Flink的容错
checkpoint介绍
checkpoint机制是Flink可靠性的基石,可以保证Flink集群在某个算子因为某些原因(如 异常退出)出现故障时,能够将整个应用流图的状态恢复到故障之前的某一状态,保 证应用流图状态的一致性。Flink的checkpoint机制原理来自“Chandy-Lamport algorithm”算法。
每个需要checkpoint的应用在启动时,Flink的JobManager为其创建一个 CheckpointCoordinator,CheckpointCoordinator全权负责本应用的快照制作

1. CheckpointCoordinator周期性的向该流应用的所有source算子发送barrier。
2.当某个source算子收到一个barrier时,便暂停数据处理过程,然后将自己的当前状 态制作成快照,并保存到指定的持久化存储中,最后向CheckpointCoordinator报告 自己快照制作情况,同时向自身所有下游算子广播该barrier,恢复数据处理
3.下游算子收到barrier之后,会暂停自己的数据处理过程,然后将自身的相关状态制作成快照,并保存到指定的持久化存储中,最后向CheckpointCoordinator报告自身 快照情况,同时向自身所有下游算子广播该barrier,恢复数据处理。
4. 每个算子按照步骤3不断制作快照并向下游广播,直到最后barrier传递到sink算子,快照制作完成。
5. 当CheckpointCoordinator收到所有算子的报告之后,认为该周期的快照制作成功; 否则,如果在规定的时间内没有收到所有算子的报告,则认为本周期快照制作失败
如果一个算子有两个输入源,则暂时阻塞先收到barrier的输入源,等到第二个输入源相 同编号的barrier到来时,再制作自身快照并向下游广播该barrier。具体如下图所示
两个输入源 checkpoint 过程 :
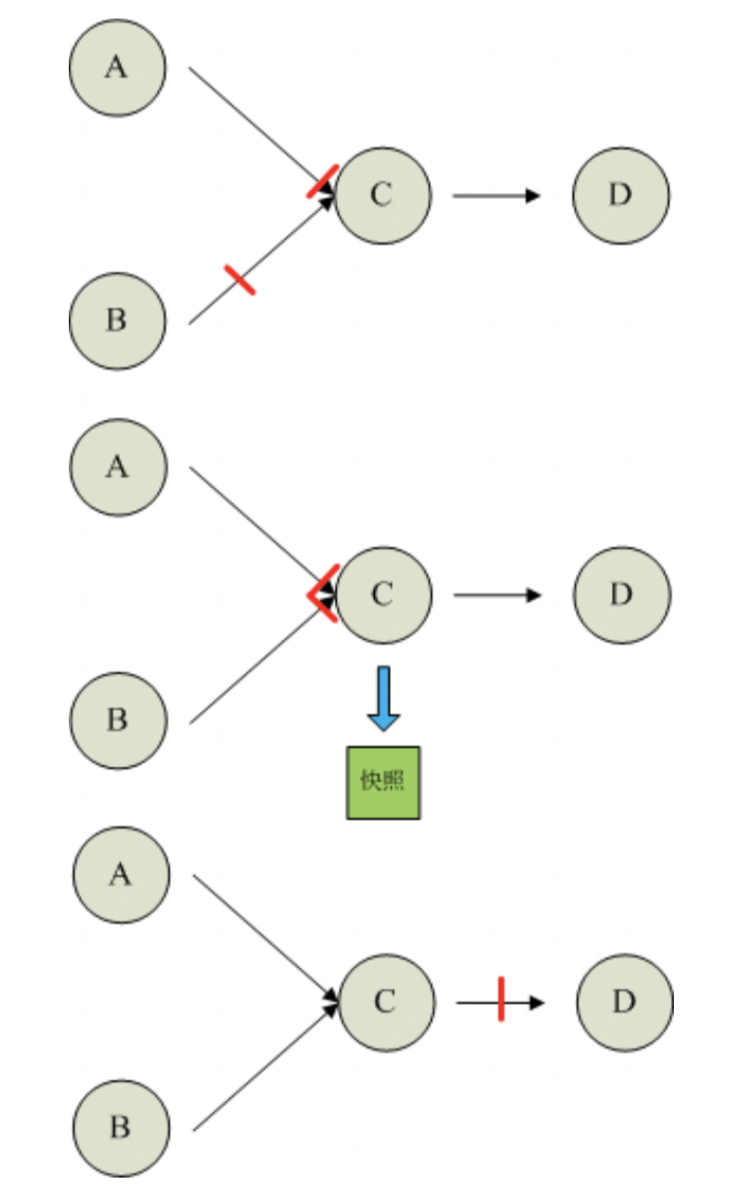
1. 假设算子C有A和B两个输入源
2. 在第i个快照周期中,由于某些原因(如处理时延、网络时延等)输入源A发出的 barrier先到来,这时算子C暂时将输入源A的输入通道阻塞,仅收输入源B的数据。
3. 当输入源B发出的barrier到来时,算子C制作自身快照并向CheckpointCoordinator报 告自身的快照制作情况,然后将两个barrier合并为一个,向下游所有的算子广播。
当由于某些原因出现故障时,CheckpointCoordinator通知流图上所有算子统一恢复到某 个周期的checkpoint状态,然后恢复数据流处理。分布式checkpoint机制保证了数据仅被 处理一次(Exactly Once)。
持久化存储
目前,Checkpoint持久化存储可以使用如下三种:
MemStateBackend
该持久化存储主要将快照数据保存到JobManager的内存中,仅适合作为测试以及 快照的数据量非常小时使用,并不推荐用作大规模商业部署。
FsStateBackend
该持久化存储主要将快照数据保存到文件系统中,目前支持的文件系统主要是 HDFS和本地文件。如果使用HDFS,则初始化FsStateBackend时,需要传入以 “hdfs://”开头的路径(即: new FsStateBackend("hdfs:///hacluster/checkpoint")), 如果使用本地文件,则需要传入以“file://”开头的路径(即:new FsStateBackend("file:///Data"))。在分布式情况下,不推荐使用本地文件。如果某 个算子在节点A上失败,在节点B上恢复,使用本地文件时,在B上无法读取节点 A上的数据,导致状态恢复失败。
RocksDBStateBackend
RocksDBStatBackend介于本地文件和HDFS之间,平时使用RocksDB的功能,将数 据持久化到本地文件中,当制作快照时,将本地数据制作成快照,并持久化到 FsStateBackend中(FsStateBackend不必用户特别指明,只需在初始化时传入HDFS 或本地路径即可,如new RocksDBStateBackend("hdfs:///hacluster/checkpoint")或new RocksDBStateBackend("file:///Data"))。
