day09 MapReduce
,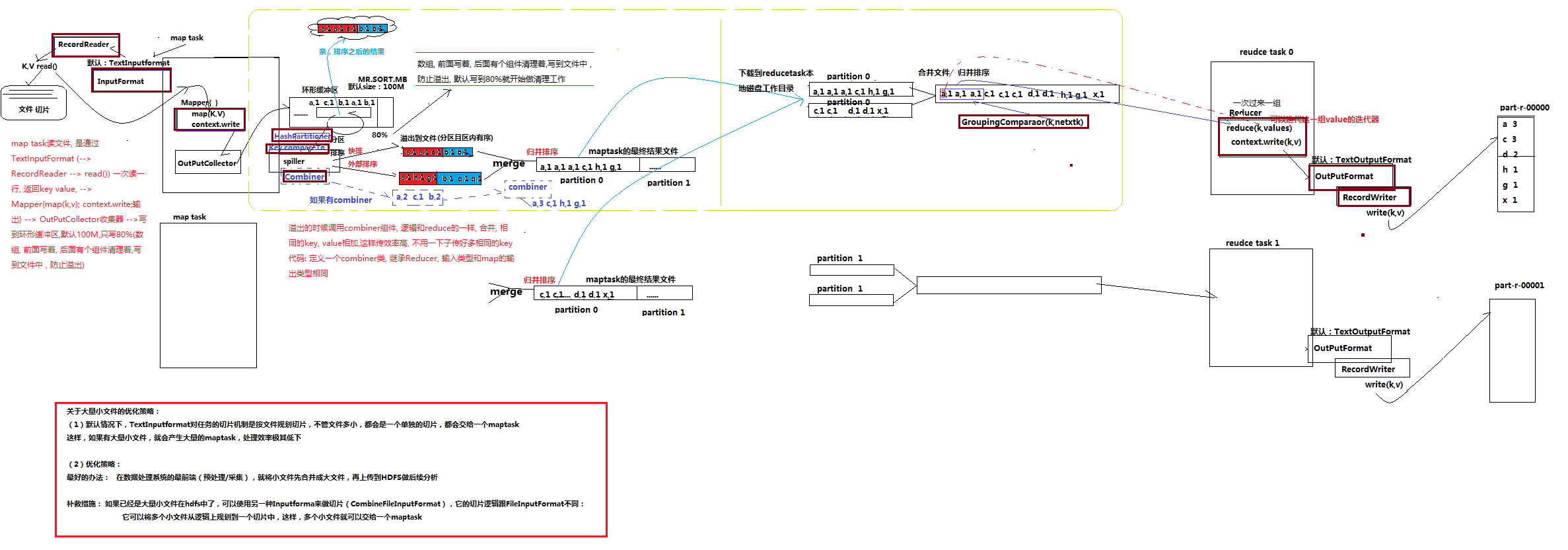
PS:上图为MapReduce原理全解剖, 图上带红色标识的部分是能够自定义的
1.首先要解决读文件的问题。 mapTask中有个read()方法,专门负责读取键值对,而且是整行整行的读
2.在读好文件以后,给到Mapper中的map方法,然后进入环形缓冲区(就是一个数组),该缓冲区满80%就溢出(溢出之前都排续好了)一个文件,溢出20% 分区排序,溢出部分用spllier收集数据,然多多个文件合并成一个大文件
3.合并数据 。 通过框架自带的组件,会把相同的key进行分组,继续合并文件,给reduce任务。reduce再通过框架内部写入HDFS
4.shuffle其实就是上图 黄色部分 ,红色部分可以自动完成, 黑色部分是由框架自动完成
--------------------------------------------
PS:Combinder就是如果有a,1.......好多,然后出来以后在中间就开始合并,这样就可以降低程序执行的效率,其实就是相当于提前Reduce。 其他执行的时候一直循环

package cn.itcast.bigdata.mr.wcdemo; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; /**
* 输如为map的-------------------提前合并文件
* @author: 张政
* @date: 2016年4月11日 下午7:08:18
* @package_name: day07.sample
*/
public class WordcountCombiner extends Reducer<Text, IntWritable, Text, IntWritable>{ @Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int count=;
for(IntWritable v: values){ count += v.get();
} context.write(key, new IntWritable(count)); } }

PS:当有很多小的切片文件的时候,使用combinder这样会减少开启 map的程序,提高效率,程序下面部分指定的开启的文件的大小范围;绑定类也可以不指定
------------------------------------MapReduce和yarn的工作机制
PS:yarn其实是就是一个类似虚拟化隔离的技术,好比我买的服务器要隔离开来,提供一种内部运算的机制,下图就是MapReduce和yarn的的执行顺序
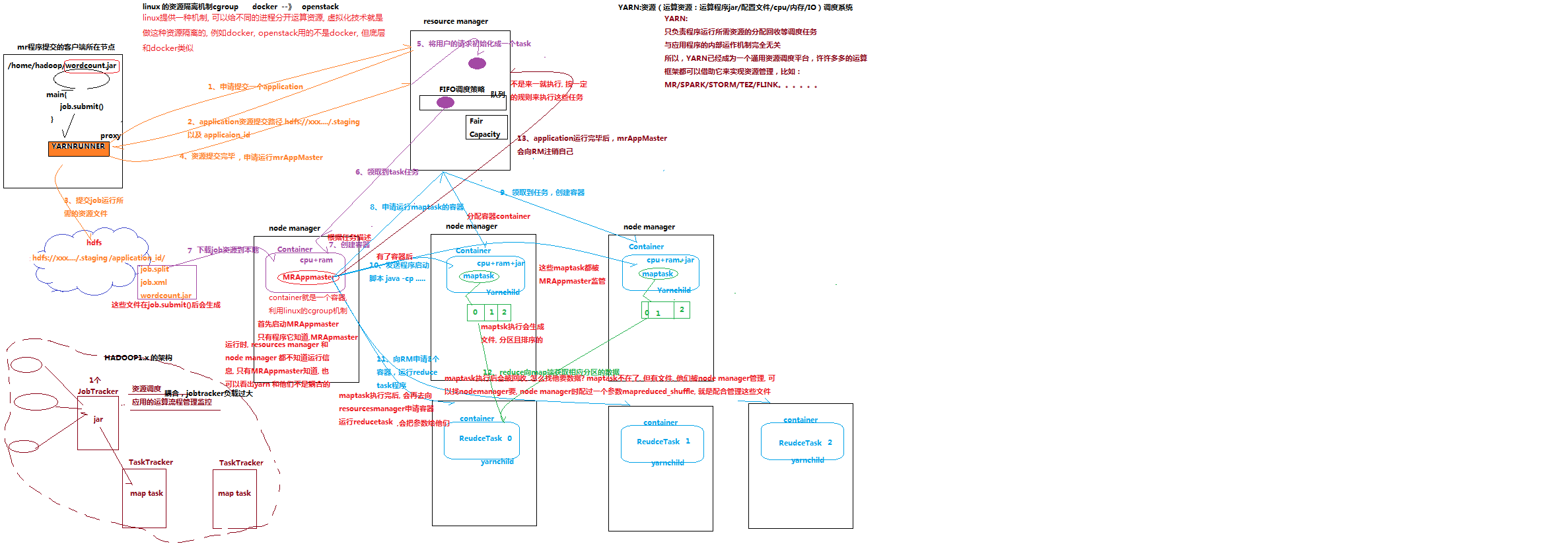
3.3. MapReduce与YARN
3.3.1 YARN概述---本身也是集群
Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而mapreduce等运算程序则相当于运行于操作系统之上的应用程序
3.3.2 YARN的重要概念
1、 yarn并不清楚用户提交的程序的运行机制
2、 yarn只提供运算资源的调度(用户程序向yarn申请资源,yarn就负责分配资源)
3、 yarn中的主管角色叫ResourceManager
4、 yarn中具体提供运算资源的角色叫NodeManager
5、 这样一来,yarn其实就与运行的用户程序完全解耦,就意味着yarn上可以运行各种类型的分布式运算程序(mapreduce只是其中的一种),比如mapreduce、storm程序,spark程序,tez ……
6、 所以,spark、storm等运算框架都可以整合在yarn上运行,只要他们各自的框架中有符合yarn规范的资源请求机制即可
7、 Yarn就成为一个通用的资源调度平台,从此,企业中以前存在的各种运算集群都可以整合在一个物理集群上,提高资源利用率,方便数据共享
-----------------------------
PS:
1.当主函数程序submit的时候,就会按照上述执行。
PS:
1.yarn是一种资源调度模式,MapReduce可以使用,其他的框架也可以使用。
2.2 MAPREDUCE程序运行模式
2.2.1 本地运行模式
(1)mapreduce程序是被提交给LocalJobRunner在本地以单进程的形式运行
(2)而处理的数据及输出结果可以在本地文件系统,也可以在hdfs上
(3)怎样实现本地运行?写一个程序,不要带集群的配置文件(本质是你的mr程序的conf中是否有mapreduce.framework.name=local以及yarn.resourcemanager.hostname参数)
(4)本地模式非常便于进行业务逻辑的debug,只要在eclipse中打断点即可
步骤:
1.如果在windows下想运行本地模式来测试程序逻辑,需要在windows中配置环境变量:
%HADOOP_HOME% = d:/hadoop-2.6.1
%PATH% = %HADOOP_HOME%\bin
并且要将d:/hadoop-2.6.1的lib和bin目录替换成windows平台编译的版本
2.添加测试参数
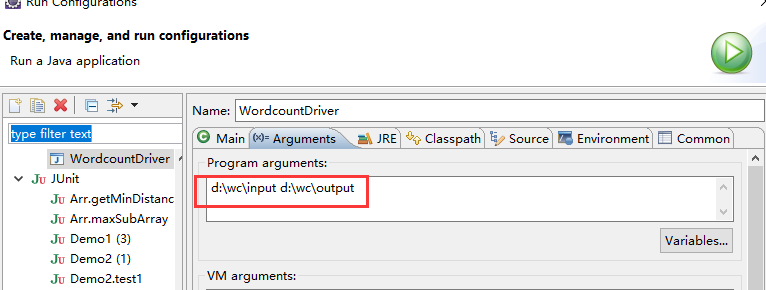
3.修改执行平台

4.文件夹 测试擦看,记得要编写测试数据
2.2.2 集群运行模式
(1)将mapreduce程序提交给yarn集群resourcemanager,分发到很多的节点上并发执行
(2)处理的数据和输出结果应该位于hdfs文件系统
(3)提交集群的实现步骤:
A、将程序打成JAR包,然后在集群的任意一个节点上用hadoop命令启动
$ hadoop jar wordcount.jar cn.itcast.bigdata.mrsimple.WordCountDriver inputpath outputpath
B、直接在linux的eclipse中运行main方法
(项目中要带参数:mapreduce.framework.name=yarn以及yarn的两个基本配置)
C、如果要在windows的eclipse中提交job给集群,则要修改YarnRunner类
PS:
通过对wordcount程序的调试,我明白程序先执行map阶段,再执行reduce阶段。
在map阶段,主要是对输入的键值对进行分组分割
在reduce节点,对每个以key为分组进行操作,最后汇总输出文件中
-------------------------------------------------------------------
2018-1-4 Java 也可以直接编译 jar包控制执行,下面对 在eclipse远程传递jar包,给集群运行,而不用命令(注意4个关键点)
package cn.itcast.bigdata.mr.wcdemo; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.CombineTextInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /**
