爬虫之scrapy
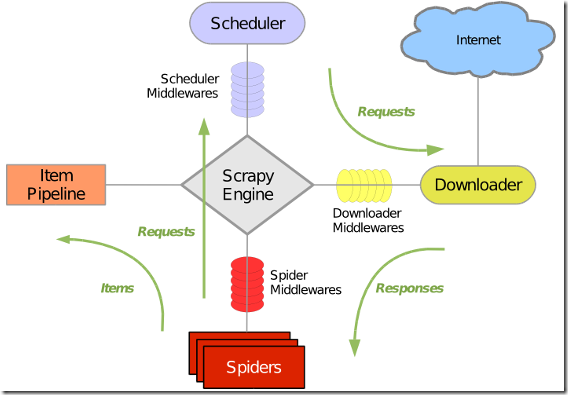
一、项目简单流程
1、创建项目
scrapy startproject 项目名
2、创建Spider
cd 项目名
scrapy genspider 爬虫名 域名
class YokaSpider(scrapy.Spider):
name = 'yoka'
allowed_domains = ['www.yoka.com/fashion/']
start_urls = ['http://www.yoka.com/fashion/'] def parse(self,response):
pass
创建的Spider类需继承scrapy.Spider
name:爬虫名
allowed_domains:允许爬取的域名,不在域名下的请求链接会被过滤掉
start_urls:Spider启动时爬取的url列表,初始请求由它来定义
parse:默认情况下, start_urls里的链接请求完成下载后,返回的响应就会作为唯一的参数传递给这个函数。该方法负责解析返回的响应、提取数据、进一步生成要处理的请求
3、创建Item
Item是保存爬取数据的容器,使用方法和字典类似,不过多了额外的保护机制,可以避免拼写错误和定义字段错误
创建的Item类需继承scrapy.Item,并定义类型为scrapy.Field的字段
class YokadapeiItem(scrapy.Item):
text= scrapy.Field()
tags=scrapy.Field()
4、解析Response
5、使用Item
①实例化 item=YokadapeiItem()
②赋值item['text']=... item['tags']=...
③yield item
6、后续Request
使用scrapy.Request方法
yield scrapy.Request(url=请求连接,callback=回调函数)
7、运行
scrapy crawl 爬虫名
8、保存到文件
scrapy crawl 爬虫名 -o 文件名.后缀名(json、csv、xml等)
9、使用Item Pipeline
Item生成后,会自动被送到Item Pipeline进行处理
Item Pipeline的作用
①清理HTML数据
②验证爬取数据,检查爬取字段
③查重并丢弃重复内容
④将爬取结果保存到数据库
实现Item Pipeline
①定义一个类并实现process_item()方法 ---必须返回包含数据的字典或Item对象,或抛出DropItem异常
该方法有两个参数,第一个是item,每次Spider生成的Item都会作为参数传过来,第二个是spider,就是Spider的实例
接下来,我们是实现一个Item Pipeline筛调长度大于25的title
from scrapy.exceptions import DropItem class TestSPipeline(object):
def __init__(self):
self.limit=25
def process_item(self, item, spider):
#判断该字段是否存在
if item['title']:
if len(item['title']) > self.limit:
item['title']=item['title'][0:self.limit].rstrip() + '...'
