tensorflow:验证码的识别(中)
三、训练识别模型
首先先拷贝一个nets文件夹,主要使用的是文件夹下的两个文件nets_factory.py、alexnet.py,用于导入训练使用的网络alexnet。
nets_factory.py
# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Contains a factory for building various models.""" from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import functools import tensorflow as tf from nets import alexnet
from nets import cifarnet
from nets import inception
from nets import lenet
from nets import overfeat
from nets import resnet_v1
from nets import resnet_v2
from nets import vgg slim = tf.contrib.slim networks_map = {'alexnet_v2': alexnet.alexnet_v2,
'cifarnet': cifarnet.cifarnet,
'overfeat': overfeat.overfeat,
'vgg_a': vgg.vgg_a,
'vgg_16': vgg.vgg_16,
'vgg_19': vgg.vgg_19,
'inception_v1': inception.inception_v1,
'inception_v2': inception.inception_v2,
'inception_v3': inception.inception_v3,
'inception_v4': inception.inception_v4,
'inception_resnet_v2': inception.inception_resnet_v2,
'lenet': lenet.lenet,
'resnet_v1_50': resnet_v1.resnet_v1_50,
'resnet_v1_101': resnet_v1.resnet_v1_101,
'resnet_v1_152': resnet_v1.resnet_v1_152,
'resnet_v1_200': resnet_v1.resnet_v1_200,
'resnet_v2_50': resnet_v2.resnet_v2_50,
'resnet_v2_101': resnet_v2.resnet_v2_101,
'resnet_v2_152': resnet_v2.resnet_v2_152,
'resnet_v2_200': resnet_v2.resnet_v2_200,
} arg_scopes_map = {'alexnet_v2': alexnet.alexnet_v2_arg_scope,
'cifarnet': cifarnet.cifarnet_arg_scope,
'overfeat': overfeat.overfeat_arg_scope,
'vgg_a': vgg.vgg_arg_scope,
'vgg_16': vgg.vgg_arg_scope,
'vgg_19': vgg.vgg_arg_scope,
'inception_v1': inception.inception_v3_arg_scope,
'inception_v2': inception.inception_v3_arg_scope,
'inception_v3': inception.inception_v3_arg_scope,
'inception_v4': inception.inception_v4_arg_scope,
'inception_resnet_v2':
inception.inception_resnet_v2_arg_scope,
'lenet': lenet.lenet_arg_scope,
'resnet_v1_50': resnet_v1.resnet_arg_scope,
'resnet_v1_101': resnet_v1.resnet_arg_scope,
'resnet_v1_152': resnet_v1.resnet_arg_scope,
'resnet_v1_200': resnet_v1.resnet_arg_scope,
'resnet_v2_50': resnet_v2.resnet_arg_scope,
'resnet_v2_101': resnet_v2.resnet_arg_scope,
'resnet_v2_152': resnet_v2.resnet_arg_scope,
'resnet_v2_200': resnet_v2.resnet_arg_scope,
} def get_network_fn(name, num_classes, weight_decay=0.0, is_training=False):
"""Returns a network_fn such as `logits, end_points = network_fn(images)`. Args:
name: The name of the network.
num_classes: The number of classes to use for classification.
weight_decay: The l2 coefficient for the model weights.
is_training: `True` if the model is being used for training and `False`
otherwise. Returns:
network_fn: A function that applies the model to a batch of images. It has
the following signature:
logits, end_points = network_fn(images)
Raises:
ValueError: If network `name` is not recognized.
