hadoop框架详解
Hadoop框架详解
Hadoop项目主要包括以下四个模块
◆ Hadoop Common:
为其他Hadoop模块提供基础设施
◆ Hadoop HDFS:
一个高可靠、高吞吐量的分布式文件系统
◆ Hadoop MapReduce:
一个分布式的离线并行计算框架
◆ Hadoop YARN:
一个新的MapReduce框架,任务调度与资源管理
Apache Hadoop起源
◆Apache Lucene
开源的高性能全文检索工具包
◆Apache Nutch
开源的Web搜索引擎
◆Google三大论文
MapReduce/GFS/BigTable
◆Apache Hadoop
大规模数据处理
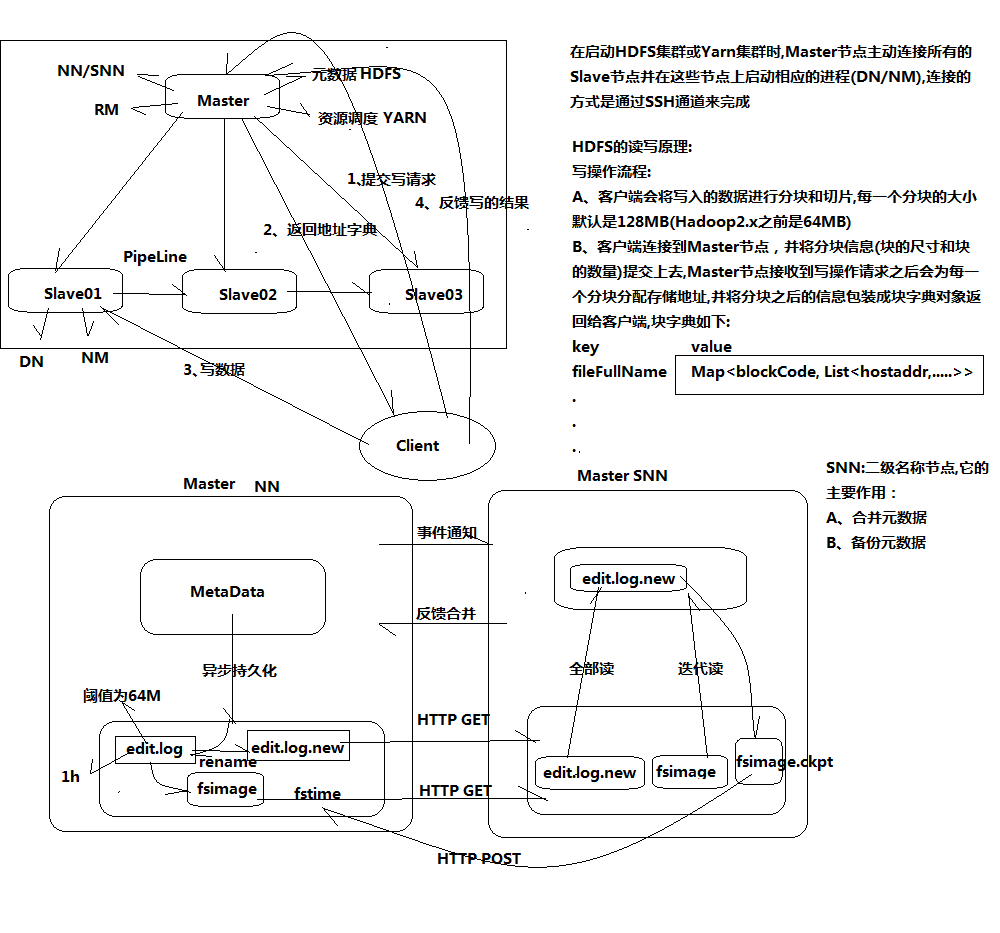
一张图了解分布式的好处(数据量达到500G就可以考虑使用大数据处理了)

HDFS
(HDFS即Hadoop Distributed File System分布式文件系统:主要是分布式存储数据)
——————-

HDFS服务功能
◆NameNode(NN)是主节点,存储文件的元数据如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个文件的块列表和块所在DataNode等。
◆DataNode(DN)在本地文件系统存储文件块数据,以及块数据的校验和。
◆Secondary NameNode(SNN) 用来监控HDFS状态的辅助后台程序,每隔一段时间获 取HDFS元数据的快照。
NameNode
◆Namenode 是一个中心服务器,单一节点(简化系统的设计和实现),负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。
◆文件操作,NameNode 负责文件元数据的操作,DataNode负责处理文件内容的读写请求,跟 文件内容相关的数据流不经过NameNode,只会询问它跟那个DataNode联系,否则 NameNode会成为系统的瓶颈。
◆副本存放在哪些DataNode上由 NameNode来控制,根据全局情况做出块放置决定,读取文件时NameNode尽量让用户先读取最近的副本,降低带块消耗和读取延时;
◆Namenode 全权管理数据块的复制,它周期性地从集群中的每个Datanode接收心跳信号和块状态报告(Blockreport)。接收到心跳信号意味着该Datanode节点工作正常。块状态报告包含了一个该Datanode上所有数据块的列表。
DataNode
◆一个数据块在DataNode以文件存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳 ;
◆DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息;
◆心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode 的心跳,则认为该节点不可用;
◆集群运行中可以安全加入和退出一些机器。
文件
◆文件切分成块(默认大小128M),以块为单位,每个块有多个副本存储在不同的机器上,副本数可在文件生成时指定(默认3,是在hdfs-site.xml中配置的);
◆NameNode 是主节点,存储文件的元数据如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个文件的块列表以及块所在的DataNode等等;
◆DataNode 在本地文件系统存储文件块数据,以及块数据的校验和。
◆可以创建、删除、移动或重命名文件,当文件创建、写入和关闭之后不能修改文件内容。
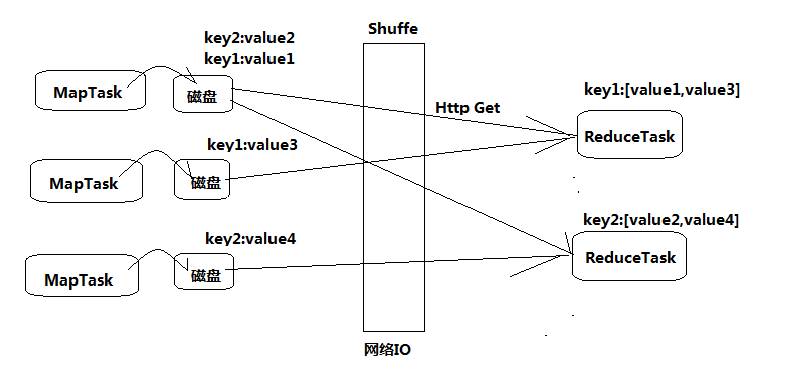
