kudu集成impala

Kudu 与 Apache Impala (孵化)紧密集成,允许开发人员使用 Impala 使用 Impala 的 SQL 语法从 Kudu tablets 插入,查询,更新和删除数据;
安装impala
安装规划
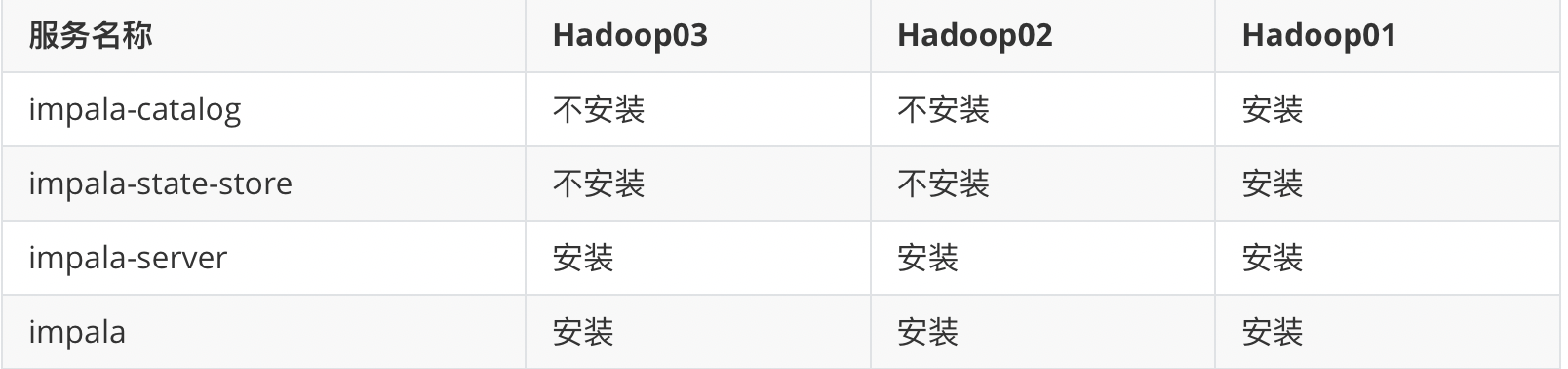
:Imppalla catalog服务将SQL语句做出的元数据变化通知给集群的各个节点 :Impala Statestore检查集群各个节点上Impala daemon的健康状态
主节点hadoop01执行以下命令进行安装
yum install impala -y
yum install impala-server -y
yum install impala-state-store -y
yum install impala-catalog -y
yum install impala-shell -y
从节点hadoop02与hadoop03安装以下服务
yum install impala-server -y yum install impala -y
所有节点配置impala
修改hive-site.xml
impala依赖于hive,所以首先需要进行hive的配置修改;
Hadoop01机器修改hive-site.xml内容如下
hive-site.xml配置
vim /opt/cdh/hive-1.1.0-cdh5.14.0/conf/hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop01:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop01</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop01:9083</value>
</property>
<property>
<name>hive.metastore.client.socket.timeout</name>
<value></value>
</property> </configuration>
添加mysql的jar包,放入hive的lib目录下
(cp mysql的connection包,复制在hive的lib下)
将hive的安装包发送到hadoop02与hadoop03机器上
在hadoop01机器上面执行
cd /opt/cdh/
scp -r hive-1.1.-cdh5.14.0/ hadoop02:$PWD
scp -r hive-1.1.-cdh5.14.0/ hadoop03:$PWD
启动hive的metastore服务
启动hive的metastore服务(如果impala报错,则启动全部hive)
Hadoop01机器启动hive的metastore服务
cd /opt/cdh/hive-1.1.-cdh5.14.0
nohup bin/hive --service metastore &
注意:一定要保证mysql的服务正常启动,否则metastore的服务不能够启动
所有hadoop节点修改hdfs-site.xml添加以下内容
所有节点创建文件夹
mkdir -p /var/run/hdfs-sockets
修改所有节点的hdfs-site.xml添加以下配置,修改完之后重启hdfs集群生效
vim /opt/cdh/hadoop-2.6.0-cdh5.14.0/etc/hadoop/hdfs-site.xml
<configuration>
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value></value>
</property> <property>
<name>dfs.secondary.http.address</name>
<value>hadoop01:</value>
</property> <property>
<name>dfs.client.read.shortcircuit</name>
<value>true</value>
</property>
<property>
<name>dfs.domain.socket.path</name>
<value>/var/run/hdfs-sockets/dn</value>
</property>
<property>
<name>dfs.client.file-block-storage-locations.timeout.millis</name>
<value></value>
</property>
<property>
<name>dfs.datanode.hdfs-blocks-metadata.enabled</name>
<value>true</value>