"""
if name not in networks_map:
raise ValueError('Name of network unknown %s' % name)
func = networks_map[name]
@functools.wraps(func)
def network_fn(images):
arg_scope = arg_scopes_map[name](weight_decay=weight_decay)
with slim.arg_scope(arg_scope):
return func(images, num_classes, is_training=is_training)
if hasattr(func, 'default_image_size'):
network_fn.default_image_size = func.default_image_size return network_fn
alexnet.py
对源码做出一定的修改,前面的卷积和池化作为共享层保持不变,主要就是修改最后的输出。net0-net3
# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Contains a model definition for AlexNet. This work was first described in:
ImageNet Classification with Deep Convolutional Neural Networks
Alex Krizhevsky, Ilya Sutskever and Geoffrey E. Hinton and later refined in:
One weird trick for parallelizing convolutional neural networks
Alex Krizhevsky, 2014 Here we provide the implementation proposed in "One weird trick" and not
"ImageNet Classification", as per the paper, the LRN layers have been removed. Usage:
with slim.arg_scope(alexnet.alexnet_v2_arg_scope()):
outputs, end_points = alexnet.alexnet_v2(inputs) @@alexnet_v2
""" from __future__ import absolute_import
from __future__ import division
from __future__ import print_function import tensorflow as tf slim = tf.contrib.slim
trunc_normal = lambda stddev: tf.truncated_normal_initializer(0.0, stddev) def alexnet_v2_arg_scope(weight_decay=0.0005):
with slim.arg_scope([slim.conv2d, slim.fully_connected],
activation_fn=tf.nn.relu,
biases_initializer=tf.constant_initializer(0.1),
weights_regularizer=slim.l2_regularizer(weight_decay)):
with slim.arg_scope([slim.conv2d], padding='SAME'):
with slim.arg_scope([slim.max_pool2d], padding='VALID') as arg_sc:
return arg_sc def alexnet_v2(inputs,
num_classes=1000,
is_training=True,
dropout_keep_prob=0.5,
spatial_squeeze=True,
scope='alexnet_v2'):
"""AlexNet version 2. Described in: http://arxiv.org/pdf/1404.5997v2.pdf
Parameters from:
github.com/akrizhevsky/cuda-convnet2/blob/master/layers/
layers-imagenet-1gpu.cfg Note: All the fully_connected layers have been transformed to conv2d layers.
To use in classification mode, resize input to 224x224. To use in fully
convolutional mode, set spatial_squeeze to false.
The LRN layers have been removed and change the initializers from
random_normal_initializer to xavier_initializer. Args:
inputs: a tensor of size [batch_size, height, width, channels].
num_classes: number of predicted classes.
is_training: whether or not the model is being trained.
dropout_keep_prob: the probability that activations are kept in the dropout
layers during training.
spatial_squeeze: whether or not should squeeze the spatial dimensions of the
outputs. Useful to remove unnecessary dimensions for classification.
scope: Optional scope for the variables. Returns:
the last op containing the log predictions and end_points dict.
"""
with tf.variable_scope(scope, 'alexnet_v2', [inputs]) as sc:
end_points_collection = sc.name + '_end_points'
# Collect outputs for conv2d, fully_connected and max_pool2d.
with slim.arg_scope([slim.conv2d, slim.fully_connected, slim.max_pool2d],
outputs_collections=[end_points_collection]):
net = slim.conv2d(inputs, 64, [11, 11], 4, padding='VALID',
scope='conv1')
net = slim.max_pool2d(net, [3, 3], 2, scope='pool1')
net = slim.conv2d(net, 192, [5, 5], scope='conv2')
net = slim.max_pool2d(net, [3, 3], 2, scope='pool2')
net = slim.conv2d(net, 384, [3, 3], scope='conv3')
net = slim.conv2d(net, 384, [3, 3], scope='conv4')
net = slim.conv2d(net, 256, [3, 3], scope='conv5')
net = slim.max_pool2d(net, [3, 3], 2, scope='pool5') # Use conv2d instead of fully_connected layers.
