centos7下kafka集群安装部署
应用摘要:
Apache kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的
分布式发布订阅消息系统,是消息中间件的一种,用于构建实时数据管道和流应用程序,很火!
Kafka官网:http://kafka.apache.org/
学习推荐 :http://orchome.com/kafka/index
官网下载 :http://kafka.apache.org/downloads
安装环境:
Kafka集群环境搭建,需要准备好一个zookeeper环境(集群),zk集群部署:>> 点击这里 <<

说明:kafka名中的2.12是Scala语言版本,后面的0.11.0.2是kafka版本,端口默认为9092。
2. 编辑配置文件
进入到config目录,编辑配置文件:server.properties
[root@server- config]# vim server.properties
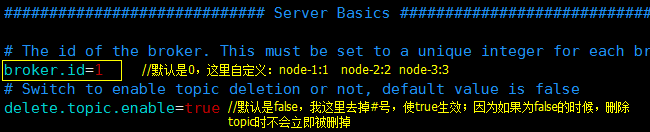
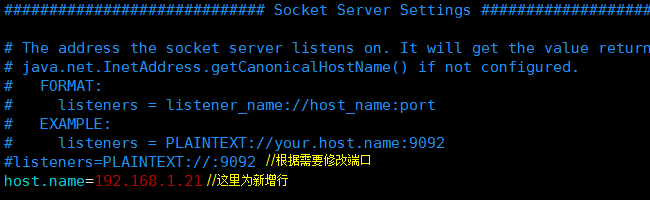


其他配置可以保持默认,保持,退出;
参数说明可以参考:http://orchome.com/12 或者 http://blog.csdn.net/lizhitao/article/details/25667831
同样的操作在server-2和server-3上修改一下broker.id和host.name,不再赘述。
3. 启动Kafka
切换到bin目录中,查看相关脚本:
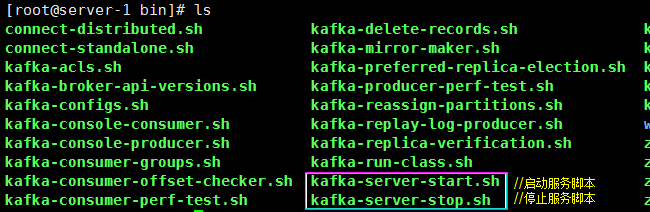

