爬虫框架之Scrapy
一、介绍
Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速、简单、可扩展的方式从网站中提取所需的数据。但目前Scrapy的用途十分广泛,可用于如数据挖掘、监测和自动化测试等领域,也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。
Scrapy 是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架。因此Scrapy使用了一种非阻塞(又名异步)的代码来实现并发。整体架构大致如下

在Scrapy的数据流是由执行引擎控制,具体流程如下:
- 1、spiders产生request请求,将请求交给引擎
- 2、引擎(EGINE)吧刚刚处理好的请求交给了调度器,以一个队列或者堆栈的形式吧这些请求保存起来,调度一个出来再传给引擎
- 3、调度器(SCHEDULER)返回给引擎一个要爬取的url
- 4、引擎把调度好的请求发送给download,通过中间件发送(这个中间件至少有 两个方法,一个请求的,一个返回的),
- 5、一旦完成下载就返回一个response,通过下载器中间件,返回给引擎,引擎把response 对象传给下载器中间件,最后到达引擎
- 6、引擎从下载器中收到response对象,从下载器中间件传给了spiders(spiders里面做两件事,1、产生request请求,2、为request请求绑定一个回调函数),spiders只负责解析爬取的任务。不做存储,
- 7、解析完成之后返回一个解析之后的结果items对象及(跟进的)新的Request给引擎
- 就被ITEM PIPELUMES处理了
- 8、引擎将(Spider返回的)爬取到的Item给Item Pipeline,存入数据库,持久化,如果数据不对,可重新封装成一个request请求,传给调度器
- 9、(从第二步)重复直到调度器中没有更多地request,引擎关闭该网站
scrapy框架分为七大部分核心的组件
1、引擎(EGINE)
引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。有关详细信息,请参见上面的数据流部分。
2、调度器(SCHEDULER)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL的优先级队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
3、下载器(DOWLOADER)
用于下载网页内容, 并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的
4、爬虫(SPIDERS)
SPIDERS是开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求
5、项目管道(ITEM PIPLINES)
在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作
6、下载器中间件(Downloader Middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看 下载器中间件(Downloader Middleware) 。
7、爬虫中间件(Spider Middlewares)
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看 Spider中间件(Middleware) 。
二、安装
#Windows平台
1、pip3 install wheel #安装后,便支持通过wheel文件安装软件,wheel文件官网:https://www.lfd.uci.edu/~gohlke/pythonlibs
3、pip3 install lxml
4、pip3 install pyopenssl
5、下载并安装pywin32:https://sourceforge.net/projects/pywin32/files/pywin32/
6、下载twisted的wheel文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
7、执行pip3 install 下载目录\Twisted-17.9.0-cp36-cp36m-win_amd64.whl
8、pip3 install scrapy #Linux平台
1、pip3 install scrapy
三、命令行工具
#1 查看帮助
scrapy -h
scrapy <command> -h #2 有两种命令:其中Project-only必须切到项目文件夹下才能执行,而Global的命令则不需要
Global commands:
startproject #创建项目
genspider #创建爬虫程序
settings #如果是在项目目录下,则得到的是该项目的配置
runspider #运行一个独立的python文件,不必创建项目
shell #scrapy shell url地址 在交互式调试,如选择器规则正确与否
fetch #独立于程单纯地爬取一个页面,可以拿到请求头
view #下载完毕后直接弹出浏览器,以此可以分辨出哪些数据是ajax请求
version #scrapy version 查看scrapy的版本,scrapy version -v查看scrapy依赖库的版本
Project-only commands:
crawl #运行爬虫,必须创建项目才行,确保配置文件中ROBOTSTXT_OBEY = False
check #检测项目中有无语法错误
list #列出项目中所包含的爬虫名
edit #编辑器,一般不用
parse #scrapy parse url地址 --callback 回调函数 #以此可以验证我们的回调函数是否正确
bench #scrapy bentch压力测试 #3 官网链接
https://docs.scrapy.org/en/latest/topics/commands.html
全局命令:所有文件夹都使用的命令,可以不依赖与项目文件也可以执行
项目的文件夹下执行的命令
1、scrapy startproject Myproject #创建项目
cd Myproject
2、scrapy genspider baidu www.baidu.com #创建爬虫程序,baidu是爬虫名,定位爬虫的名字
#写完域名以后默认会有一个url,
3、scrapy settings --get BOT_NAME #获取配置文件
#全局:4、scrapy runspider budui.py
5、scrapy runspider AMAZON\spiders\amazon.py #执行爬虫程序
在项目下:scrapy crawl amazon #指定爬虫名,定位爬虫程序来运行程序
#robots.txt 反爬协议:在目标站点建一个文件,里面规定了哪些能爬,哪些不能爬
# 有的国家觉得是合法的,有的是不合法的,这就产生了反爬协议
# 默认是ROBOTSTXT_OBEY = True
# 修改为ROBOTSTXT_OBEY = False #默认不遵循反扒协议
6、scrapy shell https://www.baidu.com #直接超目标站点发请求
response
response.status
response.body
view(response)
