tensorflow实现基于LSTM的文本分类方法
tensorflow实现基于LSTM的文本分类方法
作者:u010223750
引言
学习一段时间的tensor flow之后,想找个项目试试手,然后想起了之前在看Theano教程中的一个文本分类的实例,这个星期就用tensorflow实现了一下,感觉和之前使用的theano还是有很大的区别,有必要总结mark一下
模型说明
这个分类的模型其实也是很简单,主要就是一个单层的LSTM模型,当然也可以实现多层的模型,多层的模型使用Tensorflow尤其简单,下面是这个模型的图 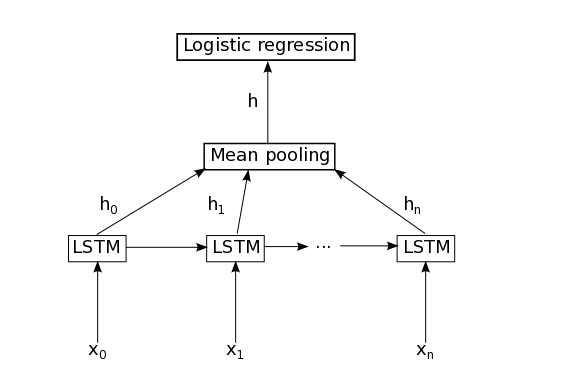
简单解释一下这个图,每个word经过embedding之后,进入LSTM层,这里LSTM是标准的LSTM,然后经过一个时间序列得到的t个隐藏LSTM神经单元的向量,这些向量经过mean pooling层之后,可以得到一个向量h,然后紧接着是一个简单的逻辑斯蒂回归层(或者一个softmax层)得到一个类别分布向量。
公式就不一一介绍了,因为这个实验是使用了Tensorflow重现了Theano的实现,因此具体的公式可以参看LSTM Networks for Sentiment Analysis这个链接。
tensorflow实现
鄙人接触tensor flow的时间不长,也是在慢慢摸索,但是因为有之前使用Theano的经验,对于符号化编程也不算陌生,因此上手Tensorflow倒也容易。但是感觉tensorflow还是和theano有着很多不一样的地方,这里也会提及一下。
代码的模型的主要如下:
import tensorflow as tf
import numpy as np
class RNN_Model(object):
def __init__(self,config,is_training=True):
self.keep_prob=config.keep_prob
self.batch_size=tf.Variable(0,dtype=tf.int32,trainable=False)
num_step=config.num_step
self.input_data=tf.placeholder(tf.int32,[None,num_step])
self.target = tf.placeholder(tf.int64,[None])
self.mask_x = tf.placeholder(tf.float32,[num_step,None])
class_num=config.class_num
hidden_neural_size=config.hidden_neural_size
vocabulary_size=config.vocabulary_size
embed_dim=config.embed_dim
hidden_layer_num=config.hidden_layer_num
self.new_batch_size = tf.placeholder(tf.int32,shape=[],name="new_batch_size")
self._batch_size_update = tf.assign(self.batch_size,self.new_batch_size)
#build LSTM network
lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(hidden_neural_size,forget_bias=0.0,state_is_tuple=True)
if self.keep_prob<1:
lstm_cell = tf.nn.rnn_cell.DropoutWrapper(
lstm_cell,output_keep_prob=self.keep_prob
)
cell = tf.nn.rnn_cell.MultiRNNCell([lstm_cell]*hidden_layer_num,state_is_tuple=True)
self._initial_state = cell.zero_state(self.batch_size,dtype=tf.float32)
#embedding layer
with tf.device("/cpu:0"),tf.name_scope("embedding_layer"):
embedding = tf.get_variable("embedding",[vocabulary_size,embed_dim],dtype=tf.float32)
inputs=tf.nn.embedding_lookup(embedding,self.input_data)
if self.keep_prob<1:
inputs = tf.nn.dropout(inputs,self.keep_prob)
out_put=[]
state=self._initial_state
with tf.variable_scope("LSTM_layer"):
for time_step in range(num_step):
if time_step>0: tf.get_variable_scope().reuse_variables()
(cell_output,state)=cell(inputs[:,time_step,:],state)
out_put.append(cell_output)
out_put=out_put*self.mask_x[:,:,None]
with tf.name_scope("mean_pooling_layer"):
out_put=tf.reduce_sum(out_put,0)/(tf.reduce_sum(self.mask_x,0)[:,None])
