目标检测:YOLO(v1 to v3)——学习笔记
前段时间看了YOLO的论文,打算用YOLO模型做一个迁移学习,看看能不能用于项目中去。但在实践过程中感觉到对于YOLO的一些细节和技巧还是没有很好的理解,现学习其他人的博客总结(所有参考连接都附于最后一部分“参考资料”),加入自己的理解,整理此学习笔记。
概念补充:mAP:mAP是目标检测算法中衡量算法精确度的一个指标,其涉及到查准率(Precision)和查全率(Recall)。对于目标检测任务,对于每一个目标可以计算出其查准率和查全率,多次实验进行统计,可以得到每个类有一条P-R曲线,曲线下面的面积即是AP的值,m的意思是对每一个类的AP值求平均,即mAP的定义,mAP的大小在[0, 1]区间内。
0 - 背景
过去的目标检测算法很多的思路是通过算法(经典的如region proposal)产生大量的可能包含目标物体的边界框(potential bounding box),然后用分类器去判断每一个边界框里面是否包含物体,以及包含物体的类别以及置信度(confidence),经典的模型由R-CNN以及其多个变种。但正如YOLO论文中反复提及的,这种做法一方面会使得训练变得麻烦(因为整个模型由多个部分组成,而每一部分通常都需要独立训练),不仅费时,也很难综合几部分结果求得最好的整体结果,另一方面,多个部分的协同使得整个模型的效率较为低下。
一直以来,计算机视觉对于检测两个距离很近的同类目标或者不同目标都具有很大的挑战。很多算法会对输入的图像进行尺寸的放缩,而如果当图像中由两个目标相近的时候,加上缩小尺寸,这使得对于相近目标的检测变得很困难。对于这种情况(特别是小目标检测,如鸟群),YOLO v3做得很好。
1 - 与其他算法的比较
YOLO不同于上述的目标检测算法,它将目标检测抽象为一个回归问题(regression problem),直接使用一个神经网络,输入为原始图片,输出为边界框坐标、目标类别、目标置信度等,YOLO将其他模型分开的部分都综合到一个神经网络中,使得训练能够采用端到端(end-to-end)来优化。同时,这种改进不仅使得训练变得容易,也使得检测速度很快。并且,论文中提到,YOLO迁移到其他数据集(如艺术图像)上的表现远好于其他目标检测算法,这表明了YOLO较其他模型学习了较好的抽象特征,泛化能力更强。
但YOLO也有缺点,其在物体定位时容易出错,不过在误将在背景检测出本不存在的物品的情况相对少一些。
不同算法的检测流程对比如下(图来自于博客:https://blog.csdn.net/hrsstudy):

综上,将YOLO的优点总结如下:
- 检测快速
- 不同于其他检测算法,YOLO的模型只由一个神经网路构成,原始图像和最终结果是模型的输入和输出。论文中提到,YOLO在Titan X的GPU上能达到45 FPS,其快速版本Fast YOLO能达到155 FPS
- 减少背景错误(将背景识别成本不存在的物体)
