Python之路Day5
一、时间复杂度
(1)时间频度:
一个算法花费的时间与算法中语句的执行次数成正比例,哪个算法中语句执行次数多,它花费的时间就多。一个算法中的语句执行次数称为语句频度或时间频度,记为T(n)。
(2)时间复杂度:
在上面提到的时间频度中,n称为问题的规模,当n不断变化时,时间频度T(n)也会不断变化。但有时我们想知道它变化时呈现什么规律。为此,我们引入时间复杂度概念。 一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数,用T(n)表示,若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n)/f(n)的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n)),称O(f(n)) 为算法的渐进时间复杂度,简称时间复杂度。
(3)指数时间:
 而呈指数成长(即输入数据的数量依线性成长,所花的时间将会以指数成长) 比如:嵌套的for循环
而呈指数成长(即输入数据的数量依线性成长,所花的时间将会以指数成长) 比如:嵌套的for循环(4)常数时间:
若对于一个算法, 的上界与输入大小无关,则称其具有常数时间,记作
的上界与输入大小无关,则称其具有常数时间,记作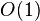 时间。一个例子是访问数组中的单个元素,因为访问它只需要一条指令。但是,找到无序数组中的最小元素则不是,因为这需要遍历所有元素来找出最小值。这是一项线性时间的操作,或称
时间。一个例子是访问数组中的单个元素,因为访问它只需要一条指令。但是,找到无序数组中的最小元素则不是,因为这需要遍历所有元素来找出最小值。这是一项线性时间的操作,或称 时间。但如果预先知道元素的数量并假设数量保持不变,则该操作也可被称为具有常数时间。
时间。但如果预先知道元素的数量并假设数量保持不变,则该操作也可被称为具有常数时间。
(5)对数时间:
若算法的T(n) = O(log n),则称其具有对数时间
对数时间的算法是非常有效的,因为每增加一个输入,其所需要的额外计算时间会变小。
递归地将字符串砍半并且输出是这个类别函数的一个简单例子。它需要O(log n)的时间因为每次输出之前我们都将字符串砍半。 这意味着,如果我们想增加输出的次数,我们需要将字符串长度加倍。
(6)线性时间:
如果一个算法的时间复杂度为O(n),则称这个算法具有线性时间,或O(n)时间。非正式地说,这意味着对于足够大的输入,运行时间增加的大小与输入成线性关系。例如,一个计算列表所有元素的和的程序,需要的时间与列表的长度成正比。
二、模块
1.time和datetime模块
import time
import datetime
# time模块
print(time.clock()) # 输出=>3.110193534902903e-07
print(time.process_time()) # 输出=>0.031200199999999997
# 返回当前时间戳,即1970.1.1至今的秒数
print(time.time()) # 输出=>1454239454.328046
# 当前系统时间
print(time.ctime()) # 输出=>Sun Jan 31 19:24:14 2016
# 将当前时间戳转换成字符串格式的时间
print(time.ctime(time.time())) # 输出=>Sun Jan 31 19:24:14 2016
# 将时间戳转换成struct_time格式
print(time.gmtime(time.time()))
# time.struct_time(tm_year=2016, tm_mon=1, tm_mday=31, tm_hour=11, tm_min=24, tm_sec=14, tm_wday=6, tm_yday=31, tm_isdst=0)
# 将本地时间的时间戳转换成struct_time格式
print(time.localtime(time.time()))
# time.struct_time(tm_year=2016, tm_mon=1, tm_mday=31, tm_hour=19, tm_min=24, tm_sec=14, tm_wday=6, tm_yday=31, tm_isdst=0)
# 与上面的相反,将struct_time格式转回成时间戳格式。
print(time.mktime(time.localtime())) # 输出=>1454239454.0
# sleep
# time.sleep(4)
# 将struct_time格式转成指定的字符串格式
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time.time()))) # 输出=>2016-02-01 13:53:22
# 将字符串格式转成struct_time格式
print(time.strptime("2016-02-01", "%Y-%m-%d"))
# time.struct_time(tm_year=2016, tm_mon=2, tm_mday=1, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=0, tm_yday=32, tm_isdst=-1)
# datetime 模块
print(datetime.date.today()) # 输出=>2016-02-01
print(datetime.date.fromtimestamp(time.time() - 86640)) # 输出=>2016-01-31
current_time = datetime.datetime.now()
print(current_time) # 输出=>2016-02-01 14:01:02.428880
# 返回struct_time格式的时间
print(current_time.timetuple())
# time.struct_time(tm_year=2016, tm_mon=2, tm_mday=1, tm_hour=14, tm_min=1, tm_sec=41, tm_wday=0, tm_yday=32, tm_isdst=-1)
# 指定替换
# datetime.replace([year[, month[, day[, hour[, minute[, second[, microsecond[, tzinfo]]]]]]]])
print(current_time.replace(2008, 8, 8)) # 输出=>2008-08-08 14:03:53.901093
# 将字符串转换成日期格式
str_to_date = datetime.datetime.strptime("2016-02-01", "%Y-%m-%d")
print(str_to_date) # 输出=>2016-02-01 00:00:00
# 比现在+10d
new_date = datetime.datetime.now() + datetime.timedelta(days=10)
print(new_date) # 输出=>2016-02-11 14:46:49.158138