* 相当于一个yarn集群的客户端
* 需要在此封装我们的mr程序的相关运行参数,指定jar包
* 最后提交给yarn
* @author
*
*/
public class WordcountDriver { public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); //是否运行为本地模式,就是看这个参数值是否为local,默认就是local
//conf.set("mapreduce.framework.name", "local"); //本地模式运行mr程序时,输入输出的数据可以在本地,也可以在hdfs上
//到底在哪里,就看以下两行配置你用哪行,默认就是file:///
/*conf.set("fs.defaultFS", "hdfs://mini1:9000/");*/
//conf.set("fs.defaultFS", "file:///"); //运行集群模式,就是把程序提交到yarn中去运行
//要想运行为集群模式,以下3个参数要指定为集群上的值, 第一点 ,要么把hadoop配置文件放入项目上
conf.set("mapreduce.framework.name", "yarn");
conf.set("yarn.resourcemanager.hostname", "192.168.8.10");
conf.set("fs.defaultFS", "hdfs://192.168.8.10:9000/");
Job job = Job.getInstance(conf); job.setJar("d:/wordcount.jar"); //第二点
//指定本程序的jar包所在的本地路径
//job.setJarByClass(WordcountDriver.class); //指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class); //指定mapper输出数据的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class); //指定最终输出的数据的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); //指定需要使用combiner,以及用哪个类作为combiner的逻辑
/*job.setCombinerClass(WordcountCombiner.class);*/
job.setCombinerClass(WordcountReducer.class); //如果不设置InputFormat,它默认用的是TextInputformat.class
job.setInputFormatClass(CombineTextInputFormat.class);
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);
CombineTextInputFormat.setMinInputSplitSize(job, 2097152); //指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
//指定job的输出结果所在目录
FileOutputFormat.setOutputPath(job, new Path(args[1])); //将job中配置的相关参数,以及job所用的java类所在的jar包,提交给yarn去运行
/*job.submit();*/
boolean res = job.waitForCompletion(true);
System.exit(res?0:1); } }
3.将该文件引入到项目中,包名都不能够改
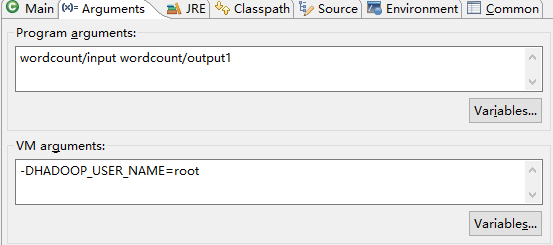
4.运行时的参数设置
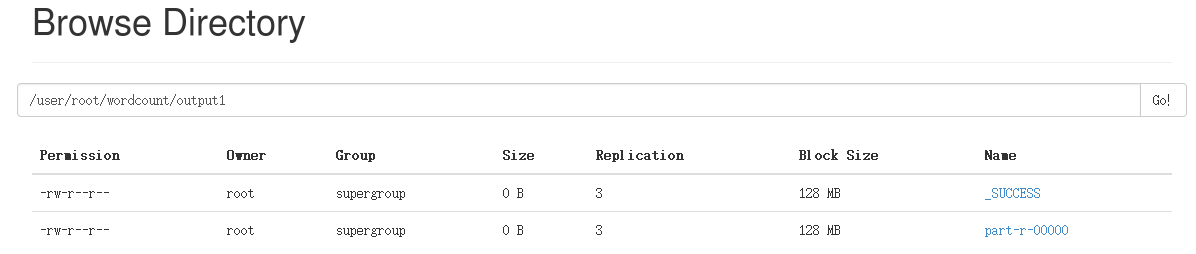
5.测试结果
------------------------------------------------------------------------------------------------------------------------------
1、需求:
订单数据表t_order:
|
id |
date |
pid |
amount |
|
1001 |
20150710 |
P0001 |
2 |
|
1002 |
20150710 |
P0001 |
3 |
|
1002 |
20150710 |
P0002 |
3 |
商品信息表t_product
|
id |
pname |
category_id |
price |
|
P0001 |
小米5 |
1000 |
2 |
|
P0002 |
锤子T1 |
1000 |
3 |
假如数据量巨大,两表的数据是以文件的形式存储在HDFS中,需要用mapreduce程序来实现一下SQL查询运算:
|
select a.id,a.date,b.name,b.category_id,b.price from t_order a join t_product b on a.pid = b.id |
2、实现机制:
通过将关联的条件作为map输出的key,将两表满足join条件的数据并携带数据所来源的文件信息,发往同一个reduce task,在reduce中进行数据的串联
package cn.itcast.bigdata.mr.rjoin; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; import org.apache.hadoop.io.Writable; public class InfoBean implements Writable { private int order_id;
private String dateString;
private String p_id;
private int amount;
private String pname;
private int category_id;
private float price; // flag=0表示这个对象是封装订单表记录
// flag=1表示这个对象是封装产品信息记录
private String flag; public InfoBean() {
} public void set(int order_id, String dateString, String p_id, int amount, String pname, int category_id, float price, String flag) {
this.order_id = order_id;
this.dateString = dateString;
this.p_id = p_id;
this.amount = amount;
this.pname = pname;
this.category_id = category_id;