- 其他检测算法,采用的诸如滑动窗口或者region proposal产生预选边界框,一定程度忽略了全局信息(上下文信息),而过多关注了局部信息。而YOLO采用整张图片进行输入,很好的利用了检测目标的上下文信息(环境信息),从而有效避免了背景错误(值得一提的是,YOLO的背景错误不到Fast R-CNN的一半)
- 较好的学习了目标的泛化特征
- YOLO对于其他数据集的迁移学习能力较强,这说明其学到了目标的泛化特征,提高了泛化能力。我的理解是,相比其他算法,YOLO用一个神经网络代替了复杂的多部分综合,从而减少了人工干预,使得模型能学习到更加好的参数,从而提高了效果
以上总结了YOLO的优点,下面总结其缺点:
- YOLO的目标检测精度低于R-CNN为代表的其他state-of-the-art的物体检测算法
- YOLO的定位错误相比其他算法较为严重
- YOLO对小物体的检测效果也不佳,这是因为划定网络单元的时候限制了其每一个单元最多打的边界框数量,因此网格单元的数量以及每个单元的边界框数量都成了额外影响结果的参数
下面是各个目标检测算法的性能对比(图来自于博客:https://blog.csdn.net/hrsstudy):

2 - 相关计算
2.1 - 网格单元置信度计算
如果该网格单元存在目标,则计算公式为:$confidence=Pr(Object)\times IOU_{pred}^{truth}$,否则其$confidence$应为0。
2.2 - 边界框目标类别置信度计算
注意到,$confidence$是针对每一个边界框(有没有目标),而$conditional\ class\ probabilities$是对整个网格单元的。因此可以通过如下公式计算每一个边界框对于每一个具体类别的置信度。
$$Pr(Class_i|Object)\times Pr(Object)\times IOU_{pred}^{truth}=Pr(Class_i)\times IOU_{pred}^{truth}$$
2.3 - 输出张量计算
YOLO将图像分成$S \times S$个网格单元,每一个网格单元最后输出$B$个边界框(每个边界框包括$x,y,w,h,confidence$,$x,y$表示预测的边界框中心与网格单元边界的相对值,$w,h$表示预测的边界框的宽和高相对于整幅图像的$width,height$的比例值,$confidence$表示预测的边界框与真实的边界框的$IOU$的值),以及$C$个类别的概率($Pr(Class|Object)$,即如果一个网格单元包含目标的前提下,其属于某个类别的概率,对于一个网格单元只预测一组类的概率,而不考虑边界框$B$的数量)。因此,最后输出的张量维度为$S \times S \times (B \times 5 + C)$。
2.4 - 损失函数计算
损失函数需要设计得让目标的$(x,y,w,h),confidence,classification$这三个衡量部分达到很好平衡,则需要注意到:
- 坐标是8维的,类别概率是20维的,它们在衡量中不能以同等重要的权重
