tensorflow(2):神经网络优化(loss,learning_rate)
案例: 预测酸奶的日销量, 由此可以准备产量, 使得损失小(利润大),假设销量是y , 影响销量的有两个因素x1, x2,
需要预先采集数据,每日的x1,x2和销量y_, 拟造数据集X,Y_, 假设y_=x1+x2,为了更真实加一个噪声(-0.05-0.05)
batch_size=8 #一次喂给神经网络多少数据
seed=23455
#构造数据集
rdm=np.random.RandomState(seed) #基于seed产生随机数
X=rdm.rand(32,2) #32组数据
Y_=[[x1+x2+(rdm.rand()/10.0-0.05)] for (x1,x2) in X] #rdm.rand()/10.0 是(0,1)随机数
print('X:\n',X)
print('Y_:\n',Y_)
#定义神经网络的输入 参数 输出 定义前向传播过程
x=tf.placeholder(tf.float32,shape=(None,2))
y_=tf.placeholder(tf.float32,shape=(None,1)) # 合格或者不合格的特征
w1=tf.Variable(tf.random_normal([2,1],stddev=1,seed=1))
y=tf.matmul(x,w1)
#定义损失函数 后向传播方法
loss_mse=tf.reduce_mean(tf.square(y_-y))
train_step=tf.train.GradientDescentOptimizer(0.001).minimize(loss_mse)
#train_step=tf.train.MomentumOptimizer(0.001,0.9).minimize(loss) #其他方法
#train_step=tf.train.AdamOptimizer(0.001).minimize(loss) #生成会话 训练
with tf.Session() as sess: #用会话计算结果
init_op=tf.global_variables_initializer()
sess.run(init_op)
print('w1:\n', sess.run(w1)) #输出目前(未经训练的)参数取值
#训练模型
steps=20000 #训练20000次
for i in range(steps):
start=(i*batch_size) %32
end=start+batch_size
sess.run(train_step,feed_dict={x:X[start:end],y_:Y_[start:end]}) #8组数据
if i % 500==0: #每500轮打印一次w1值
print('After %d training steps,w1 is:' %i)
print(sess.run(w1),'\n')
print('Final w1 is:',sess.run(w1)) 结果显示 w1=[0.98,1.015] 这与Y_=x1+x2一致,预测正确!!
1.loss优化
上述例子中, loss函数是均方和, 但是实际中,预测的销量(即要准备的产量y_) 与真实的销量y 之间的差异导致的损失 取决于 生产成本cost 与销售利润profit,
当预测多了, 损失成本, 预测少了,损失利润,
所以这里要自定义loss, 上述代码不变,只需要修改下loss参数

batch_size=8 #一次喂给神经网络多少数据
seed=23455
cost=1
profit=9
#构造数据集
rdm=np.random.RandomState(seed) #基于seed产生随机数
X=rdm.rand(32,2) #32组数据
Y_=[[x1+x2+(rdm.rand()/10.0-0.05)] for (x1,x2) in X] #rdm.rand()/10.0 是(0,1)随机数
print('X:\n',X)
print('Y_:\n',Y_)
#定义神经网络的输入 参数 输出 定义前向传播过程
x=tf.placeholder(tf.float32,shape=(None,2))
y_=tf.placeholder(tf.float32,shape=(None,1)) # 合格或者不合格的特征
w1=tf.Variable(tf.random_normal([2,1],stddev=1,seed=1))
y=tf.matmul(x,w1)
#定义损失函数 后向传播方法
loss=tf.reduce_sum(tf.where(tf.greater(y,y_),cost*(y-y_),profit*(y_-y)))
#tf.where(tf.greater(y,y_),cost*(y-y_),profit*(y_-y))第一个表示逻辑值,当为真时取第二项
#为假时取第三项
train_step=tf.train.GradientDescentOptimizer(0.001).minimize(loss)
#train_step=tf.train.MomentumOptimizer(0.001,0.9).minimize(loss) #其他方法
#train_step=tf.train.AdamOptimizer(0.001).minimize(loss) #生成会话 训练
with tf.Session() as sess: #用会话计算结果
init_op=tf.global_variables_initializer()
sess.run(init_op)
print('w1:\n', sess.run(w1)) #输出目前(未经训练的)参数取值
#训练模型
steps=20000 #训练3000次
for i in range(steps):
start=(i*batch_size) %32
end=start+batch_size
sess.run(train_step,feed_dict={x:X[start:end],y_:Y_[start:end]}) #8组数据
if i % 500==0: #每500轮打印一次结果
print('After %d training steps,w1 is:' %i)
print(sess.run(w1),'\n')
print('Final w1 is:',sess.run(w1))
得到结果是w1=[1.02,1.04] ,系数都大于1 ,这是由于多预测的损失 少于少预测的损失,结果也往多的方向预测了.要是 cost=9 ,profit=1,
最终得到参数w1=[0.96, 0.97] 都小于1
除了均方和, 自定义loss只要, 还有第三种 交叉熵(cross entropy)的loss,
交叉熵(cross entropy): 表示两个概率分布之间的距离, ce越大,距离也就越大.

