Zookeeper与Kafka集群搭建
一 :环境准备:
- 物理机window7 64位
- vmware 3个虚拟机 centos6.8 IP为:192.168.17.[129 -131]
- JDK1.7安装配置
- 各虚拟机之间配置免密登录
- 安装clustershell用于集群各节点统一操作配置
1 :在此说明一下免密和clustershell的操作和使用方式
1.1 :配置免密登录(各集群节点间,互相操作对方时,只需要输入对方ip或者host即可,不需要输入密码,即:免密登录)
1.1.2 :生成密钥文件和私钥文件 命令
ssh-keygen -t rsa
1.1.3 :查看生成秘钥文件
ls /root/.ssh
1.1.4 : 将秘钥拷贝到对方机器
ssh-copy-id -i /root/.ssh/id_rsa.pub 192.168.17.129
ssh-copy-id -i /root/.ssh/id_rsa.pub 192.168.17.130
ssh-copy-id -i /root/.ssh/id_rsa.pub 192.168.17.131
1.1.5 :测试互相是否连接上
可以分别在不同节点间互相登录操作一下
ssh root@192.168.17.130
hostname
1.2 : clustershell的安装
备注一下,我是安装的centos6.6 mini无界面版本,通过yun install clustershell安装时,会提示no package ,原因yum源中的包长期没有更新,所以使用来epel-release
安装命令:
sudo yum install epel-release
然后在yum install clustershell 就可以通过epel来安装了
1.2.2 : 配置cluster groups
vim /etc/clustershell/groups
添加一个组名:服务器IP或者host
kafka:192.168.17.129 192.168.17.130 192.168.17.131
二 :Zookeeper和Kafka下载
本文使用的zookeeper和kafka版本分别为:3.4.8 , 0.10.0.0
1 :首先到官网进行下载:
将压缩包放在自己指定的目录下,我这里放在了/opt/kafka 目录下
然后,通过clush 将压缩包copy到其它几个服务节点中
clush -g kafka -c /opt/kafka
2 :通过clush来解压缩所有节点的zk和kafka压缩包
clush -g kafka tar zxvf /opt/kafka/zookeeper-3.4.8
clush -g kafka tar zxvf /opt/kafka/kafka_2.11-0.10.1.0
3 : 将zoo_sample.cfg 拷贝一份为zoo.cfg (默认的zookeeper配置文件)
修改配置,zoo.cfg文件
# The number of milliseconds of each tick
tickTime=
# The number of ticks that the initial
# synchronization phase can take
initLimit=
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/tmp/zookeeper
# the port at which the clients will connect
clientPort= ## zk 默认端口 ## 节点IP和端口
server.=192.168.17.129::
server.=192.168.17.130::
server.=192.168.17.131:: # the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=