- 如果网络单元中没有目标,则这些单元的边界框的置信度要为0,而往往图中这种单元很多,这将使得它们对于梯度的贡献可能远大于那些有目标的单元,这将导致网络不稳定而发散
因此,解决方法如下:
- 相比于20维的类别概率,8维的坐标预测需要得到重视,因此给其分配更大的损失权重$\lambda_{coord}$,在pascal VOC训练中取5(下图蓝色框)
- 对于没有目标的网络单元,其损失权重$\lambda_{noobj}$需要小一点,在pascal VOC训练中取0.5(下图黄色框)
- 其他的损失权重:有目标的边界框的置信度损失权重(下图紫色框)以及类别概率的损失权重均取1(下图红色框)
下图为损失函数理解(图来自于博客:https://blog.csdn.net/hrsstudy): 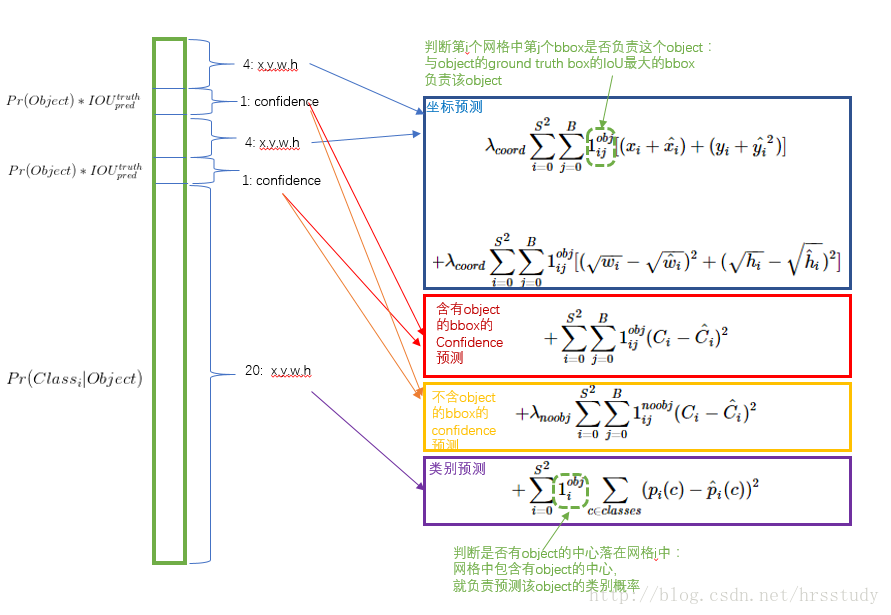
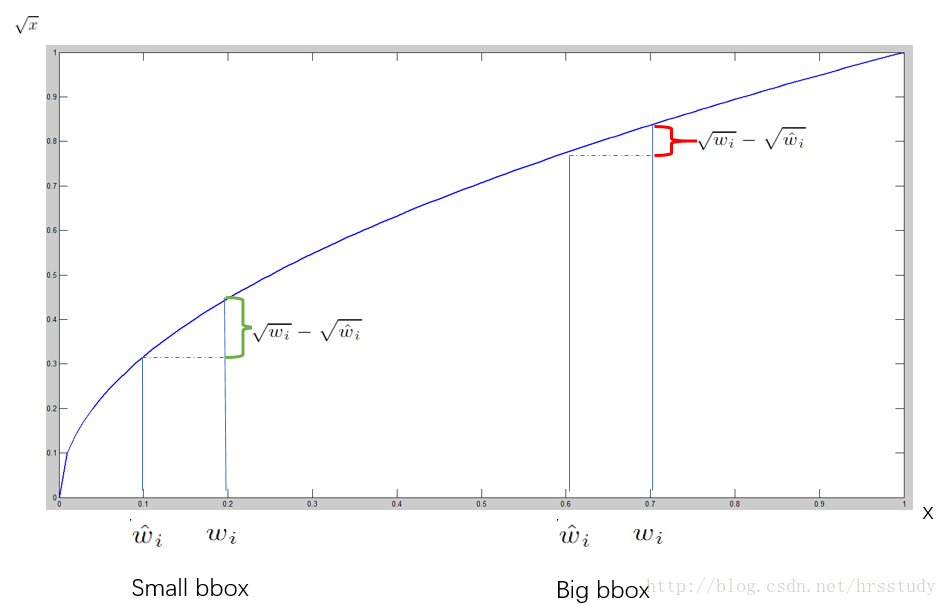
注意到,上面的损失函数对于$w,h$的损失计算是先取了开方再平方的,这是因为对于不同的小的边界框预测中,相同的偏差影响程度不同(小偏差对于小边界框的影响更大,因此需要更严重的惩罚),基于此,作者想到了这个巧妙的方法,其原理可以由下图直观理解(图来自于博客:https://blog.csdn.net/hrsstudy):
参考资料
https://www.imooc.com/article/36391
https://blog.csdn.net/hrsstudy
https://blog.csdn.net/honk2012/article/details/79081956
目标检测:YOLO(v1 to v3)——学习笔记的更多相关文章
- CNN目标检测系列算法发展脉络——学习笔记(一):AlexNet
在咨询了老师的建议后,最近开始着手深入的学习一下目标检测算法,结合这两天所查到的资料和个人的理解,准备大致将CNN目标检测的发展脉络理一理(暂时只讲CNN系列部分,YOLO和SSD,后面会抽空整理). ...
- 小白也能弄得懂的目标检测YOLO系列之YOLOv1网络训练
上期给大家介绍了YOLO模型的检测系统和具体实现,YOLO是如何进行目标定位和目标分类的,这期主要给大家介绍YOLO是如何进行网络训练的,话不多说,马上开始! 前言: 输入图片首先被分成S*S个网格c ...
- [目标检测]YOLO原理
1 YOLO 创新点: 端到端训练及推断 + 改革区域建议框式目标检测框架 + 实时目标检测 1.1 创新点 (1) 改革了区域建议框式检测框架: RCNN系列均需要生成建议框,在建议框上进行分类与回 ...
- 第四节,目标检测---YOLO系列
1.R-CNN回顾 适应全卷积化CNN结构,提出全卷积化设计 共享ResNet的所有卷积层 引入变换敏感性(Translation variance) 位置敏感分值图(Position-sensiti ...