with slim.arg_scope([slim.conv2d],
weights_initializer=trunc_normal(0.005),
biases_initializer=tf.constant_initializer(0.1)):
net = slim.conv2d(net, 4096, [5, 5], padding='VALID',
scope='fc6')
net = slim.dropout(net, dropout_keep_prob, is_training=is_training,
scope='dropout6')
net = slim.conv2d(net, 4096, [1, 1], scope='fc7')
net = slim.dropout(net, dropout_keep_prob, is_training=is_training,
scope='dropout7')
net0 = slim.conv2d(net, num_classes, [1, 1],
activation_fn=None,
normalizer_fn=None,
biases_initializer=tf.zeros_initializer(),
scope='fc8_0')
net1 = slim.conv2d(net, num_classes, [1, 1],
activation_fn=None,
normalizer_fn=None,
biases_initializer=tf.zeros_initializer(),
scope='fc8_1')
net2 = slim.conv2d(net, num_classes, [1, 1],
activation_fn=None,
normalizer_fn=None,
biases_initializer=tf.zeros_initializer(),
scope='fc8_2')
net3 = slim.conv2d(net, num_classes, [1, 1],
activation_fn=None,
normalizer_fn=None,
biases_initializer=tf.zeros_initializer(),
scope='fc8_3') # Convert end_points_collection into a end_point dict.
end_points = slim.utils.convert_collection_to_dict(end_points_collection)
if spatial_squeeze:
net0 = tf.squeeze(net0, [1, 2], name='fc8_0/squeezed')
end_points[sc.name + '/fc8_0'] = net0
net1 = tf.squeeze(net1, [1, 2], name='fc8_1/squeezed')
end_points[sc.name + '/fc8_1'] = net1
net2 = tf.squeeze(net2, [1, 2], name='fc8_2/squeezed')
end_points[sc.name + '/fc8_2'] = net2
net3 = tf.squeeze(net3, [1, 2], name='fc8_3/squeezed')
end_points[sc.name + '/fc8_3'] = net3 return net0,net1,net2,net3,end_points
alexnet_v2.default_image_size = 224
train.py
import os
import tensorflow as tf
from PIL import Image
from nets import nets_factory
import numpy as np # 不同字符数量
CHAR_SET_LEN = 10
# 图片高度
IMAGE_HEIGHT = 60
# 图片宽度
IMAGE_WIDTH = 160
# 批次
BATCH_SIZE = 25
# tfrecord文件存放路径
TFRECORD_FILE = "F:/PyCharm-projects/第十周/train.tfrecords" # placeholder
x = tf.placeholder(tf.float32, [None, 224, 224])
y0 = tf.placeholder(tf.float32, [None])
y1 = tf.placeholder(tf.float32, [None])
y2 = tf.placeholder(tf.float32, [None])
y3 = tf.placeholder(tf.float32, [None]) # 学习率
lr = tf.Variable(0.003, dtype=tf.float32) # 从tfrecord读出数据
def read_and_decode(filename):
# 根据文件名生成一个队列
filename_queue = tf.train.string_input_producer([filename])
reader = tf.TFRecordReader()
# 返回文件名和文件
_, serialized_example = reader.read(filename_queue)
features = tf.parse_single_example(serialized_example,
features={
'image': tf.FixedLenFeature([], tf.string),
'label0': tf.FixedLenFeature([], tf.int64),
'label1': tf.FixedLenFeature([], tf.int64),
'label2': tf.FixedLenFeature([], tf.int64),
'label3': tf.FixedLenFeature([], tf.int64),
})
# 获取图片数据
image = tf.decode_raw(features['image'], tf.uint8)
# tf.train.shuffle_batch必须确定shape
image = tf.reshape(image, [224, 224])
# 图片预处理
image = tf.cast(image, tf.float32) / 255.0
image = tf.subtract(image, 0.5)
image = tf.multiply(image, 2.0)
# 获取label
label0 = tf.cast(features['label0'], tf.int32)
label1 = tf.cast(features['label1'], tf.int32)
label2 = tf.cast(features['label2'], tf.int32)
label3 = tf.cast(features['label3'], tf.int32) return image, label0, label1, label2, label3 # In[3]: # 获取图片数据和标签
image, label0, label1, label2, label3 = read_and_decode(TFRECORD_FILE) # 使用shuffle_batch可以随机打乱
image_batch, label_batch0, label_batch1, label_batch2, label_batch3 = tf.train.shuffle_batch(
