OCR技术浅探: 语言模型(4)
由于图像质量等原因,性能再好的识别模型,都会有识别错误的可能性,为了减少识别错误率,可以将识别问题跟统计语言模型结合起来,通过动态规划的方法给出最优的识别结果。这是改进OCR识别效果的重要方法之一。
转移概率
在我们分析实验结果的过程中,有出现这一案例。由于图像不清晰等可能的原因,导致“电视”一词被识别为“电柳”,仅用图像模型是不能很好地解决这个问题的,因为从图像模型来看,识别为“电柳”是最优的选择。但是语言模型却可以很巧妙地解决这个问题。原因很简单,基于大量的文本数据我们可以统计“电视”一词和“电柳”一词的概率,可以发现“电视”一词的概率远远大于“电柳”,因此我们会认为这个词是“电视”而不是“电柳”。
从概率的角度来看,就是对于第一个字的区域的识别结果s1,我们前面的卷积神经网络给出了“电”、“宙”两个候选字(仅仅选了前两个,后面的概率太小),每个候选字的概率W(s1)分别为0.99996、0.00004;第二个字的区域的识别结果s2,我们前面的卷积神经网络给出了“柳”、“视”、“规”(仅仅选了前三个,后面的概率太小),每个候选字的概率W(s2)分别为0.87838、0.12148、0.00012,因此,它们事实上有六种组合:“电柳”、“电视”、“电规”、“宙柳”、“宙视”、“宙规”。
下面考虑它们的迁移概率。所谓迁移概率,其实就是条件概率P(s1|s2),即当s1出现时后面接s2的概率。通过10万微信文本,我们统计出,“电”字出现的次数为145001,而“电柳”、“电视“、”电规“出现的次数为0、12426、7;“宙”字出现的次数为1980次,而“宙柳”、“宙视”、“宙规”出现的次数为0、0、18,因此,可以算出

结果如下图:
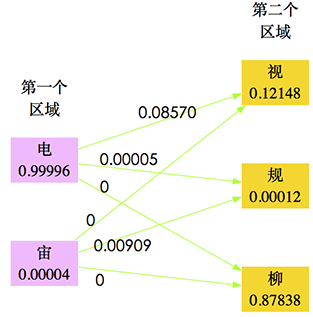
图20 考虑转移概率
从统计的角度来看,最优的s1,s2组合,应该使得式(14)取最大值:
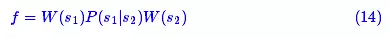
因此,可以算得s1,s2的最佳组合应该是“电视”而不是“电柳”。这时我们成功地通过统计的方法得到了正确结果,从而提高了正确率。
动态规划
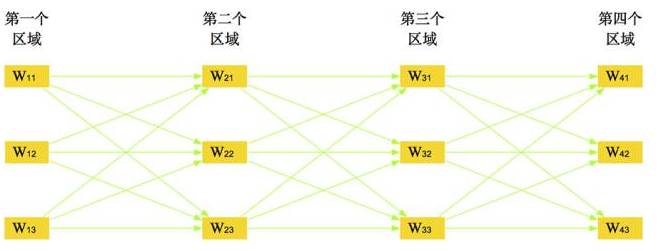
图21 多字图片的规划问题
类似地,如图21,如果一个单行文字图片有n个字 需要确定,那么应当使得
需要确定,那么应当使得
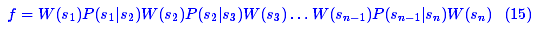
取得最大值,这就是统计语言模型的思想,自然语言处理的很多领域,比如中文分词、语音识别、图像识别等,都用到了同样的方法[6]。这里需要解决两个主要的问题:(1)各个 的估计;(2)给定各个
的估计;(2)给定各个 后如何求解f的最大值。
后如何求解f的最大值。
转移概率矩阵
对于第一个问题,只需要从大的语料库中统计si的出现次数#si,以及si,si+1相接地出现的次数#(si,si+1),然后认为

即可,本质上没有什么困难。本文的识别对象有3062个,理论上来说,应该生成一个3062×3062的矩阵,这是非常庞大的。当然,这个矩阵是非常稀疏的,我们可以只保存那些有价值的元素。
现在要着重考虑当#(si,si+1)=0的情况。在前一节我们就直接当P(si|si+1)=0,但事实上是不合理的。没有出现不能说明不会出现,只能说明概率很小,因此,即便是对于#(si,si+1)=0,也应该赋予一个小概率而不是0。这在统计上称为数据的平滑问题。