with tf.name_scope("Softmax_layer_and_output"):
softmax_w = tf.get_variable("softmax_w",[hidden_neural_size,class_num],dtype=tf.float32)
softmax_b = tf.get_variable("softmax_b",[class_num],dtype=tf.float32)
self.logits = tf.matmul(out_put,softmax_w)+softmax_b
with tf.name_scope("loss"):
self.loss = tf.nn.sparse_softmax_cross_entropy_with_logits(self.logits+1e-10,self.target)
self.cost = tf.reduce_mean(self.loss)
with tf.name_scope("accuracy"):
self.prediction = tf.argmax(self.logits,1)
correct_prediction = tf.equal(self.prediction,self.target)
self.correct_num=tf.reduce_sum(tf.cast(correct_prediction,tf.float32))
self.accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32),name="accuracy")
#add summary
loss_summary = tf.scalar_summary("loss",self.cost)
#add summary
accuracy_summary=tf.scalar_summary("accuracy_summary",self.accuracy)
if not is_training:
return
self.globle_step = tf.Variable(0,name="globle_step",trainable=False)
self.lr = tf.Variable(0.0,trainable=False)
tvars = tf.trainable_variables()
grads, _ = tf.clip_by_global_norm(tf.gradients(self.cost, tvars),
config.max_grad_norm)
# Keep track of gradient values and sparsity (optional)
grad_summaries = []
for g, v in zip(grads, tvars):
if g is not None:
grad_hist_summary = tf.histogram_summary("{}/grad/hist".format(v.name), g)
sparsity_summary = tf.scalar_summary("{}/grad/sparsity".format(v.name), tf.nn.zero_fraction(g))
grad_summaries.append(grad_hist_summary)
grad_summaries.append(sparsity_summary)
self.grad_summaries_merged = tf.merge_summary(grad_summaries)
self.summary =tf.merge_summary([loss_summary,accuracy_summary,self.grad_summaries_merged])
optimizer = tf.train.GradientDescentOptimizer(self.lr)
optimizer.apply_gradients(zip(grads, tvars))
self.train_op=optimizer.apply_gradients(zip(grads, tvars))
self.new_lr = tf.placeholder(tf.float32,shape=[],name="new_learning_rate")
self._lr_update = tf.assign(self.lr,self.new_lr)
def assign_new_lr(self,session,lr_value):
session.run(self._lr_update,feed_dict={self.new_lr:lr_value})
def assign_new_batch_size(self,session,batch_size_value):
session.run(self._batch_size_update,feed_dict={self.new_batch_size:batch_size_value})模型不复杂,也就不一一解释了,在debug的时候,还是入了几个tensorflow的坑,因此想单独说一下这几个坑。
坑1:tensor flow的LSTM实现
tensorflow是已经写好了几个LSTM的实现类,可以很方便的使用,而且也可以选择多种类型的LSTM,包括Basic、Bi-Directional等等。
这个代码用的是BasicLSTM:
#build LSTM network
lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(hidden_neural_size,forget_bias=0.0,state_is_tuple=True)
