Java类集 List, Set, Map, Stack, Properties基本使用
首先看下继承结构:
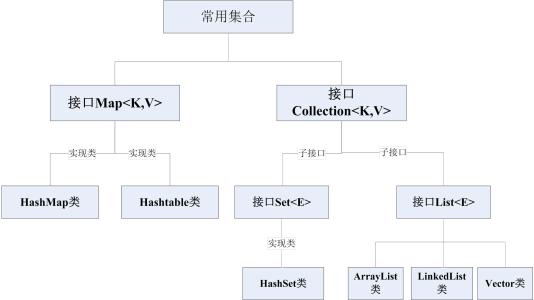
ArrayList(常用):
/**
* List接口继承Collection接口
* ArrayList, Vector为List接口的实现类
* add()添加新元素,remove()删除指定位置元素,get()通过索引获取对应位置元素,set()设置索引位置元素
* Iterator(最常用)接口实现集合遍历
*/
List list = new ArrayList<String>();
list.add("Hello aa");
list.add("Hello bb");
list.add("Hello cc");
list.add("Hello dd");
list.add("Hello dd");
list.add("Hello dd");
list.remove(0);
System.out.println(list);
System.out.println(list.get(0));
list.set(0, "nihao");
System.out.println(list.get(0));
Iterator iter = list.iterator();
while (iter.hasNext()) {
System.out.println(iter.next());
}
Vector(旧版):
/**
* List接口继承Collection接口
* ArrayList, Vector为List接口的实现类
* add()添加新元素,remove()删除指定位置元素,get()通过索引获取对应位置元素,set()设置索引位置元素
* Iterator(最常用)接口实现集合遍历
*/
List list = new Vector<String>();
list.add("Hello aa");
list.add("Hello bb");
list.add("Hello cc");
list.add("Hello dd");
list.add("Hello dd");
list.add("Hello dd");
list.remove(0);
System.out.println(list);
System.out.println(list.get(0));
list.set(0, "nihao");
System.out.println(list.get(0));
Iterator iter = list.iterator();
while (iter.hasNext()) {
System.out.println(iter.next());
}
两者的主要区别:
ArrayList是JDK1.2新加入的, Vector在JDK1.0中就已经出现, Vector是同步的, 所以是线程安全的(当然性能会低),ArrayList是异步的,所以线程不安全,日常开发中Vector已经很少用了,ArrayList更常用一些,两者的用法基本一致。
HashSet, TreeSet:
/**
* Set(集合)是不重复的, Collection集合的子接口
*/
Set hashSet = new HashSet<String>();
hashSet.add("1111");
hashSet.add("1111");
hashSet.add("2222");
hashSet.add("3333");
hashSet.add("X");
hashSet.add("C");
hashSet.add("E");
hashSet.add("A");
System.out.println(hashSet); // 发现HashSet是无序的
Set treeSet = new TreeSet<String>();
treeSet.add("1111");
treeSet.add("1111");
treeSet.add("2222");
treeSet.add("3333");
treeSet.add("X");
treeSet.add("C");
treeSet.add("E");
treeSet.add("A");
System.out.println(treeSet); // 发现TreeSet是有序的
用HashSet, TreeSet存储自定义类Book:
Book类:
public class Book {
private String title;
private double price;
public Book(){
this("", 0.0);
}
public Book(String title, double price){
this.title = title;
this.price = price;
}
}
执行如下代码:
public class Ph {
public static void main(String[] args) {
Set treeSet = new TreeSet<String>();
treeSet.add(new Book("Java开发", 29.8));
treeSet.add(new Book("Java开发", 29.8));
treeSet.add(new Book("JSP开发", 39.8));
treeSet.add(new Book("Oracle开发", 79.8));
System.out.println(treeSet);
}
}
运行时异常:
Exception in thread "main" java.lang.ClassCastException: MyPackageOne.Book cannot be cast to java.lang.Comparable
看到Comparable明白TreeSet通过Comparable接口实现让元素不重复和排序,所以运用TreeSet存储自定义类时应实现Comparable接口并实现CompareTo方法
故Book类此时应为:
public class Book implements Comparable<Book>{
private String title;
private double price;
public Book(){
this("", 0.0);
}
public Book(String title, double price){
this.title = title;
this.price = price;
}
@Override
public int compareTo(Book o) {
if(price > o.price){
return 1;
}else if(price < o.price){
return -1;
}else{
// 注意应该把所有元素的比较填入, 不然有一个属性相同可能就会误以为相同元素
return title.compareTo(o.title);
}
}
}
而此时换成HashSet,发现会有重复元素,因为HashSet通过HashCode()和equals()方法实现去重,故此时Book类应为:
import java.util.Objects;
public class Book {
private String title;
private double price;
public Book() {
this("", 0.0);
}
public Book(String title, double price) {
this.title = title;
this.price = price;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Book book = (Book) o;
return Double.compare(book.price, price) == 0 &&