交叉熵 ce
ce=-tf.reduce_mean(y_*tf.log(tf.clip_by_value(y,1e-12,1.0)))
n个分类的n输出

ce=tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y,labels=tf.argmax(y_,1))
cem=tf.reduce_mean(ce)
2.learning_rate 学习率调整
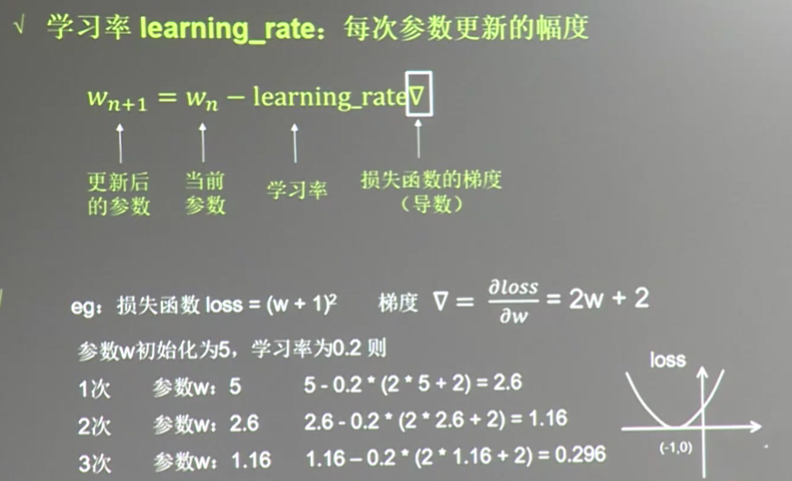
设置learning_rate=0.2
w=tf.Variable(tf.constant(5,dtype=tf.float32))
loss=tf.square(w+1) #定义损失函数
train_step=tf.train.GradientDescentOptimizer(0.2).minimize(loss) with tf.Session() as sess:
init_op=tf.global_variables_initializer()
sess.run(init_op)
for i in range(40): #迭代40次
sess.run(train_step)
w_val=sess.run(w)
loss_val=sess.run(loss)
print('after %d steps, w is %f, loss is %f.'%(i,w_val,loss_val))
若上述learning_rate=0.001, w趋于-1速度很慢, learning_rate=1, w会发散,不会趋于-1
上述learning_rate 不能太大,也不能太小

#学习率 决定参数的更新 learning_rate
#根据运行的轮数决定动态更新学习率
learning_rate=LEARNING_RATE_BASE*LEARNING_RATE_DECAY^(global_step/LEARNING_RATE_STEP)
#LEARNING_RATE_BASE是学习率初始值 LEARNING_RATE_DECAY是学习衰减率(0,1)
#多少轮更新一次学习率,LEARNING_RATE_STEP 一般是总样本数/batch_size
global_step=tf.Variable(0,trainable=False) #记录当前共运行了多少轮batch-size
learning_rate=tf.train.exponential_decay(LEARNING_RATE_BASE,
global_step, LEARNING_RATE_STEP,
LEARNING_RATE_DECAY,
staircase=True)
# staircase true 学习率阶梯型衰减, false则为平滑下降的曲线
#根据运行的轮数决定动态更新学习率
LEARNING_RATE_BASE=0.1 #最初学习率
LEARNING_RATE_DECAY=0.9 #学习率衰减率
LEARNING_RATE_STEP=1 # 喂入多少batch_size后更新一次学习率,一般是总样本数/batch_size,这里为了方便为1 global_step=tf.Variable(0,trainable=False) #记录当前共运行了多少轮batch-size
#定义指数下降学习率
learning_rate=tf.train.exponential_decay(LEARNING_RATE_BASE,
global_step, LEARNING_RATE_STEP,
LEARNING_RATE_DECAY,
staircase=True) #优化参数 ,初值5
w=tf.Variable(tf.constant(5,dtype=tf.float32))
loss=tf.square(w+1) #定义损失函数
train_step=tf.train.GradientDescentOptimizer(learning_rate).minimize(loss,global_step=global_step) with tf.Session() as sess:
init_op=tf.global_variables_initializer()
sess.run(init_op)
for i in range(40): #迭代40次
sess.run(train_step)
learning_rate_val=sess.run(learning_rate)
global_step_val=sess.run(global_step)
w_val=sess.run(w)
loss_val=sess.run(loss)
print('after %d steps, global_step is %f,w is %f, loss is %f.' %(i,global_step_val,w_val,loss_val))
结果:
tensorflow(2):神经网络优化(loss,learning_rate)的更多相关文章
- tensorflow(3):神经网络优化(ema,regularization)
1.指数滑动平均 (ema) 描述滑动平均: with tf.control_dependencies([train_step,ema_op]) 将计算滑动平均与 训练过程绑在一起运行 train_o ...
