python 学习之爬虫练习
通过学习python,写两个简单的爬虫,没用线程,本地抓取速度还不错,有些瑕疵就是抓的图片有些显示不出来,代码做个笔记记录下:
# -*- coding:utf-8 -*- import re
import urllib.request
import os url = "http://www.58pic.com/yuanchuang/0/day-" def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read().decode('gbk')
return html def getImg(html,num):
reg = r'src="(.*?)" '
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
x = 0
os.mkdir(r"G:\collect/%d" % num)
filePath = r"G:\collect/%d/" % num
for imgurl in imglist:
f=open(filePath+str(x)+".jpg",'wb')
req=urllib.request.urlopen(imgurl)
buf=req.read()
f.write(buf)
x+=1 for i in range(1,10):
getUrl = url+"%d.html" % i
print(getUrl)
html = getHtml(getUrl)
#print(html)
print(getImg(html,i))
最终的结果如下图:
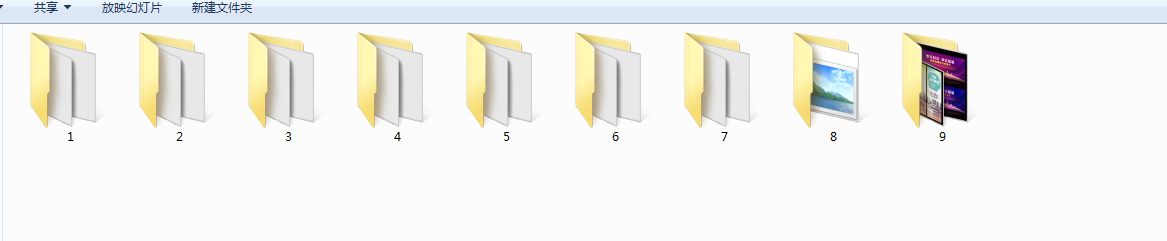
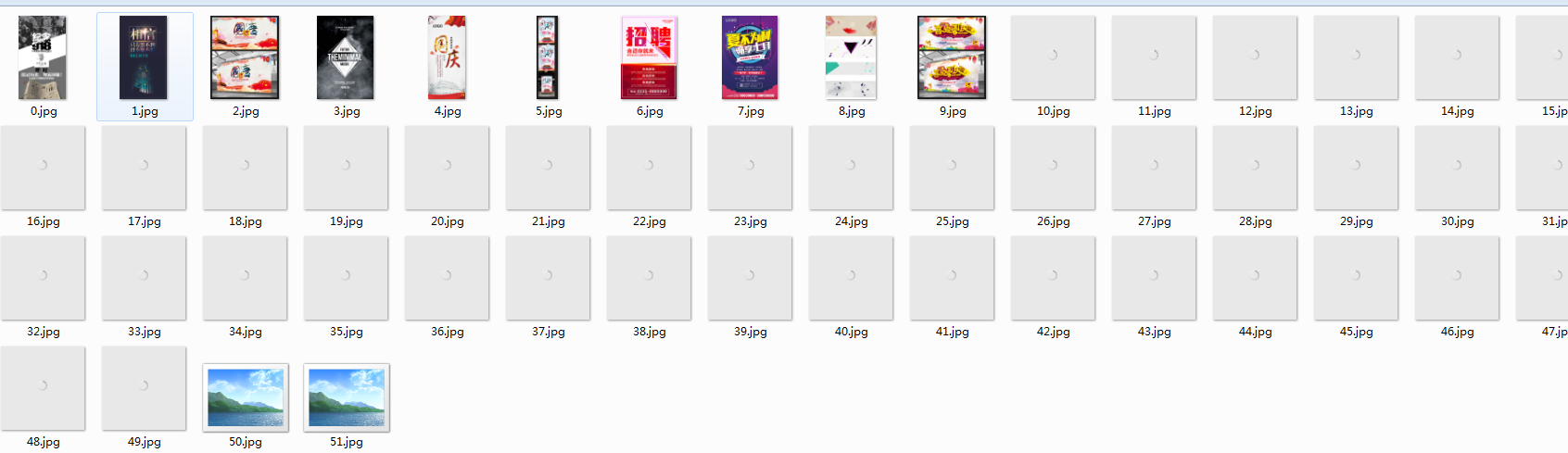
根据上面的初步代码,优化后加强版的爬虫代码,对于链接的状态异常的抛出异常后在继续执行程序。代码如下:
# -*- coding:utf-8 -*- import re
import urllib.request
import os url = "http://www.58pic.com/psd/" def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read().decode('gbk')
return html def getImg(html,num):
reg = r'src="(.+?\.jpg)" class="show-area-pic" id="show-area-pic" alt="(.*?)"'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
print(imglist)
filePath = r"F:\Py/collect/%d/" % num
isCreate = os.path.exists(filePath)
if isCreate == False :
os.mkdir(r"F:\Py/collect/%d" % num)
for img in imglist:
title = img[1]
f=open(filePath+title+".jpg",'wb')
req=urllib.request.urlopen(img[0])
buf=req.read()
f.write(buf) for i in range(22797263,22797666):
getUrl = url+"%d.html" % i
#status = urllib.request.urlopen(getUrl).code
try:
html = getHtml(getUrl)
#print(html)
getImg(html,i)
except urllib.request.URLError as e:
print(e.code)
print(e.reason)
python 学习之爬虫练习的更多相关文章
- Python学习网络爬虫--转
原文地址:https://github.com/lining0806/PythonSpiderNotes Python学习网络爬虫主要分3个大的版块:抓取,分析,存储 另外,比较常用的爬虫框架Scra ...