7、scrapy view https://www.taobao.com #如果页面显示内容不全,不全的内容则是ajax请求实现的,以此快速定位问题
8、scrapy version #查看版本
9、scrapy version -v #查看scrapy依赖库锁依赖的版本
10、scrapy fetch --nolog http://www.logou.com #获取响应的内容
11、scrapy fetch --nolog --headers http://www.logou.com #获取响应的请求头
(venv3_spider) E:\twisted\scrapy框架\AMAZON>scrapy fetch --nolog --headers http://www.logou.com
> Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
> Accept-Language: en
> User-Agent: Scrapy/1.5.0 (+https://scrapy.org)
> Accept-Encoding: gzip,deflate
>
< Content-Type: text/html; charset=UTF-8
< Date: Tue, 23 Jan 2018 15:51:32 GMT
< Server: Apache
>代表请求
<代表返回
10、scrapy shell http://www.logou.com #直接朝目标站点发请求
11、scrapy check #检测爬虫有没有错误
12、scrapy list #所有的爬虫名
13、scrapy parse http://quotes.toscrape.com/ --callback parse #验证回调函函数是否成功执行
14、scrapy bench #压力测试
示例用法
四、项目结构以及爬虫应用简介
project_name/
scrapy.cfg
project_name/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
爬虫1.py
爬虫2.py
爬虫3.py
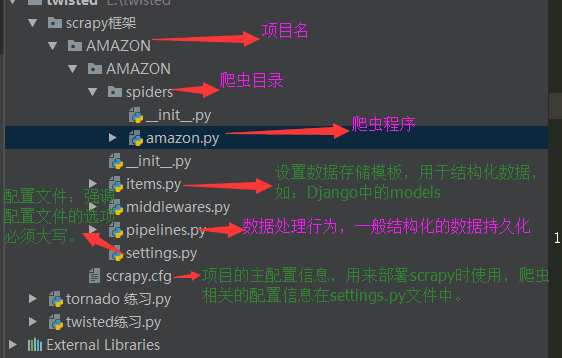
注意:一般创建爬虫文件时,以网站域名命名
默认只能在cmd中执行爬虫,如果想在pycharm中执行需要做:
#在项目目录下新建:entrypoint.py
from scrapy.cmdline import execute
# execute(['scrapy', 'crawl', 'amazon','--nolog']) #不要日志打印
# execute(['scrapy', 'crawl', 'amazon']) #我们可能需要在命令行为爬虫程序传递参数,就用下面这样的命令
#acrapy crawl amzaon -a keyword=iphone8
execute(['scrapy', 'crawl', 'amazon1','-a','keyword=iphone8','--nolog']) #不要日志打印 # execute(['scrapy', 'crawl', 'amazon1'])
import sys,os
sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
关于windows编码
五、Spiders
1、介绍
#1、Spiders是由一系列类(定义了一个网址或一组网址将被爬取)组成,具体包括如何执行爬取任务并且如何从页面中提取结构化的数据。 #2、换句话说,Spiders是你为了一个特定的网址或一组网址自定义爬取和解析页面行为的地方
2、Spiders会循环做如下事情
#1、生成初始的Requests来爬取第一个URLS,并且标识一个回调函数
第一个请求定义在start_requests()方法内默认从start_urls列表中获得url地址来生成Request请求,默认的回调函数是parse方法。回调函数在下载完成返回response时自动触发 #2、在回调函数中,解析response并且返回值
返回值可以4种:
包含解析数据的字典
Item对象
新的Request对象(新的Requests也需要指定一个回调函数)
或者是可迭代对象(包含Items或Request) #3、在回调函数中解析页面内容
通常使用Scrapy自带的Selectors,但很明显你也可以使用Beutifulsoup,lxml或其他你爱用啥用啥。 #4、最后,针对返回的Items对象将会被持久化到数据库
通过Item Pipeline组件存到数据库:https://docs.scrapy.org/en/latest/topics/item-pipeline.html#topics-item-pipeline)
或者导出到不同的文件(通过Feed exports:https://docs.scrapy.org/en/latest/topics/feed-exports.html#topics-feed-exports)
3、Spiders总共提供了五种类:
#1、scrapy.spiders.Spider #scrapy.Spider等同于scrapy.spiders.Spider
#2、scrapy.spiders.CrawlSpider
#3、scrapy.spiders.XMLFeedSpider
#4、scrapy.spiders.CSVFeedSpider
#5、scrapy.spiders.SitemapSpider
4、导入使用
import scrapy
class AmazonSpider(scrapy.Spider): name = 'amazon' # 必须唯一
allowed_domains = ['www.amazon.cn'] # 允许域
start_urls = ['http://www.amazon.cn/'] # 如果你没有指定发送的请求地址,会默认使用只一个 def parse(self,response):
pass
5、class scrapy.spiders.Spider
这是最简单的spider类,任何其他的spider类都需要继承它(包含你自己定义的)。
该类不提供任何特殊的功能,它仅提供了一个默认的start_requests方法默认从start_urls中读取url地址发送requests请求,并且默认parse作为回调函数
import scrapy
class AmazonSpider(scrapy.Spider):
def __init__(self,keyword=None,*args,**kwargs): #在entrypoint文件里面传进来的keyword,在这里接收了
super(AmazonSpider,self).__init__(*args,**kwargs)
self.keyword = keyword name = 'amazon' # 必须唯一
allowed_domains = ['www.amazon.cn'] # 允许域
start_urls = ['http://www.amazon.cn/'] # 如果你没有指定发送的请求地址,会默认使用只一个 custom_settings = { # 自定制配置文件,自己设置了用自己的,没有就找父类的
"BOT_NAME": 'HAIYAN_AMAZON',
'REQUSET_HEADERS': {},
} def start_requests(self):
url = 'https://www.amazon.cn/s/ref=nb_sb_noss_1/461-4093573-7508641?'
