Kafka安装部署
1.从官网下载安装包,并通过Xftp5上传到机器集群上
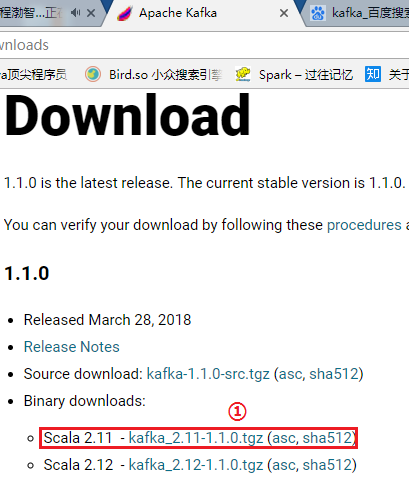
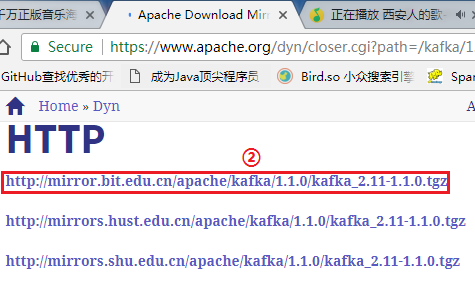
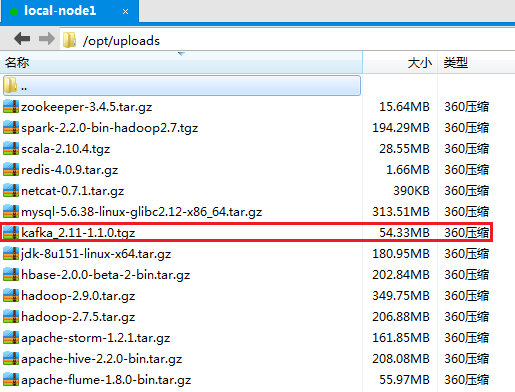
下载kafka_2.11-1.1.0.tgz版本,并通过Xftp5上传到hadoop机器集群的第一个节点node1上的/opt/uploads/目录:
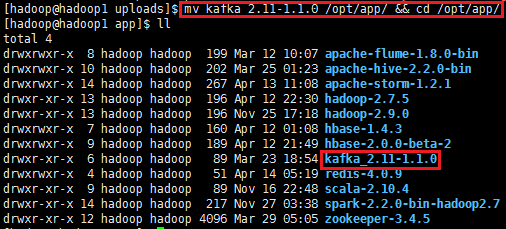
2、解压kafka_2.11-1.1.0.tgz,并把解压的安装包移动到/opt/app/目录上
tar zxvf kafka_2.11-1.1.0.tgz

mv kafka_2.11-1.1.0 /opt/app/ && cd /opt/app/
3、修改环境变量(每台机器都要执行),编辑/etc/profile,并生效环境变量,输入如下命令:
sudo vi /etc/profile
添加如下内容:
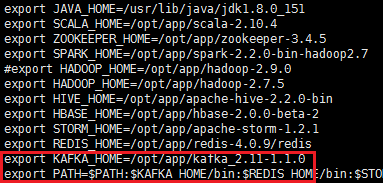
export KAFKA_HOME=/opt/app/kafka_2.11-1.1.0
export PATH=:$PATH:$KAFKA_HOME/bin
使环境变量生效:source /etc/profile
4、zookeeper集群安装搭建
zookeeper可以使用kafka_2.11-1.1.0内置的,也可以从zookeeper官网下载一个安装部署集群,差别不大。
安装部署及配置详情请看https://www.cnblogs.com/swordfall/p/8667409.html 第六节点。
这里独立安装zookeeper,不使用kafka内置的。
5、修改配置文件server.properties
进入kafka配置文件的目录,cd /opt/app/kafka_2.11-1.1.0/config/
修改server.properties文件 vi server.properties,将以下内容写入到server.properties文件中
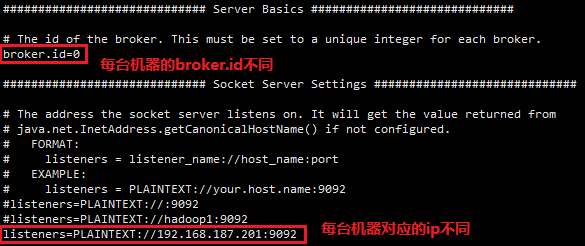
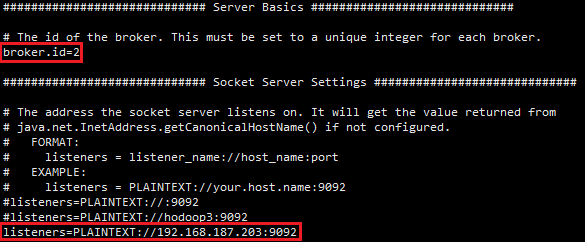
# broker id就是指各台服务器对应的id,所以各台服务器值不同
broker.id=0
# kafka端口号,无需改变
listeners=PLAINTEXT://192.168.187.201:9092
# 日志目录
log.dirs=/opt/app/kafka_2.11-1.1.0/logs
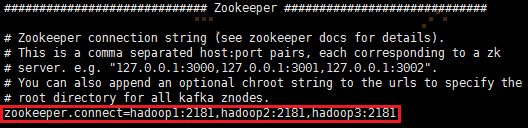
# Zookeeper集群的ip和端口号
zookeeper.connect=hadoop1:2181,hadoop2:2181,hadoop3:2181

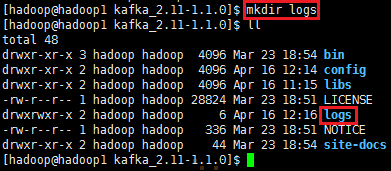
