Transport Layer Protocols
1 End-to-end Protocols(端到端协议)
传输层协议往往是主机对主机(host-to-host)或者说是端到端(end-to-end)。通常希望传输层协议可以提供如下service:
1. 保证资料可以成功传输给对方。例如TCP,就是一个非常可靠的protocol,在做文件传输时,必须保证100%正确,因此往往使用TCP。
2. 保证封包原来的顺序。在做文件传输时,资料比较大,需要切割,送达目的地时要保证顺序不能乱掉。
3. 对每一个message最多只收到一份copy。资料传输时可能发生重送,如果Destination重复接收会发生错误,因此Destination只能收到一份copy。
4. 支持任意大小的message。
5. 发送方和接收方可以保持同步的关系。
6. 接收方可以通过flow control来控制发送方的传送。Receiver能不能收封包,完全取决于其的resource,何为resource?Receiver有一个buffer,可以将sender送过来的封包先存起来,buffer的大小就决定了sender可以送多少量进来。因此需要receiver控制sender送出来的流量。
7. 每台Host上可以run不同的application processes。可以run FTP做文件传输、可以run telnet做两端连线、可以run browser、可以看视频等等。Host可以同时跑不同的应用,而Transport Layer也要能够提供这样的服务,当封包进来时,知道是给哪一个application。
虽然传输层希望提供以上这些很好的服务,但是它的下一层Internet本身提供了什么服务呢?
1. message可能会drop。router可能因为overflow,因为阻塞,封包可能会被router丢掉。
2. 封包被切割成小片段后到达Destination的顺序可能会与发送的顺序不同,即先送未必先到。
3. 一个封包发出去,Destination可能会收到不止一份的copy。
4. 封包经过不同网络时,会遇到一个大小限制(MTU)。
5. Deliver message可能会经过一个非常长的delay。
显然,网络层(Network Layer)的服务是Unreliable service。但是我们又希望传输层(Transport Layer)的服务是reliable。因此,传输层最大的挑战是必须有一个方法,使其在不可靠的环境下,提供可靠的服务。

2 Simple Demultiplexer (UDP)
UDP通过不可靠的服务来提供不可靠的服务,因此很容易实现。那既然网络层已经提供了不可靠的服务,为什么在传输层还需要UDP再来实现一遍不可靠的服务呢?因为一个IP Address代表的是某一个Host,而真正需要沟通的是run在Host上的Application,因此同样需要UDP来提供一个process-to-process的service。因此,UDP将Host-to-host的服务更进一步的扩展成了process-to-process的服务。
在一台Host上会有多个process在run,那么当收到封包时,我们怎么知道封包到底要给哪一个process呢?因此需要在UDP中增加了一个demultiplexing的level。
通过IP Address来区分Host,通过Port来区分Application。
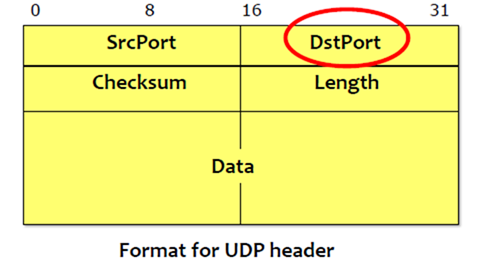
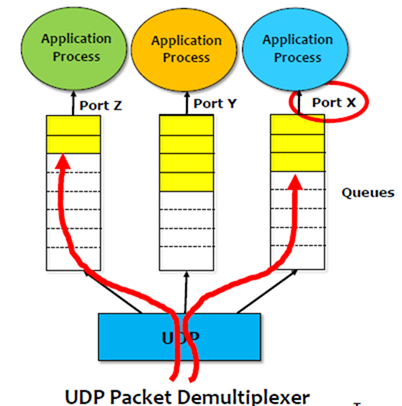
要将message传送给某个process,但是process不见得可以立即处理(涉及CPU调度),因此需要有一个Queue来存储,每一个process都有一个Queue,什么时候process抢占到了cpu,就什么时候去处理这个message。
3 Reliable Byte Stream protocol (TCP)
与UDP相比,TCP提供如下的service:
1. Reliable
2. Connection oriented。Tcp在使用之前必须先建连线。
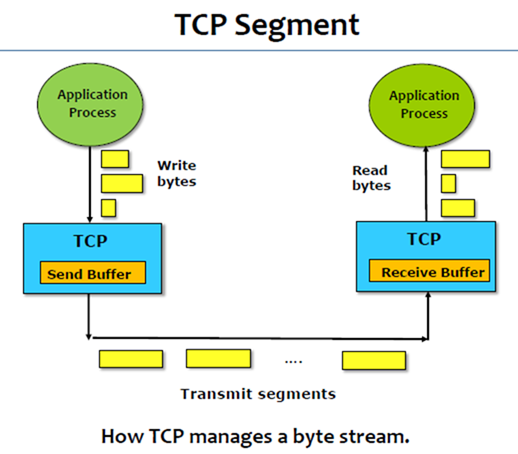
3. Byte-stream service。对于Tcp而言,它所传送的资料是以Byte为单位的,sender上层应用将message丢给Tcp时,可以一段一段资料量的往下丢,例如100个byte100个byte往下丢,可是送到对方,每次上来的数量可以与之前sender下来的数量不一样。 比如sender是100个byte100个byte的下来,但是receiver可以50个byte50个byte的上去,唯一需要保证的是,byte送到的顺序以及总量是正确的。
1 Flow control VS Congestion control
