Pandas数据去重和对重复数据分类、求和,得到未重复和重复(求和后)的数据
人的理想志向往往和他的能力成正比。 —— 约翰逊
其实整个需求呢,就是题目。2018-08-16
需求的结构图:
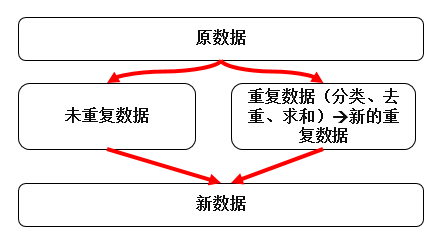
涉及的包有:pandas、numpy
1、导入包:
import pandas as pd
import numpy as np
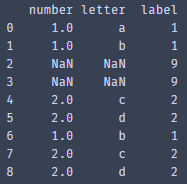
2、构造DataFrame,里面包含三种数据类型:int、null、str
data = {"number":[1,1,np.nan,np.nan,2,2,1,2,2],
"letter":['a','b',np.nan,np.nan,'c','d','b','c','d'],
"label":[1,1,9,9,2,2,1,2,2]}
dataset1 = pd.DataFrame(data) #初始化DataFrame 得到数据集dataset1
print(dataset1)
3、空值填充
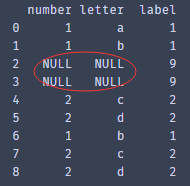
由于数据集里含有空值,为了能够对后面重复数据进行求和,则需要对空值进行填充
dataset = dataset1.fillna("NULL")
print(dataset)
4、利用duplicated()函数和drop_duplicates()函数对数据去重
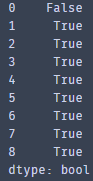
首先,利用duplicated()函数按列名'letter'和' number '取重复行,其返回的是bool类型,若为重复行则true,反之为false
duplicate_row = dataset.duplicated(subset=['letter',' number '],keep=False)
print(duplicate_row)
然后通过bool值取出重复行的数据
duplicate_data = dataset.loc[duplicate_row,:]
print(duplicate_data)
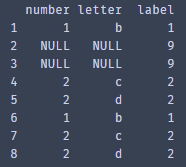
再然后根据'letter',' number '对重复数据进行分类,在该前提下并对重复数据的’label’进行求和,且重置索引(对后文中的赋值操作有帮助)
duplicate_data_sum = duplicate_data.groupby(by=['letter',' number ']).agg({' label ':sum}).reset_index(drop=True)
Print(duplicate_data_sum)

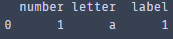
取出重复数据中的一个,例如:1,1,2,2——>1,2
对drop_duplicates指定列:subset=['letter',' number '],保留第一条重复的数据:keep="first"
duplicate_data _one= duplicate_data.drop_duplicates(subset=['letter',' number '] ,keep="first").reset_index(drop=True)
Print(duplicate_data)
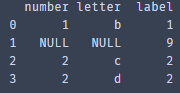
获取不重复的数据,指定列subset=['letter',' number ',' label '],不保留重复数据:keep=False
no_duplicate = dataset.drop_duplicates(subset=['letter',' number ',' label '] ,keep=False)
Print(no_duplicate)
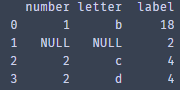
将对重复值的’label’求和,并赋值给“重复值中的一个”,得到新的”新重复值中的一个
duplicate_data _one ["label"] = duplicate_data_sum ['label'] #前面需要重置索引
print(duplicate_data_one)
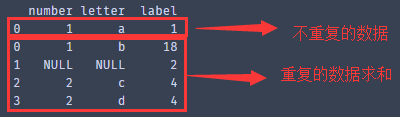
最后,拼接”新重复值中的一个”和不重复的数据
Result = pd.concat([no_duplicate,duplicate_data _one])
Print(result)
5、全体代码:
import pandas as pd
import numpy as np #构造DataFrame
data = {"number":[1,1,np.nan,np.nan,2,2,1,2,2],
"letter":['a','b',np.nan,np.nan,'c','d','b','c','d'],
"label":[1,1,9,9,2,2,1,2,2]}
dataset1 = pd.DataFrame(data) #空值填充
dataset = dataset1.fillna("NULL")
#得到重复行的索引
duplicate_row = dataset.duplicated(subset=['letter','number'],keep=False)
#得到重复行的数据
duplicate_data = dataset.loc[duplicate_row,:]
#重复行按''label''求和
duplicate_data_sum = duplicate_data.groupby(by=['letter','number']).agg({'label':sum}).reset_index(drop=True) #得到唯一的重复数据
duplicate_data_one= duplicate_data.drop_duplicates(subset=[
'letter','number'],keep="first").reset_index(drop=True)
#获得不重复的数据
no_duplicate = dataset.drop_duplicates(subset=['letter','number','label']
,keep=False)
#把重复行按"label"列求和的"label"列赋值给唯一的重复数据的"label"列
duplicate_data_one ["label"] = duplicate_data_sum ['label']
Result = pd.concat([no_duplicate,duplicate_data_one]
主要用到几个关键的函数:
Pandas.concat()
DataFrame.duplicated()
DataFrame.drop_duplicates().reset_index(drop=True)
DataFrame.groupby().agg({})
本人处于学习中,如有写的不够专业或者错误的地方,诚心希望各位读者多多指出!!
