《机器学习实战(基于scikit-learn和TensorFlow)》第二章内容的学习心得

请支持正版图书, 购买链接
下方内容里面很多链接需要我们***,请大家自备梯子,实在不会再请留言,节约彼此时间。
源码在底部,请自行获取,谢谢!
当开始着手进行一个端到端的机器学习项目,大致需要以下几个步骤:
- 观察大局
- 分析业务,确定工作方向与性能指标
- 获得数据
- 借助框架分析数据
- 机器学习算法的数据准备
- 选择和训练模型
- 微调模型
- 展示解决方案
- 启动、监控和维护系统
接下来,我将对每一个部分自己的心得进行总结。
一、观察大局
当开始一个真实机器学习项目时,需要针对项目的特点,有针对性进行分析。任何项目都有其最终的目的,总的说来,我觉得首先要考虑的是业务需求,即用这个模型要解决什么事情,需要的程度如何等等的问题。假设项目是一个预测的问题,那么我需要知道的是我上游环节能给我什么样的数据,下游的环节需要我提供怎样的数据流,是具体的价格(要精确到何种地步?)?还是一个等级划分?这些都决定了自己在这个项目上所花费的精力以及使用的模型、测量方法等一系列问题,总之要求不一样,进行的处理就不一样,这就是大局观。
二、分析业务,确定工作方向与性能指标
因为我们是要进行机器学习项目,所以应该根据业务对我们的项目要构造的机器学习系统的种类进行划分。从长远来看,机器学习系统大致有以下几种:
- 是否在人类监督下训练:监督式学习、无监督学习、半监督学习与强化学习
- 是否可以动态地进行增量学习:在线学习和批量学习
- 是简单地将新的数据点和已知的数据点进行匹配,还是对训练的数据进行有针对性的模型预测:基于实例的学习与基于模型的学习
这里,以文中的”房价预测“为例。
1、分析机器学习系统的类别
这里可以先提前给出部分数据,如下图。让我们来思考一下,这个预测问题应该划分为什么类别。

我们可以看到,图中数据有很多属性,由于我们最终做的是房价预测而数据中你会发现有一列属性很耀眼”median_house_value“,这个属性是该地区的房价中位数属性,那我就明白了一件事,那就是我要预测的结果应该与该地区的房价中位数差不多才是正确的预测结果,所以我的机器学习系统应该是一个有监督的学习系统,是一个多变量回归的问题。
2、测试指标的选择
因为已经确定了是一个对变量的回归问题,因此测试指标就应该对应多变量回归问题进行。
回归问题的典型性能衡量指标首选是均方根误差(RMSE),这里首先给出它的公式供大家参考:
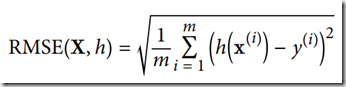
注:其中的m是数据集实例中的实例数量,x是数据集中所有实例的所有特征值的矩阵,h(x)为系统的预测函数,即我们要预测的结果,y为真实值。
上式的意思就是描述预测值与真实值之间的差异,RMSE的值越小,说明预测效果越好,预测值与真实值的偏差越小。
(这里附一个链接,关于讲解均方根误差、标准差、方差之间的关系。总的说来,标准差是数据序列与均值的关系,而均方根误差是数据序列与真实值之间的关系。因此,标准差是用来衡量一组数自身的离散程度,而均方根误差是用来衡量观测值同真值之间的偏差,它们的研究对象和研究目的不同,但是计算过程类似)
如果获得的数据中存在许多的离群区域,我们可以考虑用平均绝对误差(MAE),这里给出公式:
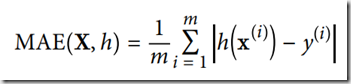
这个公式可以很好的解决偏离抵消的情况,真实反映出预测值与真实值的偏差,当然MAE的值越小越好。
上述两个公式相比,我们可以发现,RMSE对异常值更加敏感,因为当出现一个较大的偏差的异常值时,会极大影响结果的数值,MAE则影响相对小。
所以,RMSE更加适合数据分布为钟形的曲线(类似正态分布)的情况,而MAE更加适合数据偏离散的情况。
三、获得数据
我的建议是要获取真实的数据进行操作。书中列出了很多的开源数据:
- 流行的开放数据存储库:
— UC Irvine Machine Learning Repository
- 源门户站点(他们会列出很多开放的数据库):
- 其他的一些许多流行的开放数据库页面:
— Wikipedia’s list of Machine Learning datasets
这里开放的数据许多是国外数据库,访问需要***,如急切需要但不知如何***,请与我联系(nfuquan AT gmail.com)
以后会更新更多的关于我们中文的数据库,尽情期待。
四、借助框架分析数据
用Anaconda组件中的Jupyter Notebook说明,编程语言为python3.5。
1、Pandas
具体它的功能就不去介绍了,可以附一个链接,自行查看。
这里集中说明几个函数的功能,方便以后自己能快速查看。
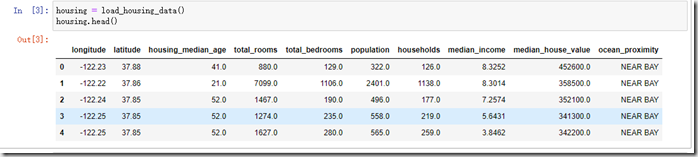
- pandas.DataFrames.head()
这个函数是读取DataFrames格式数据,默认读取5个元素,当然可以在参数中传递自己想读取的函数的个数。
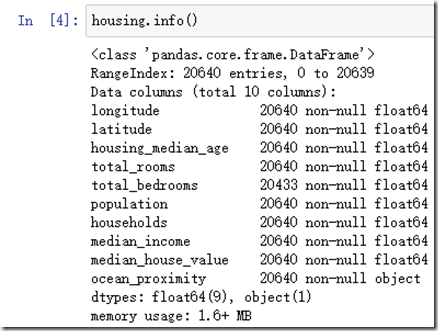
- pandas.DataFrames.info()
这个函数是列出DataFrames格式中的索引信息、行信息、非空值信息以及内存使用信息,这个函数可以清楚地告诉我们数据的异常状态,从而让我们在数值上进行处理。
- pandas.DataFrames.describe()
这个函数显示数据的各个属性摘要,同时针对数值数据进行了数据的一些计算。