Objects.equals(title, book.title);
}
@Override
public int hashCode() {
return Objects.hash(title, price);
}
@Override
public String toString() {
return title + price;
}
}
HashMap,Hashtable:
Map map = new HashMap<String, Integer>();
map.put("Hello", 1);
map.put("Hello", 100);
map.put("world", 100);
map.put("Java", 100);
map.put(null, 100);
System.out.println(map.get("Hello"));
System.out.println(map.get("Jav"));
System.out.println(map.get(null));
运行结果:
100
null
100
Map map = new Hashtable<String, Integer>();
map.put("Hello", 1);
map.put("Hello", 100);
map.put("world", 100);
map.put("Java", 100);
map.put(null, 100);
System.out.println(map.get("Hello"));
System.out.println(map.get("Jav"));
System.out.println(map.get(null));
运行结果:
Exception in thread "main" java.lang.NullPointerException
at java.util.Hashtable.put(Hashtable.java:465)
at MyPackageOne.Ph.main(Ph.java:12)
将null去掉:
map.put("Hello", 1);
map.put("Hello", 100);
map.put("world", 100);
map.put("Java", 100);
System.out.println(map.get("Jav"));
运行结果:
null
总结:HashMap和Hashtable区别:
Hashtable为JDK1.0时存在的Map实现类, HashMap为JDK1.2时新加入的Map实现类,HashMap可以设置null而Hashtable不能,Hashtable为同步的线程安全,不推荐使用,HashMap为异步线程非安全,两者用法基本一致。
遍历HashMap(Hashtable一样):
Map map = new Hashtable<String, Integer>();
map.put("Hello", 1);
map.put("world", 100);
map.put("Java", 100);
/**
* 方法一
* 通过keySet()方法获取key集合
*/
Set keySet = map.keySet();
Iterator iter = keySet.iterator();
while (iter.hasNext()){
System.out.println(iter.next());
}
/**
* 方法二
* 通过Map.Entry接口
*/
Set<Map.Entry<String, Integer>> set = map.entrySet();
Iterator<Map.Entry<String, Integer>> iterator = set.iterator();
while (iterator.hasNext()){
Map.Entry<String, Integer> mapEntry = iterator.next();
System.out.println(mapEntry.getKey() + mapEntry.getValue());
}
特别的, Map可以以自定义类为key或value,当作key时,比如之前的Book类(注释掉hashCode和equals方法)
Map map = new HashMap<Book, String>();
map.put(new Book("Java", 10.9), "1");
map.put(new Book("Java", 10.9), "1");
map.put(new Book("Java", 11.9), "1");
System.out.println(map);
运行结果为:{Java10.9=1, Java10.9=1, Java11.9=1}
发现有重复元素, 去掉hashCode和equals方法注释:
此时运行结果:{Java10.9=1, Java11.9=1}
总结:用HashMap,Hashtable时如果自定义类作为key需要加上hashCode和equals方法
Stack:
/**
* Stack为Vector子类,但一般用法与Vector无关
* 常用push,pop,size方法
*/
Stack stack = new Stack<String>();
stack.push("11");
stack.push("22");
stack.push("33");
System.out.println(stack.size());
System.out.println(stack.get(stack.size() - 1));
stack.pop();
System.out.println(stack.get(stack.size() - 1));
Properties:
/**
* Properties类为Hashtable子类
* 不用设置泛型因为只能用String,String
* 常用setProperty方法设置属性, getProperty方法获得属性
* store方法存入文件中,load方法从文件中取出
*/
Properties properties = new Properties();
properties.setProperty("123", "456");
properties.setProperty("1", "4");
properties.setProperty("12", "45");
properties.setProperty("123", "456");
System.out.println(properties.getProperty("123"));
properties.store(new FileOutputStream(new File("key.txt")), "key-info");
properties.load(new FileInputStream(new File("key.txt")));
Collections:
/**
* Collection和Collections的区别:
* Collection是集合的接口,Collections是接口的工具类,提供一些方法
* 如:addAll, reverse, replaceAll等方法
*/
Collections.addAll(list, "1", "2", "3");
Collections.reverse(list);
System.out.println(list);
Collections.replaceAll(list, "1", "2");
System.out.println(list);
Java类集 List, Set, Map, Stack, Properties基本使用的更多相关文章
- 专题笔记--Java 类集框架
Java 类集框架 1. Java类集框架产生的原因 在基础的应用中,我们可以通过数组来保存一组对象或者基本数据,但数组的大小是不可更改的,因此出于灵活性的考虑和对空间价值的担忧,我们可以使用链表来实 ...
