dom解析xml随笔
1.dom解析jar包准备:
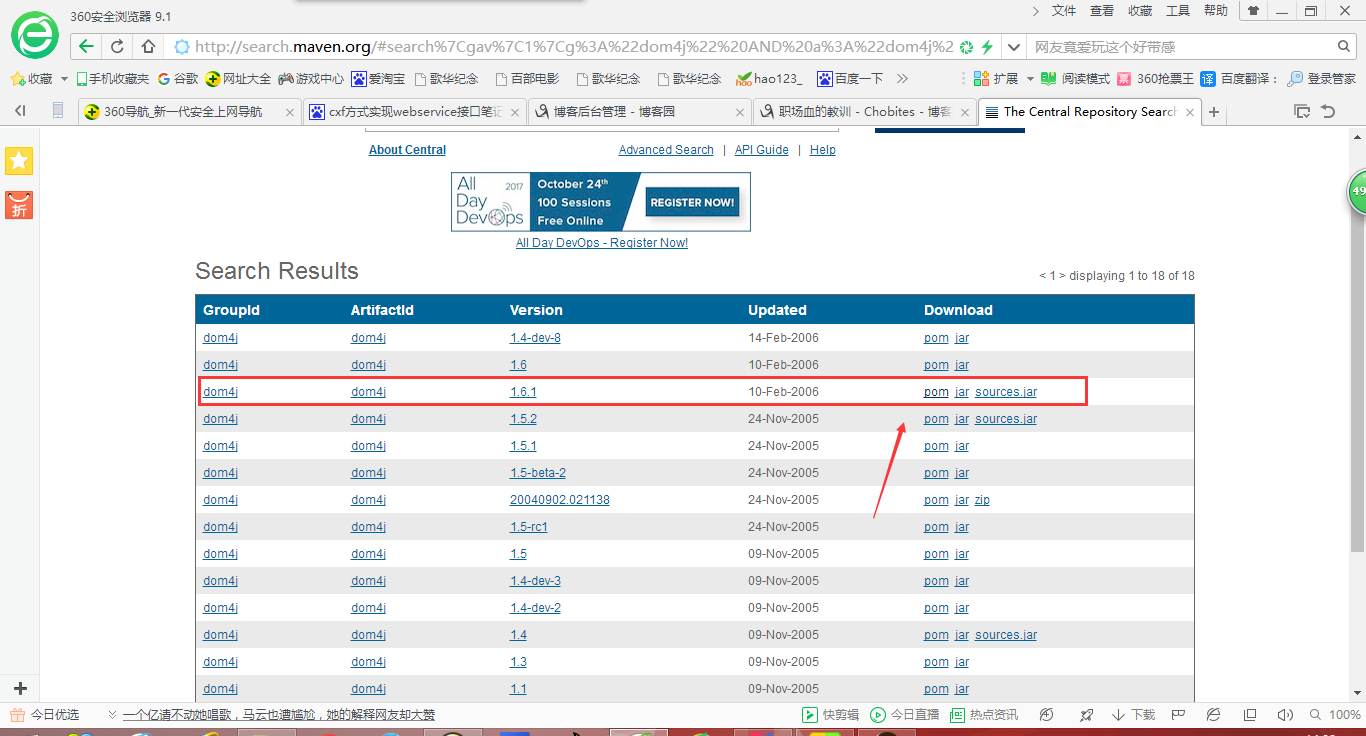
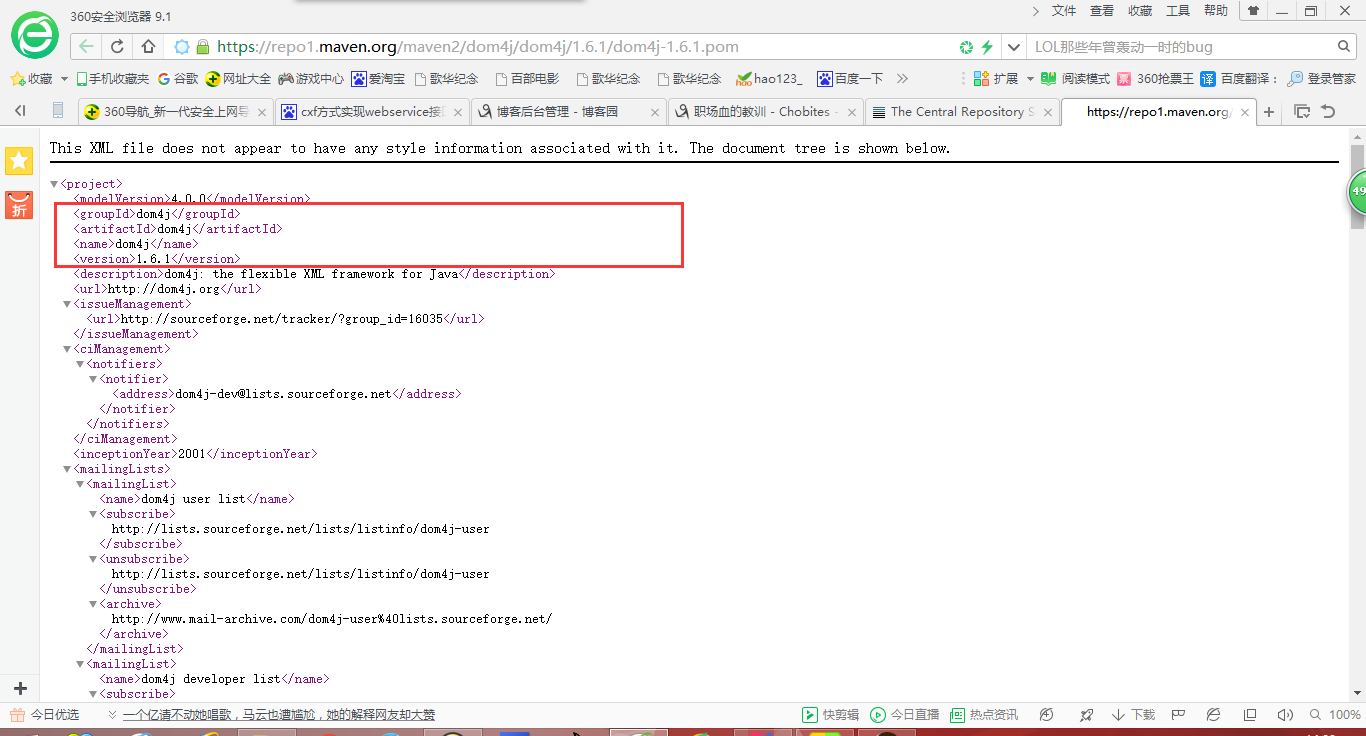
dom解析需用到dom4j的jar包,比如我在项目中用到的的是dom4j-1.6.1jar,因为项目用的是MAVEN,所以可直接到maven中央库去搜索相关pom坐标配置,贴到项目中的pom.xml,下载即可。 备注:如果进行的是web项目开发,我们只需要把jar包(例如:dom4j-1.6.1.jar)拷贝到web-inf/lib中去即可,会自动构建到web项目中.
2.dom解析具体用法:
一、DOM4j中,获得Document对象的方式有三种:
1.读取XML文件,获得document对象
SAXReader reader = new SAXReader();
Document document = reader.read(new File("csdn.xml"));
2.解析XML形式的文本,得到document对象.
String text = "<csdn></csdn>";
Document document = DocumentHelper.parseText(text);
3.主动创建document对象.