# 比现在-10d
new_date = datetime.datetime.now() - datetime.timedelta(days=10)
print(new_date) # 输出=>2016-01-22 14:53:03.712109
# 比现在+10h
new_date = datetime.datetime.now() + datetime.timedelta(hours=10)
print(new_date) # 输出=>2016-02-02 00:53:03.712109
# 比现在+120s
new_date = datetime.datetime.now() + datetime.timedelta(seconds=120)
print(new_date) # 输出=>2016-02-01 14:55:03.712109
2.random模块
import random
print(random.random()) # 输出=>0.10518206284945941
# 包含边界
print(random.randint(1, 3)) # 输出=>2
# 不包含边界
print(random.randrange(1, 3)) # 输出=>1
# 生成4位随机验证码
check_code = ""
for i in range(4):
current = random.randrange(0, 4)
if current != i:
temp = chr(random.randint(97, 122))
else:
temp = random.randint(0, 9)
check_code = "{}{}".format(check_code, temp)
print(check_code) # 输出=>oovf
3.sys模块
import sys
# 返回命令函参数的list,第一个元素是程序本身
# sys.argv
# 退出程序,并打印括号内的内容,正常退出时exit(0)
# sys.exit(0)
# 获取Python解释器的版本信息
print(sys.version) # 输出=>3.5.0 (v3.5.0:374f501f4567, Sep 13 2015, 02:27:37) [MSC v.1900 64 bit (AMD64)]
# 返回支持的最大数值
print(sys.maxsize) # 输出=>9223372036854775807
# 返回模块的搜索路径
print(sys.path) # 输出=>['D:\\qimi_WorkSpace\\S12\\day5', 'D:\\qimi_WorkSpace', ...]
# 返回操作系统平台名称
print(sys.platform) # 输出=>win32
# 标准输出
sys.stdout.write('Please:')
# 标准输入
val = sys.stdin.readline()[-1] # [-1]的作用是去掉输入时的回车
# 打印进度条...
import time
for i in range(10):
sys.stdout.write("#")
sys.stdout.flush()
time.sleep(0.5)
4.os模块
import os
# os模块,提供对操作系统进行调用的接口
# 获取当前的工作目录
print(os.getcwd())
# 改变当前脚本的工作目录
os.chdir("D:\qimi_WorkSpace\S12\day5")
# 返回当前目录的字符串名
print(os.curdir) # 输出=>.
# 返回当前目录的父目录字符串名
print(os.pardir) # 输出=>..
# 生成多层目录
# os.makedirs("D:\qimi_WorkSpace\S12\day5\dirname1\dirname2")
# 生成单层目录
# os.mkdir("D:\qimi_WorkSpace\S12\day5\dirname1")
# 删除目录,如果目录为空则递归删除上一级目录
# os.removedirs("D:\qimi_WorkSpace\S12\day5\dirname1\dirname2")
# 删除单层空目录,目录为空无法删除。
# os.rmdir("D:\qimi_WorkSpace\S12\day5\dirname1")
# 列出指定目录下的所有文件盒子目录,包含隐藏文件,并以列表形式打印
os.listdir("D:\qimi_WorkSpace\S12\day5")
# 删除一个文件
# os.remove("文件路径")
# 重命名文件/目录
# os.rename("ordname", "newname")
# 获取文件/目录信息
# os.stat("path/filename")
# 输出当前操作系统下的路径分隔符
print(os.sep) # 输出=>'\\'
# 输出当前操作系统下的行中止符
print(os.linesep) # 输出=>'\t\n'
# 输出当前系统下用于分割文件路径的字符串
print(os.pathsep) # 输出';'
# 输出当前平台
print(os.name)
# 运行shell命令
os.system("dir")
# 获取系统环境变量
print(os.environ)
# 返回path规范化的绝对路径
os.path.abspath("D:\qimi_WorkSpace\S12\day5")
# 将path分割成目录和文件名二元组返回(仅以后面跟不跟\为依据)
os.path.split("D:\qimi_WorkSpace\S12\day5") # 输出=>("D:\qimi_WorkSpace\S12", "day5")
# 返回path的目录
os.path.dirname("D:\qimi_WorkSpace\S12\day5") # 输出=>"D:\qimi_WorkSpace\S12"
# 返回path的文件名
os.path.basename("D:\qimi_WorkSpace\S12\day5") # 输出=>"day5"
# 判断路径是否存在
os.path.exists("D:\qimi_WorkSpace\S12\day5") # 输出=>True
# 判断path是不是绝对路径
os.path.abspath("D:\qimi_WorkSpace\S12\day5") # 输出=>True
# 判断path是不是一个存在的文件
os.path.isfile("D:\qimi_WorkSpace\S12\day5") # 输出=>False
# 判断path是不是一个存在的目录
os.path.isdir("D:\qimi_WorkSpace\S12\day5") # 输出=>True
# 将多个路径组合后返回,第一个绝对路径之前的参数被忽略
os.path.join("D:\qimi_WorkSpace\S12\day5", "day5_1") # 输出=>"D:\qimi_WorkSpace\S12\day5\day5_1"
os.path.join("day5_01", "D:\qimi_WorkSpace\S12\day5", "day5_1") # 输出=>"D:\qimi_WorkSpace\S12\day5\day5_1"
# 返回path指向的文件或者目录的最后存取时间
os.path.getatime("D:\qimi_WorkSpace\S12\day5\day5_1") # 输出=>1454321491.5017765