return item
else:
return DropItem("Missing title")
②将处理后的item存入MySQL
创建MysqlPipeline类
import pymsql class MysqlPipeline(object):
def __init__(self,mysql_host,mysql_port,mysql_db,mysql_user,mysql_password,mysql_table):
self.mysql_host=mysql_host
self.mysql_port=mysql_port
self.mysql_db=mysql_db
self.mysql_table=mysql_table
self.mysql_user=mysql_user
self.mysql_password=mysql_password #类方法,用classmethod标识,通过参数crawler拿到全局配置的每个配置信息
#再settings中我们可以定义MYSQL_HOST和MYSQL_PORT等来指定MySQL连接需要的地址和端口等信息
@classmethod
def from_crawler(cls,crawler):
return cls(
mysql_host=crawler.settings.get('MYSQL_HOST'),
mysql_port=crawler.settings.get('PORT'),
mysql_db=crawler.settings.get('MYSQL_DB'),
mysql_user=crawler.settings.get('MYSQL_USER'),
mysql_password=crawler.settings.get('MYSQL_PASSWORD'),
mysql_table=crawler.settings.get('MYSQL_TABLE'),
) def open_spider(self,spider):
self.conn = pymysql.connect(host=self.mysql_host,port=self.mysql_port,
user=self.mysql_user,password=self.mysql_password,
database=self.mysql_db,charset='utf8')
self.cur=self.conn.cursor() def process_item(self,item,spider):
dc=dict(item)
for v in dc.values():
sql="insert into %s (title) values ('%s')"%(self.mysql_table,v)
self.cur.execute(sql)
self.conn.commit()
return item def close_spider(self,spider):
self.conn.close()
在配置文件settings中
#数字越小越先被调用
ITEM_PIPELINES = {
'test_s.pipelines.TestSPipeline': 300,
'test_s.pipelines.MysqlPipeline':400,
}
MYSQL_HOST='localhost'
MYSQL_PORT='3306'
MYSQL_DB='scrapy'
MYSQL_TABLE='titles'
MYSQL_USER='root'
MYSQL_PASSWORD='123456'
二、Selector的用法
xpath、css、正则
三、Spider的用法
1、Spider运行流程 ---Spider主要做两件事[1]、定义爬取网站的动作 [2]、分析爬取下来的网页
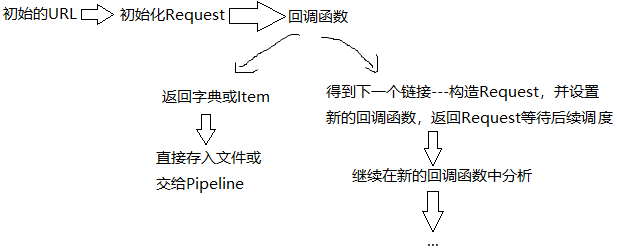
2、Spider类 ---提供了start_requests()方法的默认实现 -> 读取start_urls属性,并根据返回的结果调用parse()方法解析结果
属性:
①name:爬虫名称
②allowed_domains:允许爬虫的域名
③start_urls:起始URL列表,当没有实现start_requests()时,默认会从这个列表开始抓取
③custom_settings:字典,专属本Spider的配置,覆盖项目全局的设置。此设置必须在初始化之前被更新,必须定义成类变量
④crawler:由from_crawler()方法设置的,代表本Spider类对应的Crawler对象,利用它可以获取项目的一些配置信息
⑤settings;Settings对象,可以直接获取项目的全局设置变量
方法:
①start_requests():生成初始请求,必须返回一个可迭代对象。默认使用start_urls里的URL来构造Request(GET请求方式),
若想以POST方式访问某个站点,可以直接重写该方法,发送POST请求时使用FormRequest
②parse():当Response没有指定回调函数时,该方法会默认被调用。该方法需返回一个包含Request或Item的可迭代对象
③closed():当Spider关闭时,该方法会被调用
四、Downloader Middleware的用法
Scrapy内置了许多Downloader Middleware,被定义在DOWNLOADER_MIDDLEWARES_BASE变量中,
可以在settings修改DOWNLOADER_MIDDLEWARES以及禁用(将该中间件优先级设置为None)内置的Downloader Middleware
在整个架构中的位置为:
①在Request执行下载之前对其进行修改
②在生成Response被Spider解析之前对其进行修改
可以修改User-Agent、处理重定向、设置代理、失败重试、设置Cookies等
核心方法有三个:process_request(request,spider)、process_response(request,response,spider)、process_exception(request,exception,spider)
实现至少一个方法,就可以定义一个Downloader Middleware