如果用户使用自定义窗口(window),不推荐用户使用RocksDBStateBackend。在自 定义窗口中,状态以ListState的形式保存在StatBackend中,如果一个key值中有多 个value值,则RocksDB读取该种ListState非常缓慢,影响性能。用户可以根据应用 的具体情况选择FsStateBackend+HDFS或RocksStateBackend+HDFS。
语法:
val env = StreamExecutionEnvironment.getExecutionEnvironment()
// start a checkpoint every 1000 ms
env.enableCheckpointing(1000)
// advanced options:
// 设置checkpoint的执行模式,最多执行一次或者至少执行一次
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
// 设置checkpoint的超时时间
env.getCheckpointConfig.setCheckpointTimeout(60000)
// 如果在只做快照过程中出现错误,是否让整体任务失败:true是 false不是
env.getCheckpointConfig.setFailTasksOnCheckpointingErrors(false)
//设置同一时间有多少 个checkpoint可以同时执行
env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
需求:
假定用户需要每隔1秒钟需要统计4秒中窗口中数据的量,然后对统计的结果值进行checkpoint处理
数据规划:
\1. 使用自定义算子每秒钟产生大约10000条数据。 \2. 产生的数据为一个四元组(Long,String,String,Integer)—------(id,name,info,count)。 \3. 数据经统计后,统计结果打印到终端输出。 \4. 打印输出的结果为Long类型的数据。
开发思路:
\1. source算子每隔1秒钟发送10000条数据,并注入到Window算子中。 \2. window算子每隔1秒钟统计一次最近4秒钟内数据数量。 \3. 每隔1秒钟将统计结果打印到终端 \4. 每隔6秒钟触发一次checkpoint,然后将checkpoint的结果保存到HDFS中。
//发送数据形式
case class SEvent(id: Long, name: String, info: String, count: Int) class SEventSourceWithChk extends RichSourceFunction[SEvent]{
private var count = 0L
private var isRunning = true
private val alphabet = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWZYX0987654321"
// 任务取消时调用
override def cancel(): Unit = {
isRunning = false
}
//// source算子的逻辑,即:每秒钟向流图中注入10000个元组
override def run(sourceContext: SourceContext[SEvent]): Unit = {
while(isRunning) {
for (i <- 0 until 10000) {
sourceContext.collect(SEvent(1, "hello-"+count, alphabet,1))
count += 1L
}
Thread.sleep(1000)
}
}
} /**
该段代码是流图定义代码,具体实现业务流程,另外,代码中窗口的触发时间使 用了event time。
*/
object FlinkEventTimeAPIChkMain {
def main(args: Array[String]): Unit ={
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStateBackend(new FsStateBackend("hdfs://hadoop01:9000/flink-checkpoint/checkpoint/"))