if self.keep_prob<1:
lstm_cell = tf.nn.rnn_cell.DropoutWrapper(
lstm_cell,output_keep_prob=self.keep_prob
)
cell = tf.nn.rnn_cell.MultiRNNCell([lstm_cell]*hidden_layer_num,state_is_tuple=True)
self._initial_state = cell.zero_state(self.batch_size,dtype=tf.float32)
out_put=[]
state=self._initial_state
with tf.variable_scope("LSTM_layer"):
for time_step in range(num_step):
if time_step>0: tf.get_variable_scope().reuse_variables()
(cell_output,state)=cell(inputs[:,time_step,:],state)
out_put.append(cell_output)在这段代码里面,tf.nn.rnn_cell.BasicLSTMCell的初始化只需要制定LSTM神经元的隐含神经元的个数即可,然后需要初始化LSTM网络的参数:self._initial_state = cell.zero_state(self.batch_size,dtype=tf.float32),这句代码乍看一下很迷糊,开始并不知道是什么意义,在实验以及查阅源码之后,返现这句话返回的是两个维度是batch_size*hidden_neural_size的零向量元组,其实就是LSTM初始化的c0、h0向量,当然这里指的是对于单层的LSTM,对于多层的,返回的是多个元组。
坑2:这段代码中的zero_state和循环代数num_step都需要制定
这里比较蛋疼,这就意味着tensorflow中实现变长的情况是要padding的,而且需要全部一样的长度,但是因为数据集的原因,不可能每个batch的size都是一样的,这里就需要每次运行前,动态制定batch_size的大小,代码中体现这个的是assign_new_batch_size函数,但是对于num_step参数却不能动态指定(可能是因为笔者没找到,但是指定tf.Variable()方法确实不行),出于无奈只能将数据集全部padding成指定大小的size,当然既然使用了padding那就必须使用mask矩阵进行计算。
坑3:cost返回non
cost返回Non一般是因为在使用交叉熵时候,logits这一边出现了0值,因此stack overflow上推荐的一般是:sparse_softmax_cross_entropy_with_logits(self.logits+1e-10,self.target)这样写法
训练and结果
实验背景:
tensor flow: tensor flow 0.11
platform:mac OS
数据集:subject dataset,数据集都经过了预处理,拿到的是其在词表中的索引
得益于tensorboard各个参数训练过程都可以可视化,下面是实验训练结果:
训练集训练结果: 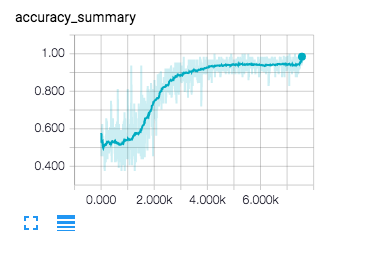
验证集训练结果 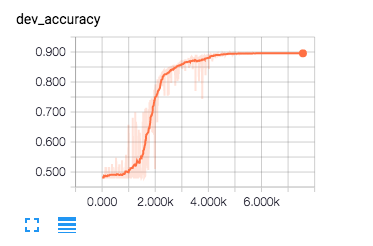
损失函数训练过程 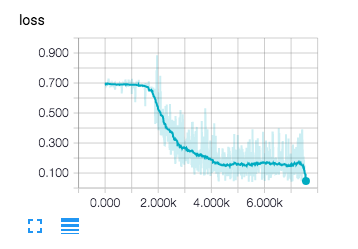
各个参数训练结果:
最终在测试集上,准确度约为85%,还不错。
比较tensorflow和thenao
tensor flow 和 theano 是最近比较流行的深度学习框架,两者非常相似但是两者又不一样,下面就我个人体验比较下两者的异同。
难易程度
就使用难度而言,tensorflow的便易性要远胜于theano,毕竟theano是一堆学者研究出来的,而tensorflow是Google研究出来的,比较面向工业化。tensor flow直接集成了学术界的很多方法,比如像RNN、LSTM等都已经被tensorflow集成了,还有比如参数更新方法如梯度下降、Adadelta等也已经被tensorflow写好了,但是对于theano这个就得自己写,当然难易程度不一样了。
灵活性
就灵活性而言,theano是要胜过tensor flow的,正是因为上一点theano的门槛稍高,却也使得theano有着更大的弹性,可以实现自己任意定义的网络结果,这里不是说tensorflow不行,tensorflow也能写,但是使用tensorflow久了之后,写一些自定义的结构能力就会生疏许多,比如修改LSTM内的一些结构。而Theano则没有这个约束。
- 容错性
我个人觉得theano的容错性是比tensor flow要高的,theano定义变量,只需要制定类型,比如imatrix、ivertor之类的而不用制定任何的维度,只要你输入的数据和你的网络结构图能够对的上的话,就没问题,而tensorflow择需要预先指定一些参数(如上面代码的num_step参数),相比而言,theano的容错能力多得多,当然这样也有坏处,那就是可能对导致代码调试起来比较费劲儿。
代码
本文的代码可以在这里获得,转载请注明出处。
tensorflow实现基于LSTM的文本分类方法的更多相关文章
- 一文详解如何用 TensorFlow 实现基于 LSTM 的文本分类(附源码)
雷锋网按:本文作者陆池,原文载于作者个人博客,雷锋网已获授权. 引言 学习一段时间的tensor flow之后,想找个项目试试手,然后想起了之前在看Theano教程中的一个文本分类的实例,这个星期就用 ...
