机器学习--k-means聚类原理
“物以类聚,人以群分”, 所谓聚类就是将相似的元素分到一"类"(有时也被称为"簇"或"集合"), 簇内元素相似程度高, 簇间元素相似程度低. 常用的聚类方法有划分聚类, 层次聚类, 密度聚类, 网格聚类, 模型聚类等. 我们这里重点介绍划分聚类.
1. 划分聚类
划分聚类, 就是给定一个样本量为N的数据集, 将其划分为K个簇(K<N), 每一个簇中至少包含一个样本点.
大部分的划分方法是基于距离的, 即簇内距离最小化, 簇间距离最大化. 常用的距离计算方法有: 曼哈顿距离和欧几里得距离. 坐标点(x1, y1)到坐标点(x2, y2)的曼哈顿距离和欧几里得距离分别表示为:
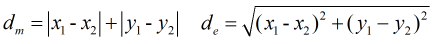
为了达到全局最优解, 传统的划分法可能需要穷举所有可能的划分点, 这计算量是相当大的. 而在实际应用中, 通常会通过计算到均值或中心点的距离进行划分来逼近局部最优, 把计算到均值和到中心点距离的算法分别称为K-MEANS算法和K-MEDOIDS算法, 在这里只介绍K-MEANS算法.
2. K-MEANS算法
K-MEANS算法有时也叫快速聚类算法, 其大致流程为:
第一步: 随机选取K个点, 作为初始的K个聚类中心, 有时也叫质心.
第二步: 计算每个样本点到K个聚类中心的距离, 并将其分给距离最短的簇, 如果k个簇中均至少有一个样本点, 那么我们就说将所有样本点分成了K个簇.
第三步: 计算K个簇中所有样本点的均值, 将这K个均值作为K个新的聚类中心.
第四步: 重复第二步和第三步, 直到聚类中心不再改变时停止算法, 输出聚类结果.
显然, 初始聚类中心的选择对迭代时间和聚类结果产生的影响较大, 选不好的话很有可能严重偏离最优聚类. 在实际应用中, 通常选取多个不同的K值以及初始聚类中心, 选取其中表现最好的作为最终的初始聚类中心. 怎么算表现最好呢? 能满足业务需求的, 且簇内距离最小的.
簇内距离可以簇内离差平方和表示:
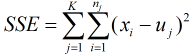
其中, K表示K个簇, nj表示第j个簇中的样本个数, xi表示样本, uj表示第j个簇的质心, K-means算法中质心可以表示为:
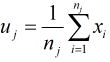
3. 优缺点及注意事项
优点:
1. 原理简单, 计算速度快
2. 聚类效果较理想.
缺点:
1. K值以及初始质心对结果影响较大, 且不好把握.
2. 在大数据集上收敛较慢.
3. 由于目标函数(簇内离差平方和最小)是非凸函数, 因此通过迭代只能保证局部最优.
4. 对于离群点较敏感, 这是由于其是基于均值计算的, 而均值易受离群点的影响.
5. 由于其是基于距离进行计算的, 因此通常只能发现"类圆形"的聚类.
注意事项:
1. 由于其是基于距离进行计算的, 因此通常需要对连续型数据进行标准化处理来缩小数据间的差异.(对于离散型, 则需要进行one-hot编码)
2. 如果采用欧几里得距离进行计算的话, 单位的平方和的平方根是没有意义的, 因此通常需要进行无量纲化处理
机器学习--k-means聚类原理的更多相关文章
- 吴裕雄 python 机器学习——K均值聚类KMeans模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
- 机器学习算法与Python实践之(五)k均值聚类(k-means)
机器学习算法与Python实践这个系列主要是参考<机器学习实战>这本书.因为自己想学习Python,然后也想对一些机器学习算法加深下了解,所以就想通过Python来实现几个比较常用的机器学 ...
- 机器学习算法与Python实践之(六)二分k均值聚类
http://blog.csdn.net/zouxy09/article/details/17590137 机器学习算法与Python实践之(六)二分k均值聚类 zouxy09@qq.com http ...