1、process_request(request,spider)
在Request从队列里调度出来到Downloader下载执行之前,都可以用process_request()方法对Request进行处理
参数:①request:Request对象,即被处理的Request
②spider:Spider对象,即此Request对应的Spider
---返回值必须为None、Response对象、Request对象 之一,或抛出IgnoreRequest异常
①返回None时,不同的Downloader Middleware按照设置的优先级顺序依次对Request进行修改,最后送至Downloader执行
②返回Response对象时,更低优先级的Downloader Middleware的process_request()和process_exception()不会继续调用,每个Downloader Middleware的process_response()依次被调用,调用完毕后,直接将Response对象发送给Spider来处理
③返回Request对象时,更低优先级的Downloader Middleware的process_request()停止执行,该Request会重新放到调度队列里,相当于全新的Request
④IgnoreRequest异常抛出,所有的Downloader Middleware的process_exception()依次执行,若没有一个方法处理该异常,那么Request的errorback()方法就会回调。如果该异常还没有被处理,那么它便会被忽略
2、process_response(request,response,spider)
参数:①request:Request对象,此Response对应的Request
②response:Response对象,此被处理的Response
③spider:Spider对象,此Response对应的Spider
不同的返回情况:
①返回Request对象时,更低优先级的Downloader Middleware的process_response()不会被调用,该Request会重新放到调度队列里,相当于全新的Request
②返回Response对象时,更低优先级的Downloader Middleware的process_response()继续调用,继续对该Response对象进行处理
③IgnoreRequest异常抛出,则Request的errorback()方法就会回调。如果该异常还没有被处理,那么它便会被忽略
3、process_exception(request,exception,spider)
参数:①request:Request对象,产生异常的Request
②exception:Exception对象,即抛出的异常
③spider:Spider对象,即Request对应的Spider
不同的返回情况:
①返回为None时,更低优先级的Downloader Middleware的process_exception()会被继续调用,直到所有的方法都被调度完毕
②返回Response对象时,更低优先级的Downloader Middleware的process_exception()不再继续调用,每个Downloader Middleware的process_response()转而被依次调用
③返回Request对象时,更低优先级的Downloader Middleware的process_exception()也不再继续调用,该Request会重新放到调度队列里,相当于全新的Request
4、实战:
在parse()中可以用 response.request.headers 查看请求头信息
如 b'User-Agent': [b'Scrapy/1.5.1 (+https://scrapy.org)'], 使用的Use-Agent是Scrapy/1.5.1 (+https://scrapy.org),它是由Scrapy内置的UserAgentMiddleware设置的
from scrapy import signals class UserAgentMiddleware(object):
"""This middleware allows spiders to override the user_agent""" def __init__(self, user_agent='Scrapy'):
self.user_agent = user_agent @classmethod
def from_crawler(cls, crawler):
o = cls(crawler.settings['USER_AGENT'])
crawler.signals.connect(o.spider_opened, signal=signals.spider_opened)
return o def spider_opened(self, spider):
self.user_agent = getattr(spider, 'user_agent', self.user_agent) def process_request(self, request, spider):
if self.user_agent:
request.headers.setdefault(b'User-Agent', self.user_agent)
修改User-Agent有两种方式①直接修改在settings的USER_AGENT变量 ②通过Downloader Middleware的process_request()来修改
如需设置随机的User-Agent,需要使用第二种方法
class RandomUserAgentMiddleware(object):
def __init__(self):
self.user_agents = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10"
]
def process_request(self, request, spider):