[image, label0, label1, label2, label3], batch_size=BATCH_SIZE,
capacity=50000, min_after_dequeue=10000, num_threads=1) # 定义网络结构
train_network_fn = nets_factory.get_network_fn(
'alexnet_v2',
num_classes=CHAR_SET_LEN,
weight_decay=0.0005,
is_training=True) with tf.Session() as sess:
# inputs: a tensor of size [batch_size, height, width, channels]
X = tf.reshape(x, [BATCH_SIZE, 224, 224, 1])
# 数据输入网络得到输出值
logits0, logits1, logits2, logits3, end_points = train_network_fn(X) # 把标签转成one_hot的形式
one_hot_labels0 = tf.one_hot(indices=tf.cast(y0, tf.int32), depth=CHAR_SET_LEN)
one_hot_labels1 = tf.one_hot(indices=tf.cast(y1, tf.int32), depth=CHAR_SET_LEN)
one_hot_labels2 = tf.one_hot(indices=tf.cast(y2, tf.int32), depth=CHAR_SET_LEN)
one_hot_labels3 = tf.one_hot(indices=tf.cast(y3, tf.int32), depth=CHAR_SET_LEN) # 计算loss
loss0 = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits0, labels=one_hot_labels0))
loss1 = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits1, labels=one_hot_labels1))
loss2 = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits2, labels=one_hot_labels2))
loss3 = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits3, labels=one_hot_labels3))
# 计算总的loss
total_loss = (loss0 + loss1 + loss2 + loss3) / 4.0
# 优化total_loss
optimizer = tf.train.AdamOptimizer(learning_rate=lr).minimize(total_loss) # 计算准确率
correct_prediction0 = tf.equal(tf.argmax(one_hot_labels0, 1), tf.argmax(logits0, 1))
accuracy0 = tf.reduce_mean(tf.cast(correct_prediction0, tf.float32)) correct_prediction1 = tf.equal(tf.argmax(one_hot_labels1, 1), tf.argmax(logits1, 1))
accuracy1 = tf.reduce_mean(tf.cast(correct_prediction1, tf.float32)) correct_prediction2 = tf.equal(tf.argmax(one_hot_labels2, 1), tf.argmax(logits2, 1))
accuracy2 = tf.reduce_mean(tf.cast(correct_prediction2, tf.float32)) correct_prediction3 = tf.equal(tf.argmax(one_hot_labels3, 1), tf.argmax(logits3, 1))
accuracy3 = tf.reduce_mean(tf.cast(correct_prediction3, tf.float32)) # 用于保存模型
saver = tf.train.Saver()
# 初始化
sess.run(tf.global_variables_initializer()) # 创建一个协调器,管理线程
coord = tf.train.Coordinator()
# 启动QueueRunner, 此时文件名队列已经进队
threads = tf.train.start_queue_runners(sess=sess, coord=coord) for i in range(4001):
# 获取一个批次的数据和标签
b_image, b_label0, b_label1, b_label2, b_label3 = sess.run(
[image_batch, label_batch0, label_batch1, label_batch2, label_batch3])
# 优化模型
sess.run(optimizer, feed_dict={x: b_image, y0: b_label0, y1: b_label1, y2: b_label2, y3: b_label3}) # 每迭代50次计算一次loss和准确率
if i % 50 == 0:
# 每迭代2000次降低一次学习率
if i % 2000 == 0:
sess.run(tf.assign(lr, lr / 3))
acc0, acc1, acc2, acc3, loss_ = sess.run([accuracy0, accuracy1, accuracy2, accuracy3, total_loss],
feed_dict={x: b_image,
y0: b_label0,
y1: b_label1,
y2: b_label2,
y3: b_label3})
learning_rate = sess.run(lr)
print("Iter:%d Loss:%.3f Accuracy:%.2f,%.2f,%.2f,%.2f Learning_rate:%.4f" % (
i, loss_, acc0, acc1, acc2, acc3, learning_rate)) # 保存模型
# if acc0 > 0.90 and acc1 > 0.90 and acc2 > 0.90 and acc3 > 0.90:
if i == 4000:
saver.save(sess, "./captcha/models/crack_captcha.model", global_step=i)
break # 通知其他线程关闭
coord.request_stop()
# 其他所有线程关闭之后,这一函数才能返回
coord.join(threads)
Iter:0 Loss:2315.252 Accuracy:0.20,0.28,0.20,0.12 Learning_rate:0.0010
Iter:50 Loss:2.312 Accuracy:0.08,0.08,0.00,0.04 Learning_rate:0.0010
......