# 返回path指向的文件或者目录的最后修改时间
os.path.getmtime("D:\qimi_WorkSpace\S12\day5\day5_1") # 输出=>1454321491.5017765
# 返回path指向的文件或者目录的创建时间
os.path.getctime("D:\qimi_WorkSpace\S12\day5") # 输出=>1454164372.8629067
# 返回path指向的文件或者目录的大小
os.path.getsize("D:\qimi_WorkSpace\S12\day5") # 输出=>4096
5.pickle和json模块
pickle是Python独有的,json是普遍支持的。
import pickle
import json
# 四种方法:dump、dumps、load、loads
info = {"name": "alex", "age": 18, "Limit": 10000, "created": "2016-02-01"}
with open("test.txt", "wb") as f:
f.write(pickle.dumps(info))
with open("test.txt", "rb") as p:
# d1 = pickle.loads(p.read())
d1 = pickle.load(p)
for k in d1:
print(k, d1[k])
if d1.get("Limit", 0) > 5000:
print("haha")
# 四种方法:dump、dumps、load、loads
info = {"name": "alex", "age": 18, "Limit": 10000, "created": "2016-02-01"}
#
with open("test2.txt", "w") as f:
json.dump(info, f)
# f.write(json.dumps(info))
with open("test2.txt", "r") as p:
d2 = json.load(p)
for k in d2:
print(k, d2[k])
6.shelve模块
shelve模块是一个简单的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式。
import shelve
d = shelve.open("test3.txt")
# 定义一个测试类
class TestDemo(object):
def __init__(self, n):
self.n = n
t = TestDemo(123)
name = ["alex", "john", "eric"]
d["test1"] = name # 持久化列表
d["test2"] = t # 持久化列表
d.close()
"""Manage shelves of pickled objects.
A "shelf" is a persistent, dictionary-like object. The difference
with dbm databases is that the values (not the keys!) in a shelf can
be essentially arbitrary Python objects -- anything that the "pickle"
module can handle. This includes most class instances, recursive data
types, and objects containing lots of shared sub-objects. The keys
are ordinary strings.
To summarize the interface (key is a string, data is an arbitrary
object):
import shelve
d = shelve.open(filename) # open, with (g)dbm filename -- no suffix
d[key] = data # store data at key (overwrites old data if
# using an existing key)
data = d[key] # retrieve a COPY of the data at key (raise
# KeyError if no such key) -- NOTE that this
# access returns a *copy* of the entry!
del d[key] # delete data stored at key (raises KeyError
# if no such key)
flag = key in d # true if the key exists
list = d.keys() # a list of all existing keys (slow!)
d.close() # close it
Dependent on the implementation, closing a persistent dictionary may
or may not be necessary to flush changes to disk.
Normally, d[key] returns a COPY of the entry. This needs care when
mutable entries are mutated: for example, if d[key] is a list,
d[key].append(anitem)
does NOT modify the entry d[key] itself, as stored in the persistent
mapping -- it only modifies the copy, which is then immediately
discarded, so that the append has NO effect whatsoever. To append an
item to d[key] in a way that will affect the persistent mapping, use:
data = d[key]
data.append(anitem)
d[key] = data
To avoid the problem with mutable entries, you may pass the keyword
argument writeback=True in the call to shelve.open. When you use:
d = shelve.open(filename, writeback=True)
then d keeps a cache of all entries you access, and writes them all back
to the persistent mapping when you call d.close(). This ensures that
such usage as d[key].append(anitem) works as intended.