- 100天搞定机器学习|day54 聚类系列:层次聚类原理及案例
几张GIF理解K-均值聚类原理 k均值聚类数学推导与python实现 前文说了k均值聚类,他是基于中心的聚类方法,通过迭代将样本分到k个类中,使每个样本与其所属类的中心或均值最近. 今天我们看一下无监 ...
- 机器学习实战5:k-means聚类:二分k均值聚类+地理位置聚簇实例
k-均值聚类是非监督学习的一种,输入必须指定聚簇中心个数k.k均值是基于相似度的聚类,为没有标签的一簇实例分为一类. 一 经典的k-均值聚类 思路: 1 随机创建k个质心(k必须指定,二维的很容易确定 ...
- 机器学习之路:python k均值聚类 KMeans 手写数字
python3 学习使用api 使用了网上的数据集,我把他下载到了本地 可以到我的git中下载数据集: https://github.com/linyi0604/MachineLearning 代码: ...
- 机器学习之K均值聚类
聚类的核心概念是相似度或距离,有很多相似度或距离的方法,比如欧式距离.马氏距离.相关系数.余弦定理.层次聚类和K均值聚类等 1. K均值聚类思想 K均值聚类的基本思想是,通过迭代的方法寻找K个 ...
- 100天搞定机器学习|day43 几张GIF理解K-均值聚类原理
前文推荐 如何正确使用「K均值聚类」? KMeans算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.该算法认为簇是由距离靠近的对象组成的,因此把 ...
- 100天搞定机器学习|day44 k均值聚类数学推导与python实现
[如何正确使用「K均值聚类」? 1.k均值聚类模型 给定样本,每个样本都是m为特征向量,模型目标是将n个样本分到k个不停的类或簇中,每个样本到其所属类的中心的距离最小,每个样本只能属于一个类.用C表示 ...
随机推荐
- Python中多个列表与字典的合并方法
Python中多个列表与字典的合并方法 1多列表的合并 1)a+=b a=['] b = ['] a += b print(a) >>>['] 2) a.extend(b) a=[' ...
- TensorFlow代码初识
直接看代码 import tensorflow as tf # tf.Variable生成的变量,每次迭代都会变化, # 这个变量也就是我们要去计算的结果,所以说你要计算什么,你是不是就把什么定义为V ...
- Logparser介绍
原文链接:https://www.cnblogs.com/Jerseyblog/p/3986591.html Logparser是一款非常强大的日志分析软件,可以帮助你详细的分析网站日志.是所有数据分 ...
- 转载:消息队列MQ
本文大概围绕如下几点进行阐述: 为什么使用消息队列? 使用消息队列有什么缺点? 消息队列如何选型? 如何保证消息队列是高可用的? 如何保证消息不被重复消费? 如何保证消费的可靠性传输? 如何保证消息的 ...
- 虚拟机Ubuntu18.04——gcc版本的升降
致读者:这是本人第一篇博客,小试牛刀,希望能在以后的道路中分享出更多实用的技巧和知识,大家一起进步. 操作环境: VMware Workstation 14Pro .64位Ubuntu18.04系统 ...
- Oracle树形查询
sql树形递归查询是数据库查询的一种特殊情形,也是组织结构.行政区划查询的一种最常用的的情形之一.下面对该种查询进行一些总结: start with子句: 递归的条件,需要注意的是如果with后面的值 ...
- Hadoop2.0环境安装
0. Hadoop源码包下载 http://mirror.bit.edu.cn/apache/hadoop/common 1. 集群环境 操作系统 CentOS7 集群规划 Master 192.16 ...
- 使用 nodeJs 开发微信公众号(设置自动回复消息)
微信向第三方服务器发送请求时会降 signature .timestamp. nonce . openid(用户标识),发送内容会以 xml 的形式附加在请求中 回复消息前提我们得拿到用户id , 用 ...
- nodeJs 控制台打印中文显示为Unicode解决方案
在使用 NodeJs 采集其他网站网页时遇到的,在获取源代码后发现里面原来的中文被转成了 Unicode(UTF8) 编码的中文(如:&# [xxx]),这当然不是真正想要的中文实体 解决方案 ...
- Python OS模块,和Open函数
https://www.cnblogs.com/ginvip/p/6439679.html