Scrapy基础01
一、Scarpy简介
Scrapy基于事件驱动网络框架 Twisted 编写。(Event-driven networking)
因此,Scrapy基于并发性考虑由非阻塞(即异步)的实现。
参考:武Sir笔记
参考:Scrapy架构概览
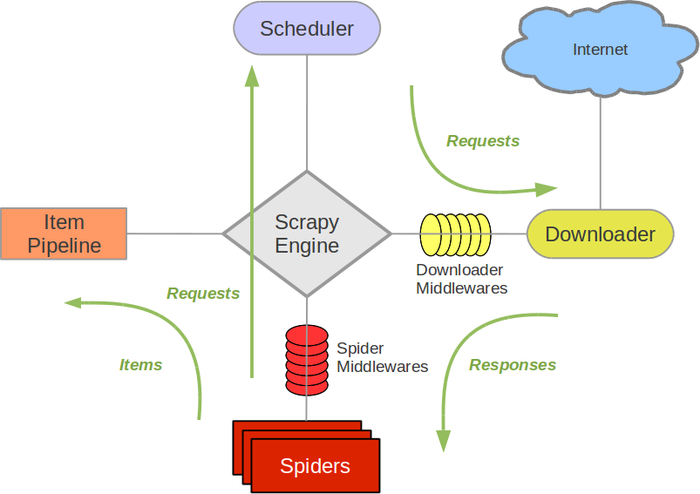
二、爬取chouti.com新闻示例
# chouti.py # -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request
from scrapy.selector import HtmlXPathSelector
from ..items import Day24SpiderItem # For windows:
import sys,io
sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') class ChoutiSpider(scrapy.Spider):
name = 'chouti'
allowed_domains = ['chouti.com']
start_urls = ['http://chouti.com/'] def parse(self, response):
# print(response.body)
# print(response.text)
hxs = HtmlXPathSelector(response)
item_list = hxs.xpath('//div[@id="content-list"]/div[@class="item"]')
# 找到首页所有消息的连接、标题、作业信息然后yield给pipeline进行持久化
for item in item_list:
link = item.xpath('./div[@class="news-content"]/div[@class="part1"]/a/@href').extract_first()
title = item.xpath('./div[@class="news-content"]/div[@class="part2"]/@share-title').extract_first()
author = item.xpath('./div[@class="news-content"]/div[@class="part2"]/a[@class="user-a"]/b/text()').extract_first()
yield Day24SpiderItem(link=link,title=title,author=author) # 找到第二页、第三页、、、第十页的消息,全部爬取下来做持久化
# hxs.xpath('//div[@id="dig_lcpage"]//a/@href').extract()
'''或者用正则精确匹配'''
page_url_list = hxs.xpath('//div[@id="dig_lcpage"]//a[re:test(@href,"/all/hot/recent/\d+")]/@href').extract()
for url in page_url_list:
url = "http://dig.chouti.com" + url
print(url)
yield Request(url, callback=self.parse, dont_filter=False)
# pipelines.py # -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html class Day24SpiderPipeline(object): def __init__(self,file_path):
self.file_path = file_path # 文件路径
self.file_obj = None # 文件对象:用于读写操作 @classmethod
def from_crawler(cls, crawler):
"""
初始化时候,用于创建pipeline对象
:param crawler:
:return:
"""
val = crawler.settings.get('STORAGE_CONFIG')
return cls(val) def process_item(self, item, spider):
print(">>>> ",item)
if 'chouti' == spider.name:
self.file_obj.write(item.get('link') + "\n" + item.get('title') + "\n" + item.get('author') + "\n\n")
return item def open_spider(self, spider):
"""
爬虫开始执行时,调用
:param spider:
:return:
"""
if 'chouti' == spider.name:
# 如果不加:encoding='utf-8' 会导致文件里中文乱码
self.file_obj = open(self.file_path,mode='a+',encoding='utf-8') def close_spider(self, spider):
"""
爬虫关闭时,被调用
:param spider:
:return:
"""
if 'chouti' == spider.name:
self.file_obj.close()