- 目标检测-yolo
论文下载:http://arxiv.org/abs/1506.02640 代码下载:https://github.com/pjreddie/darknet 1.创新点 端到端训练及推断 + 改革区域建 ...
- 小白也能弄懂的目标检测YOLO系列之YOLOV1 - 第二期
上期给大家展示了用VisDrone数据集训练pytorch版YOLOV3模型的效果,介绍了什么是目标检测.目标检测目前比较流行的检测算法和效果比较以及YOLO的进化史,这期我们来讲解YOLO最原始V1 ...
- DPI (深度报文检测) 关于DPI的学习笔记
关于DPI的学习笔记 先看一下定义 : DPI(Deep Packet Inspection)是一种基于数据包的深度检测技术,针对不同的网络应用层载荷(例如HTTP.DNS等)进行深度检测,通过对报文 ...
- 目标检测YOLO进化史之yolov1
yolov3在目标检测领域可以算得上是state-of-art级别的了,在实时性和准确性上都有很好的保证.yolo也不是一开始就达到了这么好的效果,本身也是经历了不断地演进的. yolov1 测试图片 ...
- 目标检测YOLO算法-学习笔记
算法发展及对比: 17年底,mask-R CNN YOLO YOLO最大的优势就是快 原论文中流程,可以检测出20类物体. 红色网格-张量,在这样一个1×30的张量中保存的数据 横纵坐标中心点缩放到0 ...
随机推荐
- Windows7安装程序无法定位现有系统分区,也无法创建新的系统分区
解决Windows7.Windows8系统安装时“安装程序无法定位现有系统分区,也无法创建新的系统分区”提示. 方法一 把Windows7镜像发在你电脑的非系统盘的其他硬盘上. 重启机器,通过U盘启动 ...
- (点到线段的最短距离)51nod1298 圆与三角形
1298 圆与三角形 给出圆的圆心和半径,以及三角形的三个顶点,问圆同三角形是否相交.相交输出"Yes",否则输出"No".(三角形的面积大于0). 收起 ...
- qml Loader异步导致ComBoBox数据乱序
qml Loader异步导致ComBoBox数据乱序 当使用Loader动态加载qml文件时, 如果将Loader设置为异步,那么动态加载的组件内的ComBoBox数据将呈现乱序状态, 代码请见下文 ...
- Struts2_API
1.访问servletAPI方法1 public String execute() throws Exception { //request域对象==>map (struts2并不推荐使用原生r ...
- python css盒子型 浮动
########################总结############### 块级标签能够嵌套某些块级标签和内敛标签 内敛标签不能块级标签,只能嵌套内敛标签 嵌套就是: <div> ...
- C# 一个特别不错的http请求类
using System; using System.Collections; using System.Collections.Generic; using System.Collections.S ...
- golang命令行参数
os.Args获取命令行参数 os.Args是一个srting的切片,用来存储所有的命令行参数 package main import ( "fmt" "os" ...
- spring boot 2.0.3+spring cloud (Finchley)3、声明式调用Feign
Feign受Retrofix.JAXRS-2.0和WebSocket影响,采用了声明式API接口的风格,将Java Http客户端绑定到他的内部.Feign的首要目标是将Java Http客户端调用过 ...
- 前台ajax传参数,后台spring mvc用对象接受
第二种方法:利用spring mvc的机制,调用对象的get方法,要求对象的属性名和传的参数名字一致(有兴趣的同学看 springmvc源码) 1.将参数名直接写成对象的属性名 $.ajax({ ur ...
- 【不懂】spring bean生命周期
完整的生命周期(牢记): 1.spring容器准备 2.实例化bean 3.注入依赖关系 4.初始化bean 5.使用bean 6.销毁bean Bean的完整生命週期可以認為是從容器建立初始化Bea ...