Document document = DocumentHelper.createDocument(); //创建根节点
Element root = document.addElement("csdn"); 二、节点对象操作的方法 demo1:
需解析的xml: <?xml version="1.0" encoding="UTF-8"?>
<ROWS>
<ROW no="1">
<INPUT>
<gmsfhm>23060219********</gmsfhm>
<xm>白若晶</xm>
</INPUT>
<OUTPUT>
<ITEM>
<gmsfhm>230602198********</gmsfhm>
<result_gmsfhm>一致</result_gmsfhm>
</ITEM>
<ITEM>
<xm>白若晶</xm>
<result_xm>一致</result_xm>
</ITEM>
<ITEM>
<xp>
****************
</xp>
</ITEM>
</OUTPUT>
<RTS>
<RT>
<DN>BL0人员</DN>
<DES>BL00</DES>
</RT>
</RTS>
</ROW>
</ROWS> 解析代码:
//解析部分start
Document doc = DocumentHelper.parseText(result);
//获取根节点 getRootElement
Element rootElt = doc.getRootElement();
//获取节点的名字 getName
System.out.println(rootElt.getName());
//获取某个节点的子节点 element
Element row = rootElt.element("ROW");
//获取节点的文字 gettext
system.out.println(row.getText)
Element input = row.element("INPUT");
//获取某个节点的子节点文字 elementTextTrim
String gmsfhm = input.elementTextTrim("gmsfhm");
String xm = input.elementTextTrim("xm");
System.out.println(gmsfhm);
System.out.println(xm); Element output = row.element("OUTPUT");
//获取某节点所有名为'ITEM'的子节点 elements
List<Element> items = output.elements("ITEM");
boolean checksame =false;
if(items!=null && items.size()>0){
Element item1 = items.get(0);
String gmsfhmstr = item1.elementTextTrim("gmsfhm");
String result_gmsfhm = item1.elementTextTrim("result_gmsfhm");
System.out.println(gmsfhmstr);
System.out.println(result_gmsfhm); Element item2 = items.get(1);
String xmstr = item2.elementTextTrim("xm");
String result_xm = item2.elementTextTrim("result_xm");
}
//解析部分end
1.获取文档的根节点.
Element root = document.getRootElement();
2.取得某个节点的子节点.
Element element=node.element(“四大名著");
3.取得节点的文字
String text=node.getText();
4.取得某节点下所有名为“csdn”的子节点,并进行遍历.
List nodes = rootElm.elements("csdn");
for (Iterator it = nodes.iterator(); it.hasNext();) {
Element elm = (Element) it.next();
// do something
}
5.对某节点下的所有子节点进行遍历.
for(Iterator it=root.elementIterator();it.hasNext();){
Element element = (Element) it.next();
// do something
}
6.在某节点下添加子节点
Element elm = newElm.addElement("朝代");
7.设置节点文字. elm.setText("明朝");
8.删除某节点.//childElement是待删除的节点,parentElement是其父节点 parentElement.remove(childElment);
9.添加一个CDATA节点.Element contentElm = infoElm.addElement("content");contentElm.addCDATA(“cdata区域”); 三、节点对象的属性方法操作
1.取得某节点下的某属性 Element root=document.getRootElement(); //属性名name
Attribute attribute=root.attribute("id");
2.取得属性的文字
String text=attribute.getText();
3.删除某属性 Attribute attribute=root.attribute("size"); root.remove(attribute);
4.遍历某节点的所有属性
Element root=document.getRootElement();
for(Iterator it=root.attributeIterator();it.hasNext();){
Attribute attribute = (Attribute) it.next();
String text=attribute.getText();
System.out.println(text);
}
5.设置某节点的属性和文字. newMemberElm.addAttribute("name", "sitinspring");
6.设置属性的文字 Attribute attribute=root.attribute("name"); attribute.setText("csdn");
四、将文档写入XML文件
1.文档中全为英文,不设置编码,直接写入的形式.
XMLWriter writer = new XMLWriter(new FileWriter("ot.xml"));
writer.write(document);
writer.close();
2.文档中含有中文,设置编码格式写入的形式.
OutputFormat format = OutputFormat.createPrettyPrint();// 创建文件输出的时候,自动缩进的格式
format.setEncoding("UTF-8");//设置编码
XMLWriter writer = new XMLWriter(newFileWriter("output.xml"),format);
writer.write(document);
writer.close();
五、字符串与XML的转换
1.将字符串转化为XML
String text = "<csdn> <java>Java班</java></csdn>";
Document document = DocumentHelper.parseText(text);
2.将文档或节点的XML转化为字符串.