- pandas.DataFrames[“属性”].value_counts()
这个函数是对属性中的内容进行统计。
- pandas.DataFrames.hist()
首先应该在首行加入%matplotlib inline (该式只能在jupyter notebook中使用,意思是直接编译显示结果)。
这个函数是将数据每个属性制作为一个直方图。有很多的参数,具体请查看链接


上述函数给我们一个极大的便利就是针对数据的具体情况可以进行逐个分析。例如,我们可以看到收入中位数“median_income”最大值为15,这个不符合常识,收入因该至少在五位数才对,因此需要针对该数据对数据提供方进行询问,经询问,得知该属性进行了属性的缩放。在直方图中,我们一般应该注意的方面是数据的范围以及数量、分布,为什么要关注这些呢,因为要结合实际。举个例子,比如我们发现房屋价格的中位数最大到50万美元,而且数量很多,而且根据数据的分布,感觉存在异常,如果对数据敏感的话,我们应该有这样的疑问:是否这个数据是一个限制条件,就是说将这个数据以上的数据全部都设置为50万,这会导致我们的学习算法永远不会估计出超过50万元的数值,这个结果是否可接受,需要考虑。如果要求是可以预测出50万元以上的房屋价格,我们可以针对50万以上的房屋价格重新收集数据或者除去50万元以上的数据,同时允许我们的机器学习算法预测出50万元以上的结果。直方图还表现了一个特征是有几个属性值分布不均匀,有可能会影响机器学习系统难以预测的某些模式。
书中介绍了一个典型偏误“数据窥探偏误”,这里先解释一下:人脑容易过度匹配,当发现某些数据模式有特征时,可能就会只训练某些有特征的数据,而这些数据很有可能不代表普遍规则,如果机器学习算法采用这些数据做训练,就会导致结果可能很好,但是在预测实际内容时,会缺乏泛化能力。我们需要科学的数据划分!
数据集划分:训练集(训练+验证)、测试集
假设数据量较大5000-10000内,可以用随机选择的方式,按照训练80%,测试20%进行分布。假设数据量在100000以上,可以考虑将训练集的比例增加,测试集比例降低。如果数据很少,则随机选择数据划分可能存在问题,要按照一定规则分布的规律中进行抽样选择。以房屋价格预测为例,预测的价格与人们的收入中位数属性密切相关,因此我们应该以收入中位数的属性特征进行样本的划分:
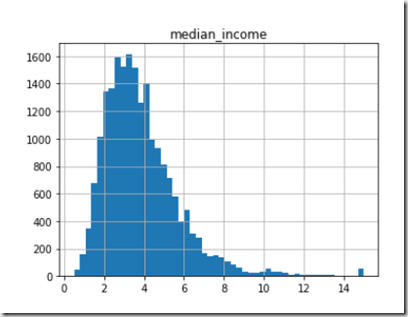
上图是收入中位数数据,我们可以看出,收入在2-4人数比较多,同时看出基本上在收入上是一个连续的分布,不能进行一个分层的抽样,因此,我们应该将上述数据进行一个划分,分成5类或者6类(这个分类可以自己定)。
操作步骤:1、使用numpy框架的ceil()函数进行取整操作
2、然后使用where()函数,将取整后的类别值大于5的类别统一归为类别

上述操作我们获得了一个分类标签属性“income_cat”,注意这个标签只是为了区别各个数据的收入中位数类别,因此这个标签可以在使用完毕之后进行删除。
使用sklearn框架中的Stratified-Shuffle Split类可以进行分层抽样。

上面的语句的意思是首先对需要分层的类别进行一个预设置,然后通过一个for循环按照数据中的“income_cat”属性中的分层情况进行划分,得出分布一样训练集和测试集。具体的类别怎么操作,请查阅链接
使用pandas.DataFrame中的drop()可以将函数中的某个属性进行删除,因此我们在使用完“income_cat”后在测试集中与训练集中将该属性删除:

至此,我们按照科学的方式对数据进行了划分,使得测试集与训练集的分布一致,这是一个合理科学的划分方式。
当我们将测试集与训练集划分好后,测试集不宜改动,我们应该重点关注训练集,并从中获取更多的易于构建我们机器学习系统的信息。
训练集的探索:
首先,创建一个训练集副本!任何探索都不能改变原始数据集合,应该创建副本,在副本上进行探索!使用copy()函数进行拷贝。

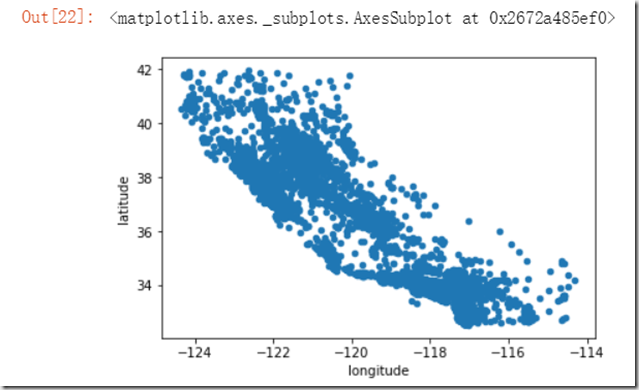
还是回归到数据集的属性上,“longitiude”与“latitude”是经纬度,这个数据是不会变的,相比其他的数据来说,这个数据在显示上更容易,因此我们可以对该数据进行可视化操作。
plot()函数是绘图函数,具体的介绍,请看链接