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
env.getCheckpointConfig.setCheckpointInterval(6000)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
// 应用逻辑
val source: DataStream[SEvent] = env.addSource(new SEventSourceWithChk)
source.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks[SEvent] {
// 设置watermark
override def getCurrentWatermark: Watermark = {
new Watermark(System.currentTimeMillis())
}
// 给每个元组打上时间戳
override def extractTimestamp(t: SEvent, l: Long): Long = {
System.currentTimeMillis()
}
})
.keyBy(0)
.window(SlidingEventTimeWindows.of(Time.seconds(4), Time.seconds(1)))
.apply(new WindowStatisticWithChk)
.print()
env.execute()
}
} //该数据在算子制作快照时用于保存到目前为止算子记录的数据条数。
// 用户自定义状态
class UDFState extends Serializable{
private var count = 0L
// 设置用户自定义状态
def setState(s: Long) = count = s
// 获取用户自定状态
def getState = count
} //该段代码是window算子的代码,每当触发计算时统计窗口中元组数量。
class WindowStatisticWithChk extends WindowFunction[SEvent, Long, Tuple, TimeWindow] with ListCheckpointed[UDFState]{
private var total = 0L // window算子的实现逻辑,即:统计window中元组的数量
override def apply(key: Tuple, window: TimeWindow, input: Iterable[SEvent], out: Collector[Long]): Unit = {
var count = 0L
for (event <- input) {
count += 1L
}
total += count
out.collect(count)
}
// 从自定义快照中恢复状态
override def restoreState(state: util.List[UDFState]): Unit = {
val udfState = state.get(0)
total = udfState.getState
} // 制作自定义状态快照
override def snapshotState(checkpointId: Long, timestamp: Long): util.List[UDFState] = {
val udfList: util.ArrayList[UDFState] = new util.ArrayList[UDFState]
val udfState = new UDFState
udfState.setState(total)
udfList.add(udfState)
udfList
}
}
Flink的容错的更多相关文章
- flink03-----1.Task的划分 2.共享资源槽 3.flink的容错
1. Task的划分 在flink中,划分task的依据是发生shuffle(也叫redistrubute),或者是并行度发生变化 1. wordcount为例 package cn._51doit ...
- Apache Flink - 数据流容错机制
Apache Flink提供了一种容错机制,可以持续恢复数据流应用程序的状态.该机制确保即使出现故障,程序的状态最终也会反映来自数据流的每条记录(只有一次). 从容错和消息处理的语义上(at leas ...
