[1] 从零开始 TensorFlow 学习
计算图的基本概念
TensorFlow 的名字中己经说明了它最重要的两个概念一一Tensor 和 Flow
Tensor: 张量(高阶数组,矩阵为二阶张量,向量为一阶张量,标量为零阶张量)
Flow: 流动的张量数据 (形状shape可以像水流一样变动)
所以TensorFlow是一个通过先构建图,然后通过张量Flow的形式来表述计算的编程系统
TensorFlow中的每一个计算都是图上的一个节点 ,称为Operation,简称op
节点之间的边 描述了计算之间的依赖关系
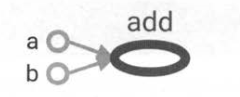 左图即为TensorFlow的基本计算图
左图即为TensorFlow的基本计算图
如果 一个运算的输入依赖于另一个运算的输出,那么这两个运算有依赖关系。
a 和 b 这两个常量不依赖任何其他计算, 而 add 计算则依赖读取两个常量的取值
计算图的使用
TensorFlow程序 可以分为A,B两个阶段
通过默认的tf.get_default_graph将定义的计算转化成计算图
A阶段: 定义计算图中的所有计算 ()
- import tensorflow as tf
- a = tf.constant([1.0,2.0],name='aa')
- b = tf.constant([2.0,3.333],name="bb")
- result = a + b
B阶段: 执行计算图 ()
- with tf.Session() as sess:
- tf.global_variables_initializer().run()
- print(sess.run(result))
通过tf.Graph函数生成新的计算图 (相互独立不共享)
A阶段: 定义计算图中的所有计算 ()
- import tensorflow as tf
- g1 = tf.Graph()
- with g1.as_default():
- # v = tf.get_variable("v",initializer=tf.zeros_initializer(shape=[1])) # 该写法已经废弃
- # 在计算图 g1 中定义变量“v”,并设置初始值为0的2*2的Tensor
- v = tf.get_variable("v1",shape=[2,2],initializer=tf.zeros_initializer)
- g2 = tf.Graph()
- with g2.as_default():
- # 在计算图 g2 中定义变量“v”,并设置初始值为1的2*2的Tensor
- v = tf.get_variable("v2",shape=[2,2],initializer=tf.ones_initializer)
B阶段: 执行计算图 ()
- # 在计算图g1中读取变量"v"的取值.
- with tf.Session(graph=g1) as sess:
- tf.global_variables_initializer().run()
- with tf.variable_scope("",reuse=True):
- print(sess.run(tf.get_variable("v1")))
- # 在计算图g2中读取变量"v"的取值.
- with tf.Session(graph=g2) as sess:
- tf.global_variables_initializer().run()
- with tf.variable_scope("",reuse=True):
- print(sess.run(tf.get_variable("v2")))
TensorFlow中的计算图提供了管理张量与计算的机制. 计算图可以通过 tf.Graph.device函数来指定运行计算的设备,这为TensorFlow 使用特定设备(GPU,TPU)提供了入口.
以下是选择设备进行计算的的具体演示:
- import tensorflow as tf
- g = tf.Graph()
- a = tf.constant([1,2,3],name="aaa")
- b = tf.constant([3,2,1],name="bbb")
- # 指定计算运行的设备
- with g.device ('/gpu:0'):
- result = a + b
在一个计算图中,可以通过集合 (collection)来管理不同类别的资源(变量) 。
比如通过 tf.add_to_collection 函数可以将变量加入一个或多个集合中
然后通过 tf.get_collection 获取一个集合里面的所有资源。这里的资源可以是张量、变量或者运行 TensorFlow 程序所需要的队列资源
tf.add_n:把集合 (collection) 里的东西都依次加起来
- import tensorflow as tf
- v1 = tf.get_variable(name='v1', shape=[1], initializer=tf.constant_initializer(1))
- tf.add_to_collection('loss', v1)
- v2 = tf.get_variable(name='v2', shape=[1], initializer=tf.constant_initializer(2))
- tf.add_to_collection('loss', v2)
- collection_sum = tf.add_n(tf.get_collection('loss')) # 累加collection
- with tf.Session() as sess:
- sess.run(tf.global_variables_initializer())
- print (tf.get_collection('loss'))
- print (sess.run(collection_sum))
- """
- 输出:
- [<tf.Variable 'v1:0' shape=(1,) dtype=float32_ref>, <tf.Variable 'v2:0' shape=(1,) dtype=float32_ref>]
- [3.]