在上述函数中有个属性是alpha,改变该值,可以提高显示图像的疏密程度,这对于我们的数据探索有帮助,因此:
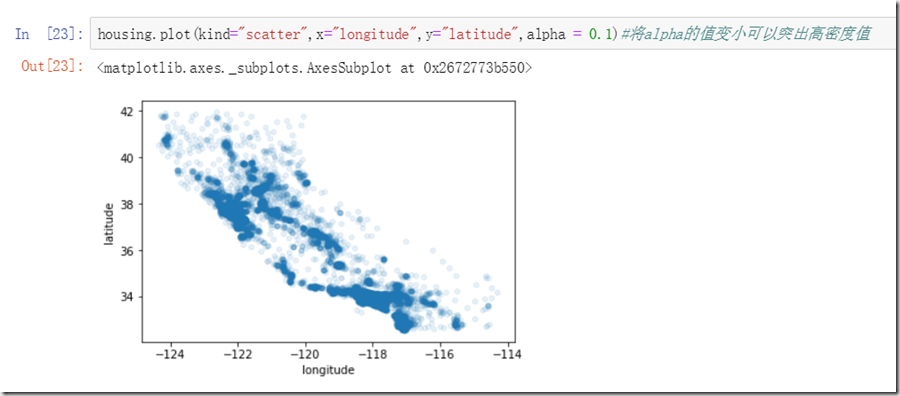
可以看出,沿海的房屋数据更多,内陆的房屋数据较少些,沿海地区中也存在集中现象。
在此基础上,我们将房价信息添加到上图中。
使用jet的一个预定义的颜色表表示房屋价值,每个园的半径显示出该地区人口数量:

从这张图,信息量就大多了。首先,我们可以观察到,越靠近沿海地区(再解释一下,该数据是加利福尼亚州的房屋价格数据,因此根据美国地理位置,沿海地区一目了然)房屋价格更高,同时人口的分布大致呈两条弧线,沿海地区与内陆地区的人口分布在总体上大致保持一致。
因为数据的量不大,我们可以让计算机对数据的相关性进行一个计算。
使用corr()函数,计算各属性与房价中位数的关系。
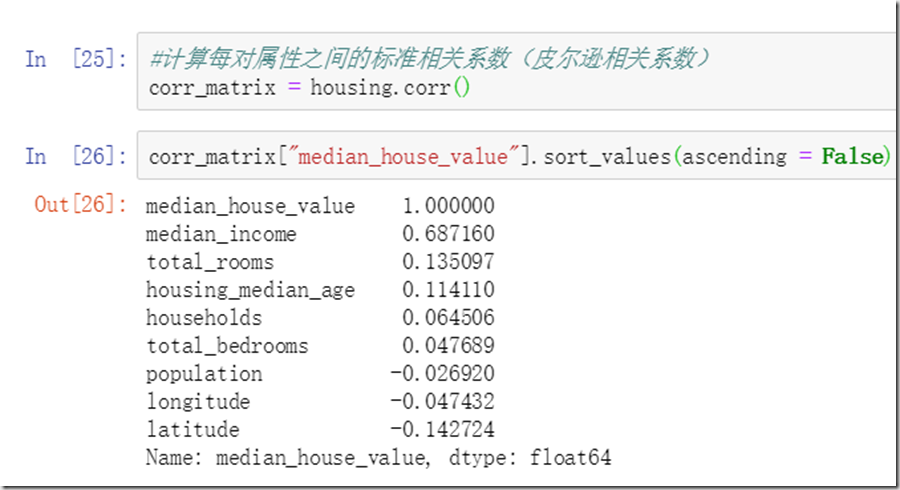
相关性的值,越靠近1说明正相关性越强,越靠近-1说明负相关性越强,越靠近0说明两者之间没有相关性。注意,这里corr()计算的是一种线性相关关系,不是非线性相关关系。
从上图,房价中位数与收入中位数有很强的相关性。
使用Pandas中的scatter_matrix()函数可以绘制各属性之间的相关性,如果不加限制条件,函数将把所有属性与其他属性的相关关系全部计算。我们的数据中存在11个属性,因此如果不加限制条件,会绘制11*11=121个图形。选取与房价中位数直觉上最相关的属性计算,这里选取“median_income”、“total_rooms”、“housing_median_age”三个属性计算相关性:

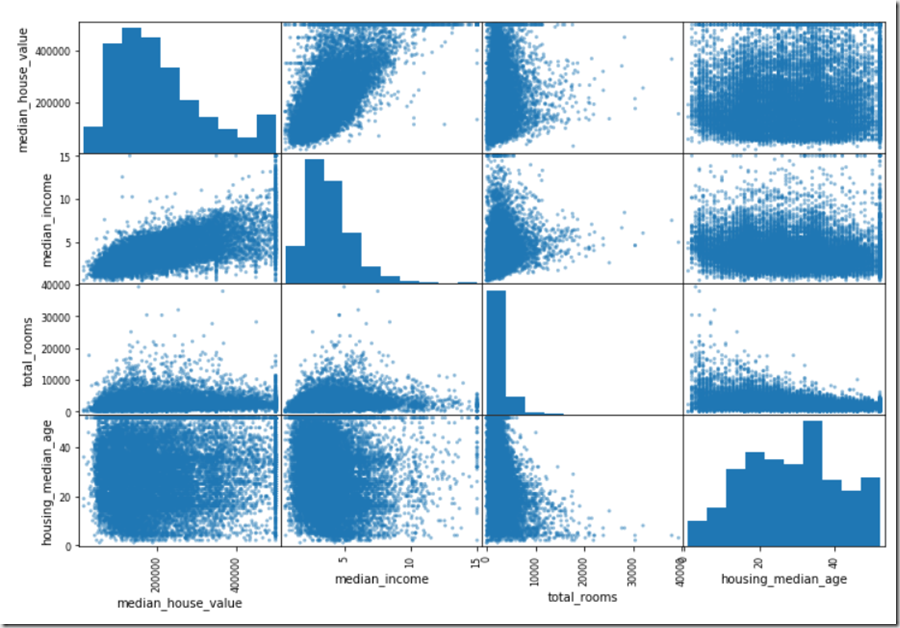
这张图的对角线需要说明一下,因为相同的属性的相关性肯定是1,因此显示直方图。
我们重点关注一下“income_value”与“house_median_value”的关系:
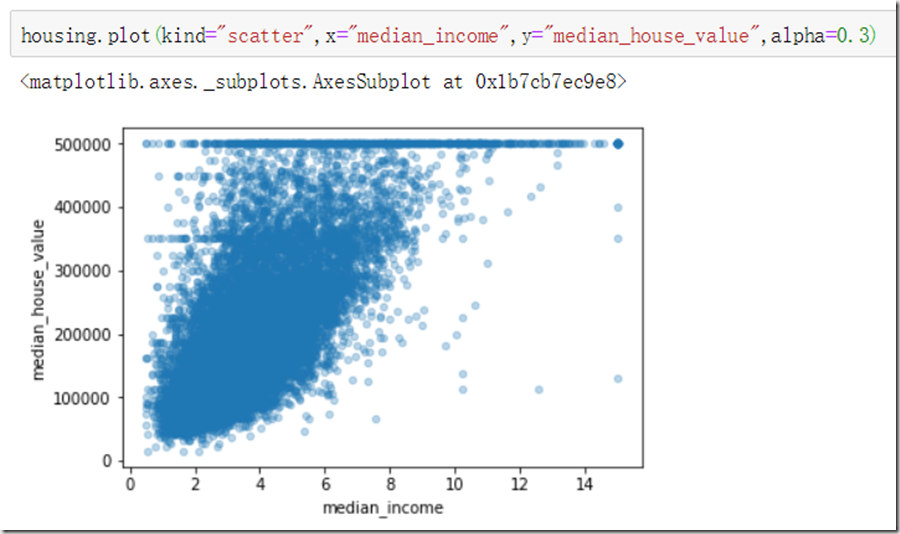
从图中可以看出,在50万有一条横线,在35万、45万处好像也存在直线,我们在继续的数据处理中应该对这些点进行去除,防止系统重现这些怪异数据。
除了上述针对原属性的介绍,我们其实也可以针对属性进行组合,形成新属性。
我们从之前给出的属性,我们可以进行分析,这里再给出我们的属性:
在属性中,我们能观察到“total_bedrooms”、“total_rooms”、“population”、“households”可能存在一定联系,那么是否可以对这几个属性进行一个数据融合形成一个新属性呢?当然可以,并且有助于深刻探索数据。书中针对该方面新创新了3个属性:

上述属性含义分别是:平均每房屋的房间数、平均房间中的卧室数、平均人口持有房屋数
我们可以通过计算相关性,看看新属性对“house_median_value”的关系:
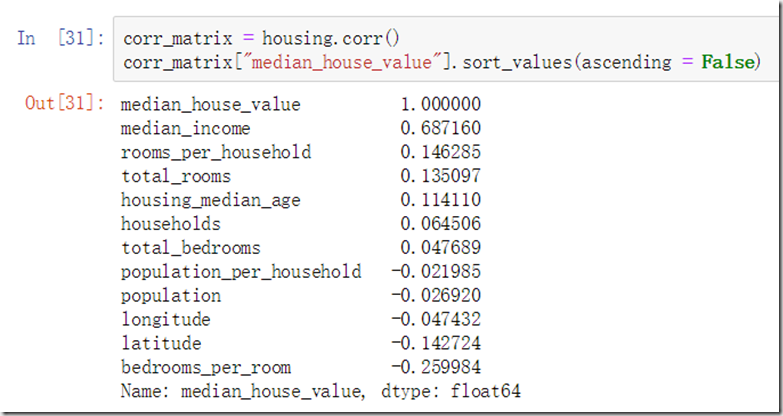
“bedrooms_per_room”与房屋中位数属性相关度比其他大部分属性高,说明新属性的创造是有效的。
五、机器学习算法的数据准备
针对给机器学习算法的数据准备,我认为有以下几个方面:
- 不完全数据的合理补全
- 非数值属性的变换
- 新增新属性,删除相关性差的属性
- 数据数值的合理化(归一化、均值化等)
从技术的角度,我们应该采用一套自动化的数据转换,而不是每次都手动转换。原因有以下几点:
- 可以在任意数据集上重现转换(比如:获得更新的数据库之后)
- 逐渐建立起一个转换函数的函数库,可重用
- 在实时系统中使用这些函数来转换新数据再给算法
- 可尝试多种转换系统,查看哪个转换组合最佳
首先,同样创建一个去除预测值的训练集(X_Train),将预测值传入新的list中(Y_train)。

准备工作完毕后,正式开始:
不完全数据的合理补全:
从之前的info()函数,我们已经得出有些数据是不全的,比如“total_bedrooms”。有三种办法对该属性值进行处理:
- 放弃缺失的地区
- 放弃该属性
- 将缺失值设置为某一个合理值
由于这个属性缺失数量比较小,因此打算采用第三种方式进行。
sklearn中的Imputer类可以处理该问题,首先应创建该类实例。由于这个类处理时需要纯数值的数据,因此我们要预先将非数值的数据进行删除后再做处理:

Imputer.fit()是计算各属性的策略值,并保存在imputer.statistics_中。这样做的好处就是我们不知道未来的数据中哪个部分存在缺失,我们可以针对这些缺失做出处理。
然后开始替换:

这个imputer实例将把housing_num中的缺失值替换为之前计算好的数值。转换后的X是一个numpy框架定义的数组,如果想转换为pandas的DataFrames,可以进行如下操作:

文本数据的处理:
“ocean_proximity”是一个文本属性,要变为数值属性,算法才能更好的工作。
sklearn中的LabelEncoder是实现这个功能的类。
废话不多说,直接上代码,马上就懂:

从结果可以发现,这个函数的功能是将文本集合映射为数字的过程。这个映射为:

内容和序号实现了映射,0对应‘1H OCEAN’,以此类推。
这里,我们需要考虑一个问题:映射的方式是没有错的,但是毕竟是数值,数值就存在大小,从数值上说1就是比4小,因此这个差异可能会导致学习算法的精准度,因此采用one-hot编码更好些!如果不晓得,请点此链接查询。
sklearn类提供了一个OneHotEncoder类来提供此服务。
先上代码,然后解释:

reshape()函数是将numpy数组的形状进行转换,这里的-1需要解释一下:一个参数为-1时,那么reshape函数会根据另一个参数的维度计算出数组的另外一个shape属性值。
fit_transform()函数是将fit()函数和transform()函数结合的函数,它的作用是先将数据做规则的操作,然后再对数据转换为标准形式。
housing_cat_1hot将会转变为一个scipy的矩阵,是一个稀疏的矩阵。当然如果需要转换为numpy类型的矩阵,只需要做如下操作:
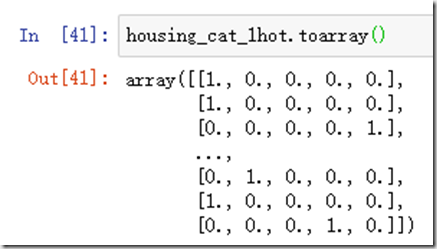
toarray()函数可以转为numpy类型的数组。
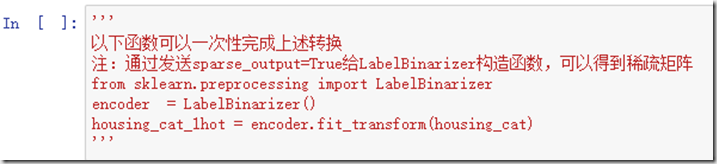
LabelBinarizer类可以将上述两个步骤合并,同时通过传送sparse_output=True给LabelBinarizer类的构造函数可以获得稀疏矩阵。
自定义转换器:
这个步骤的意义在于,使用框架中的方法总不能很好的契合我们的实际需要,我们可以利用框架中的方法,通过自己定义转换器,将框架中的方法最有效的利用到我们的转换器中,这样可以节省很多时间!
先上代码,再分析:

我们首先要明白一个概念,然后再来解释为什么要这样做,这个概念是鸭子类型,不懂的小伙伴请点击链接看一下含义。
这个类是组合属性添加类,参数是基本估计器和转换估计器,这里给个链接,需要的朋友们去链接里面看一下这两个东西是啥。首先我们知道数据属性的顺序,因此可以直接预定义需要查找到每个属性的索引序号,room_ix,bedroom_ix等都是其索引序号。然后是__init__()函数,这个是构造函数,用来初始化某个需要的属性标识,默认为Ture(也就是默认是要添加的!)。定义fit()函数,将参数self、X(外部传递的参数)传递给它,同时返回的self是一个具有fit()函数处理过的结果。设置transform()函数,同样将参数传递给它。这个函数就会根据我们在构造函数中传入的参数add_bedrooms_per_room的true或者False来判断是否需要添加这个属性,如果不添加,我们就只会添加rooms_per_household与population_per_household两个属性。np.c_函数是按行连接两个矩阵,就是把两矩阵左右相加,要求行数相等。至此,类的设置就完毕了。
CombineAttributesAdder()这个就是初始化我们的类,并且给这个类提供参数,如果不填则默认需要添加add_bedrooms_per_room这个属性。最后,使用类中transform()函数,将属性添加进来得到一个新的添加了新属性的矩阵。
特征缩放:
如果数据大小存在非常明显的差异,那么有可能会导致机器学习算法性能不佳。同比例的缩放所有属性有两种常用的方法:最大最小缩放和标准化。
- 最大最小缩放
将值重新缩放使其最终范围归于0到1之间,实现方法是将值减去最小值并除以最大值和最小值的差。我们可以用sklearn中的MinMaxScaler的转换器,当然不想范围是0-1可以通过传递超参数feature_range进行更改。
- 标准化
首先减去平均值,除以方差,使得结果的分布具有单位方差。可以使用standadScaler()函数。
标准化并不会将结果绑定到一个范围中,有可能不适合某些对输入数据有要求的处理,但是它相比上一个缩放方式,受到异常值的影响更小,比如假设某地区平均收入是1000(这是一个错误数据),缩放就会将所有数据从0-15降到0-0.015,影响较大,但如果是标准化,异常值不会干扰其他正常数据。
具体使用见下面部分!
转换流水线:
sklearn有一个很好的思想就是将转换操作工厂流水线化,它有一个非常nice的类,叫做Pipeline类,这个类可以帮我们实现对数据集处理的自动化操作!
Pipeline类的构造函数会通过一系列的名称/估算器的配对来定义步骤序列。先上代码:
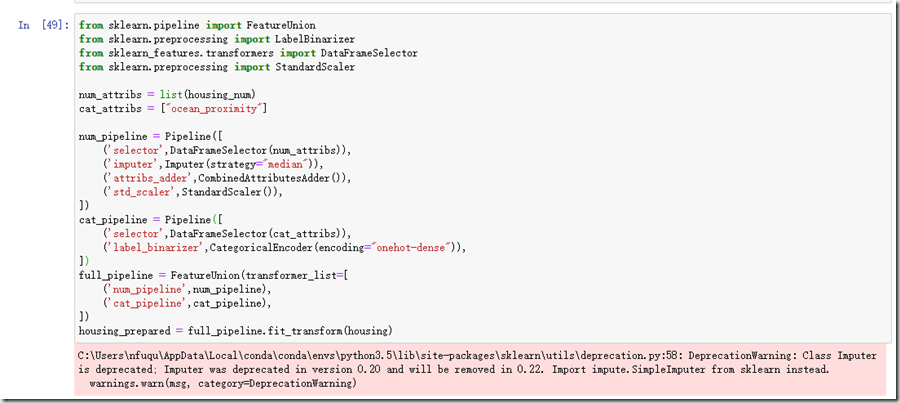
这一步可能会有很多童鞋报错,有的会说缺少sklearn_features的包,有的会报参数个数的错误,这里副个链接,有问题请点击这个链接。
除了导入了需要的包之外,我们首先看到定义了两个参数,一个是list类型的数值文本属性名称(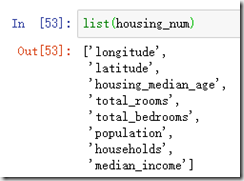 ),一个是类别参数,因为这里只有“ocean_proximity”这个属性是文本属性,因此我们只将这个属性赋值给cat_attribs中。
),一个是类别参数,因为这里只有“ocean_proximity”这个属性是文本属性,因此我们只将这个属性赋值给cat_attribs中。
首先,要先自定义一下这个DataFrameSelector,先给出代码:

这里给出的就是按照参数给出的数值属性进行转换。
接下来开始定义Pipeline,我们只需要在构造方法中传入我们需要的顺序即可。比如num_pipeline,在构造函数中传入我们需要执行的函数DataFrameSelector()、Imputer()、CombineAttributesAdders()、StandardScaler(),同样方法可对其他的流水线进行了定义。
每一条子流水线都是从选择器转换器开始,然后挑出所需属性(数值或者分类),生成的DataFrame再转换为numpy数组就可以进行训练了。
至此,针对算法的数据准备基本到此告一段落。
六、选择和训练模型
在这个阶段,应该做的就是选择一个合适的模型,训练该模型,并评估预测的质量了。
首先可以尝试选择一个线性回归模型。
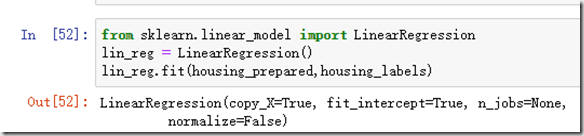
代码怎么用,这里不解释了,看代码就知道了。这里通过fit()函数后,lin_reg就是我们通过训练集得出的第一个训练模型,接下来可以通过predict来进行预测。我们可以通过训练集的一些数据进行:
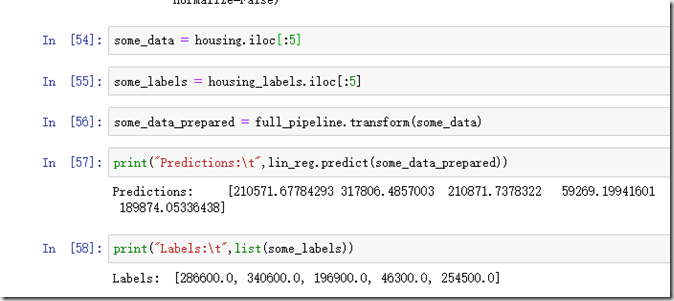
我们从总数据中选出五个数据进行测试,虽然测试结果不尽如人意,但是系统可以工作了,这个还是很让人兴奋的!
那么,怎么评估算法的性能呢?我们使用RMSE。
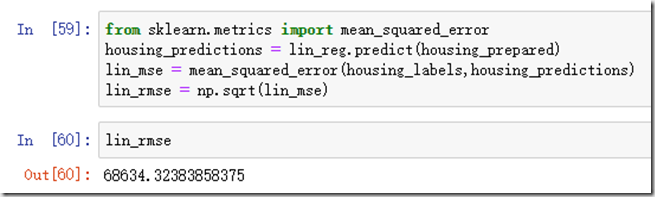
从之前的数据中,大多地区的房价中位数在12万美元到26万美元之间,我们的预测基本与之相差6万8的误差,说明我们的系统对数据拟合存在严重不足。当这种情况发生时,可能是由于特征信息不能提供足够的信息让我们做出更好的预测还有就是算法不够强大。因此到了这一步,你就有两种选择,一个是需要更多新属性来支持算法,还有一个就是选择更强大的模型或者减少模型约束(当然,我们选择的线性模型没有什么约束,谈不上这一点…)。
我们用更强大的算法试试!
用决策树模型,试试效果:
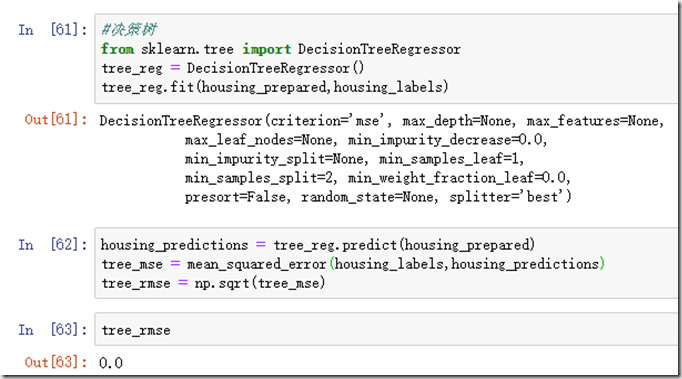
我擦,RMSE最后的结果竟然为0?!完美的算法?of course not! 很大程度上,不存在完美的算法,应该是数据严重过拟合了。。。
