(七)Transformation和action详解-Java&Python版Spark
Transformation和action详解
视频教程:
1、优酷
2、YouTube
什么是算子
算子是RDD中定义的函数,可以对RDD中的数据进行转换和操作。
算子分类:
具体:
1、Value数据类型的Transformation算子,这种变换并不触发提交作业,针对处理的数据项是Value型的数据。
2、Key-Value数据类型的Transfromation算子,这种变换并不触发提交作业,针对处理的数据项是Key-Value型的数据对。
3、Action算子,这类算子会触发SparkContext提交Job作业。
RDD有两种操作算子:
1、Transformation(转换)
2、Ation(执行)
作用
1、transformation是得到一个新的RDD,方式很多,比如从数据源生成一个新的RDD,从RDD生成一个新的RDD,Transformation属于延迟计算,当一个RDD转换成另一个RDD时并没有立即进行转换,仅仅是记住了数据集的逻辑操作。
2、action是得到一个值,或者一个结果(直接将RDDcache到内存中),触发Spark作业的运行,真正触发转换算子的计算。
所有的transformation都是采用的懒策略,如果只是将transformation提交是不会执行计算的,计算只有在action被提交的时候才被触发。
下图描述了Spark在运行转换中通过算子对RDD进行转换:
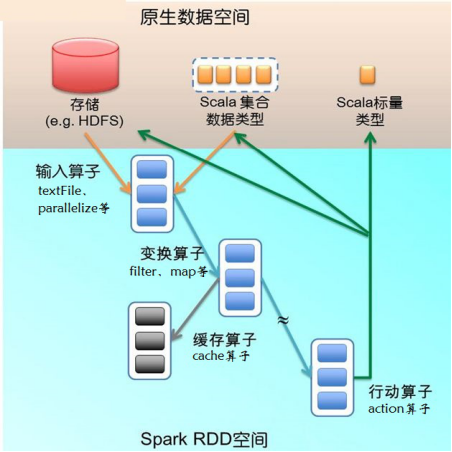
输入:在Spark程序运行中,数据从外部数据空间(如分布式存储:textFile读取HDFS等,parallelize方法输入Scala集合或数据)输入Spark,数据进入Spark运行时数据空间,转化为Spark中的数据块,通过BlockManager进行管理。
运行:在Spark数据输入形成RDD后便可以通过变换算子,如filter等,对数据进行操作并将RDD转化为新的RDD,通过Action算子,触发Spark提交作业。 如果数据需要复用,可以通过Cache算子,将数据缓存到内存。
输出:程序运行结束数据会输出Spark运行时空间,存储到分布式存储中(如saveAsTextFile输出到HDFS),或Scala数据或集合中(collect输出到Scala集合,count返回Scala int型数据)。
Transformation和Actions操作概况
Transformation具体内容
1、map(func) :返回一个新的分布式数据集,由每个原元素经过func函数转换后组成。
2、filter(func) : 返回一个新的数据集,由经过func函数后返回值为true的原元素组成 。
3、flatMap(func) : 类似于map,但是每一个输入元素,会被映射为0到多个输出元素(因此,func函数的返回值是一个Seq,而不是单一元素)。
4、sample(withReplacement, frac, seed) : 根据给定的随机种子seed,随机抽样出数量为frac的数据。
5、union(otherDataset) : 返回一个新的数据集,由原数据集和参数联合而成。
6、groupByKey([numTasks]) : 在一个由(K,V)对组成的数据集上调用,返回一个(K,Seq[V])对的数据集。注意:默认情况下,使用8个并行任务进行分组,你可以传入numTask可选参数,根据数据量设置不同数目的Task。
7、reduceByKey(func, [numTasks]) : 在一个(K,V)对的数据集上使用,返回一个(K,V)对的数据集,key相同的值,都被使用指定的reduce函数聚合到一起。和groupbykey类似,任务的个数是可以通过第二个可选参数来配置的。
8、join(otherDataset, [numTasks]) : 在类型为(K,V)和(K,W)类型的数据集上调用,返回一个(K,(V,W))对,每个key中的所有元素都在一起的数据集。
9、groupWith(otherDataset, [numTasks]) : 在类型为(K,V)和(K,W)类型的数据集上调用,返回一个数据集,组成元素为(K, Seq[V], Seq[W]) Tuples。
10、cartesian(otherDataset) : 笛卡尔积。但在数据集T和U上调用时,返回一个(T,U)对的数据集,所有元素交互进行笛卡尔积。
Actions具体内容
1、reduce(func) : 通过函数func聚集数据集中的所有元素。Func函数接受2个参数,返回一个值。这个函数必须是关联性的,确保可以被正确的并发执行。
2、collect() : 在Driver的程序中,以数组的形式,返回数据集的所有元素。这通常会在使用filter或者其它操作后,返回一个足够小的数据子集再使用,直接将整个RDD集Collect返回,很可能会让Driver程序OOM。
3、count() : 返回数据集的元素个数。
4、take(n) : 返回一个数组,由数据集的前n个元素组成。注意,这个操作目前并非在多个节点上,并行执行,而是Driver程序所在机器,单机计算所有的元素内存压力会增大,需要谨慎使用。
5、first() : 返回数据集的第一个元素(类似于take(1))。
6、saveAsTextFile(path) : 将数据集的元素,以textfile的形式,保存到本地文件系统,hdfs或者任何其它hadoop支持的文件系统。Spark将会调用每个元素的toString方法,并将它转换为文件中的一行文本。
7、saveAsSequenceFile(path) : 将数据集的元素,以sequencefile的格式,保存到指定的目录下,本地系统,hdfs或者任何其它hadoop支持的文件系统。RDD的元素必须由key-value对组成,并都实现了Hadoop的Writable接口,或隐式可以转换为Writable(Spark包括了基本类型的转换,例如Int,Double,String等等)。
8、foreach(func) : 在数据集的每一个元素上,运行函数func。这通常用于更新一个累加器变量,或者和外部存储系统做交互。
(七)Transformation和action详解-Java&Python版Spark的更多相关文章
- (八)map,filter,flatMap算子-Java&Python版Spark
map,filter,flatMap算子 视频教程: 1.优酷 2.YouTube 1.map map是将源JavaRDD的一个一个元素的传入call方法,并经过算法后一个一个的返回从而生成一个新的J ...