- """
TensorFlow的数据模型: Tensor张量
张量在 TensorFlow 中的实现并不是直接采用数组的形式,它是对 TensorFlow 中运算结果的引用,在张量中并没有真正保存数字,它保存的是如何得到这些数字的计算过程。
以张量加法为实际实验
- import tensorflow as tf
- # tf.constant 是一个计算,这个计算结果为一个张量,保存在变量a中
- a = tf.constant([[1.2,2.4],
- [2.4,3.6]],name="a")
- b = tf.constant([[3.3,4.4],
- [4.4,5.5]],name="b")
- result = tf.add(a,b,name="add")
- print (result)
- """
- 输出:
- Tensor("add:0", shape=(2, 2), dtype=float32)
- """
从以上代码可以看出 TensorFlow 中的张量和 NumPy 中的数组不同, TensorFlow 计算的结果不是一个具体的数字, 而且一个张量的结构.
一个张量中主要保存了三个属性:名字(name)、维度(shape)和 数据类型(dtype)
而张量的第一个属性名字不仅是一个张量的唯一标识符, 通过 “node:src_output”的 形式来给出。其中 node 为节点的名称,比如上面代码打出来的“add, src_output 表示当前张量来自节点的第几个输出。"add:0"
就说明了 result 这个张量是计算节点“add” 输出的第一个结果 (编号从0开始)。
TensorFlow 运行模型一会话Session()
会话Session拥有并管理 TensorFlow 程序运行时的所有资源(变量)。所有计算完成之后需要关闭会话来帮助系统回收资源,否则就可能出现 资源泄漏的问题。
推荐做法:
- # 创建一个会话,并通过 Python 中的上下文管理器来管理这个会话
- with tf.Session() as sess:
- # 使用创建好的会话来计算关心的结果
- sess.run( ... )
- # 不需要再调用“Session.close()”函数来关闭会话
- # 当上下文退出时会话关闭和资源释放也自动完成了
# 上下文管理器的机制: 只要将所有的计算放在 “with”的内部就可以
前面说过计算图没有特殊的指定,TensorFlow会自动生成一个默认的计算图用于运算使用,TensorFlow 中的会话也有类似的机制,但 TensorFlow 不会自动生成默认的会话,而是需要手动指定,当默认的会话被指定之后可以通过 tf.Tensor.eval 函数来计算一个张量的取值
- import tensorflow as tf
- # tf.constant 是一个计算,这个计算结果为一个张量,保存在变量a中
- a = tf.constant([[1.2,2.4],
- [2.4,3.6]],name="a")
- b = tf.constant([[3.3,4.4],
- [4.4,5.5]],name="b")
- result = tf.add(a,b,name="add")
- sess = tf.Session()
- with sess.as_default():
- print(result.eval())
- # 以下代码可以完成相同的功能
- sess = tf.Session()
- print(sess.run(result))
- print(result.eval(session=sess))
- sess.close()
通过ConfigProto Protocol Buffer来配置需要生成的会话,下面是通过ConfigProto配置会话的方法:
- config = tf.ConfigProto(allow_soft_placement=True, log_device_placement=True)
- sess1 = tf.Session(config=config)
ConfigProto 还可以配置类似并行的线程数、 GPU分配策略、运算超时时间等参数
参数中最常用的有两个:
第一个是 allow_soft_placement,这是一个bool型的参数 ,使得代码的可移植性强(有无GPU都可运算)
这个的参数的默认值为False, 当它为True时, 在以下任意一个条件成立时, GPU上的运算可以放到CPU上进行:
1. 运算无法在GPU上执行
2. 没有GPU资源 (比如运算被指定在第二个GPU上运行,但是机器只有一个GPU)
3. 运算输入包含对CPU计算结果的引用
第二个使用得比较多的配置参数是 log_device _placement 也是一个bool型的参数,当它为 True 时日志中将会记录每个节点被安排在哪个设备上以方便调试。而在生产环境中 将这个参数设置为False 可以减少日志量.
[1] 从零开始 TensorFlow 学习的更多相关文章
- Tensorflow学习笔记2:About Session, Graph, Operation and Tensor
简介 上一篇笔记:Tensorflow学习笔记1:Get Started 我们谈到Tensorflow是基于图(Graph)的计算系统.而图的节点则是由操作(Operation)来构成的,而图的各个节 ...
- 用tensorflow学习贝叶斯个性化排序(BPR)
在贝叶斯个性化排序(BPR)算法小结中,我们对贝叶斯个性化排序(Bayesian Personalized Ranking, 以下简称BPR)的原理做了讨论,本文我们将从实践的角度来使用BPR做一个简 ...