[root@server- bin]# ./kafka-server-start.sh -daemon ../config/server.properties // -daemon:以后台方式启动
查看9092端口状态,确保服务已经启动;
同样的,启动server-2和server-3:
[root@server- bin]# ./kafka-server-start.sh -daemon ../config/server.properties
[root@server- bin]# ./kafka-server-start.sh -daemon ../config/server.properties
至此,kafka安装启动完成。
关闭命令: [root@server- bin]# ./kafka-server-stop.sh //不带任何参数即可
4. 检查测试
在上一篇部署zookeeper集群的时候提到连接kafka使用的时候,里面除了zookeeper之外还有其他内容,来查看一下。
登录zookeeper(切换到zk的bin目录下),先连接zk:
[root@server- bin]# ./zkCli.sh -server 192.168.1.21:
[zk: 192.168.1.21:(CONNECTED) ] ls / cluster controller controller_epoch brokers
zookeeper admin isr_change_notification consumers
latest_producer_id_block config
[zk: 192.168.1.21:(CONNECTED) ] ls /brokers
[ids, topics, seqid]
[zk: 192.168.1.21:(CONNECTED) ] ls /brokers/ids
[, , ]
[zk: 192.168.1.21:(CONNECTED) ]
说明:zookeeper集群建好之后,通过“ls /”出来的只有zookeeper,连接kafka使用后,/ 下面多了不少东西,其中通过查看/brokers/ids可以
发现已经检查到了已经安装的三台kafka的broker.id[1,2,3]。
具体Kafka常见操作见下一篇:kafka命令行常见使用
结束.
centos7下kafka集群安装部署的更多相关文章
- centos7下zookeeper集群安装部署
应用场景:ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件. 它是一个为分布式应用提供一致性服务的软 ...
- Centos7.4 kafka集群安装与kafka-eagle1.3.9的安装
Centos7.4 kafka集群安装与kafka-eagle1.3.9的安装 集群规划: hostname Zookeeper Kafka kafka-eagle kafka01 √ √ √ kaf ...
- kafka集群安装部署
kafka集群安装 使用的版本 系统:centos6.5 centos6.7 jdk:1.7.0_79 zookeeper:3.4.9 kafka:2.10-0.10.1.0 一.环境准备[只列,不具 ...
- Kafka集群安装部署、Kafka生产者、Kafka消费者
Storm上游数据源之Kakfa 目标: 理解Storm消费的数据来源.理解JMS规范.理解Kafka核心组件.掌握Kakfa生产者API.掌握Kafka消费者API.对流式计算的生态环境有深入的了解 ...
- Linux 下Redis集群安装部署及使用详解(在线和离线两种安装+相关错误解决方案)
一.应用场景介绍 本文主要是介绍Redis集群在Linux环境下的安装讲解,其中主要包括在联网的Linux环境和脱机的Linux环境下是如何安装的.因为大多数时候,公司的生产环境是在内网环境下,无外网 ...
- Kafka 集群安装部署
2.1 安装部署 2.1.1 集群规划 192.168.1.102 192.168.1.103 192.168.1.104 zookeeper zookeeper zookeeper kafka ka ...
- centos7:Kafka集群安装
解压文件到安装目录 tar -zxvf kafka_2.10-0.10.2.1.tgz 1.进入目录 cd kafka_2.10-0.10.2.1 mkdir logs cd config cp se ...
- Elasticsearch学习总结 (Centos7下Elasticsearch集群部署记录)
一. ElasticSearch简单介绍 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elasticse ...
- 原创:centos7.1下 ZooKeeper 集群安装配置+Python实战范例
centos7.1下 ZooKeeper 集群安装配置+Python实战范例 下载:http://apache.fayea.com/zookeeper/zookeeper-3.4.9/zookeepe ...
随机推荐
- b,B,KB,MB,GB,TB,PB,EB,ZB,YB,BB,NB,DB的含义,之间的关系
1bit=1位2进制信息 1B (byte 字节)1KB(Kilobyte 千字节)=2(10)B=1024B=2(10)B: 1MB(Megabyte 兆字节)=2(10)KB=1024KB=2(2 ...
- [转帖]SPU、SKU、ID,它们都是什么意思,三者又有什么区别和联系呢?
SPU.SKU.ID,它们都是什么意思,三者又有什么区别和联系呢? http://blog.sina.com.cn/s/blog_5ff11b130102wx0p.html 电商时代,数据为王. 所以 ...
- MySQL索引管理及执行计划
一.索引介绍 二.explain详解 三.建立索引的原则(规范)
- 不停机修改线上 MySQL 主键字段 以及其带来的问题和总结思考
起因: 线上 user 数据库没有自增字段,数据量已经达到百万级.无论是给离线仓库还是数据分析同步数据,没有主键自增 id 都是杀手级的困难.所以在使用 create_time 痛苦了几次之后准备彻底 ...
- ArcGIS 添加 MarkerSymbol 弹出“图形符号无法序列化为 JSON”错误
今天在做一个demo,向自定义图层中添加MarkerSymbol的时候,弹出“图形符号无法序列化为 JSON”错误,之前都没有出现过这个问题,我们首先来看一看我是怎样去添加图层,然后向图层中添加Gra ...
- 集合之TreeMap(含JDK1.8源码分析)
一.前言 前面所说的hashMap和linkedHashMap都不具备统计的功能,或者说它们的统计性能的时间复杂度都不是很好,要想对两者进行统计,需要遍历所有的entry,时间复杂度比较高,此时,我们 ...
- Spring Boot基础:Spring Boot简介与快速搭建(1)
1. Spring Boot简介 Spring Boot是由Pivotal团队提供的全新框架,其设计目的是用来简化Spring应用的创建.运行.调试.部署等. Spring Boot默认使用tomca ...
- SpringJdbc框架
import javax.sql.DataSource; import org.springframework.jdbc.core.JdbcTemplate; import JdbcUtils.Jdb ...
- CS新建排版
1.拉菜单栏barmanage,去掉不要的头部和尾部 ,选择控件bar属性optionsbar 全部为false,防止菜单拖动. 2.拉一个panelcontrol属性dock 设置顶部,在拉一个p ...
- 安装mysql zip5.6版--安裝
第一步当然是下载了,我下载的是压缩包形式的安装包,这种直接解压就可以了,地址是:https://dev.mysql.com/downloads/file/?id=468784 第二步就是解压了,解压到 ...