url+=urlencode({"field-keywords":self.keyword})
print(url)
yield scrapy.Request(
url,
callback = self.parse_index, #指定回调函数
dont_filter = True, #不去重,这个也可以自己定制
# dont_filter = False, #去重,这个也可以自己定制
# meta={'a':1} #meta代理的时候会用
)
#如果要想测试自定义的dont_filter,可多返回结果重复的即可
在settings中
DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
}
#1、name = 'amazon'
定义爬虫名,scrapy会根据该值定位爬虫程序
所以它必须要有且必须唯一(In Python 2 this must be ASCII only.) #2、allowed_domains = ['www.amazon.cn']
定义允许爬取的域名,如果OffsiteMiddleware启动(默认就启动),
那么不属于该列表的域名及其子域名都不允许爬取
如果爬取的网址为:https://www.example.com/1.html,那就添加'example.com'到列表. #3、start_urls = ['http://www.amazon.cn/']
如果没有指定url,就从该列表中读取url来生成第一个请求 #4、custom_settings
值为一个字典,定义一些配置信息,在运行爬虫程序时,这些配置会覆盖项目级别的配置
所以custom_settings必须被定义成一个类属性,由于settings会在类实例化前被加载 #5、settings
通过self.settings['配置项的名字']可以访问settings.py中的配置,如果自己定义了custom_settings还是以自己的为准 #6、logger
日志名默认为spider的名字
self.logger.debug('=============>%s' %self.settings['BOT_NAME']) #5、crawler:了解
该属性必须被定义到类方法from_crawler中 #6、from_crawler(crawler, *args, **kwargs):了解
You probably won’t need to override this directly because the default implementation acts as a proxy to the __init__() method, calling it with the given arguments args and named arguments kwargs. #7、start_requests()
该方法用来发起第一个Requests请求,且必须返回一个可迭代的对象。它在爬虫程序打开时就被Scrapy调用,Scrapy只调用它一次。
默认从start_urls里取出每个url来生成Request(url, dont_filter=True) #针对参数dont_filter,请看自定义去重规则 如果你想要改变起始爬取的Requests,你就需要覆盖这个方法,例如你想要起始发送一个POST请求,如下
class MySpider(scrapy.Spider):
name = 'myspider' def start_requests(self):
return [scrapy.FormRequest("http://www.example.com/login",
formdata={'user': 'john', 'pass': 'secret'},
callback=self.logged_in)] def logged_in(self, response):
# here you would extract links to follow and return Requests for
# each of them, with another callback
pass #8、parse(response)
这是默认的回调函数,所有的回调函数必须返回an iterable of Request and/or dicts or Item objects. #9、log(message[, level, component]):了解
Wrapper that sends a log message through the Spider’s logger, kept for backwards compatibility. For more information see Logging from Spiders. #10、closed(reason)
爬虫程序结束时自动触发
定制scrapy.spider属性与方法详解
去重规则应该多个爬虫共享的,但凡一个爬虫爬取了,其他都不要爬了,实现方式如下 #方法一:
1、新增类属性
visited=set() #类属性 2、回调函数parse方法内:
def parse(self, response):
if response.url in self.visited:
return None
....... self.visited.add(response.url) #方法一改进:针对url可能过长,所以我们存放url的hash值
def parse(self, response):
url=md5(response.request.url)
if url in self.visited:
return None
....... self.visited.add(url) #方法二:Scrapy自带去重功能
配置文件:
DUPEFILTER_CLASS = 'scrapy.dupefilter.RFPDupeFilter' #默认的去重规则帮我们去重,去重规则在内存中
DUPEFILTER_DEBUG = False
JOBDIR = "保存范文记录的日志路径,如:/root/" # 最终路径为 /root/requests.seen,去重规则放文件中 scrapy自带去重规则默认为RFPDupeFilter,只需要我们指定
Request(...,dont_filter=False) ,如果dont_filter=True则告诉Scrapy这个URL不参与去重。 #方法三:
我们也可以仿照RFPDupeFilter自定义去重规则, from scrapy.dupefilter import RFPDupeFilter,看源码,仿照BaseDupeFilter #步骤一:在项目目录下自定义去重文件cumstomdupefilter.py
'''
if hasattr("MyDupeFilter",from_settings):
func = getattr("MyDupeFilter",from_settings)
obj = func()
else:
return MyDupeFilter()
'''
class MyDupeFilter(object):
def __init__(self):
self.visited = set() @classmethod
def from_settings(cls, settings):
'''读取配置文件'''
return cls() def request_seen(self, request):
'''请求看过没有,这个才是去重规则该调用的方法'''
if request.url in self.visited:
return True
self.visited.add(request.url) def open(self): # can return deferred
'''打开的时候执行'''
pass def close(self, reason): # can return a deferred
pass def log(self, request, spider): # log that a request has been filtered
'''日志记录'''
pass #步骤二:配置文件settings.py
# DUPEFILTER_CLASS = 'scrapy.dupefilter.RFPDupeFilter' #默认会去找这个类实现去重
#自定义去重规则
DUPEFILTER_CLASS = 'AMAZON.cumstomdupefilter.MyDupeFilter' # 源码分析:
from scrapy.core.scheduler import Scheduler
见Scheduler下的enqueue_request方法:self.df.request_seen(request)
去重规则:去除重复的url
#例一:
import scrapy class MySpider(scrapy.Spider):
name = 'example.com'
allowed_domains = ['example.com']
start_urls = [
'http://www.example.com/1.html',
'http://www.example.com/2.html',
'http://www.example.com/3.html',
] def parse(self, response):
self.logger.info('A response from %s just arrived!', response.url) #例二:一个回调函数返回多个Requests和Items
import scrapy class MySpider(scrapy.Spider):
name = 'example.com'
allowed_domains = ['example.com']
start_urls = [
'http://www.example.com/1.html',
'http://www.example.com/2.html',
'http://www.example.com/3.html',
] def parse(self, response):
for h3 in response.xpath('//h3').extract():
yield {"title": h3} for url in response.xpath('//a/@href').extract():
yield scrapy.Request(url, callback=self.parse) #例三:在start_requests()内直接指定起始爬取的urls,start_urls就没有用了, import scrapy
from myproject.items import MyItem class MySpider(scrapy.Spider):
name = 'example.com'
allowed_domains = ['example.com'] def start_requests(self):
yield scrapy.Request('http://www.example.com/1.html', self.parse)
yield scrapy.Request('http://www.example.com/2.html', self.parse)
yield scrapy.Request('http://www.example.com/3.html', self.parse) def parse(self, response):
for h3 in response.xpath('//h3').extract():
yield MyItem(title=h3) for url in response.xpath('//a/@href').extract():
yield scrapy.Request(url, callback=self.parse) #例四:
# -*- coding: utf-8 -*-
from urllib.parse import urlencode
# from scrapy.dupefilter import RFPDupeFilter
# from AMAZON.items import AmazonItem
from AMAZON.items import AmazonItem
''' spiders会循环做下面几件事
1、生成初始请求来爬取第一个urls,并且绑定一个回调函数
2、在回调函数中,解析response并且返回值
3、在回调函数中,解析页面内容(可通过Scrapy自带的Seletors或者BeautifuSoup等)
4、最后、针对返回的Items对象(就是你从返回结果中筛选出来自己想要的数据)将会被持久化到数据库
Spiders总共提供了五种类:
#1、scrapy.spiders.Spider #scrapy.Spider等同于scrapy.spiders.Spider
#2、scrapy.spiders.CrawlSpider
#3、scrapy.spiders.XMLFeedSpider
#4、scrapy.spiders.CSVFeedSpider
#5、scrapy.spiders.SitemapSpider
'''
import scrapy
class AmazonSpider(scrapy.Spider):
def __init__(self,keyword=None,*args,**kwargs): #在entrypoint文件里面传进来的keyword,在这里接收了
super(AmazonSpider,self).__init__(*args,**kwargs)
self.keyword = keyword name = 'amazon' # 必须唯一
allowed_domains = ['www.amazon.cn'] # 允许域
start_urls = ['http://www.amazon.cn/'] # 如果你没有指定发送的请求地址,会默认使用只一个 custom_settings = { # 自定制配置文件,自己设置了用自己的,没有就找父类的
"BOT_NAME": 'HAIYAN_AMAZON',
'REQUSET_HEADERS': {},
} def start_requests(self):
url = 'https://www.amazon.cn/s/ref=nb_sb_noss_1/461-4093573-7508641?'