request.headers['User-Agent']=random.choice(self.user_agents)
Downloader Middleware组件非常重要,是做异常处理和应对反爬处理的核心。后面将用它来处理代理、Cookies等内容
五、Spider Middleware的用法
和Downloader Middleware一样,Scrapy内置了许多Spider Middleware,被定义在SPIDER_MIDDLEWARES_BASE变量中,
可以在settings修改SPIDER_MIDDLEWARES,会和SPIDER_MIDDLEWARES_BASE定义的Spider Middleware合并
在整个架构中的位置为:
①在Response发送给Spider之前对Response进行处理
②在Request发送给Scheduler之前对Request进行处理
③在Item发送给Item Pipeline之前对Item进行处理
核心方法有四个:process_spider_input(response,spider)、process_spider_output(response,result,spider)、process_spider_exception(response,exception,spider)、process_start_request(start_request,spider),实现至少一个方法,就可以定义一个Spider Middleware
1、process_spider_input(response,spider)
当Response被Spider Middleware处理时,process_spider_input()被调用
参数:①response:Response对象,即被处理的Response
②spider:Spider对象,即该Response对应的Spider
不同的返回情况:
①返回None时,Scrapy将会继续处理该Response,调用所有其他的Spider Middleware,直到Spider处理该Response
②抛出异常时,Scrapy将不会调用任何其他的Spider Middleware的process_spider_input(),而调用Request的errback(),errback的输出将重新输入到中间件中,使用process_spider_output()来处理,当其抛出异常时则调用process_spider_exception()来处理
2、process_spider_output(response,result,spider)
当Spider处理Response返回结果时,process_spider_output()被调用
参数:①response:Response对象,即生成该输出的Response
②result:包含Request或Item对象的可迭代对象,即Spider返回的结果
③spider:Spider对象,即其结果对应的Spider
该方法必须返回包含Request或Item对象的可迭代对象。
3、process_spider_exception(response,exception,spider)
当Spider或Spider Middleware的process_spider_input()抛出异常时,process_spider_exception()被调用
参数:①response:Response对象,即异常被抛出时被处理的Response
②exception:Exception对象,即被抛出的异常
③spider:Spider对象,即抛出该异常的Spider
不同的返回情况:
①返回None时,Scrapy将会继续处理该异常,调用其他Spider Middleware中的process_spider_exception(),直到所有的Spider Middleware都被调用
②返回包含Request或Item对象的可迭代对象时,则其他Spider Middleware中的process_spider_output()被调用,其他的process_spider_exception()不会被调用
4、process_start_request(start_request,spider)
该方法以Spider启动的Request为参数时被调用,执行过程类似于process_spider_output(),不过没有相关联的Response,并且必须返回Request
参数:①start_request:包含Request的可迭代对象,即Start Request
②spider:Spider对象,即Start Request所属的Spider
该方法必须返回另一个包含Request对象的可迭代对象
Spider Middleware的使用频率不如Downloader Middleware高,在必要的情况下它可以用来方便数据的处理
六、Item Pipeline的用法
当Spider解析完Response之后,Item就会传递到Item Pipeline,被定义的Item Pipeline组件会顺次调用。
Item Pipeline的作用:
①清理HTML数据
②验证爬取数据,检查爬取字段
③查重并丢弃重复内容
④将爬取结果保存到数据库
核心方法有四个,必须要实现process_item(item,spider),其他还有几个比较实用的方法,open_spider(spider)、close_spider(spider)、from_crawler(cls,crawler)
1、process_item(item,spider)
被定义的Item Pipeline会默认调用该方法对Item进行处理
参数:①item:Item对象,即被处理的Item
②spider:Spider对象,即生成该Item的Spider
不同的返回情况:
①返回Item对象时,此Item会被更低优先级的Item Pipeline的process_item()处理,直到所有的方法被调用完毕
②抛出DropItem异常,那么此Item会被丢弃,不再进行处理
2、open_spider(spider)
该方法实在Spider开启的时候被自动调用的。我们可以在这里做一些初始化操作,如开启数据库连接等
参数:spider:被开启的Spider对象