MapReduce计算框架
(基于磁盘IO进行迭代,开销较大)
◆将计算过程分为两个阶段:Map和Reduce
Map阶段并行处理输入数据 ;
Reduce阶段对Map结果进行汇总 ;
◆ Shuffle链接Map和Reduce两个阶段(Shuffle通俗的理解就是重新洗牌,打乱原有顺序)
Map Task将数据写到本地磁盘 ;
Reduce Task从每个Map Task上读取一份数据 ;
◆ 仅适合离线批处理
具有很好的容错性和扩展性 ;
适合简单的批处理任务 ;
◆ 缺点明显:
启动开销大,过多使用磁盘导致效率低下等;
map tasks的个数只要是看splitSize,一个文件根据splitSize分成多少份就有多少个map tasks。
该slave节点上有多少个MapTask运行,取决于该slave节点分配到了多少块(一般默认128M);
slave的cpu是几核的会影响MapTask是单线程还是多线程,及其运行效率;
如果它出现问题,挂掉,会将没运行完的块交给其它slave节点重新运算;
大数据学习交流群:217770236 让我我们一起学习大数据
【测试中如果遇到没有输出结果,只有输出目录的情况;那么很可能是犯了小错误;比如:Mapper中的输入键值必须是LongWriteable和Text;outKey和outValue的类型不对,或者没有初始化;Driver类中Job任务没提交;还有就是读取的文件中的数据在map中字段没有正确对应;数据中有的字段是脏数据,需要处理;导致匹配不成功,从而输出失败。 】
YARN服务组件
(主要是负责硬件资源的合理调用)
◆ YARN 总体上仍然是Master/Slave 结构,在整个资源管理框架中,ResourceManager 为Master,NodeManager 为Slave。
◆ ResourceManager 负责对各个NodeManager 上的资源进行统一管理和调度;
◆ 当用户提交一个应用程序时,需要提供一个用以跟踪和管理这个程序的ApplicationMaster(主管进程),它负责向ResourceManager 申请资源,并要求NodeManger 启动可以占用一定资源的任务。
◆ 由于不同的ApplicationMaster 被分布到不同的节点上,因此它们之间不会相互影响。
ResourceManager
◆ 全局的资源管理器,整个集群只有一个,负责集群资源的统一管理和调度分配。
◆ 功能
- 处理客户端请求
- 启动/监控ApplicationMaster
- 监控NodeManager
- 资源分配与调度
NodeManager
◆ 整个集群有多个,负责单节点资源管理和使用
◆ 功能:
- 单个节点上的资源管理和任务管理
- 处理来自ResourceManager的命令 (下文简称RM)
- 处理来自ApplicationMaster的命令
◆ NodeManager管理抽象容器,这些容器代表着可供一个特定应用程序使用的针对每个节点的资源。
◆ 定时地向RM汇报本节点上的资源使用情况和各个Container的运行状态
ApplicationManager
管理一个在YARN 内运行的应用程序的每个实例
◆ 功能
- 数据切分
- 为应用程序申请资源,并进一步分配给内部任务
- 任务监控与容错
◆ 负责协调来自ResourceManager的资源,幵通过NodeManager监视容器的执行和资源使用(CPU、内存等的资源分配)。
Container(容器)
◆ YARN中的资源抽象,封装某个节点上多维度资源,如内存、CPU、磁盘、网络等,当AM向RM申请资源时,RM向AM返回的资源便是用Container表示的。
◆ YARN 会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。
◆ 功能
- 对任务运行环境的抽象