this.price = price;
this.flag = flag;
} public int getOrder_id() {
return order_id;
} public void setOrder_id(int order_id) {
this.order_id = order_id;
} public String getDateString() {
return dateString;
} public void setDateString(String dateString) {
this.dateString = dateString;
} public String getP_id() {
return p_id;
} public void setP_id(String p_id) {
this.p_id = p_id;
} public int getAmount() {
return amount;
} public void setAmount(int amount) {
this.amount = amount;
} public String getPname() {
return pname;
} public void setPname(String pname) {
this.pname = pname;
} public int getCategory_id() {
return category_id;
} public void setCategory_id(int category_id) {
this.category_id = category_id;
} public float getPrice() {
return price;
} public void setPrice(float price) {
this.price = price;
} public String getFlag() {
return flag;
} public void setFlag(String flag) {
this.flag = flag;
} /**
* private int order_id; private String dateString; private int p_id;
* private int amount; private String pname; private int category_id;
* private float price;
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(order_id);
out.writeUTF(dateString);
out.writeUTF(p_id);
out.writeInt(amount);
out.writeUTF(pname);
out.writeInt(category_id);
out.writeFloat(price);
out.writeUTF(flag); } @Override
public void readFields(DataInput in) throws IOException {
this.order_id = in.readInt();
this.dateString = in.readUTF();
this.p_id = in.readUTF();
this.amount = in.readInt();
this.pname = in.readUTF();
this.category_id = in.readInt();
this.price = in.readFloat();
this.flag = in.readUTF(); } @Override
public String toString() {
return "order_id=" + order_id + ", dateString=" + dateString + ", p_id=" + p_id + ", amount=" + amount + ", pname=" + pname + ", category_id=" + category_id + ", price=" + price + ", flag=" + flag;
} }
package cn.itcast.bigdata.mr.rjoin; import java.io.IOException;
import java.util.ArrayList; import org.apache.commons.beanutils.BeanUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /**
* 订单表和商品表合到一起
order.txt(订单id, 日期, 商品编号, 数量)
1001 20150710 P0001 2
1002 20150710 P0001 3
1002 20150710 P0002 3
1003 20150710 P0003 3
product.txt(商品编号, 商品名字, 价格, 数量)
P0001 小米5 1001 2
P0002 锤子T1 1000 3
P0003 锤子 1002 4
* @author: 张政
* @date: 2016-2016年4月15日-上午8:45:57
* @package_name: shizhan_03_hadoop
* @package_name: cn.itcast.bigdata.mr.rjoin
*/
public class RJoin { static class RJoinMapper extends Mapper<LongWritable, Text, Text, InfoBean> {
InfoBean bean = new InfoBean();
Text k = new Text();
/**
* 根据pid进行key的分组
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); FileSplit inputSplit = (FileSplit) context.getInputSplit(); //只是另一种获取文件的方式
String name = inputSplit.getPath().getName();
// 通过文件名判断是哪种数据
String pid = "";
if (name.startsWith("order")) {
String[] fields = line.split("\t");
// id date pid amount
pid = fields[2];
bean.set(Integer.parseInt(fields[0]), fields[1], pid, Integer.parseInt(fields[3]), "", 0, 0, "0"); } else {
String[] fields = line.split("\t");
// id pname category_id price
pid = fields[0];