url+=urlencode({"field-keywords":self.keyword})
print(url)
yield scrapy.Request(
url,
callback = self.parse_index, #指定回调函数
dont_filter = True, #不去重,这个也可以自己定制
# dont_filter = False, #去重,这个也可以自己定制
# meta={'a':1} #meta代理的时候会用
)
#如果要想测试自定义的dont_filter,可多返回结果重复的即可 def parse_index(self, response):
'''获取详情页和下一页的链接'''
detail_urls = response.xpath('//*[contains(@id,"result_")]/div/div[3]/div[1]/a/@href').extract()
print(detail_urls)
# print("%s 解析 %s",(response.url,(len(response.body))))
for detail_url in detail_urls:
yield scrapy.Request(
url=detail_url,
callback=self.parse_detail #记得每次返回response的时候记得绑定一个回调函数
)
next_url = response.urljoin(response.xpath(response.xpath('//*[@id="pagnNextLink"]/@href').extract_first()))
# 因为下一页的url是不完整的,用urljoin就可以吧路径前缀拿到并且拼接
# print(next_url)
yield scrapy.Request(
url=next_url,
callback=self.parse_index #因为下一页也属于是索引页,让去解析索引页
)
def parse_detail(self,response):
'''详情页解析'''
name = response.xpath('//*[@id="productTitle"]/text()').extract_first().strip()#获取name
price = response.xpath('//*[@id="price"]//*[@class="a-size-medium a-color-price"]/text()').extract_first()#获取价格
delivery_method=''.join(response.xpath('//*[@id="ddmMerchantMessage"]//text()').extract()) #获取配送方式
print(name)
print(price)
print(delivery_method)
#上面是筛选出自己想要的项
#必须返回一个Item对象,那么这个item对象,是从item.py中来,和django中的model类似,
# 但是这里的item对象也可当做是一个字典,和字典的操作一样
item = AmazonItem()# 实例化
item["name"] = name
item["price"] = price
item["delivery_method"] = delivery_method
return item def close(spider, reason):
print("结束啦")
sprider例子
我们可能需要在命令行为爬虫程序传递参数,比如传递初始的url,像这样
#命令行执行
scrapy crawl myspider -a category=electronics #在__init__方法中可以接收外部传进来的参数
import scrapy class MySpider(scrapy.Spider):
name = 'myspider' def __init__(self, category=None, *args, **kwargs):
super(MySpider, self).__init__(*args, **kwargs)
self.start_urls = ['http://www.example.com/categories/%s' % category]
#... #注意接收的参数全都是字符串,如果想要结构化的数据,你需要用类似json.loads的方法
参数传递
6、其他通用Spiders:https://docs.scrapy.org/en/latest/topics/spiders.html#generic-spiders
六、Selectors
#1 //与/
#2 text
#3、extract与extract_first:从selector对象中解出内容
#4、属性:xpath的属性加前缀@
#4、嵌套查找
#5、设置默认值
#4、按照属性查找
#5、按照属性模糊查找
#6、正则表达式
#7、xpath相对路径
#8、带变量的xpath
response.selector.css()
response.selector.xpath()
可简写为
response.css()
response.xpath() #1 //与/
response.xpath('//body/a/')#
response.css('div a::text') >>> response.xpath('//body/a') #开头的//代表从整篇文档中寻找,body之后的/代表body的儿子
[]
>>> response.xpath('//body//a') #开头的//代表从整篇文档中寻找,body之后的//代表body的子子孙孙
[<Selector xpath='//body//a' data='<a href="image1.html">Name: My image 1 <'>, <Selector xpath='//body//a' data='<a href="image2.html">Name: My image 2 <'>, <Selector xpath='//body//a' data='<a href="
image3.html">Name: My image 3 <'>, <Selector xpath='//body//a' data='<a href="image4.html">Name: My image 4 <'>, <Selector xpath='//body//a' data='<a href="image5.html">Name: My image 5 <'>] #2 text
>>> response.xpath('//body//a/text()')
>>> response.css('body a::text') #3、extract与extract_first:从selector对象中解出内容
>>> response.xpath('//div/a/text()').extract()
['Name: My image 1 ', 'Name: My image 2 ', 'Name: My image 3 ', 'Name: My image 4 ', 'Name: My image 5 ']
>>> response.css('div a::text').extract()
['Name: My image 1 ', 'Name: My image 2 ', 'Name: My image 3 ', 'Name: My image 4 ', 'Name: My image 5 '] >>> response.xpath('//div/a/text()').extract_first()
'Name: My image 1 '
>>> response.css('div a::text').extract_first()
'Name: My image 1 ' #4、属性:xpath的属性加前缀@
>>> response.xpath('//div/a/@href').extract_first()
'image1.html'
>>> response.css('div a::attr(href)').extract_first()
'image1.html' #4、嵌套查找
>>> response.xpath('//div').css('a').xpath('@href').extract_first()
'image1.html' #5、设置默认值
>>> response.xpath('//div[@id="xxx"]').extract_first(default="not found")
'not found' #4、按照属性查找
response.xpath('//div[@id="images"]/a[@href="image3.html"]/text()').extract()
response.css('#images a[@href="image3.html"]/text()').extract() #5、按照属性模糊查找
response.xpath('//a[contains(@href,"image")]/@href').extract()
response.css('a[href*="image"]::attr(href)').extract() response.xpath('//a[contains(@href,"image")]/img/@src').extract()
response.css('a[href*="imag"] img::attr(src)').extract() response.xpath('//*[@href="image1.html"]')
response.css('*[href="image1.html"]') #6、正则表达式
response.xpath('//a/text()').re(r'Name: (.*)')
response.xpath('//a/text()').re_first(r'Name: (.*)') #7、xpath相对路径
>>> res=response.xpath('//a[contains(@href,"3")]')[0]