SAXReader reader = new SAXReader();
Document document = reader.read(new File("csdn.xml"));
Element root=document.getRootElement();
String docXmlText=document.asXML();
String rootXmlText=root.asXML();
Element memberElm=root.element("csdn");
String memberXmlText=memberElm.asXML();
六、案例(解析sida.xml文件并对其进行curd的操作)
1.sida.xml描述四大名著的操作,文件内容如下
<?xml version="1.0" encoding="UTF-8"?>
<四大名著>
<西游记 id="x001">
<作者>吴承恩1</作者>
<作者>吴承恩2</作者>
<朝代>明朝</朝代>
</西游记>
<红楼梦 id="x002">
<作者>曹雪芹</作者>
</红楼梦>
</四大名著>
2.解析类测试操作
package dom4j; import java.io.File;
import java.io.FileOutputStream;
import java.io.FileWriter;
import java.io.OutputStreamWriter;
import java.nio.charset.Charset;
import java.nio.charset.CharsetEncoder;
import java.util.Iterator;
import java.util.List; import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import org.junit.Test; public class Demo01 { @Test
public void test() throws Exception { // 创建saxReader对象
SAXReader reader = new SAXReader();
// 通过read方法读取一个文件 转换成Document对象
Document document = reader.read(new File("src/dom4j/sida.xml"));
//获取根节点元素对象
Element node = document.getRootElement();
//遍历所有的元素节点
listNodes(node); // 获取四大名著元素节点中,子节点名称为红楼梦元素节点。
Element element = node.element("红楼梦");
//获取element的id属性节点对象
Attribute attr = element.attribute("id");
//删除属性
element.remove(attr);
//添加新的属性
element.addAttribute("name", "作者");
// 在红楼梦元素节点中添加朝代元素的节点
Element newElement = element.addElement("朝代");
newElement.setText("清朝");
//获取element中的作者元素节点对象
Element author = element.element("作者");
//删除元素节点
boolean flag = element.remove(author);
//返回true代码删除成功,否则失败
System.out.println(flag);
//添加CDATA区域
element.addCDATA("红楼梦,是一部爱情小说.");
// 写入到一个新的文件中
writer(document); } /**
* 把document对象写入新的文件
*
* @param document
* @throws Exception
*/
public void writer(Document document) throws Exception {
// 紧凑的格式
// OutputFormat format = OutputFormat.createCompactFormat();
// 排版缩进的格式
OutputFormat format = OutputFormat.createPrettyPrint();
// 设置编码
format.setEncoding("UTF-8");
// 创建XMLWriter对象,指定了写出文件及编码格式
// XMLWriter writer = new XMLWriter(new FileWriter(new
// File("src//a.xml")),format);
XMLWriter writer = new XMLWriter(new OutputStreamWriter(
new FileOutputStream(new File("src//a.xml")), "UTF-8"), format);
// 写入
writer.write(document);
// 立即写入
writer.flush();
// 关闭操作
writer.close();
} /**
* 遍历当前节点元素下面的所有(元素的)子节点
*
* @param node
*/
public void listNodes(Element node) {
System.out.println("当前节点的名称::" + node.getName());
// 获取当前节点的所有属性节点
List<Attribute> list = node.attributes();
// 遍历属性节点
for (Attribute attr : list) {
System.out.println(attr.getText() + "-----" + attr.getName()
+ "---" + attr.getValue());
} if (!(node.getTextTrim().equals(""))) {
System.out.println("文本内容::::" + node.getText());
} // 当前节点下面子节点迭代器
Iterator<Element> it = node.elementIterator();
// 遍历
while (it.hasNext()) {
// 获取某个子节点对象
Element e = it.next();
// 对子节点进行遍历
listNodes(e);
}
} /**
* 介绍Element中的element方法和elements方法的使用
*
* @param node
*/
public void elementMethod(Element node) {
// 获取node节点中,子节点的元素名称为西游记的元素节点。
Element e = node.element("西游记");
// 获取西游记元素节点中,子节点为作者的元素节点(可以看到只能获取第一个作者元素节点)
Element author = e.element("作者"); System.out.println(e.getName() + "----" + author.getText()); // 获取西游记这个元素节点 中,所有子节点名称为作者元素的节点 。 List<Element> authors = e.elements("作者");
for (Element aut : authors) {
System.out.println(aut.getText());
} // 获取西游记这个元素节点 所有元素的子节点。
List<Element> elements = e.elements(); for (Element el : elements) {
System.out.println(el.getText());
} } }
dom解析xml随笔的更多相关文章
- Android之DOM解析XML
一.DOM解析方法介绍 DOM是基于树形结构的节点或信息片段的集合,允许开发人员使用DOM API遍历XML树,检索所需数据.分析该结构通常需要加载整个文档和构造树形结构,然后才可以检索和更新节点信息 ...