- 描述一系列信息
- 任务启动命令
- 任务运行环境
----------------------------------
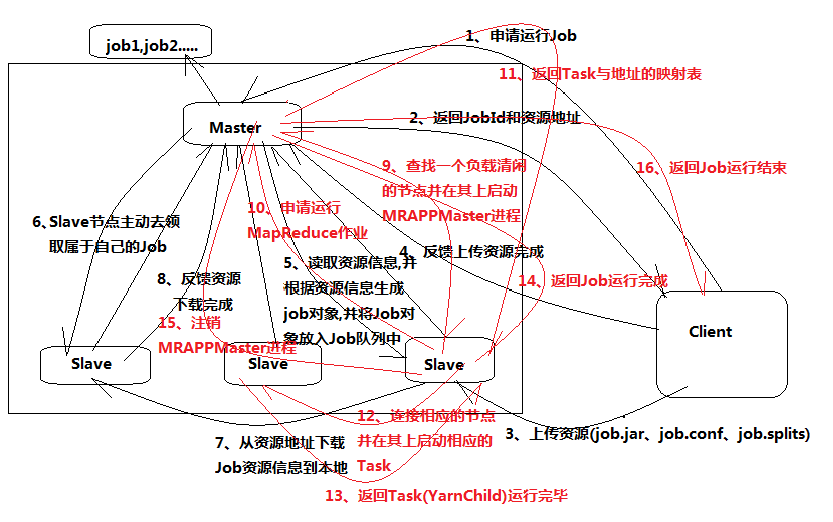
1、client---->master(申请运行job,链接的是RM进程)
2、master---->client(返回jobId和资源地址:提交的jar文件存放地址,配置信息conf地址,每个副本的spilt分配信息)
3、client---->slave03(根据资源地址链接slave节点,上传资源--job.jar/job.conf/job.spilt)
4、client---->master(反馈上传资源完成)
5、master---->slave03(读取之前上传的资源信息,根据资源信息生成job对象,并将job对象放入job队列--master缓存区(job1,job2....))
6、slave01--->master(slave主动链接master去领取自己的job,之间用NodeManage==ResourceManage进程)
7、slave01--->slave03(根据领取的jobId,从资源地址下载job资源信息到本地(尤其是job.jar))
8、slave01--->master(反馈资源下载完成,所有slave都要反馈)
9、master在slave中寻找负载清闲的节点(例slave02),并在其上启动MRAPPMaster进程,同时slave02上会出现MapReduce进程
10、slave02---->master(申请运行MapReduce进程)
11、master---->slave02(返回Task(一个job有多个Task,一个Task就是一个进程)与地址的映射表--告知哪些节点运行MapTask,哪些运行ReduceTask)
12、slave02--->slave03(链接相应的slave并在其上启动相应的Task)
--------Task进程跑完会将YarnChild进程结束信息反馈给master
13、Task----->master(反馈Task进程(名字叫:YarnChild)运行完毕,所有进程都要反馈)
-------都反馈完毕
14、slave02--->master(反馈job运行完成)
--------master关闭MapReduce进程
15、master--->client(反馈job运行结束--1、环节出错,job运行失败,2、成功运行结束)
YARN资源管理
◆ 资源调度和资源隔离是YARN作为一个资源管理系统,最重要和最基础的两个功能。资源调度由ResourceManager完成,而资源隔离由各个NM实现。
◆ ResourceManager将某个NodeManager上资源分配给任务(这就是所谓的“资源调度”)后,NodeManager需按照要求为任务提供相应的资源,甚至保证这些资源应具有独占性,为任务运行提供基础的保证,这就是所谓的资源隔离。
◆ 当谈及到资源时,我们通常指内存,CPU和IO三种资源。Hadoop YARN同时支持内存和CPU两种资源的调度。
◆ 内存资源的多少会会决定任务的生死,如果内存不够,任务可能会运行失败;相比之下,CPU资源则不同,它只会决定任务运行的快慢,不会对生死产生影响。
参考文章:
1、http://blog.csdn.net/mobanchengshuang/article/details/78786652
hadoop框架详解的更多相关文章
- Hadoop Pipeline详解[摘抄]
最近使用公司内部的一个框架写map reduce发现没有封装hadoop streaming这些东西,查了下pipeline相关的东西 Hadoop Pipeline详解 20. Aug / had ...
