/23 08:30:32 WARN ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.1.0
/_/ Using Python version 2.7.6 (default, Jun 22 2015 17:58:13)
SparkSession available as 'spark'.
>>> ds = spark.read.text('/home/spark2.1/spark/examples/src/main/python/a.txt')
>>> type(ds)
<class 'pyspark.sql.dataframe.DataFrame'>
>>> print ds
DataFrame[value: string]
>>> lines = ds.rdd
交互式Shell的好处是可以方便的查看变量内容和类型。此刻文件a.txt已经加载到lines中,它是RDD(Resilient Distributed Datasets)弹性分布式数据集的实例。
RDD操作
RDD在内存中的结构可以参考论文, 理解RDD有两点比较重要:
一是RDD一种只读、只能由已存在的RDD变换而来的共享内存,然后将所有数据都加载到内存中,方便进行多次重用。
二是RDD的数据默认情况下存放在集群中不同节点的内存中,本身提供了容错性,可以自动从节点失败中恢复过来。即如果某个节点上的RDD partition,因为节点故障,导致数据丢了,那么RDD会自动通过自己的数据来源重新计算该partition。
为了探究RDD内部的数据内容,可以利用collect()函数, 它能够以数组的形式,返回RDD数据集的所有元素。
>>> lines = ds.rdd
>>> for i in lines.collect():
... print i
...
Row(value=u'These examples give a quick overview of the Spark API. Spark is built on the concept of distributed datasets, which contain arbitrary Java or Python objects.')
lines存储的是Row object类型,而我们希望的是对String类型进行处理,所以需要利用map api进一步转换RDD
>>> lines_map = lines.map(lambda x: x[0])
>>> for i in lines_map.collect():
... print i
...
These examples give a quick overview of the Spark API. Spark is built on the concept of distributed datasets, which contain arbitrary Java or Python objects.
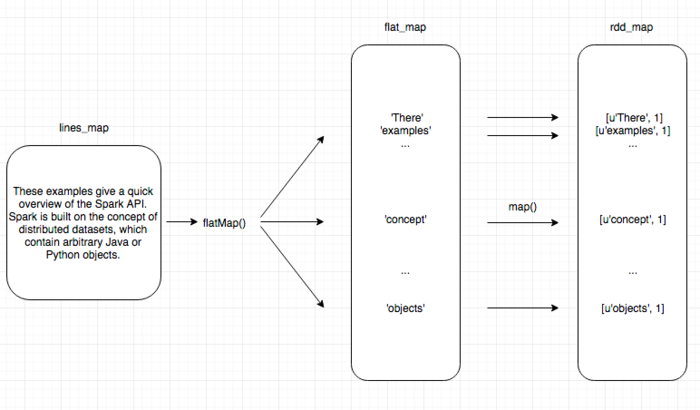
为了统计每个单词的出现频率,需要对每个单词分别统计,那么第一步需要将上面的字符串以空格作为分隔符将单词提取出来,并为每个词设置一个计数器。比如 These出现次数是1, 我们期望的数据结构是['There', 1]。但是如何将包含字符串的RDD转换成元素为类似 ['There', 1] 的RDD呢?
>>> flat_map = lines_map.flatMap(lambda x: x.split(' '))
>>> rdd_map = flat_map.map(lambda x: [x, 1])
>>> for i in rdd_map.collect():
... print i
...
[u'These', 1]
[u'examples', 1]
[u'give', 1]
[u'a', 1]
[u'quick', 1]
下图简要的讲述了flatMap 和 map的转换过程。
>>> from operator import add
>>> add_map = rdd_map.reduceByKey(add)
>>> for i in add_map.collect():
... print i
...
(u'a', 1)
(u'on', 1)
(u'of', 2)
(u'arbitrary', 1)
(u'quick', 1)
(u'the', 2)
(u'or', 1) >>> print rdd_map.count()
26
>>> print add_map.count()
23
根据a.txt 的内容,可知只有 of 和 the 两个单词出现了两次,符合预期。
总结
以上的分解步骤,可以帮我们理解RDD的操作,需要提示的是,RDD将操作分为两类:transformation与action。无论执行了多少次transformation操作,RDD都不会真正执行运算,只有当action操作被执行时,运算才会触发。也就是说,上面所有的RDD都是通过collect()触发的, 那么如果将上述的transformation放入一条简练语句中, 则展现为原始wordcount.py的书写形式。
counts = lines.flatMap(lambda x: x.split(' ')) \
.map(lambda x: (x, 1)) \
.reduceByKey(add)
而真正的action 则是由collect()完成。
output = counts.collect()
至此,已经完成了对wordcount.py的深入剖析
转自:https://www.jianshu.com/p/067907b23546?winzoom=1
PySpark理解wordcount.py的更多相关文章
- 大话Spark(3)-一图深入理解WordCount程序在Spark中的执行过程
本文以WordCount为例, 画图说明spark程序的执行过程 WordCount就是统计一段数据中每个单词出现的次数, 例如hello spark hello you 这段文本中hello出现2次 ...
