正则表达式零宽断言详解(?=,?<=,?!,?<!)
在使用正则表达式时,有时我们需要捕获的内容前后必须是特定内容,但又不捕获这些特定内容的时候,零宽断言就起到作用了
正则表达式零宽断言:
零宽断言是正则表达式中的难点,所以重点从匹配原理方面进行分析。零宽断言还有其他的名称,例如"环视"或者"预搜索"等等,不过这些都不是我们关注的重点。
一.基本概念:
零宽断言正如它的名字一样,是一种零宽度的匹配,它匹配到的内容不会保存到匹配结果中去,最终匹配结果只是一个位置而已。
作用是给指定位置添加一个限定条件,用来规定此位置之前或者之后的字符必须满足限定条件才能使正则中的字表达式匹配成功。
注意:这里所说的子表达式并非只有用小括号括起来的表达式,而是正则表达式中的任意匹配单元。
javascript只支持零宽先行断言,而零宽先行断言又可以分为正向零宽先行断言,和负向零宽先行断言。
代码实例如下:
实例代码一:
var str="abZW863";
var reg=/ab(?=[A-Z])/;
console.log(str.match(reg));
在以上代码中,正则表达式的语义是:匹配后面跟随任意一个大写字母的字符串"ab"。最终匹配结果是"ab",因为零宽断言"(?=[A-Z])"并不匹配任何字符,只是用来规定当前位置的后面必须是一个大写字母。
实例代码二:
var str="abZW863";
var reg=/ab(?[A-Z])/;
console.log(str.match(reg));
以上代码中,正则表达式的语义是:匹配后面不跟随任意一个大写字母的字符串"ab"。正则表达式没能匹配任何字符,因为在字符串中,ab的后面跟随有大写字母。
二.匹配原理:
上面代码只是用概念的方式介绍了零宽断言是如何匹配的。
下面就以匹配原理的方式分别介绍一下正向零宽断言和负向零宽断言是如何匹配的。
1.正向零宽断言:
代码实例如下:
var str="<div>antzone";
var reg=/^(?=<)<[^>]+>\w+/;
console.log(str.match(reg));

匹配过程如下:
首先由正则表达式中的""获取控制权,首先由位置0开始进行匹配,它匹配开始位置0,匹配成功,然后控制权转交给"(?=<)",由于""是零宽的,所以"(?=<)"也是从位置0处开始匹配,它要求所在的位置右侧必须是字符"<",位置0的右侧恰好是字符"<",匹配成功,然后控制权转交个"<",由于"(?=<)"也是零宽的,所以它也是从位置0处开始匹配,于是匹配成功,后面的匹配过程就不介绍了。
2.负向零宽断言:
代码实例如下:
var str="abZW863ab88";
var reg=/ab(?[A-Z])/g;
console.log(str.match(reg));
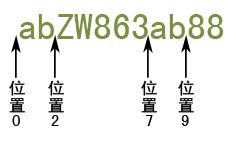
匹配过程如下:
首先由正则表达式的字符"a"获取控制权,从位置0处开始匹配,匹配字符"a"成功,然后控制权转交给"b",从位置1处开始匹配,配字符"b"成功,然后控制权转交给"(?[A-Z])",它从位置2处开始匹配,它要求所在位置的右边不能够是任意一个大写字母,而位置的右边是大写字母"Z",匹配失败,然后控制权又重新交给字符"a",并从位置1处开始尝试,匹配失败,然后控制权再次交给字符"a",从位置2处开始尝试匹配,依然失败,如此往复尝试,直到从位置7处开始尝试匹配成功,然后将控制权转交给"b",然后从位置8处开始尝试匹配,匹配成功,然后再将控制权转交给"(?[A-Z])",它从位置9处开始尝试匹配,它规定它所在的位置右边不能够是大写字母,匹配成功,但是它并不会真正匹配ab后面的字符,所以最终匹配结果是"ab"。
下面补充有重复,可能断言方法名字有所不同,理解意思最重要,可以以补充三中的断言名为准。直接看补充三:没有长篇大论的补充三
三、补充
零宽断言是正则表达式中的一种方法,正则表达式在计算机科学中,是指一个用来描述或者匹配一系列符合某个句法规则的字符串的单个字符串。
定义解释
零宽断言是正则表达式中的一种方法
正则表达式在计算机科学中,是指一个用来描述或者匹配一系列符合某个句法规则的字符串的单个字符串。在很多文本编辑器或其他工具里,正则表达式通常被用来检索和/或替换那些符合某个模式的文本内容。许多程序设计语言都支持利用正则表达式进行字符串操作。例如,在Perl中就内建了一个功能强大的正则表达式引擎。正则表达式这个概念最初是由Unix中的工具软件(例如sed和grep)普及开的。正则表达式通常缩写成“regex”,单数有regexp、regex,复数有regexps、regexes、regexen。