一个简单的平滑方法是在所有项的频数(包括频数为0的项)后面都加上一个正的小常数α(比如1),然后重新统计总数并计算频率,这样每个项目都得到了一个正的概率。这种思路有可能降低高频数的项的概率,但由于这里的概率只具有相对意义,因此这个影响是不明显的(一个更合理的思路是当频数小于某个阈值T时才加上常数,其他不加。)。按照这种思路,从数十万微信文章中,我们计算得到了160万的邻接汉字的转移概率矩阵。
Viterbi算法
对于第二个问题,求解最优组合 是属于动态规划中求最优路径的问题,其中最有效的方法是Viterbi算法[6]。
是属于动态规划中求最优路径的问题,其中最有效的方法是Viterbi算法[6]。
Viterbi算法是一个简单高效的算法,用Python实现也就十来行的代码。它的核心思想是:如果最终的最优路径经过某个si−1,那么从初始节点到si−1点的路径必然也是一个最优路径——因为每一个节点si只会影响前后两个P(si−1|si)和P(si|si+1)。
根据这个思想,可以通过递推的方法,在考虑每个si时只需要求出所有经过各si−1的候选点的最优路径,然后再与当前的si结合比较。这样每步只需要算不超过 次,就可以逐步找出最优路径。Viterbi算法的效率是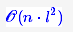 ,l 是候选数目最多的节点si的候选数目,它正比于n,这是非常高效率的。
,l 是候选数目最多的节点si的候选数目,它正比于n,这是非常高效率的。
提升效果
实验表明,结合统计语言模型进行动态规划能够很好地解决部分形近字识别错误的情况。在我们的测试中,它能修正一些错误如下:

通过统计语言模型的动态规划能修正不少识别错误
由于用来生成转移矩阵的语料库不够大,因此修正的效果还有很大的提升空间。不管怎么说,由于Viterbi算法的简单高效,这是一个性价比很高的步骤。
OCR技术浅探: 语言模型(4)的更多相关文章
- OCR技术浅探:基于深度学习和语言模型的印刷文字OCR系统
作者: 苏剑林 系列博文: 科学空间 OCR技术浅探:1. 全文简述 OCR技术浅探:2. 背景与假设 OCR技术浅探:3. 特征提取(1) OCR技术浅探:3. 特征提取(2) OCR技术浅探:4. ...
- OCR技术浅探(转)
网址:https://spaces.ac.cn/archives/3785 OCR技术浅探 作为OCR系统的第一步,特征提取是希望找出图像中候选的文字区域特征,以便我们在第二步进行文字定位和第三步进行 ...
- OCR技术浅探:特征提取(1)
研究背景 关于光学字符识别(Optical Character Recognition, 下面都简称OCR),是指将图像上的文字转化为计算机可编辑的文字内容,众多的研究人员对相关的技术研究已久,也有不 ...
- OCR技术浅探: 语言模型和综合评估(4)
语言模型 由于图像质量等原因,性能再好的识别模型,都会有识别错误的可能性,为了减少识别错误率,可以将识别问题跟统计语言模型结合起来,通过动态规划的方法给出最优的识别结果.这是改进OCR识别效果的重要方 ...
- OCR技术浅探:Python示例(5)
文件说明: 1. image.py——图像处理函数,主要是特征提取: 2. model_training.py——训练CNN单字识别模型(需要较高性能的服务器,最好有GPU加速,否则真是慢得要死): ...