- Spark集群搭建简配+它到底有多快?【单挑纯C/CPP/HADOOP】
最近耳闻Spark风生水起,这两天利用休息时间研究了一下,果然还是给人不少惊喜.可惜,笔者不善JAVA,只有PYTHON和SCALA接口.花了不少时间从零开始认识PYTHON和SCALA,不少时间答了 ...
- python pyspark入门篇
一.环境介绍: 1.安装jdk 7以上 2.python 2.7.11 3.IDE pycharm 4.package: spark-1.6.0-bin-hadoop2.6.tar.gz 二.Setu ...
- win10下Anaconda3在虚拟环境python_version=3.5.3 中配置pyspark
1. 序经过了一天的修炼,深深被恶心了,在虚拟环境中配置pyspark花式报错,由于本人实在是不想卸载3.6版的python,所以硬刚了一天,终于摸清了配置方法,并且配置成功,不抱怨了,开讲: 2. ...
- 在Pycharm上编写WordCount程序
本篇博客将给大家介绍怎么在PyCharm上编写运行WordCount程序. 第一步 下载安装PyCharm 下载Pycharm PyCharm的下载地址(Linux版本).下载完成后你将得到一个名叫: ...
- Mac上pycharm集成pyspark
前提: 1.已经安装好spark.我的是spark2.2.0. 2.已经有python环境,我这边使用的是python3.6. 一.安装py4j 使用pip,运行如下命令: pip install p ...
- [PySpark] Build R&D environment
开发环境 基本操作 Ref:Spark的环境搭建 一.启动集群 先启动hadoop,再启动spark,查看启动后的状态:http://node-master:8080 start-all.sh sta ...
- Python __init__.py 作用详解
__init__.py 文件的作用是将文件夹变为一个Python模块,Python 中的每个模块的包中,都有__init__.py 文件. 通常__init__.py 文件为空,但是我们还可以为它增加 ...
- Spark运行在eclipse_使用PyDev和pyspark
一直想在eclipse上编写Spark程序,但是仿佛是因为spark的安装包提供了PS D:\software\spark-1.6.1-bin-hadoop2.6> .\bin\spark-su ...
随机推荐
- 福大软工 · BETA 版冲刺前准备之拖鞋旅游队
拖鞋旅游队BETA 版冲刺前准备 前言 队名:拖鞋旅游队 组长博客:https://www.cnblogs.com/Sulumer/p/10083834.html 本次作业:https://edu.c ...
- synchronized(四)
package com.bjsxt.base.sync005;/** * synchronized的重入 * @author alienware * */public class SyncDubbo1 ...
- switfmailer 邮件时间错误 处理
Warning: date(): It is not safe to rely on the system's timezone settings. You are *required* to use ...
- SpringBoot(二)thymeleaf模板的引入
接着上一次的配置 1.在pom文件中添加thymeleaf模板的引入, <dependency> <groupId>org.springframework.boot</g ...
- SQL注入之Sqli-labs系列第二十三关(基于过滤的GET注入)
开始挑战第二十三关(Error Based- no comments) 先尝试下单引号进行报错 再来利用and来测试下,加入注释符#,编码成%23同样的报错 再来试试--+,同样的效果 同样的,先看看 ...
- todolist待办事项
使用html/css原生js实现待办事项列表: 支持添加待办事项,删除待办事项,切换待办事项的状态(正在进行,已经完成) 支持对正在进行以及已经完成事项编辑(单击内容即可编辑) 源代码:链接:http ...
- 【Eigen开源库】linux系统如何安装使用Eigen库
code /* * File : haedPose.cpp * Coder: * Date : 20181126 * Refer: https://www.learnopencv.com/head-p ...
- 【Java】将字节转换成十六进制、BCD码输出
public class HexUtils { public static void main(String[] args) { byte []out = { 0, 1, 2, 3, 4, 5, 6, ...
- CodeForces - 1101G :(Zero XOR Subset)-less(线性基)
You are given an array a1,a2,…,an of integer numbers. Your task is to divide the array into the maxi ...
- SFM(structure from motion)学习记录(一)
visualSFM用法 添加图片 "File->Open Multi Images". 一次添加多幅图片 "SfM->Load NView Match&quo ...