3、close_spider(spider)
该方法实在Spider关闭的时候被自动调用的。我们可以在这里做一些收尾工作,如关闭数据库连接等
参数:spider:被关闭的Spider对象
4、from_crawler(cls,crawler)
类方法,用@classmethod标识,是一种依赖注入的方式。
参数:①crawler:通过crawler对象,我们可以拿到Scrapy的所有核心组件,如全局配置的每个信息,然后创建一个Pipeline实例
②cls:就是Class
最后返回一个Class实例
七、通用爬虫
1、CrawlSpider
CrawlSpider继承Spider类,除了Spider类的所有属性和方法,还提供了非常重要的属性和方法
①rules:爬取规则的属性,包含一个或多个Rule对象的列表。每个Rule对爬取网站的动作都做了定义,CrawlSpider会读取rules的每一个Rule并进行解析
②parse_start_url():可重写的方法。当start_urls里对应的Request得到Response时,该方法被调用,它会分析Response并返回Item对象或者Request对象
最重要的是Rule的定义:
scrapy.contrib.spiders下的Rule类
class Rule(object):
def __init__(self, link_extractor, callback=None, cb_kwargs=None, follow=None, process_links=None, process_request=identity):
参数:
①link_extractor:Link Extractor对象,通过它提取链接并自动生成Request。它又是一个数据结构,常用LxmlLinkExtractor对象作为参数。
scrapy.linkextractors.lxmlhtml下的LxmlLinkExtractor类
class LxmlLinkExtractor(FilteringLinkExtractor):
def __init__(self, allow=(), deny=(), allow_domains=(), deny_domains=(), restrict_xpaths=(),
tags=('a', 'area'), attrs=('href',), canonicalize=False,
unique=True, process_value=None, deny_extensions=None, restrict_css=(),
strip=True):
[1]、allow是正则表达式或正则表达式列表,符合的链接才被跟进,deny则相反
[2]、allow_domains是域名白名单,deny_domains则相反
[3]、restrict_xpaths、restrict_css xpath和css表达式或其列表,用xpath或css提取链接
②callback:回调函数,注意,避免使用parse()作为回调函数
③cb_kwargs:字典,包含传递给回调函数的参数
④follow:布尔值,指定根据该规则从response提取的链接是否需要跟进。若callback为None,follow默认为True,否则默认为False
⑤process_links:指定处理函数,从link_extractor中获取链接列表时,该函数将会调用,主要用于过滤
⑥process_request:同样指定处理函数,根据该Rule提取到每个Request时,该函数都会调用,对Request进行处理。该函数必须返回Request或None
2、Item Loader
Item提供的是保存抓取数据的容器,Item Loader提供的是填充容器的机制。数据的提取会变得更加规则化。
scrapy.loader下的ItemLoader类
class ItemLoader(object):
default_item_class = Item
default_input_processor = Identity()
default_output_processor = Identity()
default_selector_class = Selector
def __init__(self, item=None, selector=None, response=None, parent=None, **context):
返回一个新的Item Loader来填充给定的Item,若没有给出Item,则使用中的类自动实例化default_item_class,用selector、response来使用选择器或响应参数实例化
参数:
①item:Item对象,可以调用add_xpath()、add_css()、add_value()等方法来填充Item对象
②selector:Selector对象,用来提取填充数据的选择器
③response:Response对象,用于使用构造选择器的Response
本文参考文献:[1]崔庆才.python3网络爬虫开发实战[M].北京:人民邮电出版社,2018:468-541.
爬虫之scrapy的更多相关文章
- 教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http://www.xiaohuar.com/,让你体验爬取校花的成就感. Scr ...
- 爬虫之scrapy框架
解析 Scrapy解释 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓 ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- 爬虫入门scrapy
Python之路[第十九篇]:爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用 ...
- 爬虫框架Scrapy
前面十章爬虫笔记陆陆续续记录了一些简单的Python爬虫知识, 用来解决简单的贴吧下载,绩点运算自然不在话下. 不过要想批量下载大量的内容,比如知乎的所有的问答,那便显得游刃不有余了点. 于是乎,爬虫 ...