>>> res.xpath('img')
[<Selector xpath='img' data='<img src="data:image3_thumb.jpg">'>]
>>> res.xpath('./img')
[<Selector xpath='./img' data='<img src="data:image3_thumb.jpg">'>]
>>> res.xpath('.//img')
[<Selector xpath='.//img' data='<img src="data:image3_thumb.jpg">'>]
>>> res.xpath('//img') #这就是从头开始扫描
[<Selector xpath='//img' data='<img src="data:image1_thumb.jpg">'>, <Selector xpath='//img' data='<img src="data:image2_thumb.jpg">'>, <Selector xpath='//img' data='<img src="data:image3_thumb.jpg">'>, <Selector xpa
th='//img' data='<img src="data:image4_thumb.jpg">'>, <Selector xpath='//img' data='<img src="data:image5_thumb.jpg">'>] #8、带变量的xpath
>>> response.xpath('//div[@id=$xxx]/a/text()',xxx='images').extract_first()
'Name: My image 1 '
>>> response.xpath('//div[count(a)=$yyy]/@id',yyy=5).extract_first() #求有5个a标签的div的id
'images'
详细
https://docs.scrapy.org/en/latest/topics/selectors.html
七、Items
https://docs.scrapy.org/en/latest/topics/items.html
八、Item Pipelin
#一:可以写多个Pipeline类
#1、如果优先级高的Pipeline的process_item返回一个值或者None,会自动传给下一个pipline的process_item,
#2、如果只想让第一个Pipeline执行,那得让第一个pipline的process_item抛出异常raise DropItem() #3、可以用spider.name == '爬虫名' 来控制哪些爬虫用哪些pipeline 二:示范
from scrapy.exceptions import DropItem class CustomPipeline(object):
def __init__(self,v):
self.value = v @classmethod
def from_crawler(cls, crawler):
"""
Scrapy会先通过getattr判断我们是否自定义了from_crawler,有则调它来完
成实例化
"""
val = crawler.settings.getint('MMMM')
return cls(val) def open_spider(self,spider):
"""
爬虫刚启动时执行一次
"""
print('') def close_spider(self,spider):
"""
爬虫关闭时执行一次
"""
print('') def process_item(self, item, spider):
# 操作并进行持久化 # return表示会被后续的pipeline继续处理
return item # 表示将item丢弃,不会被后续pipeline处理
# raise DropItem()
自定义pipeline
'''
#1、settings.py
HOST="127.0.0.1"
PORT=27017
USER="root"
PWD="123"
DB="amazon"
TABLE="goods" '''
from scrapy.exceptions import DropItem
from pymongo import MongoClient class MongoPipeline(object):
'''2、把解析好的item对象做一个持久化,保存到数据库中'''
def __init__(self,db,collection,host,port,user,pwd):
self.db = db
self.collection = collection #文档(表)
self.host = host
self.port = port
self.user = user
self.pwd = pwd @classmethod
def from_crawler(cls,crawler):
'''1、Scrapy会先通过getattr判断我们是否自定义了from_crawler,有则调它来完
成实例化'''
db = crawler.settings.get("DB")
collection = crawler.settings.get("COLLECTION")
host = crawler.settings.get("HOST")
port = crawler.settings.get("PORT")
user = crawler.settings.get("USER")
pwd = crawler.settings.get("PWD")
return cls(db,collection,host,port,user,pwd) #cls是当前的类,类加括号执行__init__方法 def open_spider(self,spider):
'''3、爬虫刚启动时执行一次'''
print('==============>爬虫程序刚刚启动')
self.client = MongoClient('mongodb://%s:%s@%s:%s'%(
self.user,
self.pwd,
self.host,
self.port
)) def close_spider(self,spider):
'''5、关闭爬虫程序'''
print('==============>爬虫程序运行完毕')
self.client.close() def process_item(self, item, spider):
'''4、操作并执行持久化'''
# return表示会被后续的pipeline继续处理
d = dict(item)
if all(d.values()):
self.client[self.db][self.collection].save(d) #保存到数据库
return item
# 表示将item丢弃,不会被后续pipeline处理
# raise DropItem() class FilePipeline(object):
def __init__(self, file_path):
self.file_path=file_path @classmethod
def from_crawler(cls, crawler):
"""
Scrapy会先通过getattr判断我们是否自定义了from_crawler,有则调它来完
成实例化
"""
file_path = crawler.settings.get('FILE_PATH') return cls(file_path) def open_spider(self, spider):
"""
爬虫刚启动时执行一次
"""
print('==============>爬虫程序刚刚启动')
self.fileobj=open(self.file_path,'w',encoding='utf-8') def close_spider(self, spider):
"""
爬虫关闭时执行一次
"""
print('==============>爬虫程序运行完毕')
self.fileobj.close() def process_item(self, item, spider):
# 操作并进行持久化 # return表示会被后续的pipeline继续处理
d = dict(item)
if all(d.values()):
self.fileobj.write(r"%s\n" %str(d)) return item # 表示将item丢弃,不会被后续pipeline处理
# raise DropItem()
示范
https://docs.scrapy.org/en/latest/topics/item-pipeline.html
九、 Dowloader Middeware
下载中间件的用途
1、在process——request内,自定义下载,不用scrapy的下载
2、对请求进行二次加工,比如
设置请求头
设置cookie
添加代理
scrapy自带的代理组件:
from scrapy.downloadermiddlewares.httpproxy import HttpProxyMiddleware
from urllib.request import getproxies
class DownMiddleware1(object):
def process_request(self, request, spider):
"""
请求需要被下载时,经过所有下载器中间件的process_request调用
:param request:
:param spider:
:return:
None,继续后续中间件去下载;
Response对象,停止process_request的执行,开始执行process_response
Request对象,停止中间件的执行,将Request重新调度器
raise IgnoreRequest异常,停止process_request的执行,开始执行process_exception
"""
pass def process_response(self, request, response, spider):