- java:类集操作总结
java:类集操作总结 1.List接口允许有重复的元素,Set接口中不允许有重复的元素 2.ArrayList,和Vector的区别 3.set依靠equals和hashCode区分 4.TreeS ...
- 浅谈java类集框架和数据结构(1)
在另外一篇博客我简单介绍了java类集框架相关代码和理论. 这一篇博客我主要分析一下各个类集框架的原理以及源码分析. 一:先谈谈LinkedList 这是LinkedList源码的开头,我们能看到几点 ...
- 浅谈java类集框架和数据结构(2)
继续上一篇浅谈java类集框架和数据结构(1)的内容 上一篇博文简介了java类集框架几大常见集合框架,这一篇博文主要分析一些接口特性以及性能优化. 一:List接口 List是最常见的数据结构了,主 ...
- Java类集框架详细汇总-底层分析
前言: Java的类集框架比较多,也十分重要,在这里给出图解,可以理解为相应的继承关系,也可以当作重要知识点回顾: Collection集合接口 继承自:Iterable public interfa ...
- java:类集操作,多对多的关系
java:类集操作,多对多的关系 //一个课程有多个学生报名, //一个学生可以报名多个课程 demo.java, Student.java, Course.java' public class Co ...
- Java -- Java 类集 -- 目录
13.1 认识类集 13.1.1 基本概念 13.1.2 类集框架主要接口 13.2 Collection接口 13.2.1 Collection接口的定义 13.2.2 Collection子接口的 ...
- Java 类集初探
类集 类集:主要功能就是Java数据结构的实现(java.util) 类集就是动态对象数组(链表也是动态数组) Collection 接口* Collection是整个类集之中单值保存的最大 父接口 ...
- java类集开发中一对多和多对多的关系的实现
摘自<java开发实战经典>李兴华.著 一对多的关系 一个学校可以包含多个学生,一个学生属于一个学校,那么这就是一个典型的一对多关系,此时就可以通过类集进行关系的表示. 在定义Studen ...
随机推荐
- Idea设置行注释不显示在行首
如图:idea使用ctrl+/注释时候,//都在行首,强迫症表示受不了 解决方法如图
- 反射PropertyInfo的简单使用
namespace EF6._0Test { class Program { /// <summary> /// PropertyInfo的简单使用 /// </summary> ...
- 选择结构if
1.if语句 if语句是指如果满足某种条件,就进行某种处理.例如,小明妈妈跟小明说“如果你考试得了100分,星期天就带你去游乐场玩”.这句话可以通过下面的一段伪代码来描述. 如果小明考试得了100分 ...
- Nginx配置多个基于域名的虚拟主机+实验环境搭建+测试
标签:Linux 域名 Nginx 原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 .作者信息和本声明.否则将追究法律责任.http://xpleaf.blog.51cto.com/9 ...
- VMware安装操作系统提示 " Intel VT-x 处于禁用状态"解决方法
VMWARE WORKSTATION 在安装64为操作系统(kali)报错,报错内容为:“已将该虚拟机配置为使用 64 位客户机操作系统.但是,无法执行 64 位操作. 此主机支持 Intel VT- ...
- Nginx动静分离架构&&HA-LB集群整合
Nginx动静分离简单来说就将动态与静态资源分开,不能理解成只是单纯的把动态页面和静态页面物理分离,严格意义上说应该是动态请求跟静态请求分开,可以理解成使用Nginx处理静态页面,Tomcat,Res ...
- 向Spark集群提交任务
1.启动spark集群. 启动Hadoop集群 cd /usr/local/hadoop/ sbin/start-all.sh 启动Spark的Master节点和所有slaves节点 cd /usr/ ...
- Centos 6.5 本地局域网基于HTTP搭建YUM
服务端配置 init 3 文本 init5 图形 init 0 关机 init 1 重启 ls 查看 mkdir创建文件 关闭防火墙service iptables stop chkconfig ...
- CodeForces 516B Drazil and Tiles 其他
原文链接http://www.cnblogs.com/zhouzhendong/p/8990658.html 题目传送门 - CodeForces 516B 题意 给出一个$n\times m$的矩形 ...
- 064 SparkStream与kafka的集成,主要是编程
这里面包含了如何在kafka+sparkStreaming集成后的开发,也包含了一部分的优化. 一:说明 1.官网 指导网址:http://spark.apache.org/docs/1.6.1/st ...