# Purge task interval in hours
# Set to "" to disable auto purge feature
#autopurge.purgeInterval=
3 : 创建tmp/zookeeper 用来存储zk信息
mkdir /tmp/zookeeper
4 : 为每个tmp/zookeeper 设置一个myid的文件,内容为节点id 1 or 2 or 3
echo "1" > myid
clush -g kafka "service iptables status"clush -g kafka "service iptables stop"
clush -g kafka /opt/kafka/zookeeper/bin/zkServer.sh start /opt/kafka/zookeeper/conf/zoo.cfg
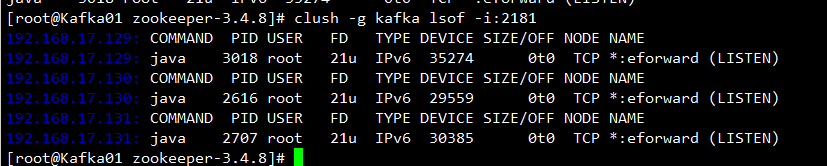
clush -g kafka lsof -i:2181
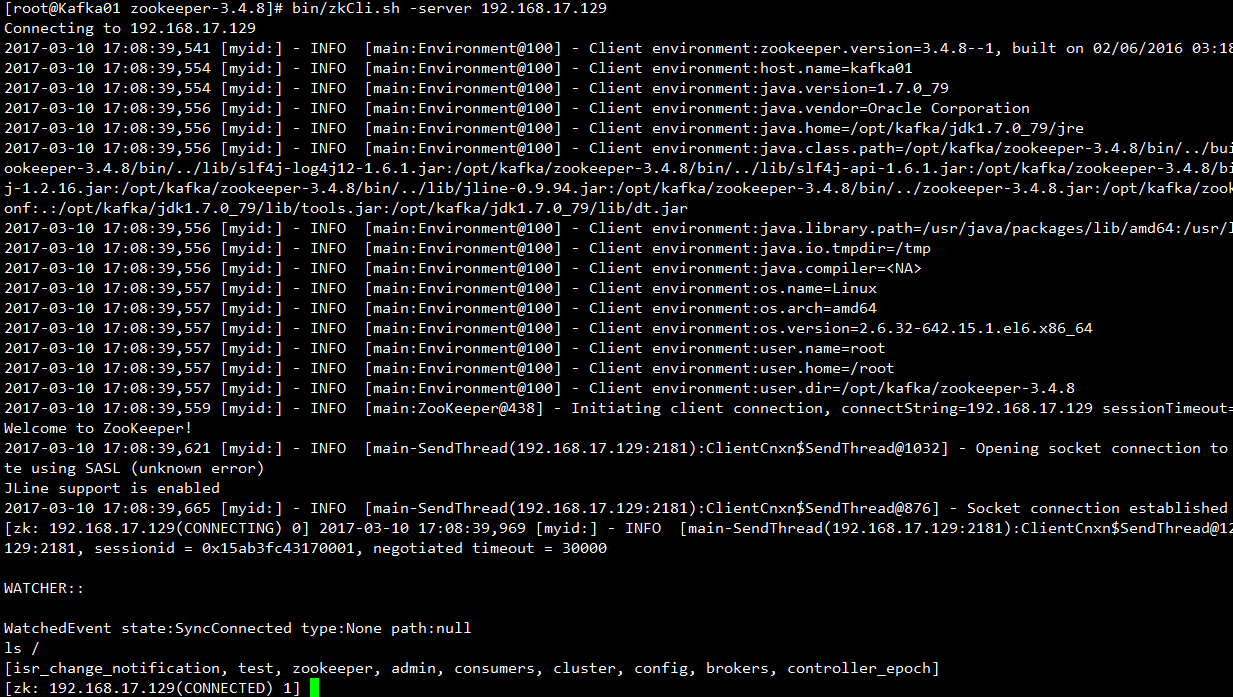
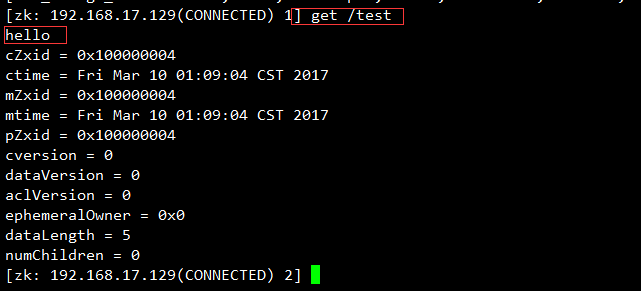
bin/zkCli.sh -server 192.168.17.130:2181create /test hello
三 :Kafka安装部署
zookeeper.connect=192.168.17.129:2181,192.168.17.130:2181,192.168.17.131:2181
/opt/kafka/kafka_2.11-0.10.1.0/bin/kafka-server-start.sh -daemon /opt/kafka/kafka_2.11-0.10.1.0/config/server.properties
bin/kafka-topics.sh --zookeeper 192.168.17.129:2181 -topic topicTest --create --partition 3 --replication-factor 2
[root@Kafka01 kafka_2.11-0.10.1.0]# bin/kafka-topics.sh --zookeeper 192.168.17.129:2181 -topic topicTest --describe

bin/kafka-console-consumer.sh --zookeeper 192.168.17.130:2181 --topic topicTest
bin/kafka-console-producer.sh --broker-list kafka02:9092 --topic topicTest



Zookeeper与Kafka集群搭建的更多相关文章
- zookeeper及kafka集群搭建
zookeeper及kafka集群搭建 1.有关zookeeper的介绍可参考:http://www.cnblogs.com/wuxl360/p/5817471.html 2.zookeeper安装 ...
- zookeeper与Kafka集群搭建及python代码测试
Kafka初识 1.Kafka使用背景 在我们大量使用分布式数据库.分布式计算集群的时候,是否会遇到这样的一些问题: 我们想分析下用户行为(pageviews),以便我们设计出更好的广告位 我想对用户 ...
- CentOS 7 Zookeeper 和 Kafka 集群搭建
环境 CentOS 7.4 Zookeeper-3.6.1 Kafka_2.13-2.4.1 Kafka-manager-2.0.0.2 本次安装的软件全部在 /home/javateam 目录下. ...