- mapreduce框架详解
hadoop 学习笔记:mapreduce框架详解 开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感 ...
- Hadoop Streaming详解
一: Hadoop Streaming详解 1.Streaming的作用 Hadoop Streaming框架,最大的好处是,让任何语言编写的map, reduce程序能够在hadoop集群上运行:m ...
- Spark2.1.0——内置Web框架详解
Spark2.1.0——内置Web框架详解 任何系统都需要提供监控功能,否则在运行期间发生一些异常时,我们将会束手无策.也许有人说,可以增加日志来解决这个问题.日志只能解决你的程序逻辑在运行期的监控, ...
- Python API 操作Hadoop hdfs详解
1:安装 由于是windows环境(linux其实也一样),只要有pip或者setup_install安装起来都是很方便的 >pip install hdfs 2:Client——创建集群连接 ...
- jQuery Validate验证框架详解
转自:http://www.cnblogs.com/linjiqin/p/3431835.html jQuery校验官网地址:http://bassistance.de/jquery-plugins/ ...
- mina框架详解
转:http://blog.csdn.net/w13770269691/article/details/8614584 mina框架详解 分类: web2013-02-26 17:13 12651人 ...
- lombok+slf4j+logback SLF4J和Logback日志框架详解
maven 包依赖 <dependency> <groupId>org.projectlombok</groupId> <artifactId>lomb ...
- [Cocoa]深入浅出 Cocoa 之 Core Data(1)- 框架详解
Core data 是 Cocoa 中处理数据,绑定数据的关键特性,其重要性不言而喻,但也比较复杂.Core Data 相关的类比较多,初学者往往不太容易弄懂.计划用三个教程来讲解这一部分: 框架详解 ...
随机推荐
- U-Boot Makefile分析(1)配置脚本mkconfig分析
我们在编译U-Boot之前,需要根据当前使用的板子进行配置,例如make s5p_goni_config,接着才能进行编译make.下面首先分析配置阶段U-Boot做了哪些事情. 由于执行这些命令是在 ...
- 使用rsync实现不同Linux服务器间目录同步
实现目标: A 服务器上 /opt/web 目录,与B服务器上 /opt/web目录实现同步.即:B主动与A进行同步. OS: Reaht AS4 A Server 192.168.1 ...
- Xaml引用图片路径的方式
最近写代码的时候遇到过好几次引用某个路径下图片资源的情况,思索了一下,便将自己所知的在xaml里引用图片资源的方法写成了个小Demo,并完成了这篇博文.希望罗列出的这些方式能够对大家有所帮助. Xam ...
- 【Solidity】学习(2)
address 地址类型 40个16进制数,160位 地址包括合约地址和账户地址 payable 合约充值 balance,指的是当前地址的账户value,单位是wei this指的是当前合约的地址 ...
- C++ 使用Lambda
基础使用: C++中的Lambda表达式详解 c++11的闭包(lambda.function.bind) C++ lambda作为函数参数,实现通用的查找接口 C++11系列-lambda函数 进阶 ...
- js前段开发工具
http://runjs.cn/?token=e87dac453af5caed08d1771682b0c3f5
- 包建强的培训课程(12):iOS深入学习(内存管理、Block和GCD等)
@import url(/css/cuteeditor.css); @import url(http://i.cnblogs.com/Load.ashx?type=style&file=Syn ...
- 53_并发编程-线程-GIL锁
一.GIL - 全局解释器锁 有了GIL的存在,同一时刻同一进程中只有一个线程被执行:由于线程不能使用cpu多核,可以开多个进程实现线程的并发,因为每个进程都会含有一个线程,每个进程都有自己的GI ...
- 解析Java分布式系统中的缓存架构(上)
作者 陈彩华 文章转载交流请联系 caison@aliyun.com 本文主要介绍大型分布式系统中缓存的相关理论,常见的缓存组件以及应用场景. 1 缓存概述 2 缓存的分类 缓存主要分为以下四类 2. ...
- Javascript高级编程学习笔记(83)—— 富文本选区(3)
富文本选区 在富文本编辑器中使用 iframe 的 getSelection() 方法可以获取选中的文本 该方法是 window 对象和 document 对象的属性,调用后会返回一个当前选选择文本的 ...