- 如何从零开始系统化学习视觉SLAM?
由于显示格式问题,建议阅读原文:如何从零开始系统化学习视觉SLAM? 什么是SLAM? SLAM是 Simultaneous Localization And Mapping的 英文首字母组合,一般翻 ...
- 从零开始一起学习SLAM | 掌握g2o边的代码套路
点"计算机视觉life"关注,置顶更快接收消息! 小白:师兄,g2o框架<从零开始一起学习SLAM | 理解图优化,一步步带你看懂g2o代码>,以及顶点<从零开始 ...
- 从零开始一起学习SLAM | 掌握g2o顶点编程套路
点"计算机视觉life"关注,置顶更快接收消息! ## 小白:师兄,上一次将的g2o框架<从零开始一起学习SLAM | 理解图优化,一步步带你看懂g2o代码>真的很清晰 ...
- 从零开始一起学习SLAM | 点云到网格的进化
点击公众号"计算机视觉life"关注,置顶星标更快接收消息! 本文编程练习框架及数据获取方法见文末获取方式 菜单栏点击"知识星球"查看「从零开始学习SLAM」一 ...
- Tensorflow学习笔记2019.01.22
tensorflow学习笔记2 edit by Strangewx 2019.01.04 4.1 机器学习基础 4.1.1 一般结构: 初始化模型参数:通常随机赋值,简单模型赋值0 训练数据:一般打乱 ...
- Tensorflow学习笔记2019.01.03
tensorflow学习笔记: 3.2 Tensorflow中定义数据流图 张量知识矩阵的一个超集. 超集:如果一个集合S2中的每一个元素都在集合S1中,且集合S1中可能包含S2中没有的元素,则集合S ...
- TensorFlow学习笔记之--[compute_gradients和apply_gradients原理浅析]
I optimizer.minimize(loss, var_list) 我们都知道,TensorFlow为我们提供了丰富的优化函数,例如GradientDescentOptimizer.这个方法会自 ...
随机推荐
- Redis的数据结构
Redis的数据结构 redis是一种高级的key-value的存储系统,其中value支持五种数据类型. 字符串(String) 哈希(hash) 字符串列表(list) 字符串集合(set) 有序 ...
- 如何创建.gitignore文件,忽略git不必要提交的文件
touch .gitignore 在项目目录里输入以上名利后,会自动生成一个文件 .gitignore,可在文件里写入忽略的文件名,例如 node_modules coverage .idea npm ...
- nodeJs express mongodb 建站(linux 版)
一.环境安装 1.安装node wget http://nodejs.org/dist/v0.12.2/node-v0.12.2-linux-x64.tar.gz //下载tar xvf node-v ...
- 浅谈css中的盒模型(框模型)
css中的盒模型是css的基础,盒模型的理解可以帮助我们进行对样式进行修改.废话不多说,进入正题: 在w3c中,CSS 框模型 (Box Model) 规定了元素框处理元素内容.内边框.边框 和 外边 ...
- JavaScript String常用方法和属性
在JavaScript中,字符串是不可变的,如果使用索引对字符串进行修改浏览器不会报错,但也没有任何效果.JavaScript提供的这些方法不会修改原有字符串的内容,而是返回一个新的期望的字符串. 一 ...
- vuejs通过filterBy,orderBy实现搜索筛选,降序排序数据实例
直接贴代码了: 先上输入前的样子: <style> #example{margin:100px auto;width:600px;} .show{margin:10px;} #search ...
- win7下利用ftp实现华为路由器的配置文件上传和下载
win7下利用ftp实现华为路由器的配置文件上传和下载 1. Win7下ftp的安装和配置 (1)开始—>控制面板—>程序—>程序和功能—>打开或关闭Windows功能 (2 ...
- getCacheDir()、getFilesDir()、getExternalFilesDir()、getExternalCacheDir()
一.getCacheDir.getCacheDir getCacheDir()方法用于获取/data/data//cache目录 getFilesDir()方法用于获取/data/data//file ...
- leetcode-217存在重复元素
leetcode-217存在重复元素 题意 给定一个整数数组,判断是否存在重复元素. 如果任何值在数组中出现至少两次,函数返回 true.如果数组中每个元素都不相同,则返回 false. 示例 1: ...
- Java:Hibernate报错记录:Error executing DDL via JDBC Statement
想着写一篇hibernate的博文,于是准备从头开始,从官网下了最新的稳定版本来做讲述. 结果利用hibernate自动建表的时候发生下面这个问题. 我很纳闷,之前用低版本一点的没有发生这个问题啊. ...