零宽断言
用于查找在某些内容(但并不包括这些内容)之前或之后的东西,也就是说它们像\b,^,$那样用于指定一个位置,这个位置应该满足一定的条件(即断言),因此它们也被称为零宽断言。最好还是拿例子来说明吧: 断言用来声明一个应该为真的事实。正则表达式中只有当断言为真时才会继续进行匹配。
(?=exp)也叫零宽度正预测先行断言,它断言自身出现的位置的后面能匹配表达式exp。比如\b(?=re)\w+\b,匹配以re开头的单词,如查找reading a book.时,它会匹配reading。
var reg = new Regex(@"\w+(?=ing)");
var str = "muing";
Console.WriteLine(reg.Match(str).Value);//返回mu
(?<=exp)也叫零宽度正回顾后发断言,它断言自身出现的位置的前面能匹配表达式exp。比如\b\w+(?<=ing\b)会匹配以ing结尾的单词的前半部分(除了ing以外的部分),例如在查找I am reading.时,它匹配read。
假如你想要给一个很长的数字中每三位间加一个逗号(当然是从右边加起了),你可以这样查找需要在前面和里面添加逗号的部分:((?=\d)\d{3})+\b,用它对1234567890进行查找时结果是234567890。
下面这个例子同时使用了这两种断言:(?<=\s)\d+(?=\s)匹配以空白符间隔的数字(再次强调,不包括这些空白符)。
前面我们提到过怎么查找不是某个字符或不在某个字符类里的字符的方法(反义)。但是如果我们只是想要确保某个字符没有出现,但并不想去匹配它时怎么办?
例如,如果我们想查找这样的单词--它里面出现了字母q,但是q后面跟的不是字母u,我们可以尝试这样:
\b\wq[^u]\w\b匹配包含后面不是字母u的字母q的单词。但是如果多做测试(或者你思维足够敏锐,直接就观察出来了),你会发现,如果q出现在单词的结尾的话,像Iraq,Benq,这个表达式就会出错。这是因为[u]总要匹配一个字符,所以如果q是单词的最后一个字符的话,后面的[u]将会匹配q后面的单词分隔符(可能是空格,或者是句号或其它的什么),后面的\w\b将会匹配下一个单词,于是 \b\wq[^u]\w\b 就能匹配整个Iraq fighting。\b\wq[^u]\w\b不会匹配Iraq fighting,只能匹配Iraq fighting中的 aq f 。而\b\w+q[^u]\w+\b才能匹配整个Iraq fighting。(2017-10-20修正,感谢RussellJX指正)
负向零宽断言能解决这样的问题,因为它只匹配一个位置,并不消费任何字符。现在,我们可以这样来解决这个问题:\b\wq(?!u)\w\b。
零宽度负预测先行断言(?!exp),断言此位置的后面不能匹配表达式exp。
例如:\d{3}(?!\d)匹配三位数字,而且这三位数字的后面不能是数字;\b((?!abc)\w)+\b匹配不包含连续字符串abc的单词。
同理,我们可以用(?<!exp),零宽度负回顾后发断言来断言此位置的前面不能匹配表达式exp:(?<[a-z])\d{7}匹配前面不是小写字母的七位数字。
一个更复杂的例子:(?<=<(\w+)>).(?=<\/\1>)匹配不包含属性的简单HTML标签内里的内容。(<?=(\w+)>)指定了这样的前缀:被尖括号括起来的单词(比如可能是),然后是.*(任意的字符串),最后是一个后缀(?=<\/\1>)。注意后缀里的\/,它用到了前面提过的字符转义;\1则是一个反向引用,引用的正是捕获的第一组,前面的(\w+)匹配的内容,这样如果前缀实际上是的话,后缀就是了。整个表达式匹配的是和之间的内容(再次提醒,不包括前缀和后缀本身)。
上面的看了有点伤脑筋啊。下面来点补充:
补充一:(复习正预测,正回顾,已经理解可以跳过)
断言用来声明一个应该为真的事实。正则表达式中只有当断言为真时才会继续进行匹配。
接下来的四个用于查找在某些内容(但并不包括这些内容)之前或之后的东西,也就是说它们像\b,^,$那样用于指定一个位置,这个位置应该满足一定的条件(即断言),因此它们也被称为零宽断言。最好还是拿例子来说明吧:
(?=exp)也叫零宽度正预测先行断言,它断言自身出现的位置的后面能匹配表达式exp。
比如\b\w+(?=ing\b),匹配以ing结尾的单词的前面部分(除了ing以外的部分),如查找I'm singing while you're dancing.时,它会匹配sing和danc。