- Tensorflow学习:(三)神经网络优化
一.完善常用概念和细节 1.神经元模型: 之前的神经元结构都采用线上的权重w直接乘以输入数据x,用数学表达式即,但这样的结构不够完善. 完善的结构需要加上偏置,并加上激励函数.用数学公式表示为:.其中 ...
- tensorflow:实战Google深度学习框架第四章02神经网络优化(学习率,避免过拟合,滑动平均模型)
1.学习率的设置既不能太小,又不能太大,解决方法:使用指数衰减法 例如: 假设我们要最小化函数 y=x2y=x2, 选择初始点 x0=5x0=5 1. 学习率为1的时候,x在5和-5之间震荡. im ...
- 深度学习之TensorFlow构建神经网络层
深度学习之TensorFlow构建神经网络层 基本法 深度神经网络是一个多层次的网络模型,包含了:输入层,隐藏层和输出层,其中隐藏层是最重要也是深度最多的,通过TensorFlow,python代码可 ...
- 通过TensorFlow训练神经网络模型
神经网络模型的训练过程其实质上就是神经网络参数的设置过程 在神经网络优化算法中最常用的方法是反向传播算法,下图是反向传播算法流程图: 从上图可知,反向传播算法实现了一个迭代的过程,在每次迭代的开始,先 ...
- 【零基础】神经网络优化之Adam
一.序言 Adam是神经网络优化的另一种方法,有点类似上一篇中的“动量梯度下降”,实际上是先提出了RMSprop(类似动量梯度下降的优化算法),而后结合RMSprop和动量梯度下降整出了Adam,所以 ...
- tensorflow,model,object_detection,训练loss先下降后递增,到几百万,解决tensorflow,model,object,detection,loss,incease
现象:训练loss一开始下降一部分,跌代到若干次(具体多少和你的learning rate大小有关,大就迭代小就发生,小就需要多几次迭代) 日志如下(下面的日志来源于网络,我自己的日志已经clear掉 ...
- zz图像、神经网络优化利器:了解Halide
动图示例实在太好 图像.神经网络优化利器:了解Halide Oldpan 2019年4月17日 0条评论 1,327次阅读 3人点赞 前言 Halide是用C++作为宿主语言的一个图像处理相 ...
- 神经网络优化算法:梯度下降法、Momentum、RMSprop和Adam
最近回顾神经网络的知识,简单做一些整理,归档一下神经网络优化算法的知识.关于神经网络的优化,吴恩达的深度学习课程讲解得非常通俗易懂,有需要的可以去学习一下,本人只是对课程知识点做一个总结.吴恩达的深度 ...
随机推荐
- mkyaffs2image 生成不了120M的镜像文件的解决方法
下载链接: http://download.csdn.net/download/macrocrazier/3807761 用上述下载的链接会出现Failed to execute /linuxrc ...
- asyncio模块中的Future和Task
task是可以理解为单个coroutine,经过ensure_future方法处理而形成,而众多task所组成的集合经过asyncio.gather处理而形成一个future. 再不精确的粗略的说 ...
- Invalid bound statement (not found) 找不到mapper 映射文件异常
访问页面报如下错(注意第一行后面的 invalid bound statement (not found)) 这时候再mapper的pom.xml文件要加如下. 否则该节点mybatis的mapper ...
- mongodb 案例 ~ 经典故障案例
一 简介:此文汇总遇到过和搜集过的故障案例 二 场景案例 1 问题描述: mongo集群在无任何业务情况下,mongos所在服务器cpu突然被打满,内核日志报错 mongos被hung住,非常奇怪的问 ...
- IntelliJ IDEA执行maven 跳过test
- 【python小练习】简单的猜数字游戏
简单的猜数字游戏 前两天在论坛回答问题时候,看到一个猜数字的游戏,就在原来的基础上改了一下,玩一玩. 此程序,数字范围和尝试次数是事先设定好的,当然可以通过代码修改.经过测试,由于难度过大,我在其中加 ...
- ASP.NET - 学习总目录
ASP.NET - 处理页面 ASP.NET - ADO.NET框架 ASP.NET - 创建功能菜单 ASP.NET MVC - 入门 ASP.NET MVC - 模型验证 ASP.NET MVC ...
- java知识点3
高级篇 新技术 Java 8 lambda表达式.Stream API. Java 9 Jigsaw.Jshell.Reactive Streams Java 10 局部变量类型推断.G1的并行Ful ...
- vue中过滤器filters的使用
组件内写法 filters:{ filter:function(data,arg1,arg2){ return .... } } 全局写法 filters('filter',function(data ...
- Linux系统启动那些事—基于Linux 3.10内核【转】
转自:https://blog.csdn.net/shichaog/article/details/40218763 Linux系统启动那些事—基于Linux 3.10内核 csdn 我的空间的下载地 ...