bean.set(0, "", pid, 0, fields[1], Integer.parseInt(fields[2]), Float.parseFloat(fields[3]), "1"); }
k.set(pid);
context.write(k, bean);
} }
/**
* 针对相同的key进行操作,每一个key输出一行
* @author bee
*
*/
static class RJoinReducer extends Reducer<Text, InfoBean, InfoBean, NullWritable> { @Override
protected void reduce(Text pid, Iterable<InfoBean> beans, Context context) throws IOException, InterruptedException {
InfoBean pdBean = new InfoBean();//记录产品中的信息,一个产品只有一个
ArrayList<InfoBean> orderBeans = new ArrayList<InfoBean>(); for (InfoBean bean : beans) { //这个是根据pid进行分类
if ("1".equals(bean.getFlag())) { //产品的
try {
BeanUtils.copyProperties(pdBean, bean);
} catch (Exception e) {
e.printStackTrace();
}
} else {
InfoBean odbean = new InfoBean();
try {
BeanUtils.copyProperties(odbean, bean);
orderBeans.add(odbean);
} catch (Exception e) {
e.printStackTrace();
}
} } // 拼接两类数据形成最终结果
for (InfoBean bean : orderBeans) { bean.setPname(pdBean.getPname());
bean.setCategory_id(pdBean.getCategory_id());
bean.setPrice(pdBean.getPrice()); context.write(bean, NullWritable.get());
}
}
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); conf.set("mapred.textoutputformat.separator", "\t"); Job job = Job.getInstance(conf); // 指定本程序的jar包所在的本地路径
job.setJarByClass(RJoin.class);
//job.setJar("d:/rjoin.jar"); 这种是通过本地运行直接调试 ,不过我至今没成功,都是先上传到HDFS然后再二次执行 // 指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(RJoinMapper.class);
job.setReducerClass(RJoinReducer.class); // 指定mapper输出数据的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(InfoBean.class); // 指定最终输出的数据的kv类型
job.setOutputKeyClass(InfoBean.class);
job.setOutputValueClass(NullWritable.class); // 指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
// 指定job的输出结果所在目录
FileOutputFormat.setOutputPath(job, new Path(args[1])); // 将job中配置的相关参数,以及job所用的java类所在的jar包,提交给yarn去运行
/* job.submit(); */
boolean res = job.waitForCompletion(true);
System.exit(res ? 0 : 1); }
}
PS:简单的总结一下:
1.这两种方式首先都需要创建好 文件夹和待执行的文件。
2.当为 上传执行的时候 hadoop jar rjoin.jar cn.itcast.bigdata.mr.rjoin.RJoin /rjoin/input /rjoin/output 传入参数执行
当为eclipse远程执行的时候,现在本地生产jar包,然后再上传,注意上面的四点

---------------------day10
Map端的join,避免数据倾斜
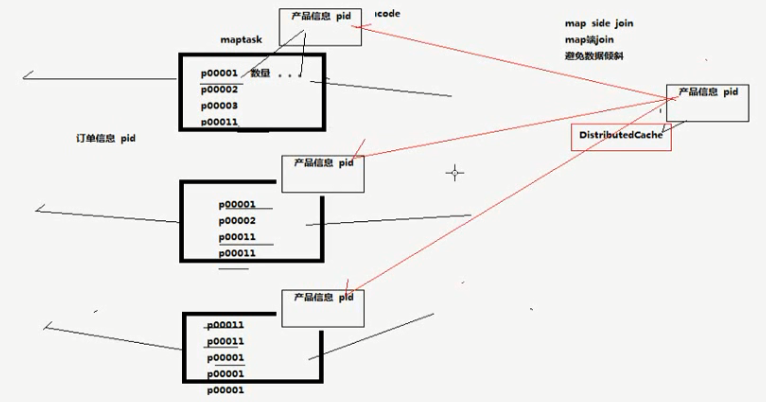
PS:思想就是在 DistributeCashe缓冲中,放置一个文件,每个map任务执行的时候都去取本地文件,在map端完成任务的执行。
下面看代码。 好好体会核心思想
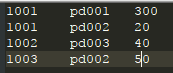
1001 pd001 300
1001 pd002 20
1002 pd003 40
1003 pd002 50

pd001,apple
pd002,banana
pd003,orange
package cn.itcast.bigdata.mr.mapsidejoin; import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.HashMap;
import java.util.Map; import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class MapSideJoin { public static class MapSideJoinMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
// 用一个hashmap来加载保存产品信息表
Map<String, String> pdInfoMap = new HashMap<String, String>(); Text k = new Text(); /**
* 通过阅读父类Mapper的源码,发现 setup方法是在maptask处理数据之前调用一次 可以用来做一些初始化工作
* 文件就放入Map阶段中
*/
@Override
protected void setup(Context context) throws IOException, InterruptedException {
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream("pdts.txt")));
String line;
while (StringUtils.isNotEmpty(line = br.readLine())) {