- 在TensorFlow中基于lstm构建分词系统笔记
在TensorFlow中基于lstm构建分词系统笔记(一) https://www.jianshu.com/p/ccb805b9f014 前言 我打算基于lstm构建一个分词系统,通过这个例子来学习下 ...
- 基于weka的文本分类实现
weka介绍 参见 1)百度百科:http://baike.baidu.com/link?url=V9GKiFxiAoFkaUvPULJ7gK_xoEDnSfUNR1woed0YTmo20Wjo0wY ...
- 基于SVMLight的文本分类
支持向量机(Support Vector Machine)是Cortes和Vapnik于1995年首先提出的,它在解决小样本 .非线性及高维模式识别 中表现出许多特有的优势,并能够推广应用到函数拟合等 ...
- AI - TensorFlow - 示例02:影评文本分类
影评文本分类 文本分类(Text classification):https://www.tensorflow.org/tutorials/keras/basic_text_classificatio ...
- Python 基于 NLP 的文本分类
这是前一段时间在做的事情,有些python库需要python3.5以上,所以mac请先升级 brew安装以下就好,然后Preference(comm+',')->Project: Text-Cl ...
- NLP文本分类方法汇总
模型: FastText TextCNN TextRNN RCNN 分层注意网络(Hierarchical Attention Network) 具有注意的seq2seq模型(seq2seq with ...
- Tensorflow之基于LSTM神经网络写唐诗
最近看了不少关于写诗的博客,在前人的基础上做了一些小的改动,因比较喜欢一次输入很长的开头句,所以让机器人输出压缩为一个开头字生成两个诗句,写五言和七言诗,当然如果你想写更长的诗句是可以继续改动的. 在 ...
- NLP第9章 NLP 中用到的机器学习算法——基于统计学(文本分类和文本聚类)
随机推荐
- Python:Day54 ORM
Django项目中使用mysql DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'books', # ...
- java 方法超时
public void getcd() { logger.info("任务开始!-------------------------------------"); final Exe ...
- docker 9 docker的容器命令
有镜像才能创建容器,这是根本的前提 下面我们以下载一个centos镜像来做演示. [root@t-docker chenzx]# docker images REPOSITORY TAG IMAGE ...
- 获取数值型数组中大于60的元素个数,给数值型数组中不足60分的加20分。(数组,for循环,if条件判断语句)
package com.Summer_0420.cn; /** * @author Summer * 获取数值型数组中大于60的元素个数 * 给数值型数组中不足60分的加20分 */ public c ...
- Java中volatile关键字解析
一.内存模型的相关概念 大家都知道,计算机在执行程序时,每条指令都是在CPU中执行的,而执行指令过程中,势必涉及到数据的读取和写入.由于程序运行过程中的临时数据是存放在主存(物理内存)当中的,这时就存 ...
- selenium:断言
在编写自动化测试脚本时,为了使“机器”去自动辨识test case的执行结果是True还是False,一般都需要在用例执行过程中获取一些信息,来判断用例的执行时成功还是失败. 判断成功失败与否,就涉及 ...
- FineUIMvc v1.4.0 发布了(ASP.NET MVC控件库)!
FineUIMvc v1.4.0 已经于 2017-06-30 发布,FineUIMvc 是基于 jQuery 的专业 ASP.NET MVC 控件库,是我们的新产品.由于和 FineUI(专业版)共 ...
- .NET Core Community 第三个千星项目诞生:爬虫 DotnetSpider
本文所有打赏将全数捐赠于 NCC(NCC 的资金目前由 倾竹大人 负责管理),请注明捐赠于 NCC.捐赠情况将由倾竹大人在此处公示. DotnetSpider 至力于打造一个轻量化.高效率.易开发.可 ...
- find和grep命令合集
linux grep命令 1.作用Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来.grep全称是Global Regular Expressi ...
- 使用 Emmet 生成 HTML 的语法详解
生成 HTML 文档初始结构 HTML 文档的初始结构,就是包括 doctype.html.head.body 以及 meta 等内容.你只需要输入一个 “!” 就可以生成一个 HTML5 的标准文档 ...