"""
spider处理完成,返回时调用
:param response:
:param result:
:param spider:
:return:
Response 对象:转交给其他中间件process_response
Request 对象:停止中间件,request会被重新调度下载
raise IgnoreRequest 异常:调用Request.errback
"""
print('response1')
return response def process_exception(self, request, exception, spider):
"""
当下载处理器(download handler)或 process_request() (下载中间件)抛出异常
:param response:
:param exception:
:param spider:
:return:
None:继续交给后续中间件处理异常;
Response对象:停止后续process_exception方法
Request对象:停止中间件,request将会被重新调用下载
"""
return None
下载器中间件
from scrapy import signals
from scrapy.http import Response
from scrapy.exceptions import IgnoreRequest
from AMAZON.proxy_handle import get_proxy,delete_proxy
class AmazonSpiderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects. @classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider. # Should return None or raise an exception.
return None def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response. # Must return an iterable of Request, dict or Item objects.
for i in result:
yield i def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception. # Should return either None or an iterable of Response, dict
# or Item objects.
pass def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated. # Must return only requests (not items).
for r in start_requests:
yield r def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name) class AmazonDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects. @classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware. # Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None def process_response(self, request, response, spider):
# Called with the response returned from the downloader. # Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception. # Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name) class DownMiddleware1(object):
def process_request(self, request, spider):
"""
请求需要被下载时,经过所有下载器中间件的process_request调用
:param request:
:param spider:
:return:
None,继续后续中间件去下载;
Response对象,停止process_request的执行,开始执行process_response,会先打印response2,后打印response1
Request对象,停止中间件的执行,将Request重新调度器(无论在那个阶段,只要返回request,就丢给引擎了。)
raise IgnoreRequest异常,停止process_request的执行,开始执行process_exception
"""
# spider.name
print('下载中间件1')
# request.meta['proxy']='http://user:pwd@ip:port'
request.meta['download_timeout']=10 #设置超时时间
request.meta['proxy']='http://'+get_proxy() #request.meta加代理,注意这里的key必须叫proxy
print(request.meta)
# return Response('http://www.xxx.com')
# print(request.dont_filter)
# return request
# raise IgnoreRequest
# raise TimeoutError def process_response(self, request, response, spider):
"""
spider处理完成,返回时调用
:param response:
:param result:
:param spider:
:return:
Response 对象:转交给其他中间件process_response
Request 对象:停止中间件,request会被重新调度下载
raise IgnoreRequest 异常:调用Request.errback
"""
print('response1')
return response def process_exception(self, request, exception, spider):
"""
当下载处理器(download handler)或 process_request() (下载中间件)抛出异常
:param response:
:param exception:
:param spider:
:return:
None:继续交给后续中间件处理异常;
Response对象:停止后续process_exception方法
Request对象:停止中间件,request将会被重新调用下载
"""
print('异常1')
# return None # 删旧代理 delelte request.meta['proxy']
old_proxy=request.meta['proxy'].split("//")[-1]
delete_proxy(old_proxy) #删除就代理, request.meta['proxy']='http://'+get_proxy() #换新代理
return request
配置代理
十、Sider Middlewear
class SpiderMiddleware(object):
def process_spider_input(self,response, spider):
"""
下载完成,执行,然后交给parse处理
:param response:
:param spider:
:return:
"""
pass
def process_spider_output(self,response, result, spider):
"""
spider处理完成,返回时调用
:param response:
:param result:
:param spider:
:return: 必须返回包含 Request 或 Item 对象的可迭代对象(iterable)
"""
return result
def process_spider_exception(self,response, exception, spider):
"""
异常调用
:param response:
:param exception:
:param spider:
:return: None,继续交给后续中间件处理异常;含 Response 或 Item 的可迭代对象(iterable),交给调度器或pipeline
"""
return None
def process_start_requests(self,start_requests, spider):
"""
爬虫启动时调用
:param start_requests:
:param spider:
:return: 包含 Request 对象的可迭代对象
"""
return start_requests
爬虫中间件
十一、自定义扩展
自定义扩展(与django的信号类似)
1、django的信号是django是预留的扩展,信号一旦被触发,相应的功能就会执行
2、scrapy自定义扩展的好处是可以在任意我们想要的位置添加功能,而其他组件中提供的功能只能在规定的位置执行
#1、在与settings同级目录下新建一个文件,文件名可以为extentions.py,内容如下
from scrapy import signals class MyExtension(object):
def __init__(self, value):
self.value = value @classmethod
def from_crawler(cls, crawler):
val = crawler.settings.getint('MMMM')