Iter:3850 Loss:0.055 Accuracy:0.96,0.96,1.00,0.96 Learning_rate:0.0003
Iter:3900 Loss:0.041 Accuracy:1.00,0.92,1.00,1.00 Learning_rate:0.0003
Iter:3950 Loss:0.025 Accuracy:1.00,1.00,1.00,1.00 Learning_rate:0.0003
从train.tfrecord读出数据和标签,打乱,将数据送入alexnet网络得到输出值,将输出的标签转化为one_hot形式,计算loss,对loss求和得total_loss并用优化器优化。计算准确率,迭代40001次,保存模型。
四、测试模型
import os
import tensorflow as tf
from PIL import Image
from nets import nets_factory
import numpy as np
import matplotlib.pyplot as plt # 不同字符数量
CHAR_SET_LEN = 10
# 图片高度
IMAGE_HEIGHT = 60
# 图片宽度
IMAGE_WIDTH = 160
# 批次
BATCH_SIZE = 1
# tfrecord文件存放路径
TFRECORD_FILE = "F:/PyCharm-projects/第十周/test.tfrecords" # placeholder
x = tf.placeholder(tf.float32, [None, 224, 224]) # 从tfrecord读出数据
def read_and_decode(filename):
# 根据文件名生成一个队列
filename_queue = tf.train.string_input_producer([filename])
reader = tf.TFRecordReader()
# 返回文件名和文件
_, serialized_example = reader.read(filename_queue)
features = tf.parse_single_example(serialized_example,
features={
'image' : tf.FixedLenFeature([], tf.string),
'label0': tf.FixedLenFeature([], tf.int64),
'label1': tf.FixedLenFeature([], tf.int64),
'label2': tf.FixedLenFeature([], tf.int64),
'label3': tf.FixedLenFeature([], tf.int64),
})
# 获取图片数据
image = tf.decode_raw(features['image'], tf.uint8)
# 没有经过预处理的灰度图
image_raw = tf.reshape(image, [224, 224])
# tf.train.shuffle_batch必须确定shape
image = tf.reshape(image, [224, 224])
# 图片预处理
image = tf.cast(image, tf.float32) / 255.0
image = tf.subtract(image, 0.5)
image = tf.multiply(image, 2.0)
# 获取label
label0 = tf.cast(features['label0'], tf.int32)
label1 = tf.cast(features['label1'], tf.int32)
label2 = tf.cast(features['label2'], tf.int32)
label3 = tf.cast(features['label3'], tf.int32) return image, image_raw, label0, label1, label2, label3 # In[3]: # 获取图片数据和标签
image, image_raw, label0, label1, label2, label3 = read_and_decode(TFRECORD_FILE) #使用shuffle_batch可以随机打乱
image_batch, image_raw_batch, label_batch0, label_batch1, label_batch2, label_batch3 = tf.train.shuffle_batch(
[image, image_raw, label0, label1, label2, label3], batch_size = BATCH_SIZE,
capacity = 50000, min_after_dequeue=10000, num_threads=1) #定义网络结构
train_network_fn = nets_factory.get_network_fn(
'alexnet_v2',
num_classes=CHAR_SET_LEN,
weight_decay=0.0005,
is_training=False) with tf.Session() as sess:
