浅析 Bag of Feature
Bag of Feature 是一种图像特征提取方法,它借鉴了文本分类的思路(Bag of Words),从图像抽象出很多具有代表性的「关键词」,形成一个字典,再统计每张图片中出现的「关键词」数量,得到图片的特征向量。

Bag of Words 模型
要了解「Bag of Feature」,首先要知道「Bag of Words」。
「Bag of Words」 是文本分类中一种通俗易懂的策略。一般来讲,如果我们要了解一段文本的主要内容,最行之有效的策略是抓取文本中的关键词,根据关键词出现的频率确定这段文本的中心思想。比如:如果一则新闻中经常出现「iraq」、「terrorists」,那么,我们可以认为这则新闻应该跟伊拉克的恐怖主义有关。而如果一则新闻中出现较多的关键词是「soviet」、「cuba」,我们又可以猜测这则新闻是关于冷战的(见下图)。

这里所说的关键词,就是「Bag of words」中的 words ,它们是区分度较高的单词。根据这些 words ,我们可以很快地识别出文章的内容,并快速地对文章进行分类。
而「Bag of Feature」也是借鉴了这种思路,只不过在图像中,我们抽出的不再是一个个「word」,而是图像的关键特征「Feature」,所以研究人员将它更名为「Bag of Feature」。
Bag of Feature 算法
从上面的讨论中,我们不难发现,「Bag of Feature」的本质是提出一种图像的特征表示方法。
按照「Bag of Feature」算法的思想,首先我们要找到图像中的关键词,而且这些关键词必须具备较高的区分度。实际过程中,通常会采用「SIFT」特征。
有了特征之后,我们会将这些特征通过聚类算法得出很多聚类中心。这些聚类中心通常具有较高的代表性,比如,对于人脸来说,虽然不同人的眼睛、鼻子等特征都不尽相同,但它们往往具有共性,而这些聚类中心就代表了这类共性。我们将这些聚类中心组合在一起,形成一部字典(CodeBook)。
对于图像中的每个「SIFT」特征,我们能够在字典中找到最相似的聚类中心,统计这些聚类中心出现的次数,可以得到一个向量表示(有些文章称之为「直方图」),如本文开篇的图片所示。这些向量就是所谓的「Bag」。这样,对于不同类别的图片,这个向量应该具有较大的区分度,基于此,我们可以训练出一些分类模型(SVM等),并用其对图片进行分类。
Bag of Feature 算法过程
「Bag of Feature」大概分为四步:
- 提取图像特征;
- 对特征进行聚类,得到一部字典( visual vocabulary );
- 根据字典将图片表示成向量(直方图);
- 训练分类器或者用 KNN 进行检索(这一步严格来讲不属于「Bag of Feature」的范畴)。
下面,我们简单分析一下每一步的实现过程。
提取图像特征
特征必须具有较高的区分度,而且要满足旋转不变性以及尺寸不变性等,因此,我们通常都会采用「SIFT」特征(有时为了降低计算量,也会采用其他特征,如:SURF )。「SIFT」会从图片上提取出很多特征点,每个特征点都是 128 维的向量,因此,如果图片足够多的话,我们会提取出一个巨大的特征向量库。
训练字典( visual vocabulary )
提取完特征后,我们会采用一些聚类算法对这些特征向量进行聚类。最常用的聚类算法是 k-means。至于 k-means 中的 k 如何取,要根据具体情况来确定。另外,由于特征的数量可能非常庞大,这个聚类的过程也会非常漫长。
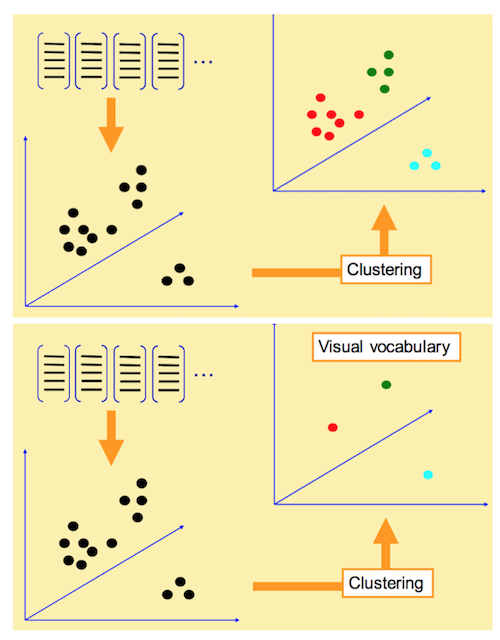
聚类完成后,我们就得到了这 k 个向量组成的字典,这 k 个向量有一个通用的表达,叫 visual word。
图片直方图表示
上一步训练得到的字典,是为了这一步对图像特征进行量化。对于一幅图像而言,我们可以提取出大量的「SIFT」特征点,但这些特征点仍然属于一种浅层(low level)的表达,缺乏代表性。因此,这一步的目标,是根据字典重新提取图像的高层特征。