obj = cls(val) crawler.signals.connect(obj.spider_opened, signal=signals.spider_opened)
crawler.signals.connect(obj.spider_closed, signal=signals.spider_closed) return obj def spider_opened(self, spider):
print('=============>open') def spider_closed(self, spider):
print('=============>close') #2、配置生效
EXTENSIONS = {
"Amazon.extentions.MyExtension":200
}
十二、setitings.py
#==>第一部分:基本配置<===
#1、项目名称,默认的USER_AGENT由它来构成,也作为日志记录的日志名
BOT_NAME = 'Amazon' #2、爬虫应用路径
SPIDER_MODULES = ['Amazon.spiders']
NEWSPIDER_MODULE = 'Amazon.spiders' #3、客户端User-Agent请求头
#USER_AGENT = 'Amazon (+http://www.yourdomain.com)' #4、是否遵循爬虫协议
# Obey robots.txt rules
ROBOTSTXT_OBEY = False #5、是否支持cookie,cookiejar进行操作cookie,默认开启
#COOKIES_ENABLED = False #6、Telnet用于查看当前爬虫的信息,操作爬虫等...使用telnet ip port ,然后通过命令操作
#TELNETCONSOLE_ENABLED = False
#TELNETCONSOLE_HOST = '127.0.0.1'
#TELNETCONSOLE_PORT = [6023,] #7、Scrapy发送HTTP请求默认使用的请求头
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#} #===>第二部分:并发与延迟<===
#1、下载器总共最大处理的并发请求数,默认值16
#CONCURRENT_REQUESTS = 32 #2、每个域名能够被执行的最大并发请求数目,默认值8
#CONCURRENT_REQUESTS_PER_DOMAIN = 16 #3、能够被单个IP处理的并发请求数,默认值0,代表无限制,需要注意两点
#I、如果不为零,那CONCURRENT_REQUESTS_PER_DOMAIN将被忽略,即并发数的限制是按照每个IP来计算,而不是每个域名
#II、该设置也影响DOWNLOAD_DELAY,如果该值不为零,那么DOWNLOAD_DELAY下载延迟是限制每个IP而不是每个域
#CONCURRENT_REQUESTS_PER_IP = 16 #4、如果没有开启智能限速,这个值就代表一个规定死的值,代表对同一网址延迟请求的秒数
#DOWNLOAD_DELAY = 3 #===>第三部分:智能限速/自动节流:AutoThrottle extension<===
#一:介绍
from scrapy.contrib.throttle import AutoThrottle #http://scrapy.readthedocs.io/en/latest/topics/autothrottle.html#topics-autothrottle
设置目标:
1、比使用默认的下载延迟对站点更好
2、自动调整scrapy到最佳的爬取速度,所以用户无需自己调整下载延迟到最佳状态。用户只需要定义允许最大并发的请求,剩下的事情由该扩展组件自动完成 #二:如何实现?
在Scrapy中,下载延迟是通过计算建立TCP连接到接收到HTTP包头(header)之间的时间来测量的。
注意,由于Scrapy可能在忙着处理spider的回调函数或者无法下载,因此在合作的多任务环境下准确测量这些延迟是十分苦难的。 不过,这些延迟仍然是对Scrapy(甚至是服务器)繁忙程度的合理测量,而这扩展就是以此为前提进行编写的。 #三:限速算法
自动限速算法基于以下规则调整下载延迟
#1、spiders开始时的下载延迟是基于AUTOTHROTTLE_START_DELAY的值
#2、当收到一个response,对目标站点的下载延迟=收到响应的延迟时间/AUTOTHROTTLE_TARGET_CONCURRENCY
#3、下一次请求的下载延迟就被设置成:对目标站点下载延迟时间和过去的下载延迟时间的平均值
#4、没有达到200个response则不允许降低延迟
#5、下载延迟不能变的比DOWNLOAD_DELAY更低或者比AUTOTHROTTLE_MAX_DELAY更高 #四:配置使用
#开启True,默认False
AUTOTHROTTLE_ENABLED = True
#起始的延迟
AUTOTHROTTLE_START_DELAY = 5
#最小延迟
DOWNLOAD_DELAY = 3
#最大延迟
AUTOTHROTTLE_MAX_DELAY = 10
#每秒并发请求数的平均值,不能高于 CONCURRENT_REQUESTS_PER_DOMAIN或CONCURRENT_REQUESTS_PER_IP,调高了则吞吐量增大强奸目标站点,调低了则对目标站点更加”礼貌“
#每个特定的时间点,scrapy并发请求的数目都可能高于或低于该值,这是爬虫视图达到的建议值而不是硬限制
AUTOTHROTTLE_TARGET_CONCURRENCY = 16.0
#调试
AUTOTHROTTLE_DEBUG = True
CONCURRENT_REQUESTS_PER_DOMAIN = 16
CONCURRENT_REQUESTS_PER_IP = 16 #===>第四部分:爬取深度与爬取方式<===
#1、爬虫允许的最大深度,可以通过meta查看当前深度;0表示无深度
# DEPTH_LIMIT = 3 #2、爬取时,0表示深度优先Lifo(默认);1表示广度优先FiFo # 后进先出,深度优先
# DEPTH_PRIORITY = 0
# SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleLifoDiskQueue'
# SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.LifoMemoryQueue'
# 先进先出,广度优先 # DEPTH_PRIORITY = 1
# SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleFifoDiskQueue'
# SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.FifoMemoryQueue' #3、调度器队列
# SCHEDULER = 'scrapy.core.scheduler.Scheduler'
# from scrapy.core.scheduler import Scheduler #4、访问URL去重
# DUPEFILTER_CLASS = 'step8_king.duplication.RepeatUrl' #===>第五部分:中间件、Pipelines、扩展<===
#1、Enable or disable spider middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'Amazon.middlewares.AmazonSpiderMiddleware': 543,
#} #2、Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
# 'Amazon.middlewares.DownMiddleware1': 543,
} #3、Enable or disable extensions
# See http://scrapy.readthedocs.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#} #4、Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
# 'Amazon.pipelines.CustomPipeline': 200,
} #===>第六部分:缓存<===
"""
1. 启用缓存
目的用于将已经发送的请求或相应缓存下来,以便以后使用 from scrapy.downloadermiddlewares.httpcache import HttpCacheMiddleware
from scrapy.extensions.httpcache import DummyPolicy
from scrapy.extensions.httpcache import FilesystemCacheStorage
"""
# 是否启用缓存策略
# HTTPCACHE_ENABLED = True # 缓存策略:所有请求均缓存,下次在请求直接访问原来的缓存即可
# HTTPCACHE_POLICY = "scrapy.extensions.httpcache.DummyPolicy"
# 缓存策略:根据Http响应头:Cache-Control、Last-Modified 等进行缓存的策略
# HTTPCACHE_POLICY = "scrapy.extensions.httpcache.RFC2616Policy" # 缓存超时时间
# HTTPCACHE_EXPIRATION_SECS = 0 # 缓存保存路径
# HTTPCACHE_DIR = 'httpcache' # 缓存忽略的Http状态码
# HTTPCACHE_IGNORE_HTTP_CODES = [] # 缓存存储的插件
# HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
settings.py
十三、获取亚马逊商品信息
待续.......