- JAVA中使用DOM解析XML文件
XML是一种方便快捷高效的数据保存传输的格式,在JSON广泛使用之前,XML是服务器和客户端之间数据传输的主要方式.因此,需要使用各种方式,解析服务器传送过来的信息,以供使用者查看. JAVA作为一种 ...
- 简单谈谈dom解析xml和html
前言 文件对象模型(Document Object Model,简称DOM),是W3C组织推荐的处理可扩展标志语言的标准编程接口.html,xml都是基于这个模型构造的.这也是一个W3C推出的标准.j ...
- Java从零开始学四十二(DOM解析XML)
一.DOM解析XML xml文件 favorite.xml <?xml version="1.0" encoding="UTF-8" standalone ...
- xml语法、DTD约束xml、Schema约束xml、DOM解析xml
今日大纲 1.什么是xml.xml的作用 2.xml的语法 3.DTD约束xml 4.Schema约束xml 5.DOM解析xml 1.什么是xml.xml的作用 1.1.xml介绍 在前面学习的ht ...
- python 解析XML python模块xml.dom解析xml实例代码
分享下python中使用模块xml.dom解析xml文件的实例代码,学习下python解析xml文件的方法. 原文转自:http://www.jbxue.com/article/16587.html ...
- Java解析XML文档(简单实例)——dom解析xml
一.前言 用Java解析XML文档,最常用的有两种方法:使用基于事件的XML简单API(Simple API for XML)称为SAX和基于树和节点的文档对象模型(Document Object ...
- xml--通过DOM解析XML
此文章通过3个例子表示DOM方式解析XML的用法. 通过DOM解析XML必须要写的3行代码. step 1: 获得dom解析器工厂(工作的作用是用于创建具体的解析器) step 2:获得具体的dom解 ...
- POPTEST老李分享DOM解析XML之java
POPTEST老李分享DOM解析XML之java Java提供了两种XML解析器:树型解释器DOM(Document Object Model,文档对象模型),和流机制解析器SAX(Simple ...
随机推荐
- eclipse导出svn源码,如何转化为项目
1.先导出 2.点击项目右键,选“属性” 3.选择project facets 4.添加对应的支持 5.可进行进一步配置,设置name,然后点击确定等待完成
- 安装Androidsdudio时
安装Androidsdudio时,Androidsdudio的路劲可以任意选择,但Androidsdk的路劲就默认到c盘里.然后安装后就可以直接用了
- python基础-格式化时间
module datatime用strftime格式化时间import datetimedatetime.datetime.now() 返回microsecond,要修改datetime.dateti ...
- sqlserver Timeout 时间已到。在操作完成之前超时时间已过或服务器未响应
随着数据库数据的不断增大,查询时间也随之增长.今天在之前一个项目中执行数据库查询超过30秒就报“Timeout 时间已到.在操作完成之前超时时间已过或服务器未响应.”了,网上找了些文章,是在.co ...
- pycharm更新之后pip显示没有main
更新pip之后,Pycharm安装package出现报错:module 'pip' has no attribute 'main' 找到安装目录下 helpers/packaging_tool.py文 ...
- div设置overflow-scroll滚动之后,jq获取其子元素的offset.top出现问题。
先上个图: 布局很简单,左右超过屏幕的部分自行滚动. 1. html <div class="ce-container"> <div class="ce ...
- qml: 组件复用
在编写组件时,使用下面两种方法可以实现组件的复用: import QtQuick 2.0 import QtQuick.Window 2.2 import QtQuick.Controls 1.4 a ...
- 信用评分卡 (part 3of 7)
python信用评分卡(附代码,博主录制) https://study.163.com/course/introduction.htm?courseId=1005214003&utm_camp ...
- Hadoop ha CDH5.15.1-hadoop集群启动后,两个namenode都是standby模式
Hadoop ha CDH5.15.1-hadoop集群启动后,两个namenode都是standby模式 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一说起周五,想必大家都特别 ...
- 转: Linux 系统调用sysconf 获取系统配置信息
1.前言 linux提供了sysconf系统调用可以获取系统的cpu个数和可用的cpu个数. 2.sysconf 函数 man一下sysconf,解释这个函数用来获取系统执行的配置信息.例如页大小. ...