String[] fields = line.split(",");
pdInfoMap.put(fields[0], fields[1]);
}
br.close();
} // 由于已经持有完整的产品信息表,所以在map方法中就能实现join逻辑了
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String orderLine = value.toString();
String[] fields = orderLine.split("\t");
String pdName = pdInfoMap.get(fields[1]);//在表中查找到名字,然后给到赋值到一起
k.set(orderLine + "\t" + pdName);
context.write(k, NullWritable.get());
} } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(MapSideJoin.class); job.setMapperClass(MapSideJoinMapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class); FileInputFormat.setInputPaths(job, new Path("D:/tmp/mapjoininput"));
FileOutputFormat.setOutputPath(job, new Path("D:/tmp/output")); // 指定需要缓存一个文件到所有的maptask运行节点工作目录
/* job.addArchiveToClassPath(archive); */// 缓存jar包到task运行节点的classpath中
/* job.addFileToClassPath(file); */// 缓存普通文件到task运行节点的classpath中
/* job.addCacheArchive(uri); */// 缓存压缩包文件到task运行节点的工作目录
/* job.addCacheFile(uri) */// 缓存普通文件到task运行节点的工作目录 // 将产品表文件缓存到task工作节点的工作目录中去
job.addCacheFile(new URI("file:/D:/tmp/mapjoincache/pdts.txt")); //map端join的逻辑不需要reduce阶段,设置reducetask数量为0
job.setNumReduceTasks(0); boolean res = job.waitForCompletion(true);
System.exit(res ? 0 : 1); } }
day10
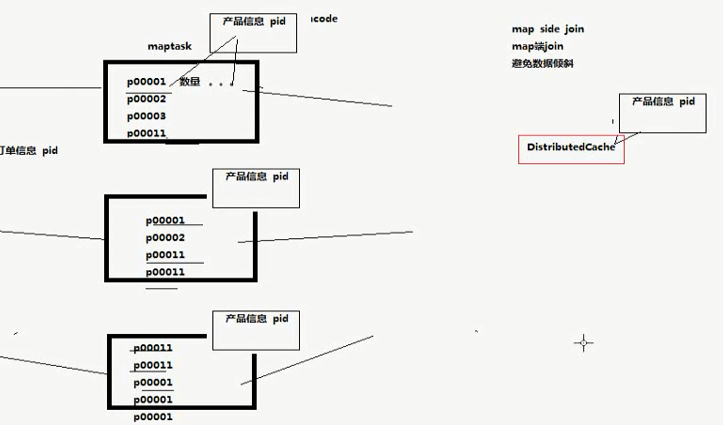
PS:如果map少,reducetask的任务多的话,就会引起数据倾斜, 一般通过map端的join来解决问题,那么mapReduce有个组件DistributedCache缓存来解决该问题



public class TestDistributedCache {
static class TestDistributedCacheMapper extends Mapper<LongWritable, Text, Text, Text>{
FileReader in = null;
BufferedReader reader = null;
HashMap<String,String> b_tab = new HashMap<String, String>();
String localpath =null;
String uirpath = null;
//是在map任务初始化的时候调用一次
@Override
protected void setup(Context context) throws IOException, InterruptedException {
//通过这几句代码可以获取到cache file的本地绝对路径,测试验证用
Path[] files = context.getLocalCacheFiles();
localpath = files[0].toString();
URI[] cacheFiles = context.getCacheFiles();
//缓存文件的用法——直接用本地IO来读取
//这里读的数据是map task所在机器本地工作目录中的一个小文件
in = new FileReader("b.txt");
reader =new BufferedReader(in);
String line =null;
while(null!=(line=reader.readLine())){
String[] fields = line.split(",");
b_tab.put(fields[0],fields[1]);
}
IOUtils.closeStream(reader);
IOUtils.closeStream(in);
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//这里读的是这个map task所负责的那一个切片数据(在hdfs上)
String[] fields = value.toString().split("\t");
String a_itemid = fields[0];
String a_amount = fields[1];
String b_name = b_tab.get(a_itemid);
// 输出结果 1001 98.9 banan
context.write(new Text(a_itemid), new Text(a_amount + "\t" + ":" + localpath + "\t" +b_name ));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(TestDistributedCache.class);
job.setMapperClass(TestDistributedCacheMapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//这里是我们正常的需要处理的数据所在路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//不需要reducer
job.setNumReduceTasks(0);
//分发一个文件到task进程的工作目录
job.addCacheFile(new URI("hdfs://hadoop-server01:9000/cachefile/b.txt"));
//分发一个归档文件到task进程的工作目录
// job.addArchiveToClassPath(archive);
//分发jar包到task节点的classpath下
// job.addFileToClassPath(jarfile);
job.waitForCompletion(true);
}
}