</property> <property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
注意:root用户不需要这一步操作了,实际工作当中普通用户需要这一步操作
创建文件夹 /var/run/hadoop-sockets/
给这个文件夹赋予权限,例如如果我们用的是普通用户,那就直接赋予普通用户的权限
例如:
chown -R angel:angel /var/run/hadoop-sockets/
因为我这里直接用的root用户,所以不需要赋权限了
重启hdfs
重启hdfs文件系统
Hadoop01服务器上面执行以下命令
cd /opt/cdh/hadoop-2.6.-cdh5.14.0/ sbin/stop-dfs.sh sbin/start-dfs.sh
创建hadoop与hive的配置文件的连接
impala的配置目录为 /etc/impala/conf
这个路径下面需要把core-site.xml,hdfs-site.xml以及hive-site.xml拷贝到这里来,但是我们这里使用软连接的方式会更好
所有节点执行以下命令创建链接到impala配置目录下来
ln -s /opt/cdh/hadoop-2.6.-cdh5.14.0/etc/hadoop/core-site.xml /etc/impala/conf/core-site.xml
ln -s /opt/cdh/hadoop-2.6.-cdh5.14.0/etc/hadoop/hdfs-site.xml /etc/impala/conf/hdfs-site.xml
ln -s /opt/cdh/hive-1.1.-cdh5.14.0/conf/hive-site.xml /etc/impala/conf/hive-site.xml
所有节点修改impala默认配置
所有节点更改impala默认配置文件以及添加mysql的连接驱动包
vim /etc/default/impala
IMPALA_CATALOG_SERVICE_HOST=hadoop01
IMPALA_STATE_STORE_HOST=hadoop01
所有节点创建mysql的驱动包的软连接
ln -s /opt/cdh/hive-1.1.-cdh5.14.0/lib/mysql-connector-java-5.1..jar /usr/share/java/mysql-connector-java.jar
所有节点修改bigtop的java路径
修改bigtop的java_home路径
vim /etc/default/bigtop-utils
export JAVA_HOME=/opt/cdh/jdk1..0_181
启动impala服务
主节点hadoop01启动以下三个服务进程
service impala-state-store start
service impala-catalog start
service impala-server start service impala-state-store stop
service impala-catalog stop
service impala-server stop
从节点启动hadoop02与hadoop03s启动impala-server
service impala-server start|stop
查看impala进程是否存在
ps -ef | grep impala
注意:启动之后所有关于impala的日志默认都在/var/log/impala 这个路径下,hadoop01机器上面应该有三个进程,hadoop02与hadoop03机器上面只有一个进程,如果进程个数不对,去对应目录下查看报错日志
浏览器页面访问
访问impalad的管理界面http://hadoop01:25000/
访问statestored的管理界面http://hadoop01:25010/
将impala与kudu整合
在每一个服务器的impala的配置文件中添加如下配置:
vim /etc/default/impala
在IMPALA_SERVER_ARGS下添加:-kudu_master_hosts=hadoop01:,hadoop02:,hadoop03:
kudu集成impala的更多相关文章
- 实战kudu集成impala
推荐阅读: 论主数据的重要性(正确理解元数据.数据元) CDC+ETL实现数据集成方案 Java实现impala操作kudu 实战kudu集成impala impala基本介绍 im ...
- impala记录-安装kudu和impala
1.配置/etc/yum.repos.d clouder-kudu.repo [cloudera-kudu]# Packages for Cloudera's Distribution for kud ...