在/opt/app/kafka_2.11-1.1.0/logs目录下创建logs目录,mkdir logs目录
6. 把kafka的安装包发送到其他节点机器hadoop2和hadoop3
scp -r /opt/app/kafka_2.11-1.1.0/ hadoop@hadoop2:/opt/app/
scp -r /opt/app/kafka_2.11-1.1.0/ hadoop@hadoop3:/opt/app/
然后hadoop2、hadoop3分别重复第3步骤,修改环境变量
7. 分别在hadoop2、hadoop3机器节点上修改broker.id和listeners
hadoop2机器节点上修改kafka的server.properties配置文件

hadoop3机器节点上修改kafka的server.properties配置文件
8. 启动zookeeper和kafka
在每台机器上先分别通过命令zkServer.sh start启动zookeeper,再分别启动kafka为后台进程:
kafka-server-start.sh /opt/app/kafka_2.11-1.1.0/config/server.properties &

或者通过kafka-server-start.sh /opt/app/kafka_2.11-1.1.0/config/server.properties > /dev/null 2>&1 & 启动kafka
注:"> /dev/null" 表示把日志写入/dev/null,"2>&1"表示错误日志和标准输出日志合并写入一个文件,"&"表示后台运行
通过jps命令可以查看到每台机器上是否都启动了zookeeper和kafka
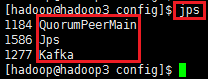
至此kafka集群部署成功。
9. 注意点
kafka安装包根目录下config/server.properties文件如果listeners配置的是hostname主机名,而不是ip,那么需要格外配置一项:
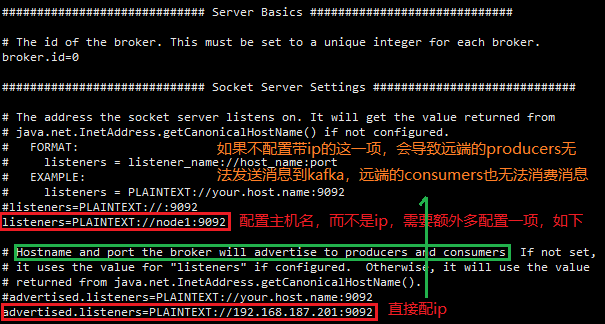
listeners的两种配置方法,可以二选一,一般选第一种。
Kafka安装部署的更多相关文章
- zookeeper与kafka安装部署及java环境搭建(发布订阅模式)
1. ZooKeeper安装部署 本文在一台机器上模拟3个zk server的集群安装. 1.1. 创建目录.解压 cd /usr/ #创建项目目录 mkdir zookeeper cd zookee ...
- ELK+KAFKA安装部署指南
一.ELK 背景 通常,日志被分散的储存不同的设备上.如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志.这样是不是感觉很繁琐和效率低下.当务之急我们使用集中化的日志管理,例如: ...
- 【Apache KafKa系列之一】KafKa安装部署
kafka是一种高吞吐量的分布式发布订阅消息系统,她有如下特性: 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能. 高吞吐量:即使是非常普通的 ...