- Flink Program Guide (7) -- 容错 Fault Tolerance(DataStream API编程指导 -- For Java)
false false false false EN-US ZH-CN X-NONE /* Style Definitions */ table.MsoNormalTable {mso-style-n ...
- Flink原理(五)——容错机制
本文是博主阅读Flink官方文档以及<Flink基础教程>后结合自己理解所写,若有表达有误的地方欢迎大伙留言指出. 1. 前言 流式计算分为有状态和无状态两种情况,所谓状态就是计算过程中 ...
- Flink 容错机制与状态
简介 Apache Flink提供了一种容错机制,可以持续恢复数据流应用程序的状态. 该机制确保即使出现故障,经过恢复,程序的状态也会回到以前的状态. Flink 主持 at least once 语 ...
- 9、flink的状态与容错
1.理解State(状态) 1.1.State 对象的状态 Flink中的状态:一般指一个具体的task/operator某时刻在内存中的状态(例如某属性的值) 注意:State和Checkpoint ...
- Flink 剖析
1.概述 在如今数据爆炸的时代,企业的数据量与日俱增,大数据产品层出不穷.今天给大家分享一款产品—— Apache Flink,目前,已是 Apache 顶级项目之一.那么,接下来,笔者为大家介绍Fl ...
- Apache Flink
Flink 剖析 1.概述 在如今数据爆炸的时代,企业的数据量与日俱增,大数据产品层出不穷.今天给大家分享一款产品—— Apache Flink,目前,已是 Apache 顶级项目之一.那么,接下来, ...
- 流式处理新秀Flink原理与实践
随着大数据技术在各行各业的广泛应用,要求能对海量数据进行实时处理的需求越来越多,同时数据处理的业务逻辑也越来越复杂,传统的批处理方式和早期的流式处理框架也越来越难以在延迟性.吞吐量.容错能力以及使用便 ...
随机推荐
- $Djangon admin界面 添加表 增删查改
from django.contrib import admin表变中文 class Meta: verbose_name_plural='评论表' null=True的字段:admin创建要求写可以 ...
- mysql的csv数据导入与导出
# 需要station_realtime存在 load data infile 'd:/xxxx/station_realtime2013_01.csv' into table `station_re ...
- PHP超精简文章管理系统 Summer Article
2017年3月8日 21:18:43 星期三 git: https://git.oschina.net/myDcool/article.git 截图:
- ASP.NET 验证码绘制
using System; using System.Collections.Generic; using System.Linq; using System.Web; using System.We ...
- SqlBulkCopy 之 Received an invalid column length from the bcp client for colid 5.
SqlBulkCopy 批量复制报错: Received an invalid column length from the bcp client for colid 5. 翻译:从bcp客户端收到一 ...
- Java中关于string的些许问题及解析
问题一:String 和 StringBuffer 的区别JAVA 平台提供了两个类: String 和 StringBuf fer ,它们可以储存和操作字符串,即包含多个字符的字符数据.这个 Str ...
- 通过cmd 使用 InstallUtil.exe 命令 操作 windows服务 Windows Service
要安装windows service 首先要找到 InstallUtil.exe,InstallUtil.exe位置在 C:\Windows\Microsoft.NET\Framework\v4.0. ...
- Confluence 6 企业环境或者网站托管的 Java 配置策略
Confluence 需要依赖一些 Java 的库才能够允运行.一些依赖的 Java 库应用了 Java 的语言特性,但是又是被 Java 的安全策略所限制的. 这个通常来说是不会造成任何问题的.默认 ...
- Confluence 6 从外部目录中同步数据配置同步间隔
在用户目录(User Directories)界面中显示了最后的系统同步时间,包括有这次同步所花费的时间. 注意:针对 Crowd 和 Jira 目录同步时间的配置只在 Confluence 3.5 ...
- Python之函数(自定义函数,内置函数,装饰器,迭代器,生成器)
Python之函数(自定义函数,内置函数,装饰器,迭代器,生成器) 1.初始函数 2.函数嵌套及作用域 3.装饰器 4.迭代器和生成器 6.内置函数 7.递归函数 8.匿名函数