(?<=exp)也叫零宽度正回顾后发断言,它断言自身出现的位置的前面能匹配表达式exp。
比如(?<=\bre)\w+\b会匹配以re开头的单词的后半部分(除了re以外的部分),例如在查找reading a book时,它匹配ading。
假如你想要给一个很长的数字中每三位间加一个逗号(当然是从右边加起了),你可以这样查找需要在前面和里面添加逗号的部分:((?<=\d)\d{3})*\b,用它对1234567890进行查找时结果是234567890。
这个正则同时使用了这两种断言:(?<=\s)\d+(?=\s)匹配以空白符间隔的数字(再次强调,不包括这些空白符)。
补充二:(官方理解正预测)
零宽度正预测先行断言是什么呢,看msdn上的官方解释定义
(?= 子表达式)
零宽度正预测先行断言仅当子表达式在此位置的右侧匹配时才继续匹配。
例如,\w+(?=\d) 与后跟数字的单词匹配,而不与该数字匹配。
经典的例子:某单词以ing结尾,要获取ing前面的内容
var reg = new Regex(@"\w+(?=ing)");
var str = "muing";
Console.WriteLine(reg.Match(str).Value);//返回mu
以上是网上到处可见的例子,到这里或许你明白了,原来就是返回了exp表达式前面的内容。
再看下面的的代码
var reg = new Regex(@"a(?=b)c");
var str = "abc";
Console.WriteLine(reg.IsMatch(str));//返回false
为什么会返回false?
其实msdn官方定义已经说了,只是它说得很官方而已。这里需要我们注意一个关键点:**此位置。没错,是位置而不是字符。
**
那么结合官方定义和第一个例子来理解第二个例子:
因为a后面是b,则此时返回了匹配内容a(由第一个例子知道,只返回a不返回exp匹配的内容),此时a(?=b)c中的a(?=b)部分已经解决了,接下来要解决c的匹配问题了,此时匹配c要从字符串abc哪里开始呢,结合官方定义,就知道是从子表达的位置向右开始的,那么就是从b的位置开始,但b又不匹配a(?=b)c剩余部分的c,所以abc就不匹配a(?=b)c了。
那么如果要上面的进行匹配,正则应该如何写呢?
答案是:a(?=b)bc
当然,有人会说直接abc就匹配上了,还要这么折腾吗?当然不用这么折腾,只是为了说明零宽度正预测先行断言到底是怎么一回事?关于其它的零宽断言也是同一原理!
(最精简有用的)补充三:(看例子直接上手用)
(?=exp):零宽度正预测先行断言,它断言自身出现的位置的后面能匹配表达式exp。
匹配后面为_path,结果为product
'product_path'.scan
/(product)(?=_path)/
(?<=exp):零宽度正回顾后发断言,它断言自身出现的位置的前面能匹配表达式exp
匹配前面为name:,结果为wangfei
'name:wangfei'.scan
/(?<=name:)(wangfei)/
(?!exp):零宽度负预测先行断言,断言此位置的后面不能匹配表达式exp。
匹配后面不是_path
'product_path'.scan
/(product)(?!_path)/
匹配后面不是_url
'product_path'.scan
/(product)(?!_url)/
(?<!exp):零宽度负回顾后发断言来断言此位置的前面不能匹配表达式exp
匹配前面不是name:
'name:angelica'.scan
/(?<!name:)(angelica)/
匹配前面不是nick_name:
'name:angelica'.scan
/(?<!nick_name:)(angelica)/
再次提醒,如果由于同样表达式在不同地方的断言方法名(断言表达式叫法)不一致引起不适的话请以补充三中的为准。溜了溜了。
谢谢大家的阅读。
正则表达式零宽断言详解(?=,?<=,?!,?<!)的更多相关文章
- crawler_正则表达式零宽断言
在使用正则表达式时,有时我们需要捕获的内容前后必须是特定内容,但又不捕获这些特定内容的时候,零宽断言就起到作用了. (?=exp):零宽度正预测先行断言,它断言自身出现的位置的后面能匹配表达式exp. ...
- python 之re模块(正则表达式) 分组、断言详解
正则表达式分组.断言详解 提示:阅读本文需要有一定的正则表达式基础. 正则表达式中的断言,作为高级应用出现,倒不是因为它有多难,而是概念比较抽象,不容易理解而已,今天就让小菜通俗的讲解一下. 如果 ...