PS : 倒排索引,分为两步的MapReduce
package cn.itcast.bigdata.mr.inverindex; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class InverIndexStepOne { static class InverIndexStepOneMapper extends Mapper<LongWritable, Text, Text, IntWritable> { Text k = new Text();
IntWritable v = new IntWritable(1); @Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] words = line.split(" "); FileSplit inputSplit = (FileSplit) context.getInputSplit();
String fileName = inputSplit.getPath().getName();
for (String word : words) {
k.set(word + "--" + fileName);
context.write(k, v); } } } static class InverIndexStepOneReducer extends Reducer<Text, IntWritable, Text, IntWritable> { @Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int count = 0;
for (IntWritable value : values) { count += value.get();
} context.write(key, new IntWritable(count)); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf);
job.setJarByClass(InverIndexStepOne.class); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); FileInputFormat.setInputPaths(job, new Path("D:/srcdata/inverindexinput"));
FileOutputFormat.setOutputPath(job, new Path("D:/temp/out"));
// FileInputFormat.setInputPaths(job, new Path(args[0]));
// FileOutputFormat.setOutputPath(job, new Path(args[1])); job.setMapperClass(InverIndexStepOneMapper.class);
job.setReducerClass(InverIndexStepOneReducer.class); job.waitForCompletion(true); } }
Ps:分解完的形式,第一步是这个样式
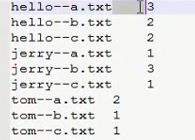
package cn.itcast.bigdata.mr.inverindex; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class IndexStepTwo {
public static class IndexStepTwoMapper extends Mapper<LongWritable, Text, Text, Text>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] files = line.split("--");
context.write(new Text(files[0]), new Text(files[1]));
}
}
public static class IndexStepTwoReducer extends Reducer<Text, Text, Text, Text>{
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
StringBuffer sb = new StringBuffer();
for (Text text : values) {
sb.append(text.toString().replace("\t", "-->") + "\t");
}
context.write(key, new Text(sb.toString()));
}
}
public static void main(String[] args) throws Exception { if (args.length < 1 || args == null) {
args = new String[]{"D:/temp/out/part-r-00000", "D:/temp/out2"};
} Configuration config = new Configuration();
Job job = Job.getInstance(config); job.setMapperClass(IndexStepTwoMapper.class);
job.setReducerClass(IndexStepTwoReducer.class);
// job.setMapOutputKeyClass(Text.class);
// job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class); FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 1:0);
}
}
PS: 第二部是这样的形式 ,就得到了想要的结果

以下是qq的好友列表数据,冒号前是一个用,冒号后是该用户的所有好友(数据中的好友关系是单向的)
A:B,C,D,F,E,O
B:A,C,E,K
C:F,A,D,I
D:A,E,F,L
E:B,C,D,M,L
F:A,B,C,D,E,O,M
G:A,C,D,E,F
H:A,C,D,E,O
I:A,O
J:B,O
K:A,C,D
L:D,E,F
M:E,F,G
O:A,H,I,J
求出哪些人两两之间有共同好友,及他俩的共同好友都有谁?
解题思路:
|
第一步 map 读一行 A:B,C,D,F,E,O 输出 <B,A><C,A><D,A><F,A><E,A><O,A> 在读一行 B:A,C,E,K 输出 <A,B><C,B><E,B><K,B> REDUCE 拿到的数据比如<C,A><C,B><C,E><C,F><C,G>...... 输出: <A-B,C> <A-E,C> <A-F,C> <A-G,C> <B-E,C> <B-F,C>..... 第二步 map 读入一行<A-B,C> 直接输出<A-B,C> reduce 读入数据 <A-B,C><A-B,F><A-B,G>....... 输出: A-B C,F,G,..... |