- OCR技术浅探: 光学识别(3)
经过前面的文字定位和文本切割,我们已经能够找出图像中单个文字的区域,接下来可以建立相应的模型对单字进行识别. 模型选择 在模型方面,我们选择了深度学习中的卷积神经网络模型,通过多层卷积神经网络,构建了 ...
- OCR技术浅探 : 文字定位和文本切割(2)
文字定位 经过前面的特征提取,我们已经较好地提取了图像的文本特征,下面进行文字定位. 主要过程分两步: 1.邻近搜索,目的是圈出单行文字: 2.文本切割,目的是将单行文本切割为单字. 邻近搜索 我们可 ...
- OCR技术浅析-无代码篇(1)
图像识别中最贴近我们生活的可能就是 OCR 技术了. OCR 的定义:OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打 ...
- font and face, 浅探Emacs字体选择机制及部分记录
缘起 最近因为仰慕org-mode,从vim迁移到了Emacs.偶然发现org-mode中调出的calendar第一行居然没有对齐,排查一下发现是字体的问题.刚好也想改改Emacs的字体,于是我就开始 ...
随机推荐
- java中堆和堆栈的区别
java中堆和堆栈的区别(一) 1.栈(stack)与堆(heap)都是Java用来在Ram中存放数据的地方.与C++不同,Java自动管理栈和堆,程序员不能直接地设置栈或堆. 2. 栈的优势是,存取 ...
- PHP header使用
header()函数的作用是:发送一个原始 HTTP 标头[Http Header]到客户端.标头 (header) 是服务器以 HTTP 协义传 HTML 资料到浏览器前所送出的字串,在标头与 HT ...
- 顽强的的砂锅之——深究finally代码块与return语句的执行顺序!
当问到finally代码块的执行顺序,就算刚刚学编程的小白都能毫不犹豫的说出答案:不管异常发生与否,finally语句块的代码一定会被执行!大体上这样讲是没有错,但是finally块中的代码一定会有效 ...
- Photoshop 画基本图形
作者:zccst 1,画三角形 按下“U”选择“多边形工具”(是个六边形的图标),在上方的菜单栏中的“边”后面输入“3”,然后在画布中拖动就是三角形了,画好后按下CTRL+ENTER键转化成选区,然后 ...
- @synthesize和@dynamic
@synthesize 除非开发人员已经做了,否则由编译器自动生成getter/setter方法.当开发人员自定义存或取方法时,自定义会屏蔽自动生成该方法. @dynamic 告诉编译器,不自动生成g ...
- python threading模块中对于信号的抓取
最近的物联网智能网关(树莓派)项目中遇到这样一个问题:要从多个底层串口读取发来的数据,并且做出相应的处理,对于每个串口的数据的读取我能想到的可以采用两种方式: 一种是采用轮询串口的方式,例如每3s向每 ...
- PHP利用数组构造JSON
问题起因 以往都是直接用构造数组的形式构造json 例子: $arr = array("A"=>"1","B"=>"2 ...
- UVa 11450 - Wedding shopping
题目大意:我们的朋友Bob要结婚了,所以要为他买一些衣服.有m的资金预算,要买c种类型的衣服(衬衫.裤子等),而每种类型的衣服有k个选择(只能做出一个选择),每个选择的衣服都有一个价格,问如何选择才能 ...
- SVN和Git的一些用法总结
(A)SVN (1)查看日志提交的时候一般会写上注释,如果要查看提交日志,用以下命令: 1 svn log -l 4 其中,-l 4表示只查看最近4条日志(也可以没有这样的参数,就表示查看所有日志). ...
- IM 融云 之 安装cocoapods 安装 SDK
1. podfile 内容如下: platform :ios, '7.0' pod 'RongCloudIMKitWithVoip', '2.4.3' 现在最新是2.4.3 导入之后,就直接可以用了. ...