- 零宽断言 -- Lookahead/Lookahead Positive/Negative
http://www.vaikan.com/regular-expression-to-match-string-not-containing-a-word/ 经常我们会遇到想找出不包含某个字符串的文 ...
- js正则:零宽断言
JavaScript正则表达式零宽断言 var str="abnsdfZL1234nvcncZL123456kjlvjkl"var reg=/ZL(\d{4}|\d{6})(?!\ ...
- python 正则表达式之零宽断言
零宽断言:用于查找特定内容之前或之后的内容,但并不包括特定内容本身.对于零宽断言来说,我认为最重要的一个概念是位置,零宽断言用于指定一个位置,这个位置应该满足一定的条件(它附近满足什么表达式),并且这 ...
- $python正则表达式系列(5)——零宽断言
本文主要总结了python正则零宽断言(zero-length-assertion)的一些常用用法. 1. 什么是零宽断言 有时候在使用正则表达式做匹配的时候,我们希望匹配一个字符串,这个字符串的前面 ...
- Python正则表达式进阶-零宽断言
1. 什么是零宽断言 有时候在使用正则表达式做匹配的时候,我们希望匹配一个字符串,这个字符串的前面或后面需要是特定的内容,但我们又不想要前面或后面的这个特定的内容,这时候就需要零宽断言的帮助了.所谓零 ...
- Python爬虫学习(4): python中re模块中的向后引用以及零宽断言
使用小括号的时候,还有很多特定用途的语法.下面列出了最常用的一些: 表4.常用分组语法 分类 代码/语法 说明 捕获 (exp) 匹配exp,并捕获文本到自动命名的组里 (?<name>e ...
- JS不支持正则中的负向零宽断言
今天在项目中用到了正则表达式,并且需要用负向零宽断言 (?<=exp) 进行筛选,结果运行时报 Invalid group 错,一开始以为是自己很久没用表达式写错了,查阅了一下正则语法后发现并没 ...
随机推荐
- 452. Minimum Number of Arrows to Burst Balloons
There are a number of spherical balloons spread in two-dimensional space. For each balloon, provided ...
- zeromq的安装,部署(号称最快的消息队列,消息中间件)
1:Storm作为一个实时处理的框架,产生的消息需要快速的进行处理,比如存在消息队列ZeroMQ里面. 由于消息队列ZeroMQ是C++写的,而我们的程序是运行在JVM虚拟机里面的.所以需要jzmq这 ...
- CAS5.3.X 配置备忘
## # 普通MD5用户jdbc验证 ## #配置数据库连接 cas.authn.jdbc.query[0].driverClass=com.mysql.cj.jdbc.Driver cas.auth ...
- 【AtCoder】ARC075
ARC075 在省选前一天听说正式选手线画到省二,有了别的女选手,慌的一批,然后刷了一个ARC来稍微找回一点代码感觉 最后还是挂分了,不开心 果然水平退化老年加重啊 原题链接 C - Bugged 直 ...
- ArcObjects 中连接geodatabase
参考资料: 1. http://help.arcgis.com/en/sdk/10.0/arcobjects_net/conceptualhelp/index.html#/d/0001000003s8 ...
- ES6新特性:使用export和import实现模块化(转载)
在ES6前, 前端就使用RequireJS或者seaJS实现模块化, requireJS是基于AMD规范的模块化库, 而像seaJS是基于CMD规范的模块化库, 两者都是为了为了推广前端模块化的工 ...
- 51Nod1863 Travel 主席树 最短路 Dijkstra 哈希
原文链接https://www.cnblogs.com/zhouzhendong/p/51Nod1863.html 题目传送门 - 51Nod1863 题意 有 n 个城市,有 m 条双向路径连通它们 ...
- 三次Java实验整理汇报:
*第一节 eclipse操作,建Javaproject项目(可直接用中文名命名)->建包与类(名字相同) ->public static void main(String[] args){ ...
- P1080 国王游戏 贪心 高精度
题目描述 恰逢 HH国国庆,国王邀请nn 位大臣来玩一个有奖游戏.首先,他让每个大臣在左.右手上面分别写下一个整数,国王自己也在左.右手上各写一个整数.然后,让这 nn 位大臣排成一排,国王站在队伍的 ...
- 044 SimpleDateFormat的线程安全问题与解决方案
这个问题,以前好像写过,不过现在这篇文章,有一个重现的过程,还是值得读一读的. URL:SimpleDateFormat的线程安全问题与解决方案