# items.py # -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html import scrapy class Day24SpiderItem(scrapy.Item):
link = scrapy.Field()
title = scrapy.Field()
author = scrapy.Field()
# settings.py # -*- coding: utf-8 -*- # Scrapy settings for day24spider project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
# http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html BOT_NAME = 'day24spider' SPIDER_MODULES = ['day24spider.spiders']
NEWSPIDER_MODULE = 'day24spider.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'day24spider (+http://www.yourdomain.com)' # Obey robots.txt rules
ROBOTSTXT_OBEY = True # Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0)
# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default)
#COOKIES_ENABLED = False # Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False # Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#} # Enable or disable spider middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'day24spider.middlewares.Day24SpiderSpiderMiddleware': 543,
#} # Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'day24spider.middlewares.MyCustomDownloaderMiddleware': 543,
#} # Enable or disable extensions
# See http://scrapy.readthedocs.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#} # Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'day24spider.pipelines.Day24SpiderPipeline': 300,
} # Enable and configure the AutoThrottle extension (disabled by default)
# See http://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default)
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage' STORAGE_CONFIG = "chouti.json"
DEPTH_LIMIT = 1
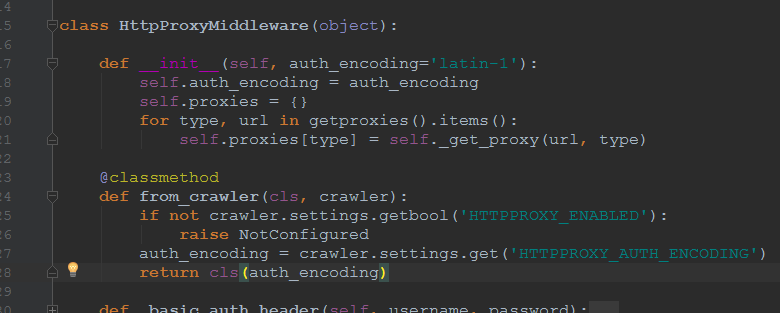
三、classmethod方法应用
from_crawler() --> __init__()
Scrapy基础01的更多相关文章
- javascript基础01
javascript基础01 Javascript能做些什么? 给予页面灵魂,让页面可以动起来,包括动态的数据,动态的标签,动态的样式等等. 如实现到轮播图.拖拽.放大镜等,而动态的数据就好比不像没有 ...
- Androd核心基础01
Androd核心基础01包含的主要内容如下 Android版本简介 Android体系结构 JVM和DVM的区别 常见adb命令操作 Android工程目录结构 点击事件的四种形式 电话拨号器Demo ...
- java基础学习05(面向对象基础01)
面向对象基础01 1.理解面向对象的概念 2.掌握类与对象的概念3.掌握类的封装性4.掌握类构造方法的使用 实现的目标 1.类与对象的关系.定义.使用 2.对象的创建格式,可以创建多个对象3.对象的内 ...
- Linux基础01 学会使用命令帮助
Linux基础01 学会使用命令帮助 概述 在linux终端,面对命令不知道怎么用,或不记得命令的拼写及参数时,我们需要求助于系统的帮助文档:linux系统内置的帮助文档很详细,通常能解决我们的问题, ...
- 可满足性模块理论(SMT)基础 - 01 - 自动机和斯皮尔伯格算术
可满足性模块理论(SMT)基础 - 01 - 自动机和斯皮尔伯格算术 前言 如果,我们只给出一个数学问题的(比如一道数独题)约束条件,是否有程序可以自动求出一个解? 可满足性模理论(SMT - Sat ...
- LibreOJ 2003. 「SDOI2017」新生舞会 基础01分数规划 最大权匹配
#2003. 「SDOI2017」新生舞会 内存限制:256 MiB时间限制:1500 ms标准输入输出 题目类型:传统评测方式:文本比较 上传者: 匿名 提交提交记录统计讨论测试数据 题目描述 ...