- ambari hdp 集成 impala
1.下载ambari-impala-service VERSION=`hdp-select status hadoop-client | sed 's/hadoop-client - \([0-9]\ ...
- ambari集成impala
1.查看hdp版本,可在ambari-agent节点上查看 VERSION=`hdp-select status hadoop-client | sed 's/hadoop-client - \([0 ...
- Java实现impala操作kudu
推荐阅读: 论主数据的重要性(正确理解元数据.数据元) CDC+ETL实现数据集成方案 Java实现impala操作kudu 实战kudu集成impala 对于impala而言,开发人员是可以通过JD ...
- kudu基础入门
1.kudu介绍 1.1 背景介绍 在KUDU之前,大数据主要以两种方式存储: (1)静态数据: 以 HDFS 引擎作为存储引擎,适用于高吞吐量的离线大数据分析场景.这类存储的局限性是数据无法进行随机 ...
- kudu导入文件(基于impala)
kudu是cloudera开源的运行在hadoop平台上的列式存储系统,拥有Hadoop生态系统应用的常见技术特性,运行在一般的商用硬件上,支持水平扩展,高可用,集成impala后,支持标准sql语句 ...
- Kudu+Impala介绍
Kudu+Impala介绍 概述 Kudu和Impala均是Cloudera贡献给Apache基金会的顶级项目.Kudu作为底层存储,在支持高并发低延迟kv查询的同时,还保持良好的Scan性能,该特性 ...
- impala和kudu使用的小细节
七堇年:我们要有最朴素的生活与最遥远的梦想 . 即使明日天寒地冻,路远马亡. 加油! 之前入门的小错误总结,建表都会出错,真的好尴尬 还是要做好笔记 第一个错误: error:AnalysisEx ...
随机推荐
- $Django ajax简介 ajax简单数据交互,上传文件(form-data格式数据),Json数据格式交互
一.ajax 1 什么是ajax:异步的JavaScript和xml,跟后台交互,都用json 2 ajax干啥用的?前后端做数据交互: 3 之前学的跟后台做交互的方式: -第一种:在浏览器 ...
- linux 过滤内存使用率并于计划任务结合来自动清理内存缓存
过滤出内存使用率并进行判断 #!/bin/bash echo "###cleand free_cache script########" #memory usage mem_pus ...
- 信息摘要算法之七:SHA在区块链中的应用
最近几年比特币的火爆带动了人们对区块链技术的研究.当然我们在这里并不讨论区块链技术本身,而是讨论一下区块链中的SHA算法的应用.对于SHA系列算法我们已经在前面作了说明,在这里也不再重复. 1.区块链 ...
- ORA-00257 archiver error. 错误的处理方法
archive log 日志已满 方法/步骤 1 SecureCRT登录服务器,切换用户oracle,连接oracle [root@userbeta~]# su - oracle [oracle@us ...
- 银联支付java版
注:本文来源于:< 银联支付java版 > 银联支付java版 2016年09月18日 15:55:20 阅读数:2431 首先去银联官网注册测试支付账户 下载对应的demo[ ...
- Confluence 6 手动安装语言包和找到更多语言包
手动安装语言包 希望以手动的方式按照语言包,你需要按照下面描述的方式上传语言包.一旦你安装成功后,语言包插件将会默认启用. 插件通常以 JAR 或者 OBR(OSGi Bundle Repositor ...
- Java的动手动脑(六)
日期:2018.11.8 星期四 博客期:022 --------------------------------------------------------------------------- ...
- mac 端口占用问题
查看端口号 终端输入:sudo lsof -i tcp:port 将port换成被占用的端口(如:8086.9998) 将会出现占用端口的进程信息. 杀死占用端口的PID进程 找到进程的PID,使用k ...
- spring boot 解决跨域访问
package com.newings.disaster.shelters.configuration; import org.springframework.context.annotation.B ...
- LeetCode(69):x 的平方根
Easy! 题目描述: 实现 int sqrt(int x) 函数. 计算并返回 x 的平方根,其中 x 是非负整数. 由于返回类型是整数,结果只保留整数的部分,小数部分将被舍去. 示例 1: 输入: ...