很大程度上,不存在完美的算法,应该是数据严重过拟合了。。。
用K折交叉验证的方式,能够还原算法的本来面貌。
交叉验证,说白了就是将训练集科学分成K份,每次选择1份做验证集,其他为训练集,分别训练K次,选出性能最好的模型作为最后的模型:
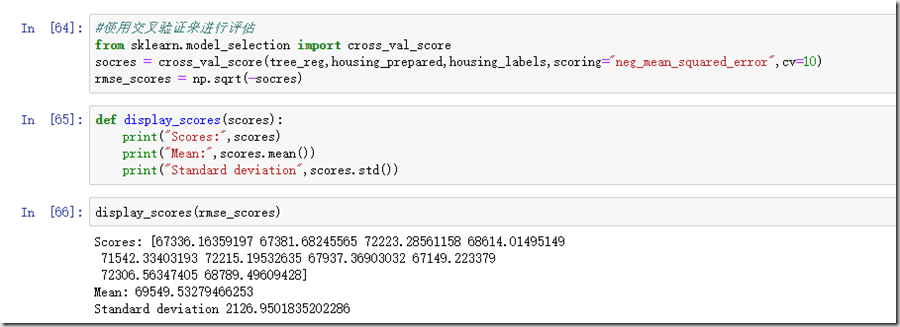
这里从cross_val_score的参数中可以发现,第一个参数是模型,第二个参数是训练集,第三个参数是标签,第四个参数是选择打分类型,第五个参数是选择那个K,最后得出的score就是一个K大小的数组,每个里面放着一次的得分。
从结果上看,平均得分在69549,上下浮动2000左右。
我们再看看线性回归模型:
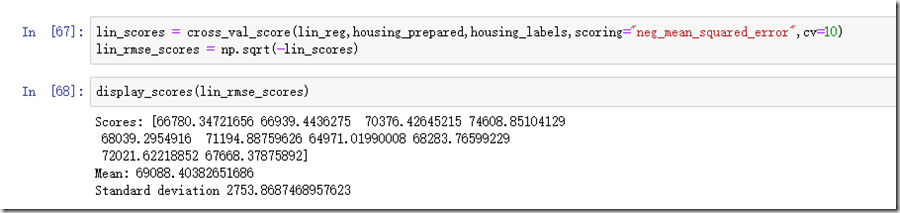
线性回归跑分是69088,比决策树稍差。
我们最后再看看随机森林模型。
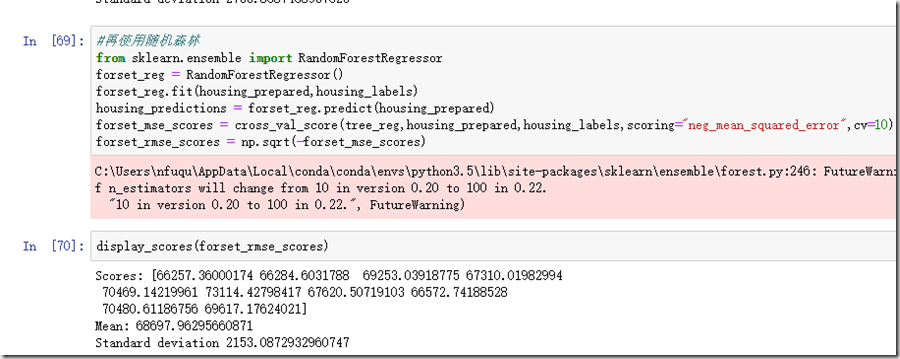
随机森林模型显然不如决策树模型。
我们尝试了很多种不同的模型,原因是在这个阶段我们需要尝试不同模型,选出其中有潜力的模型,千万不要花太多时间去调整每个模型的超参数,确定要使用的模型才是这个阶段最关键的!
至于模型的过拟合问题或者其他什么问题,我们等确定模型后再调试即可。
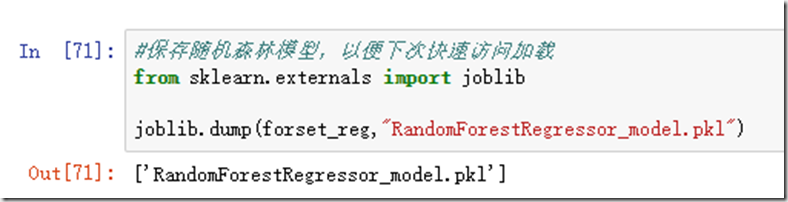
每个模型都应该妥善的保存,这里介绍一个python中的pickel模块或者sklearn.externals的joblib模块:
七、微调模型
假设,你现在已经确定了好几个有潜力的模型,那么这时候需要微调它们了。
微调的一个方法是对模型的超参数进行调整,这个过程很耗时,你需要科学的工具帮助你。使用sklearn中的GridSearchCV来帮助你。
这里面param_grid首先评估第一个dict中的n_estimator和max_features的所有可能的组合(3*4=12),然后尝试第二个dict中的参数组合(2*3=6)。最后需要尝试6+12=18种组合,并对每个模型进行5次训练。当运行完毕后,可获得最佳参数组合:
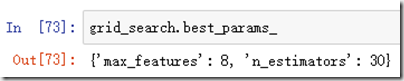
同时,我可以得到最好的估算器:

评估分数也可以得出:

对了,有些数据准备也可以当作超参数来处理,比如之前的自定义转换器中是否添加“add_bedrooms_per_room”。
当然若超参数数量非常大,一般选择RandomizedSearchCV,这个函数会在每次迭代中为每个超参数随机选择一个值,对一定数量的迭代进行评估,这里不详细介绍了,具体请Google。
检查最佳模型,我们还可以得出每个属性的相对重要程度:
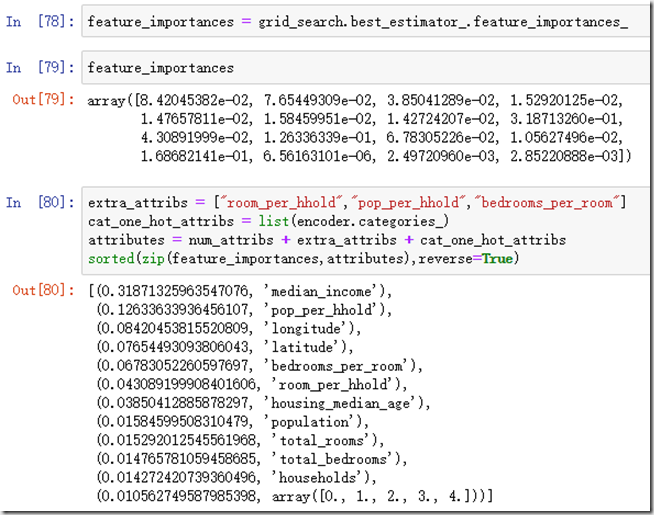
说明一下最下面那个array[]是之前的ocean_proximity属性。
好了,我们微调过后,通过测试集评估系统吧。
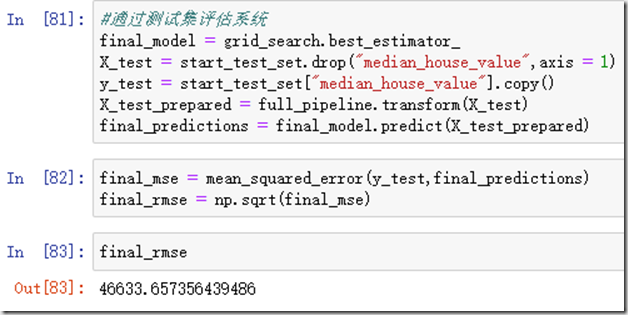
这个结果比之前就好多了!
八、展示解决方案
这里可以通过制作PPT等方式,强调系统学习到了什么、什么属性是有用的、算法基于了什么假设、系统目前存在的限制有什么,用清晰可视化的方式呈现!
九、启动、监控和维护系统
这里就是即将让项目进入实战的环节,这时候应该为生产环境做准备,特别是将生产数据接入系统,当然为了防止出错,我们必须要进行代码测试!
监控代码也要编写,这是为了定期检查系统的实时性能,在性能下降后触发警报!
任何模型几乎都经不起时间的演化,随着时间的演化,适合现阶段的参数可能不是该模型存在的参数,模型会渐渐“腐化”,所以我们应该定期使用新的数据训练模型,让模型保持年轻。同时做好模型备份,防止最新迭代的模型出现错误好马上回滚。
还要注意的是,模型的预测结果需要专家进行分析,确保环节安全。
最后要注意的是要监控输入系统的数据的质量,及时查找出质量较差的数据,防止污染系统。
好啦,我的心得在这里就算总结完毕了。这个总结对我来说,我又重新认识了一遍项目的流程,这个对我收益很大,以后要多多坚持自己的总结,加油呀!
图中代码可通过以下方式获得:
1、我的Github:https://github.com/niufuquan1/MyStudy_For_sklearn_tensorflow
2、百度云分享:https://pan.baidu.com/s/1xjBGBFbM7hqp-tUO3oNEtA (sio0)
转载请注明出处,谢谢!
有任何问题,请在下方留言,博主看到会进行回复。
《机器学习实战(基于scikit-learn和TensorFlow)》第二章内容的学习心得的更多相关文章
- 《机器学习实战(基于scikit-learn和TensorFlow)》第三章内容的学习心得
本章主要讲关于分类的一些机器学习知识点.我会按照以下关键点来总结自己的学习心得:(本文源码在文末,请自行获取) 什么是MNIST数据集 二分类 二分类的性能评估与权衡 从二元分类到多类别分类 错误分析 ...
- 《机器学习实战(基于scikit-learn和TensorFlow)》第四章内容的学习心得
本章主要讲训练模型的方法. 线性回归模型 闭式方程:直接计算最适合训练集的模型参数 梯度下降:逐渐调整模型参数直到训练集上的成本函数调至最低,最终趋同与第一种方法计算出的参数 首先,给出线性回归模型的 ...
- 分享《机器学习实战基于Scikit-Learn和TensorFlow》中英文PDF源代码+《深度学习之TensorFlow入门原理与进阶实战》PDF+源代码
下载:https://pan.baidu.com/s/1qKaDd9PSUUGbBQNB3tkDzw <机器学习实战:基于Scikit-Learn和TensorFlow>高清中文版PDF+ ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
- 机器学习实战:基于Scikit-Learn和TensorFlow 读书笔记 第6章 决策树
数据挖掘作业,要实现决策树,现记录学习过程 win10系统,Python 3.7.0 构建一个决策树,在鸢尾花数据集上训练一个DecisionTreeClassifier: from sklearn. ...
- 集成算法(chapter 7 - Hands on machine learning with scikit learn and tensorflow)
Voting classifier 多种分类器分别训练,然后分别对输入(新数据)预测/分类,各个分类器的结果视为投票,投出最终结果: 训练: 投票: 为什么三个臭皮匠顶一个诸葛亮.通过大数定律直观地解 ...
- machine learn in python 第二章2.1.1
1大约 sklearn.datasets from sklearn.datasets import load_iris import numpy as np data = load_iris() da ...
- DirectX12 3D 游戏开发与实战第二章内容
矩阵代数 学习目标 理解矩阵及其相关运算的定义 探究为何能把向量和矩阵的乘法视为一种线性组合 学习单位矩阵.转置矩阵.行列式以及矩阵的逆等概念 逐步熟悉DirectXMath库中提供的关于矩阵计算的类 ...
随机推荐
- 使用jQuery+huandlebars循环遍历中使用索引
兼容ie8(很实用,复制过来,仅供技术参考,更详细内容请看源地址:http://www.cnblogs.com/iyangyuan/archive/2013/12/12/3471227.html) & ...
- 九、Brideg 桥接模式
设计原理: 代码清单: 抽象类 DisplayImpl public abstract class DisplayImpl { public abstract void rawOpen(); publ ...
- jQueryEasyUI学习笔记
data-options 是jQuery Easyui的一个特殊属性.通过这个属性,我们可以对easyui组件的实例化可以完全写入到html中 data-options="region:'w ...
- 项目总结18-使用textarea无法判断空值之坑
项目总结18-使用textarea无法判断空值之坑 今天使用js判断textarea为空,发现怎么都无法成功仔细做了对比测试,发现结果如下: 1-JS代码 if($("#content&qu ...
- python—切片
切片就是list取值的一种方式 l = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] print(l[1:5]) #取值方式顾头不顾尾 print(l[:5]) #冒号 前面 没写代 ...
- Mysql的时间类型问题
时间类型有time, date, datetime, timestamp 如Mysql官方文档所述: time 没有date,date没有time,datetime是date和time的集合, 而ti ...
- jq怎么给图片绑定上传文件按钮
html代码 <img src="/img/zhengmian.png" alt="" class="file1"> <i ...
- python基础(二)列表与字典
列表list-数组stus=['苹果','香蕉','橘子','红枣',111.122,]# 下标 0 1 2 3 4#下标,索引,角标#print(stus[4]) #st=[]#空list#st=l ...
- Python中操作Redis
一 Rdis基本介绍 redis是一个key-value存储系统.它支持存储的value类型相对更多,包括string(字符串).list(链表).set(集合).zset(sorted set -- ...
- SPS Programming Abrites AVDI or GM MDI
Just information for you to make a wise purchase of GM scan tools for SPS programming: (here, I focu ...