- java基础 01
java基础01 1. /** * JDK: (Java Development ToolKit) java开发工具包.JDK是整个java的核心! * 包括了java运行环境 JRE(Java Ru ...
- 0.Python 爬虫之Scrapy入门实践指南(Scrapy基础知识)
目录 0.0.Scrapy基础 0.1.Scrapy 框架图 0.2.Scrapy主要包括了以下组件: 0.3.Scrapy简单示例如下: 0.4.Scrapy运行流程如下: 0.5.还有什么? 0. ...
- 081 01 Android 零基础入门 02 Java面向对象 01 Java面向对象基础 01 初识面向对象 06 new关键字
081 01 Android 零基础入门 02 Java面向对象 01 Java面向对象基础 01 初识面向对象 06 new关键字 本文知识点:new关键字 说明:因为时间紧张,本人写博客过程中只是 ...
随机推荐
- Codeforces Round #502 (in memory of Leopoldo Taravilse, Div. 1 + Div. 2)
第一次参加cf的比赛 有点小幸运也有点小遗憾 给自己定个小目标 1500[对啊我就是很菜qvq A. The Rank 难度:普及- n位学生 每个学生有四个分数 然鹅我们只需要知道他的分数和 按分数 ...
- zabbix python 微信告警脚本
测试zabbix的微信告警耗费了大量时间,使用了开源工具(OneOaaS weixin-alert).shell脚本工具(手动执行正常,服务器调用失败),均没有实现相关功能以下是自己优化过的Pytho ...
- 洛谷P4581 [BJOI2014]想法(玄学算法,拓扑排序)
洛谷题目传送门 萝卜大毒瘤 题意可以简化成这样:给一个DAG,求每个点能够从多少个入度为\(0\)的点到达(记为\(k\)). 一个随机做法:给每个入度为\(0\)的点随机一个权值,在DAG上求出每个 ...
- 【CTSC2018】暴力写挂(边分治,虚树)
[CTSC2018]暴力写挂(边分治,虚树) 题面 UOJ BZOJ 洛谷 题解 发现第二棵树上的\(LCA\)的深度这玩意没法搞,那么枚举在第二棵树上的\(LCA\). 然后剩下的部分就是\(dep ...
- [luogu3810][bzoj3262]陌下花开【cdq分治】
题目描述 有n朵花,每朵花有三个属性:花形(s).颜色(c).气味(m),用三个整数表示.现在要对每朵花评级,一朵花的级别是它拥有的美丽能超过的花的数量.定义一朵花A比另一朵花B要美丽,当且仅Sa&g ...
- IT项目管理——《人月神话》读后感
这也许是和候红老师的最后的几节课了吧,侯老师是一个很有思想深度,很关心同学的好老师. 一开学就布置了阅读<人月神话>的作业,说实话,我没有看,以我的速度可能2.3个小时就看完了,但是我觉得 ...
- 使用Coverage进行代码覆盖率的测试
软件测试实验报告 一.实验目的: 使用软件测试代码覆盖率. 二.实验工具: Windows10.Python3.6.3.Coverage. 三.实验内容: 1.编写准备测试的代码main.py和测试代 ...
- [Vani有约会]雨天的尾巴(树上差分+线段树合并)
首先村落里的一共有n座房屋,并形成一个树状结构.然后救济粮分m次发放,每次选择两个房屋(x,y),然后对于x到y的路径上(含x和y)每座房子里发放一袋z类型的救济粮. 然后深绘里想知道,当所有的救济粮 ...
- Python3 与 C# 基础语法对比(Function专栏)
Code:https://github.com/lotapp/BaseCode 多图旧版:https://www.cnblogs.com/dunitian/p/9186561.html 在线编程: ...
- Jupyter-Notebook 删除指定 kernel
原来是Python3+C# 查看列表jupyter kernelspec list 删除指定kernel:jupyter kernelspec remove icsharpkernel 删除成功:(刷 ...