- Zookeeper + Kafka 集群搭建
第一步:准备 1. 操作系统 CentOS-7-x86_64-Everything-1511 2. 安装包 kafka_2.12-0.10.2.0.tgz zookeeper-3.4.9.tar.gz ...
- 搭建zookeeper和Kafka集群
搭建zookeeper和Kafka集群: 本实验拥有3个节点,均为CentOS 7系统,分别对应IP为10.211.55.11.10.211.55.13.10.211.55.14,且均有相同用户名 ( ...
- Docker快速搭建Zookeeper和kafka集群
使用Docker快速搭建Zookeeper和kafka集群 镜像选择 Zookeeper和Kafka集群分别运行在不同的容器中zookeeper官方镜像,版本3.4kafka采用wurstmeiste ...
- 使用Docker快速搭建Zookeeper和kafka集群
使用Docker快速搭建Zookeeper和kafka集群 镜像选择 Zookeeper和Kafka集群分别运行在不同的容器中zookeeper官方镜像,版本3.4kafka采用wurstmeiste ...
- CentOS 7搭建Zookeeper和Kafka集群
环境 CentOS 7.4 Zookeeper-3.6.1 Kafka_2.13-2.4.1 Kafka-manager-2.0.0.2 本次安装的软件全部在 /home/javateam 目录下. ...
- zookeeper集群及kafka集群搭建
1.zookeeper集群搭建 1.1 上传安装包 官网推荐至少3个节点,我们这里也用三个节点192.169.2.18 192.169.1.82 192.169.1.95 准备好安装包,zooke ...
随机推荐
- thinkphp 3.2 模型的使用示例
原来以为thinkPHP的 model 就和PHPCMS一样 就起到一个连接数据库的作用,今天看了视频,才发现这个也是 mvc中的m 使用方法可以使用 D() 方法 下面是 UserControll ...
- Linux笔记(五) - 用户管理命令
(1)添加用户:useradd [选项] 用户 -u UID:手工指定用户的UID号-d 家目录:手工指定用户的家目录-c 用户说明:手工指定用户说明,有空格需加双引号-g 初始组:手工指定初始组-G ...
- Bootstrap入门(十三)组件7:导航条
Bootstrap入门(十三)组件7:导航条 1.默认样式的导航条 2.嵌入表单和按钮 3.嵌入文本和非导航的链接 4.组件排列和下拉菜单 5.固定在顶部/底部 6.反色的导航条 7.路径导航 首先先 ...
- CMD修改IP地址
在操作系统下,我们可以使用"本地连接"的属性来修改IP地址,但是如果我们要在多个IP地址之间切换,使用这种方法未免过于麻烦.我们可以使用NETSH命令来添加,相当简便.使用DOS修 ...
- 私有云存储搭建(owncloud)
第一步.搭建LAMP(基于linux7.1.1503) 1 配置yum(网络加本地,下面为网络) [vault.centos.org_7.1.1503_os_x86_64_] name=added f ...
- leetcode刷题总结
题外话 今年大三,现正值寒假时间,开学就开始大三下学期的生活了. 在大三临近结束的时间,也就是复习考试的时间里,我每天都会用早上的时间来刷codewars.刚开始玩的时候,一到8kyu的题目如果稍微难 ...
- 在C++中反射调用.NET(一)
为什么要在C++中调用.NET 一般情况下,我们常常会在.NET程序中调用C/C++的程序,使用P/Invoke方式进行调用,在编写代码代码的时候,首先要导入DLL文件,然后在根据C/C++的头文件编 ...
- Picasso 修改缓存路径
Picasso 是 Square 公司开源的一个非常友好的图片加载框架,使用范围也比较广泛.具体的使用这里就不做介绍了,文章主要讲讲如何修改图片的缓存路径.Picasso默认的缓存路径位于data/d ...
- matlab中使用elseif和if嵌套的对比
% 目标: % 判定成绩等级 %定义变量 % 输入:分数grade %清除变量或指令 clc; % 允许用户输入参数 disp ('该功能练习if语句'); disp ('输入你的成绩,系统将判定等级 ...
- hadoop2.5.2安装部署
0x00 说明 此处已经省略基本配置步骤参考Hadoop1.0.3环境搭建流程,省略主要步骤有: 建立一般用户 关闭防火墙和SELinux 网络配置 0x01 配置master免密钥登录slave 生 ...