However, using keyword argument writeback=True may consume vast amount
of memory for the cache, and it may make d.close() very slow, if you
access many of d's entries after opening it in this way: d has no way to
check which of the entries you access are mutable and/or which ones you
actually mutate, so it must cache, and write back at close, all of the
entries that you access. You can call d.sync() to write back all the
entries in the cache, and empty the cache (d.sync() also synchronizes
the persistent dictionary on disk, if feasible).
"""
shelve模块文档
Python之路Day5的更多相关文章
- Python之路,Day5 - Python基础5
本节内容 迭代器&生成器 装饰器 Json & pickle 数据序列化 软件目录结构规范 作业:ATM项目开发 一.列表生成器 , 1, 2, 3, 4, 5, 6, 7, 8, 9 ...
- Python 之路 Day5 - 常用模块学习
本节大纲: 模块介绍 time &datetime模块 random os sys shutil json & picle shelve xml处理 yaml处理 configpars ...
- python之路-Day5
1.列表生成式,迭代器&生成器 列表生成式 我现在有个需求,看列表[0, 1, 2, 3, 4, 5, 6, 7, 8, 9],我要求你把列表里的每个值加1. 普通版 a = [0,1,2,3 ...
- 小白的Python之路 day5 python模块详解及import本质
一.定义 模块:用来从逻辑上组织python代码(变量,函数,类,逻辑:实现一个功能) 本质就是.py结尾的python文件(文件名:test.py,对应的模块名:test) 包:用来从逻辑上组织模块 ...
- 小白的Python之路 day5 time,datatime模块详解
一.模块的分类 可以分成三大类: 1.标准库 2.开源模块 3.自定义模块 二.标准库模块详解 1.time与datetime 在Python中,通常有这几种方式来表示时间:1)时间戳 2)格式化的时 ...
- 小白的Python之路 day5 random模块和string模块详解
random模块详解 一.概述 首先我们看到这个单词是随机的意思,他在python中的主要用于一些随机数,或者需要写一些随机数的代码,下面我们就来整理他的一些用法 二.常用方法 1. random.r ...
- 小白的Python之路 day5 shelve模块讲解
shelve模块讲解 一.概述 之前我们说不管是json也好,还是pickle也好,在python3中只能dump一次和load一次,有什么方法可以向dump多少次就dump多少次,并且load不会出 ...
- 小白的Python之路 day5 模块XML特点和用法
模块XML的特点和用法 一.简介 xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今 ...
- 小白的Python之路 day5 configparser模块的特点和用法
configparser模块的特点和用法 一.概述 主要用于生成和修改常见配置文件,当前模块的名称在 python 3.x 版本中变更为 configparser.在python2.x版本中为Conf ...
随机推荐
- A Byte of Python 笔记(2)基本概念:数、字符串、转义符、变量、标识符命名、数据类型、对象
第4章 基本概念 字面意义上的常量 如5.1.23.9.23e-3,或者 'This is a string'."It's a string!" 字符串等 常量,不能改变它的值 数 ...
- vs2013 cpu占用100%问题
是由于显卡驱动支持wpf有问题 更新驱动或设置里取消自动调节视觉效果 http://support.microsoft.com/kb/2894215
- Vim键盘布局
Vim键盘布局 用Linux的朋友一定会使用到Vim这个文本编辑器,它是由Vi发展而来的编辑器,其具有代码补齐.编译.错误跳转等丰富的功能,非常适合编程.对于修改Linux配置文件它更是你不二的选择 ...
- Dojo baseurl
dojo.baseUrl baseUrl用来存储dojo.js存放 的跟目录,例如dojo.js的路径是“/web/scripts/dojo-1.3/dojo/dojo.js”则baseUrl为“/w ...
- Baby Step Gaint Step
给定同余式,求它在内的所有解,其中总是素数. 分析:解本同余式的步骤如下 (1)求模的一个原根 (2)利用Baby Step Giant Step求出一个,使得,因为为素数,所以有唯一解. (3)设, ...
- Ubuntu Linux: How Do I install .deb Packages?
Ubuntu Linux: How Do I install .deb Packages? Ubuntu Linux: How Do I install .deb Packages? by Nix C ...
- xpage 获取 附件
var db:NotesDatabase=session.getCurrentDatabase(); var doc:NotesDocument=db.getDocumentByUNID('80E21 ...
- UVA 12230 - Crossing Rivers(概率)
UVA 12230 - Crossing Rivers 题目链接 题意:给定几条河,每条河上有来回开的船,某一天出门,船位置随机,如今要求从A到B,所须要的期望时间 思路:每条河的期望,最坏就是船刚开 ...
- MVC 常用方法
1. 后台 action方法里添加错误消息到字典中(key,value) ModelState.AddModelError("Error", "参数传输有误,请重新尝试! ...
- servlet response 中文乱码
先,response返回有两种,一种是字节流outputstream,一种是字符流printwrite. 申明:这里为了方便起见,所有输出都统一用UTF-8编码. 先说字节流,要输出“中国" ...