- kafka 安装部署
环境:ubuntu 12.04 64位桌面版 解压kafka -0.10.0.0.tgz -C /root/software/ 进入目录 cd kafka_2.-0.10.0.0/ 创建data 目录 ...
- Kafka集群安装部署、Kafka生产者、Kafka消费者
Storm上游数据源之Kakfa 目标: 理解Storm消费的数据来源.理解JMS规范.理解Kafka核心组件.掌握Kakfa生产者API.掌握Kafka消费者API.对流式计算的生态环境有深入的了解 ...
- ELK文档-安装部署
一.ELK简介 请参考:http://www.cnblogs.com/aresxin/p/8035137.html 二.ElasticSearch安装部署 请参考:http://blog.51cto. ...
- Kafka安装及部署
安装及部署 一.环境配置 操作系统:Cent OS 7 Kafka版本:0.9.0.0 Kafka官网下载:请点击 JDK版本:1.7.0_51 SSH Secure Shell版本:XShell 5 ...
- centos7下kafka集群安装部署
应用摘要: Apache kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写.Kafka是一种高吞吐量的 分布式发布订阅消息系统,是消息中间件的一种,用于构建实时 ...
- kafka 的安装部署
Kafka 的简介: Kafka 是一款分布式消息发布和订阅系统,具有高性能.高吞吐量的特点而被广泛应用与大数据传输场景.它是由 LinkedIn 公司开发,使用 Scala 语言编写,之后成为 Ap ...
随机推荐
- word 2013 题注、图注、插入图片自动修改大小、批量更新题注编号
1 .题注 图片下面的文字说明,如 图 1.1.1 2.图注 图的标题格式,可以右键修改段落为居中,选中图片,点下此格式快捷居中等其他格式 3. 题注插入 效果 如下 4.题注自动居中对齐 先点击图 ...
- LOJ #2537. 「PKUWC 2018」Minimax (线段树合并 优化dp)
题意 小 \(C\) 有一棵 \(n\) 个结点的有根树,根是 \(1\) 号结点,且每个结点最多有两个子结点. 定义结点 \(x\) 的权值为: 1.若 \(x\) 没有子结点,那么它的权值会在输入 ...
- 求集合中选一个数与当前值进行位运算的max
求集合中选一个数与当前值进行位运算的max 这是一个听来的神仙东西. 先确定一下值域把,大概\(2^{16}\),再大点也可以,但是这里就只是写写,所以无所谓啦. 我们先看看如果暴力求怎么做,位运算需 ...
- Codeforces Round #554 ( div.2 ) 总结
应该经常需要锻炼一下英语阅读理解能力和代码能力,所以以后还是需要多打打CF. 今天大概就是水一水找找感觉. A. Neko Finds Grapes $n$个箱子,$m$个钥匙 ($n,m \leq ...
- mysql安转过程中出现的问题! Fatal error: Can't open and lock privilege tables: Table 'mysql.user' doesn't exis
net start mysql启动失败,报错信息如上,因缺少mysql这个库 所以跳过 在my.ini中添加 --skip-grant-tables 再启动mysql 然后进入mysql 倒入一个从其 ...
- BZOJ 2839: 集合计数 解题报告
BZOJ 2839: 集合计数 Description 一个有\(N\)个元素的集合有\(2^N\)个不同子集(包含空集),现在要在这\(2^N\)个集合中取出若干集合(至少一个),使得 它们的交集的 ...
- 【php】php实现数组分块
有时候需要将一个大数组按一定大小分块,那么可以实现这个功能,代码如下: /** * @param array $arr * @param int $size <p> * @param bo ...
- Luogu P1648 看守
Luogu P1648 看守 题意简述 有n个d维的点,输出这些点两两之间曼哈顿距离中的最大值 数据范围 n<=1e6,d<=4 思路 暴力?时间复杂度O(\(n^2d\)) 考虑这样的一 ...
- DHU--1247 Hat’s Words && HiHocder--1014 Trie树 (字典树模版题)
题目链接 DHU--1247 Hat’s Words HiHocder--1014 Trie树 两个一个递归方式一个非递归 HiHocoder #include<bits/stdc++.h> ...
- js 获取 url 参数
/** * 根据页面地址获取所有参数对象 * @return Object{} 返回所有参数 * ------------------------------ * 根据页面地址获取指定参数对象 * @ ...