爬虫框架之Scrapy的更多相关文章
- 06 爬虫框架:scrapy
爬虫框架:scrapy 一 介绍 Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速.简单.可扩展的方式从网站中提取所需的数据.但目前S ...
- Python-S9-Day125-Web微信&爬虫框架之scrapy
01 今日内容概要 02 内容回顾:爬虫 03 内容回顾:网络和并发编程 04 Web微信之获取联系人列表 05 Web微信之发送消息 06 为什么request.POST拿不到数据 07 到底使用j ...
- 九、爬虫框架之Scrapy
爬虫框架之Scrapy 一.介绍 二.安装 三.命令行工具 四.项目结构以及爬虫应用简介 五.Spiders 六.Selectors 七.Items 八.Item Pipelin 九. Dowload ...
- 洗礼灵魂,修炼python(72)--爬虫篇—爬虫框架:Scrapy
题外话: 前面学了那么多,相信你已经对python很了解了,对爬虫也很有见解了,然后本来的计划是这样的:(请忽略编号和日期,这个是不定数,我在更博会随时改的) 上面截图的是我的草稿 然后当我开始写博文 ...
- 爬虫框架之Scrapy(四 ImagePipeline)
ImagePipeline 使用scrapy框架我们除了要下载文本,还有可能需要下载图片,scrapy提供了ImagePipeline来进行图片的下载. ImagePipeline还支持以下特别的功能 ...
- 爬虫框架之Scrapy(一)
scrapy简介 scrapy是一个用python实现为了爬取网站数据,提取结构性数据而编写的应用框架,功能非常的强大. scrapy常应用在包括数据挖掘,信息处理或者储存历史数据的一系列程序中. s ...
- 爬虫框架:scrapy
一 介绍 Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速.简单.可扩展的方式从网站中提取所需的数据.但目前Scrapy的用途十分广泛,可 ...
- 爬虫框架之Scrapy(三 CrawlSpider)
如何爬取一个网站的全站数据? 可以使用Scrapy中基于Spider的递归方式进行爬取(Request模块回调parse方法) 还有一种更高效的方法,就是基于CrawlSpider的自动爬取实现 简介 ...
- 爬虫框架之Scrapy(二)
递归解析 糗事百科递归解析 在前面的例子里只是爬取了糗事百科热门的第一个页面,但是当我们需要爬取更多的页面时,需要对每个页面的url依次发起请求,然后通过解析的方法进行作者和标题的解析. 我们可以构建 ...
随机推荐
- 第27月第18天 epoll lt et
1. While the usage of epoll when employed as a level-triggered interface does have the same semantic ...
- drawImg、x5浏览器、react
- Javascript - ExtJs - XTemplate组件
XTemplate组件(Ext.XTemplate) 如果有一些重复的html代码需要装入数据,可以考虑使用XTemplate模板组件.XTemplate可以填入数组.对象,支持条件判断.for循环. ...
- SpringCloud知识点20190313
1.SpringBoot和SpringCloud的关系(面试题) Spring Boot 可以离开 Spring Cloud 单独使用开发项目,但是Spring Cloud离不开SpringBoot, ...
- RabbitMQ简单应用の公平分发(fair dipatch)
公平分发(fair dipatch)和轮询分发其实基本一致,只是每次分发的机制变了,由原来的平均分配到现在每次只处理一条消息 1.MQ连接工厂类Connection package com.mmr.r ...
- C++ 仿函数
先考虑一个简单的例子:假设有一个vector<string>,你的任务是统计长度小于5的string的个数,如果使用count_if函数的话,你的代码可能长成这样: 1 bool Leng ...
- TensorFlow学习笔记:共享变量
本文是根据 TensorFlow 官方教程翻译总结的学习笔记,主要介绍了在 TensorFlow 中如何共享参数变量. 教程中首先引入共享变量的应用场景,紧接着用一个例子介绍如何实现共享变量(主要涉及 ...
- QML 从入门到放弃 第二卷
第二卷如何更快速的放弃,注重的是C++和QML的交互 <1>记事本.. (1) 先测试下不在QML创建C++对象,仅仅在main.cpp添加一个属性函数供调用. 注意只使用槽函数来做到. ...
- Eclipse下egit插件的使用
接触GIT已经很久了,但碰到的公司一直都在使用SVN,并因为各种理由拒绝换成GIT.今年换了份工作,乘着搭建公司新框架和项目的机会,总算在正式项目上使用了GIT.GIT的服务器直接就用了https:/ ...
- 设计模式C++学习笔记之十五(Composite组合模式)
15.1.解释 概念:将对象组合成树形结构以表示“部分-整体”的层次结构.Composite使得用户对单个对象和组合的使用具有一致性. main(),客户 CCorpNode,抽象基类,实现基本信 ...