具体做法是,对于图像中的每一个「SIFT」特征,都可以在字典中找到一个最相似的 visual word,这样,我们可以统计一个 k 维的直方图,代表该图像的「SIFT」特征在字典中的相似度频率。
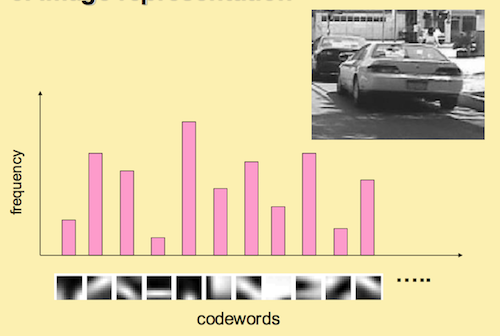
例如:对于上图这辆车的图片,我们匹配图片的「SIFT」向量与字典中的 visual word,统计出最相似的向量出现的次数,最后得到这幅图片的直方图向量。
训练分类器
当我们得到每幅图片的直方图向量后,剩下的这一步跟以往的步骤是一样的。无非是根据数据库图片的向量以及图片的标签,训练分类器模型。然后对需要预测的图片,我们仍然按照上述方法,提取「SIFT」特征,再根据字典量化直方图向量,用分类器模型对直方图向量进行分类。当然,也可以直接根据 KNN 算法对直方图向量做相似性判断。
Bag of Feature 在检索中的应用
「Bag of Feature」虽然是针对图像分类提出的算法,但它同样可以用到图像检索中。检索和分类本质上是同样的,但在细节上会有不同,事实上,我更愿意把检索当成一种精细分类,即得到图片的大致分类后,再在这个分类中找出最相似的图片。
「Bag of Feature」在检索中的算法流程和分类几乎完全一样,唯一的区别在于,对于原始的 BOF 特征,也就是直方图向量,我们引入 TF-IDF 权值。
TF-IDF
对 TF-IDF 的了解,我参考了吴军的《数学之美》一书。下面的解释,基本也是 copy 了书上的内容。
TF-IDF 最早是在文献检索领域中被提出的,下面我们就用一个文本检索的例子来了解 TF-IDF。
假设我们要检索关于「原子能的应用」的文章,最简单的做法就是将查询分解为「原子能」、「的」、「应用」,然后统计每篇文章中这三个词出现的频率。比如,如果一篇文章的总词数是 1000 ,其中「原子能」、「的」、「应用」分别出现了 2 次、35 次和 5 次,那么它们的词频就分别是 0.002、0.035、0.005。将这三个数相加,总和 0.042 就是该文章关于「原子能的应用」的「词频」。一般来说,词频越高,文章的相关性就越强。TF-IDF 中的 TF 也就是词频(Term Frequency)的意思。
但这种方法有一个明显的漏洞,就是一些跟主题不相关的词可能占据较大的比重。比如上面例子中的「的」一词,占据了总词频的 80% 以上,而这个词对主题的检索几乎没有作用。这种词我们称为「停止词(Stop Word)」,表明在度量相关性时不考虑它们的频率。忽略「的」之后,我们的词频变为 0.007,其中「原子能」贡献了 0.002,「应用」贡献了 0.007。
除此以外,这个优化后的结果还存在另一点不足。在汉语中,「应用」是个很通用的词,「原子能」是专业性很强的词,而后者对主题的检索比前者作用更大。
综合以上两点不足,我们需要对每一个词给一个权重。而且这个权重必须满足以下两个条件:
- 一个词对主题预测能力越强,权重越大;
- 停止词权重为 0;
观察一下我们就会发现,如果一个关键词只在很少的文章中出现,通过它就容易锁定搜索目标,它的权重就应该更大。反之,如果一个词在大量文章中频繁出现,看到它仍然不清楚要找什么内容,它的权重就应该小。
概括地讲,假定一个关键词 \(w\) 在 \(D_w\) 篇文章中出现过,那么 \(D_w\) 越大,\(w\) 的权重越小,反之亦然。在信息检索中,使用最多的权重是「逆文本频率指数」,也就是 TF-IDF 中的 IDF(Inverse Document Frequency)。它的公式为 \(log(\frac{D}{D_w})\),其中,\(D\) 是全部文章数。假定文章总数是 \(D=10\) 亿,停止词「的」在所有网页中都出现过,即 \(D_w=10\)亿,那么 它的 IDF = log(10亿 / 10亿) = log(1) = 0。假如「原子能」在 200万 篇文章中出现过,即 \(D_w=200\)万,那么它的 IDF = log(500) = 8.96。又假定通用词「应用」出现在 5亿 篇文章中,它的权重 IDF = log(2) = 1。