Pandas数据去重和对重复数据分类、求和,得到未重复和重复(求和后)的数据的更多相关文章
- [Hadoop]-从数据去重认识MapReduce
这学期刚好开了一门大数据的课,就是完完全全简简单单的介绍的那种,然后就接触到这里面最被人熟知的Hadoop了.看了官网的教程[吐槽一下,果然英语还是很重要!],嗯啊,一知半解地搭建了本地和伪分布式的, ...
- 利用MapReduce实现数据去重
数据去重主要是为了利用并行化的思想对数据进行有意义的筛选. 统计大数据集上的数据种类个数.从网站日志中计算访问地等这些看似庞杂的任务都会涉及数据去重. 示例文件内容: 此处应有示例文件 设计思路 数据 ...
- mySql数据重复数据去重
1.问题来源:数据中由于并发问题,数据存在多次调用接口,插入了重复数据,需要根据多条件删除重复数据: 2.参考博客文章地址:https://www.cnblogs.com/jiangxiaobo/p/ ...
- pandas-22 数据去重处理
pandas-22 数据去重处理 数据去重可以使用duplicated()和drop_duplicates()两个方法. DataFrame.duplicated(subset = None,keep ...
- map/reduce实现数据去重
import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.co ...
- MYSQL数据去重与外表填充
经常要对数据库中的数据进行去重,有时还需要使用外部表填冲数据,本文档记录数据去重与外表填充数据. date:2016/8/17 author:wangxl 1 需求 对user_info1表去重,并添 ...
- EXCEL技能之数据去重
本篇不属于技术类博文,只是想找个地方记录而已,既然是我的博客嘛,那就自己想写什么就写什么了. CRM中有个EXCEL数据导入功能,几千条数据导入CRM后去重,那是死的心都有的.往回想想EXCEL是否有 ...
- Oracle 分页查询与数据去重
1.rownum字段 Oracle下select语句每个结果集中都有一个伪字段(伪列)rownum存在.rownum用来标识每条记录的行号,行号从1开始,每次递增1.rownum是虚拟的顺序值,前提是 ...
- mssql sqlserver 三种数据表数据去重方法分享
摘要: 下文将分享三种不同的数据去重方法数据去重:需根据某一字段来界定,当此字段出现大于一行记录时,我们就界定为此行数据存在重复. 数据去重方法1: 当表中最在最大流水号时候,我们可以通过关联的方式为 ...
随机推荐
- MySQL/Oracle索引的创建与使用
MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度. 索引分单列索引和组合索引. 单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引 ...
- Https,Http,TCP,IP的一些理解
网络模型分为7层,应用层,表现层,会话层,传输层,网络层,链路层,物理层,每一层有很多不同的协议. http:属于应用层的协议,负责的是数据以什么结构传输也可以说成是打包成什么样子 SSL/TLS:属 ...
- docker容器下mysql更改WordPress的site address和home(URL)------局域网
先简单介绍下,用docker安装的WordPress,mysql是在docker容器中的,并未在Ubuntu(我把WordPress是安装Ubuntu系统上),即WordPress和Ubuntu是独立 ...
- HARD FAULT
程序陷在while(1)里面 解决办法 定点到发生死循环的位置 打开stack windows逐层查找发生死循环之前运行过的函数 导致原因 1 内存溢出或者访问越界,通常为数组或结构体访问越界.这个需 ...
- build.gradle
1.将Eclipse项目导入到Android studio 中 很多点9图出现问题解决方法: 在build.gradle里添加以下两句: aaptOptions.cruncherEnabled = f ...
- email program (客户端)演变过程有感
以下内容全部为个人读后感(参考百度百科的相关资料) 首先我认为电子邮件是一个非常伟大的发明,它不仅成本低,而且传输效率快! 关于它的起源,我从百度百科中看到了两种说法 1.1969年10月世界 ...
- attention 介绍
前言 这里学习的注意力模型是我在研究image caption过程中的出来的经验总结,其实这个注意力模型理解起来并不难,但是国内的博文写的都很不详细或说很不明确,我在看了 attention-mech ...
- JavaCV 学习(二):使用 JavaCV + FFmpeg 制作拉流播放器
一.前言 在 Android 音视频开发学习思路 中,我们不断的学习和了解音视频相关的知识,随着知识点不断的学习,我们现在应该做的事情,就是将知识点不断的串联起来.这样才能得到更深层次的领悟.通过整理 ...
- 站点的rel="alternate"属性
概述 今天看决战平安京官网源码,突然看到了rel的alternate属性,百度了一下,记录下来,供以后开发时参考,相信对其他人也有用. PC端rel 在pc版网页上,添加指向对应移动版网址的特殊链接r ...
- 控制页面打印的2种方法(css3的media媒体查询和window.print())
在实际开发中,有时可能会有打印的需求.下面我总结了2种打印的方法,希望对各位小伙伴有所帮助. ①:直接用window.print()方法就可以打印整个页面,下面是一个小demo <!DOCTYP ...