package cn.itcast.bigdata.mr.fensi; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class SharedFriendsStepOne { static class SharedFriendsStepOneMapper extends Mapper<LongWritable, Text, Text, Text> { @Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// A:B,C,D,F,E,O
String line = value.toString();
String[] person_friends = line.split(":");
String person = person_friends[0];
String friends = person_friends[1]; for (String friend : friends.split(",")) { // 输出<好友,人>
context.write(new Text(friend), new Text(person));
} } } static class SharedFriendsStepOneReducer extends Reducer<Text, Text, Text, Text> { @Override
protected void reduce(Text friend, Iterable<Text> persons, Context context) throws IOException, InterruptedException { StringBuffer sb = new StringBuffer(); for (Text person : persons) {
sb.append(person).append(","); }
context.write(friend, new Text(sb.toString()));
} } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf);
job.setJarByClass(SharedFriendsStepOne.class); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class); job.setMapperClass(SharedFriendsStepOneMapper.class);
job.setReducerClass(SharedFriendsStepOneReducer.class); FileInputFormat.setInputPaths(job, new Path("D:/srcdata/friends"));
FileOutputFormat.setOutputPath(job, new Path("D:/temp/out")); job.waitForCompletion(true); } }

package cn.itcast.bigdata.mr.fensi; import java.io.IOException;
import java.util.Arrays; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class SharedFriendsStepTwo { static class SharedFriendsStepTwoMapper extends Mapper<LongWritable, Text, Text, Text> { // 拿到的数据是上一个步骤的输出结果
// A I,K,C,B,G,F,H,O,D,
// 友 人,人,人
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString();
String[] friend_persons = line.split("\t"); String friend = friend_persons[0];
String[] persons = friend_persons[1].split(","); Arrays.sort(persons); for (int i = 0; i < persons.length - 1; i++) {
for (int j = i + 1; j < persons.length; j++) {
// 发出 <人-人,好友> ,这样,相同的“人-人”对的所有好友就会到同1个reduce中去
context.write(new Text(persons[i] + "-" + persons[j]), new Text(friend));
} } } } static class SharedFriendsStepTwoReducer extends Reducer<Text, Text, Text, Text> { @Override
protected void reduce(Text person_person, Iterable<Text> friends, Context context) throws IOException, InterruptedException { StringBuffer sb = new StringBuffer(); for (Text friend : friends) {
sb.append(friend).append(" "); }
context.write(person_person, new Text(sb.toString()));
} } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf);
job.setJarByClass(SharedFriendsStepTwo.class); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class); job.setMapperClass(SharedFriendsStepTwoMapper.class);
job.setReducerClass(SharedFriendsStepTwoReducer.class); FileInputFormat.setInputPaths(job, new Path("D:/temp/out/part-r-00000"));
FileOutputFormat.setOutputPath(job, new Path("D:/temp/out2")); job.waitForCompletion(true); } }
day09 MapReduce的更多相关文章
- Mapreduce的文件和hbase共同输入
Mapreduce的文件和hbase共同输入 package duogemap; import java.io.IOException; import org.apache.hadoop.co ...