# inputs: a tensor of size [batch_size, height, width, channels]
X = tf.reshape(x, [BATCH_SIZE, 224, 224, 1])
# 数据输入网络得到输出值
logits0,logits1,logits2,logits3,end_points = train_network_fn(X) # 预测值
predict0 = tf.reshape(logits0, [-1, CHAR_SET_LEN])
predict0 = tf.argmax(predict0, 1) predict1 = tf.reshape(logits1, [-1, CHAR_SET_LEN])
predict1 = tf.argmax(predict1, 1) predict2 = tf.reshape(logits2, [-1, CHAR_SET_LEN])
predict2 = tf.argmax(predict2, 1) predict3 = tf.reshape(logits3, [-1, CHAR_SET_LEN])
predict3 = tf.argmax(predict3, 1) # 初始化
sess.run(tf.global_variables_initializer())
# 载入训练好的模型
saver = tf.train.Saver()
saver.restore(sess,'./captcha/models/crack_captcha.model-4000') # 创建一个协调器,管理线程
coord = tf.train.Coordinator()
# 启动QueueRunner, 此时文件名队列已经进队
threads = tf.train.start_queue_runners(sess=sess, coord=coord) for i in range(10):
# 获取一个批次的数据和标签
b_image, b_image_raw, b_label0, b_label1 ,b_label2 ,b_label3 = sess.run([image_batch,
image_raw_batch,
label_batch0,
label_batch1,
label_batch2,
label_batch3])
# 显示图片
img=Image.fromarray(b_image_raw[0],'L')
plt.imshow(img)
plt.axis('off')
plt.show()
# 打印标签
print('label:',b_label0, b_label1 ,b_label2 ,b_label3)
# 预测
label0,label1,label2,label3 = sess.run([predict0,predict1,predict2,predict3], feed_dict={x: b_image})
# 打印预测值
print('predict:',label0,label1,label2,label3) # 通知其他线程关闭
coord.request_stop()
# 其他所有线程关闭之后,这一函数才能返回
coord.join(threads)

label: [5] [1] [3] [7]
predict: [5] [0] [3] [7]
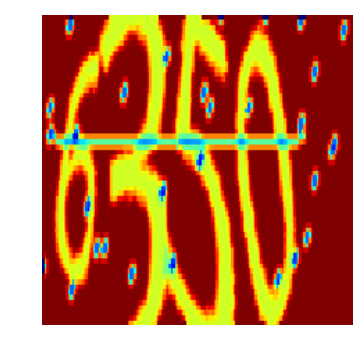
label: [6] [3] [5] [0]
predict: [6] [3] [5] [0]
.....
tensorflow:验证码的识别(中)的更多相关文章
- tensorflow:验证码的识别(下)
上两篇详细的说明了验证码的识别,不过我们采用的是方法二,下面采用方法一.注意和方法二的区别. 验证码识别方法一: 把标签转为向量,向量长度为40.(4位数字验证码) 验证码的生成和tf.record的 ...
- tensorflow:验证码的识别(上)
验证码的识别 主要分成四个部分:验证码的生成.将生成的图片制作成tfrecord文件.训练识别模型.测试模型 使用pyCharm作为编译器.本文先介绍前两个部分 验证码的识别有两种方法: 验证码识别方 ...
- TensorFlow验证码识别
本节我们来用 TensorFlow 来实现一个深度学习模型,用来实现验证码识别的过程,这里我们识别的验证码是图形验证码,首先我们会用标注好的数据来训练一个模型,然后再用模型来实现这个验证码的识别. 验 ...
- 使用TensorFlow进行训练识别视频图像中物体
本教程针对Windows10实现谷歌公布的TensorFlow Object Detection API视频物体识别系统,其他平台也可借鉴. 本教程将网络上相关资料筛选整合(文末附上参考资料链接),旨 ...
- e2e 自动化集成测试 架构 实例 WebStorm Node.js Mocha WebDriverIO Selenium Step by step (二) 图片验证码的识别
上一篇文章讲了“e2e 自动化集成测试 架构 京东 商品搜索 实例 WebStorm Node.js Mocha WebDriverIO Selenium Step by step 一 京东 商品搜索 ...