- python学习之爬虫(一) ——————爬取网易云歌词
接触python也有一段时间了,一提到python,可能大部分pythoner都会想到爬虫,没错,今天我们的话题就是爬虫!作为一个小学生,关于爬虫其实本人也只是略懂,怀着"Done is b ...
- 【Python学习】爬虫报错处理bs4.FeatureNotFound
[BUG回顾] 在学习Python爬虫时,运Pycharm中的文件出现了这样的报错: bs4.FeatureNotFound: Couldn’t find a tree builder with th ...
- python学习之爬虫初体验
作业来源: "https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/2851" ** 1.简述爬虫原理 通用爬虫 即(搜索 ...
- python学习笔记——爬虫学习中的重要库urllib
1 urllib概述 1.1 urllib库中的模块类型 urllib是python内置的http请求库 其提供了如下功能: (1)error 异常处理模块 (2)parse url解析模块 (3)r ...
- python学习笔记——爬虫中提取网页中的信息
1 数据类型 网页中的数据类型可分为结构化数据.半结构化数据.非结构化数据三种 1.1 结构化数据 常见的是MySQL,表现为二维形式的数据 1.2 半结构化数据 是结构化数据的一种形式,并不符合关系 ...
- Python学习---网页爬虫[下载图片]
爬虫学习--下载图片 1.主要用到了urllib和re库 2.利用urllib.urlopen()函数获得页面源代码 3.利用正则匹配图片类型,当然正则越准确,下载的越多 4.利用urllib.url ...
- Python学习 之 爬虫
目标:下载贴吧或空间中所有图片 步骤:(1)获取页面代码 (2)获取图片URL,下载图片 代码如下: #!/usr/bin/python import re import urllib def get ...
- python学习笔记——爬虫的抓取策略
1 深度优先算法 2 广度/宽度优先策略 3 完全二叉树遍历结果 深度优先遍历的结果:[1, 3, 5, 7, 9, 4, 12, 11, 2, 6, 14, 13, 8, 10] 广度优先遍历的结果 ...
随机推荐
- C#控制条码打印机 纸张大小,间距,绘制内容(所有条码打印机通用)
其他条码知识 请访问:http://www.ybtiaoma.com ,本文仅供参考,请勿转载,谢谢 using System; using System.Drawing; using System. ...
- (原)ubuntu上安装nvidia及torch的nccl
转载请注明出处: http://www.cnblogs.com/darkknightzh/p/5717234.html 参考网址: https://github.com/NVIDIA/nccl htt ...
- HTML5 canvas 在线画笔绘图工具(二)
Canvas+Javascript 带图标的工具条制作 TToolbar 工具条是由一个TToolbar对象和两个按钮对象(TImageButton.TColorButton)组成,因为之前我大部分时 ...
- [c language] getopt 其参数optind 及其main(int argc, char **argv) 参数解释
getopt被用来解析命令行选项参数.#include <unistd.h> extern char *optarg; //选项的参数指针extern int optind, //下一次调 ...
- python运维开发(二十)----models操作、中间件、缓存、信号、分页
内容目录 select Form标签数据库操作 models操作F/Q models多对多表操作 Django中间件 缓存 信号 分页 select Form标签补充 在上一节中我们可以知道Form标 ...
- css制作简单下拉菜单
要点:定位,隐藏,显示. (一)先建一个两次列表 <ul id="ul1"> <li>首页</li> <li>第二页 <ul& ...
- VS2005快捷键
VS2005快捷键 CTRL + SHIFT + B生成解决方案 CTRL + F7 生成编译 CTRL + O 打开文件 CTRL + SHIFT + O打开项目 CTRL + SHIFT + C显 ...
- 在Qt中怎样显示ASCII码大于127的字符
前段时间要显示“≤”符号找了挺久没找到方法,后面发现用以下方法可以解决: ushort gd[]={8805,0}; QString gteq=QString::fromUtf16(gd); 得 ...
- 扩展ArcGIS API for Silverlight/WPF 中的TextSymbol支持角度标注
原文 http://blog.csdn.net/esricd/article/details/7587136 在ArcGIS API for Silverlight/WPF中原版的TextSymbol ...
- C#中Split分隔字符串的应用(C#、split、分隔、字符串)
转载地址 .用字符串分隔: using System.Text.RegularExpressions; string str="aaajsbbbjsccc"; string[] s ...