- mapreduce多文件输出的两方法
mapreduce多文件输出的两方法 package duogemap; import java.io.IOException; import org.apache.hadoop.conf ...
- mapreduce中一个map多个输入路径
package duogemap; import java.io.IOException; import java.util.ArrayList; import java.util.List; imp ...
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- [Hadoop in Action] 第5章 高阶MapReduce
链接多个MapReduce作业 执行多个数据集的联结 生成Bloom filter 1.链接MapReduce作业 [顺序链接MapReduce作业] mapreduce-1 | mapr ...
- MapReduce
2016-12-21 16:53:49 mapred-default.xml mapreduce.input.fileinputformat.split.minsize 0 The minimum ...
- 使用mapreduce计算环比的实例
最近做了一个小的mapreduce程序,主要目的是计算环比值最高的前5名,本来打算使用spark计算,可是本人目前spark还只是简单看了下,因此就先改用mapreduce计算了,今天和大家分享下这个 ...
- MapReduce剖析笔记之八: Map输出数据的处理类MapOutputBuffer分析
在上一节我们分析了Child子进程启动,处理Map.Reduce任务的主要过程,但对于一些细节没有分析,这一节主要对MapOutputBuffer这个关键类进行分析. MapOutputBuffer顾 ...
- MapReduce剖析笔记之七:Child子进程处理Map和Reduce任务的主要流程
在上一节我们分析了TaskTracker如何对JobTracker分配过来的任务进行初始化,并创建各类JVM启动所需的信息,最终创建JVM的整个过程,本节我们继续来看,JVM启动后,执行的是Child ...
随机推荐
- centos7 克隆 网卡无法启用
1.克隆后查看网卡无法启用,报错信息如下: Apr :: agent systemd: network.service: control process exited, code=exited sta ...
- 【转载】Qt中图像的显示与基本操作
Qt可显示基本的图像类型,利用QImage.QPxmap类可以实现图像的显示,并且利用类中的方法可以实现图像的基本操作(缩放.旋转). 参考:Qt中图像的显示与基本操作 - ykm0722的专栏 - ...
- SQL-28 查找描述信息中包括robot的电影对应的分类名称以及电影数目,而且还需要该分类对应电影数量>=5部
题目描述 film表 字段 说明 film_id 电影id title 电影名称 description 电影描述信息 CREATE TABLE IF NOT EXISTS film ( film_i ...
- mysql 给表和字段加注释
给表加注释: ALTER TABLE table_name COMMENT='这是表的注释'; 给列加注释: ALTER table table_name MODIFY `column_name` d ...
- [rancher-net]
ip rule命令 rancher网络全解读 arp命令查询 rancher managed network 实践 docker自定义网桥 iptables增删改查 shell脚本调试技术
- Oracle 定时器
我的代码 declare job number; begin dbms_job.submit( JOB=>job, what=>'addBytime;',// 这里要写分号,不然容易出错. ...
- css3宽高设置:calc() / vw / vh
对于720px的设计稿,100vw == 720px,1vw == 7.2px; vw可以替代rem 实现自适应布局. 相应的计算插件:postcss-px-to-viewport ******** ...
- dos命令:系统命令
系统命令 一.mode命令 1.介绍 配置系统设备. 2.语法 串行端口: MODE COMm[:] [BAUD=b] [PARITY=p] [DATA=d] [STOP=s] [to=on|off] ...
- springboot区分开发、测试、生产多环境的应用配置
转:https://blog.csdn.net/daguairen/article/details/79236885 springboot区分开发.测试.生产多环境的应用配置(一) Spring可使用 ...
- Microsoft Project 常用快捷键
任务升级 : ALT + SHIFT + 向左键 任务降级: ALT + SHIFT + 向右键 滚动到表头(第一个任务):Ctrl + HOME 滚动到表尾(最后一个任务):Ctrl + E ...