- Python爬虫学习笔记之微信宫格验证码的识别(存在问题)
本节我们将介绍新浪微博宫格验证码的识别.微博宫格验证码是一种新型交互式验证码,每个宫格之间会有一条 指示连线,指示了应该的滑动轨迹.我们要按照滑动轨迹依次从起始宫格滑动到终止宫格,才可以完成验证,如 ...
- 爬虫(十二):图形验证码的识别、滑动验证码的识别(B站滑动验证码)
1. 验证码识别 随着爬虫的发展,越来越多的网站开始采用各种各样的措施来反爬虫,其中一个措施便是使用验证码.随着技术的发展,验证码也越来越花里胡哨的了.最开始就是几个数字随机组成的图像验证码,后来加入 ...
- python实现对简单的运算型验证码的识别【不使用OpenCV】
最近在写我们学校的教务系统的手机版,在前端用户执行绑定操作后,服务器将执行登录,但在登录过程中,教务系统中有个运算型的验证码,大致是这个样子的: 下面我们开始实现这个验证码的识别. 1.图片读取 从网 ...
- SOM聚类与Voroni图在验证码字符分割中的应用
http://www.docin.com/p-1300981517.html SOM聚类与Voroni图在验证码字符分割中的应用
- TensorFlow环境 人脸识别 FaceNet 应用(一)验证测试集
TensorFlow环境 人脸识别 FaceNet 应用(一)验证测试集 前提是TensorFlow环境以及相关的依赖环境已经安装,可以正常运行. 一.下载FaceNet源代码工程 git clone ...
随机推荐
- centos 秘钥登陆配置
准备:2台机器,ip分别为:10.1.80.13 10.1.80.14 目的:通过13 ssh远程访问14.无需输入密码 1.首先在10.1.80.13上生成密钥对.cd /root/.ssh ...
- NTSC、PAL、SECAM三大制式简介
NTSC.PAL.SECAM三大制式简介 NTSC.PAL和SECAM是全球三大主要的电视广播制式,这三种制式是不能互相兼容的,例如在PAL制式的电视上播放NTSC的视频,则影像画面将不能正常显示.下 ...
- codeforces 412div.2
A CodeForces 807A Is it rated? B CodeForces 807B T-Shirt Hunt C CodeForces 807C Success ...
- C#红绿状态灯
1.在Label里 画圆,存在窗体刷新会丢失画. public void SetShowConnectStatus(Label lbl, bool isOk) { lbl.Text = "& ...
- 使用lld自动发现监控多实例redis
zabbix 可以通过常见的手段监控到各种服务,通过编写脚本来获取返回值并将获取到的值通过图形来展现出来,包括(系统.服务.业务)层面.可是有些时候在一些不固定的场合监控一些不固定的服务就比较麻烦.例 ...
- HDU 1102
最小生成树 对于必须要加入的边, 让其边权为0 即可 Prim : #include<iostream> #include<cstring> #include<cstdi ...
- Linux命令之nohup和重定向
用途:不挂断地运行命令.语法:nohup Command [ Arg ... ] [ & ]描述:nohup 命令运行由 Command 参数和任何相关的 Arg 参数指定的命令,忽略所有挂断 ...
- js对数组中的数字排序
1 前言 如果数组里面都是数字,如果用原生的sort,默认是按字符串排序的,不符合我们的要求 2 代码 方法1:添加Array的原生方法 Array.prototype.sort2 =function ...
- Python-多表关联 外键 级联
分表为什么分表 多表关联多表关系 ****** 表之间的关系 为什么要分表 多对一 一个外键 多对多 一个中间表 两个外键 一对一 一个外键加一个唯一约束外键约束 ****** foreign key ...
- chkconfig: command not found
问题描述 Ubuntu 16.04 下安装 Nginx 服务器,在添加 nginx 服务时出现如下信息 # chkconfig --add nginx chkconfig: command not f ...