- sparkStreaming的transformation和action详解
根据Spark官方文档中的描述,在Spark Streaming应用中,一个DStream对象可以调用多种操作,主要分为以下几类 Transformations Window Operations J ...
- (一)Spark简介-Java&Python版Spark
Spark简介 视频教程: 1.优酷 2.YouTube 简介: Spark是加州大学伯克利分校AMP实验室,开发的通用内存并行计算框架.Spark在2013年6月进入Apache成为孵化项目,8个月 ...
- (四)Spark集群搭建-Java&Python版Spark
Spark集群搭建 视频教程 1.优酷 2.YouTube 安装scala环境 下载地址http://www.scala-lang.org/download/ 上传scala-2.10.5.tgz到m ...
- (二)Spark-Linux环境准备-Java&Python版Spark
Spark-Linux环境准备 视频教程: 1.优酷 2.YouTube 硬软件环境 1.虚拟机:VMware Workstation 12 2.虚拟机操作系统:RedHat5u4,单核,1G内存,2 ...
- (九)groupByKey,reduceByKey,sortByKey算子-Java&Python版Spark
groupByKey,reduceByKey,sortByKey算子 视频教程: 1.优酷 2. YouTube 1.groupByKey groupByKey是对每个key进行合并操作,但只生成一个 ...
- (三)Spark-Hadoop集群搭建-Java&Python版Spark
Spark-Hadoop集群搭建 视频教程: 1.优酷 2.YouTube 配置java 启动ftp [root@master ~]# /etc/init.d/vsftpd restart 关闭 vs ...
- “全栈2019”Java第七十章:静态内部类详解
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java第 ...
- Protocol Buffer技术详解(Java实例)
Protocol Buffer技术详解(Java实例) 该篇Blog和上一篇(C++实例)基本相同,只是面向于我们团队中的Java工程师,毕竟我们项目的前端部分是基于Android开发的,而且我们研发 ...
随机推荐
- 自动添加Linux登录账户,并授予sudo权限
#!/bin/bash USER=test PASS=$USER GROUP=root HOME=/data/home/$USER # if user not exist if [[ $(cat /e ...
- ASP.NET Web API 控制器执行过程(一)
ASP.NET Web API 控制器执行过程(一) 前言 前面两篇讲解了控制器的创建过程,只是从框架源码的角度去简单的了解,在控制器创建过后所执行的过程也是尤为重要的,本篇就来简单的说明一下控制器在 ...
- CSharpGL(11)用C#直接编写GLSL程序
CSharpGL(11)用C#直接编写GLSL程序 +BIT祝威+悄悄在此留下版了个权的信息说: 2016-08-13 由于CSharpGL一直在更新,现在这个教程已经不适用最新的代码了.CSharp ...
- ABP框架实践基础篇之开发UI层
返回总目录<一步一步使用ABP框架搭建正式项目系列教程> 说明 其实最开始写的,就是这个ABP框架实践基础篇.在写这篇博客之前,又回头复习了一下ABP框架的理论,如果你还没学习,请查看AB ...
- Entity Framework 6 Recipes 2nd Edition(11-2)译 -> 用”模型定义”函数过滤实体集
11-2. 用”模型定义”函数过滤实体集 问题 想要创建一个”模型定义”函数来过滤一个实体集 解决方案 假设我们已有一个客户(Customer)和票据Invoice)模型,如Figure 11-2所示 ...
- exportfs 入门/ 错误
exportfs -uv 不能卸载, exportfs -au 才可以 ================================================================ ...
- JSP页面跳转的几种实现方法
使用href超链接标记 客户端跳转 使用JavaScript 客户端跳转 提交表单 客户端跳转 使用response ...
- SQL Server-聚焦过滤索引提高查询性能(十)
前言 这一节我们还是继续讲讲索引知识,前面我们讲了聚集索引.非聚集索引以及覆盖索引等,在这其中还有一个过滤索引,通过索引过滤我们也能提高查询性能,简短的内容,深入的理解,Always to revie ...
- 计算机程序的思维逻辑 (8) - char的真正含义
看似简单的char 通过前两节,我们应该对字符和文本的编码和乱码有了一个清晰的认识,但前两节都是与编程语言无关的,我们还是不知道怎么在程序中处理字符和文本. 本节讨论在Java中进行字符处理的基础 - ...
- Handler系列之使用
作为一个Android开发者,我们肯定熟悉并使用过Handler机制.最常用的使用场景是"在子线程更新ui",实际上我们知道上面的说话是错误的.因为Android中只有主线程才能更 ...