利用 IDF,我们得到一个更加合理的相关性计算公式:
\[
TF_1 * IDF_1+TF_2 * IDF_2+...+TF_N * IDF_N
\]
加权 BOF
TF-IDF 是通过增加权重的方法,凸显出重要的关键信息。同样的,在图像检索中,为了更精确地度量相似性,我们也在原来直方图向量的基础上,为向量的每一项增加权重。
具体的,按照上面信息检索的方法,我们需要给字典里的每个向量(visual word)设置权重。权重的计算方法如出一辙:IDF = \(log(\frac{N}{f_j})\),其中,\(N\) 是图片总数,\(f_j\) 表示字典向量 j 在 多少张图片上出现过。仿照上面的例子,我们可以这样理解:假设我们要检索汽车图片,而汽车一般是放在地面上的,也就是说,在众多类似图片中,地面对应的 visual word 应该会经常出现,而这种特征对于我们检索汽车而言是没有帮助的,所以,用 IDF 公式,我们可以把这个权重减小到忽略不计的地步,这样就把汽车本身的特征凸显出来。
假设我们按照前面 BOF 算法的过程已经得到一张图片的直方图向量 \(\mathbf h = {h_j} (j = 0, 1, …, k)\),那么,加权 BOF 的计算公式为:\(h_j = (h_j / \sum_{i}{h_i}) log(\frac{N}{f_j})\)。公式右边后一部分就是上面所讲到的 IDF,而 \((h_j / \sum_{i}{h_i})\) 就是词频 TF。
相似性度量方法
前面对 TF-IDF 的介绍,我们得到一个相对完善的向量表示方法。最后,再简单提一下如何根据这个向量确定图片之间的相似度。
关于向量相似度测量的方法有很多,最常见的是计算向量之间的欧几里得距离或者曼哈顿距离等。但在图像检索中,我们采用向量之间的夹角作为相似性度量方法。因为我们得到的向量是各个 visual word 综合作用的结果,对于同一类图片,它们可能受几个相同的 visual word 的影响较大,这样它们的特征向量大体上都会指向一个方向。而夹角越小的,证明向量之间应该越相似。
计算向量夹角的方法非常简单,可以直接采用余弦定理:
\[
s(\mathbf h, \overline{ \mathbf h}) =\frac{ <\mathbf h, \overline{\mathbf h}> }{ ||\mathbf h||\ ||\overline{\mathbf h}||}
\]
等式右边,分子表示向量内积,分母是向量模的乘积。
由于向量中的每一个变量都是正数,因此余弦值的取值在 0 和 1 之间。如果余弦值为 0,证明向量夹角为 90 度,则这两个向量的相关性很低,图片基本不相似。如果余弦值靠近 1,证明两个向量的夹角靠近 0 度,则两个向量的相关性很高,图片很相似。
更多关于向量相似性度量的方法,请参考其他文章。吴军老师的《数学之美》中也有更加详细的介绍。
Bag of Feature 的缺点
Bag of Feature 在提取特征时不需要相关的 label 进行学习,因此是一种弱监督的学习方法。当然,没有什么方法会是十全十美的,Bag of Feature 也存在一个明显的不足,那就是它完全没有考虑到特征之间的位置关系,而位置信息对于人理解图片来说,作用是很明显的。有不少学者也提出了针对该缺点的改进,关于改进的方法,这里就不再介绍了。
参考
浅析 Bag of Feature的更多相关文章
- 图像检索(2):均值聚类-构建BoF
在图像检索时,通常首先提取图像的局部特征,这些局部特征通常有很高的维度(例如,sift是128维),有很多的冗余信息,直接利用局部特征进行检索,效率和准确度上都不是很好.这就需要重新对提取到的局部特征 ...
- BoW算法及DBoW2库简介
由于在ORB-SLAM2中扩展图像识别模块,因此总结一下BoW算法,并对DBoW2库做简单介绍. 1. BoW算法 BoW算法即Bag of Words模型,是图像检索领域最常用的方法,也是基于内容的 ...