- 97、爬虫框架scrapy
本篇导航: 介绍与安装 命令行工具 项目结构以及爬虫应用简介 Spiders 其它介绍 爬取亚马逊商品信息 一.介绍与安装 Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, ...
- 第三篇:爬虫框架 - Scrapy
前言 Python提供了一个比较实用的爬虫框架 - Scrapy.在这个框架下只要定制好指定的几个模块,就能实现一个爬虫. 本文将讲解Scrapy框架的基本体系结构,以及使用这个框架定制爬虫的具体步骤 ...
- 网络爬虫框架Scrapy简介
作者: 黄进(QQ:7149101) 一. 网络爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本:它是一个自动提取网页的程序,它为搜索引擎从万维 ...
- Linux 安装python爬虫框架 scrapy
Linux 安装python爬虫框架 scrapy http://scrapy.org/ Scrapy是python最好用的一个爬虫框架.要求: python2.7.x. 1. Ubuntu14.04 ...
- 爬虫框架Scrapy 之(一) --- scrapy初识
Scrapy框架简介 scrapy是基于Twisted的一个第三方爬虫框架,许多功能已经被封装好,方便提取结构性的数据.其可以应用在数据挖掘,信息处理等方面.提供了许多的爬虫的基类,帮我们更简便使用爬 ...
随机推荐
- python的面试问题
WHAT 1. 什么是Python? Python是一种编程语言,它有对象.模块.线程.异常处理和自动内存管理.可以加入与其他语言的对比.下面是回答这一问题的几个关键点: a. Python是一种解释 ...
- IS基础(函数片)
函数基本介绍 为什么需要函数 之所以需要函数,是因为函数可以实现对代码的复用.相同的代码,我们不需要再重复书写,只需要书写一次就足够了.函数有些时候可以看做是一个暗箱.我们不需要知道函数内部是怎么实现 ...
- asd短片数篇
黄乙己 黄乙己是站着AK而正常的唯一的人.他身材挺高大:蜡黄脸色,眼角间时常夹着些饼干屑:一副黑色的眼镜.虽然挺正常,可是他有良好的饮食习惯,似乎十多个月都是吃的牛奶泡饭,也没有洗饭盒.他对人说话,总 ...
- Python练习十一
1.写一个程序,提示输入整数X,然后计算从1到X连续整数的和. num = int(input('please the input number:')) sum_num = 0 for i in ra ...
- PythonStudy——nonlocal关键字
# 作用:将局部的变量提升为嵌套局部变量# 1.必须有同名嵌套局部变量,就是统一嵌套局部与局部的同名变量# -- 如果局部想改变嵌套局部变量的值(发生地址的变化),可以用nonlocal声明该变量 d ...
- 在linxu机器ansible上运行启动django项目命令
source py3env/bin/activate 进入虚拟环境 cd /xiangmulujing 进入项目路径 然后就可以执行运行命令了 python manage.py runser ...
- 谷歌浏览器可以google了
做为一个开发者好多疑问点或者难点大多数时间 都在进行百度,百度也能解决问题,但是呢如果让我能够google呢?我肯定会优先google的,这里面能够搜到一些国外技术人的文章可供参考. 下面是一个能够支 ...
- zabbix和iptables的nat表结合使用
A 机器要去访问C机器,但是无法直接访问到A可以访问到B机器,B机器可以访问到C机器这时候就可以再B机器设置nat,让A机器访问C机器 正好工作中zabbix server要监控2个http地址,缺无 ...
- Django学习笔记之视图高级-HTTP请求与响应
Django限制请求method 常用的请求method GET请求 GET请求一般用来向服务器索取数据,但不会向服务器提交数据,不会对服务器的状态进行更改.比如向服务器获取某篇文章的详情. POST ...
- java中增删改查(CRUD)总结
对于User表增删改查:1:save(保存方法) view(查询所有记录) update(更新方法) delete(删除方法) 通过method这个参数进行判断执行不同的操作 2: 具体的实现: ...