- 机器学习---文本特征提取之词袋模型(Machine Learning Text Feature Extraction Bag of Words)
假设有一段文本:"I have a cat, his name is Huzihu. Huzihu is really cute and friendly. We are good frie ...
- 视觉SLAM之词袋(bag of words) 模型与K-means聚类算法浅析
原文地址:http://www.cnblogs.com/zjiaxing/p/5548265.html 在目前实际的视觉SLAM中,闭环检测多采用DBOW2模型https://github.com/d ...
- 视觉SLAM之词袋(bag of words) 模型与K-means聚类算法浅析(1)
在目前实际的视觉SLAM中,闭环检测多采用DBOW2模型https://github.com/dorian3d/DBoW2,而bag of words 又运用了数据挖掘的K-means聚类算法,笔者只 ...
- 文本特征提取---词袋模型,TF-IDF模型,N-gram模型(Text Feature Extraction Bag of Words TF-IDF N-gram )
假设有一段文本:"I have a cat, his name is Huzihu. Huzihu is really cute and friendly. We are good frie ...
- 视觉SLAM之词袋(bag of words) 模型与K-means聚类算法浅析(2)
聚类概念: 聚类:简单地说就是把相似的东西分到一组.同 Classification (分类)不同,分类应属于监督学习.而在聚类的时候,我们并不关心某一类是什么,我们需要实现的目标只是把相似的东西聚到 ...
- netty5 HTTP协议栈浅析与实践
一.说在前面的话 前段时间,工作上需要做一个针对视频质量的统计分析系统,各端(PC端.移动端和 WEB端)将视频质量数据放在一个 HTTP 请求中上报到服务器,服务器对数据进行解析.分拣后从不同的 ...
- MATLAB 图像分类 Image Category Classification Using Bag of Features
使用MATLAB实现图像的识别,这是MATLAB官网上面的例子,学习一下. http://cn.mathworks.com/help/vision/examples/image-category-cl ...
随机推荐
- QT: 自定义断言;
使用Qt creator + mingw + gdb进行qt项目开发时,应用Q_ASSERT进行断言总是会出现问题: 断言失败,程序崩溃而不是停止: 采用自定义断言能完美解决该问题(方法取自于国外 ...
- Tensorflow object detection API 搭建物体识别模型(三)
三.模型训练 1)错误一: 在桌面的目标检测文件夹中打开cmd,即在路径中输入cmd后按Enter键运行.在cmd中运行命令: python /your_path/models-master/rese ...
- python while 格式化 运算符 编码
#######################总结############# 1. 循环 while 条件: 循环体(break, continue) 循环的执行过程: 执行到while的时候. 首先 ...
- @JsonFormat的导包问题
@DateTimeFormat(pattern = "yyyy-MM-dd hh:mm:ss")//注解可以以该格式注入格式@JsonFormat(locale="zh& ...
- 用过企业微信APP 后,微信接收不到消息,解决方案
用过企业微信APP 后,微信接收不到消息的,怎么办? 请打开企业微信,找到:我----设置----新消息通知----仅在企业微信中接收消息
- [Android] Android 卡片式控件CardView的优雅使用
[Android] Android 卡片式控件CardView的优雅使用 CardView是在安卓5.0提出的卡片式控件 其具体用法如下: 1.在app/build.gradle 文件中添加 comp ...
- Nginx 之六: Nginx服务器的正向及反向代理功能
一:Nginx作为正向代理服务器: 1.正向代理:代理(proxy)服务也可以称为是正向代理,指的是将服务器部署在公司的网关,代理公司内部员工上外网的请求,可以起到一定的安全作用和管理限制作用,正向代 ...
- mvn项目压缩打包
通常情况下,maven打包结果为jar或war包.如果需要一并打包配置文件等参数,通过resources配置指定需要打包的文件参数,如下示例: <project> ... <!-- ...
- GCC编译器原理(三)------编译原理三:编译过程(2-1)---编译之词法分析
二.编译 引用文档:https://blog.csdn.net/chdhust/article/details/9040647 编译过程就是把预处理完的文件进行一系列词法分析.语法分析.语义分析及优化 ...
- 【bzoj 1143】[CTSC2008]祭祀river
Description 在遥远的东方,有一个神秘的民族,自称Y族.他们世代居住在水面上,奉龙王为神.每逢重大庆典, Y族都会在水面上举办盛大的祭祀活动.我们可以把Y族居住地水系看成一个由岔口和河道组成 ...