Flow control involves preventing senders from overrunning the capacity of the receivers。接收方决定发送方到底可以送多快。接收方具有资料传送节奏的主导权,避免发送方送的太快,将接收方的buffer塞爆掉。注意,一个Host可以同时Run不同的Application,如果Connection建立起来,通过TCP收message,资料收进来,丢给Application,但是Application可能没有办法立刻处理message(什么时候执行某个Application,是由OS来决定的),因此资料进来先存储在一个buffer(Queue)中,而Application不见得立即可以从buffer中将message拿走处理,自然地,buffer可能会满,此时receiver得告诉sender送慢些。Flow control谈的就是Receiver要有一个机制,来控制从sender过来的流量,避免receiver无法接收message,overflow。
Congestion control involves preventing too much data from being injected into the network, thereby causing routers/switches or links to become overloaded。TCP要面临两个很重要的问题,一是流量控制,二是拥塞控制。拥塞控制考虑的是整个Internet上总共有多少个connection。一台Host可能会建几十上百个连线,那么整个Internet上可能会有几百亿个连线,大家都将封包丢到Internet上,Internet本身就可能发生阻塞。Congestion control就是说,某个Tcp虽然与对方建立了连线,但是如果它传送封包的速度太快,那么不仅仅receiver可能受不了,整个Internet也可能受不了。将封包交给Internet,实际上就是交给Router,封包会自己去绕,如果大家都往Internet上塞大量封包,那么router可能会掉封包。Congestion control就是说避免将过量的封包送入网络,使网络overloaded。
TCP本身必须跟它的receiver维持flow control,同时要对网络做congestion control。flow control比较容易实现,因为receiver可以告诉sender它应该送多快,注意是receiver告诉sender,因此sender可以送多少量是非常清楚的。而Congestion control是一个相对复杂的问题,因为internet(Router)不会告诉sender现在网络是不是拥塞的。
TCP就面临一个挑战,其能否知道现在网络是否拥塞?当然,网络拥塞不是由一个sender造成的,是大量sender送过多的封包导致的。因此,TCP自己必须有一个方法来告诉自己,现在网络是否是阻塞,如果是阻塞的,那么我就送慢些。(实际上如果发生掉封包了,就说明了网络可能发生了拥塞,如果掉的封包很多,那么说明网络可能阻塞的很严重)
2 End-to-end Issues
TCP本身想要沟通的对象,往往在网络的最边缘,称为end-to-end,因此TCP一般是跑在电脑、server或者手机上的。
TCP runs over the Internet rather than a point-to-point link。Tcp是run在整个internet上的,而非点对点的link,我们之前介绍的滑动窗口算法是用来保证point-to-point传输的可靠性。而TCP sliding window algorithm需要考虑的更多:
1. TCP supports logical connections between processes that are running on two different computers in the Internet。连线只是逻辑上的关系,因为封包在internet上传送时,会根据Routing Table走不同的路。
2. TCP connections are likely to have widely different RTT times。连线的Round Trip Time可能会很不同。这要看与之通信对象的位置,如果通信对象就在隔壁,那么RTT就会很短,如果通信对象在地球的另一端,那么RTT自然就会很长。因此,同样是建TCP连线,不同的连线之间封包来回的时间差异可能会非常大。还需看网络拥塞的情况,不同网络间封包传送的速度等等。
3. Packets may get reordered in the Internet。
4. TCP needs a mechanism using which each side of a connection will learn what resources the other side offers to the connection。TCP需要一个机制来知道连线的另一方会提供怎样的resource,这就涉及到了flow control。对方提供怎样的resource为什么要让我们知道?至少要让我们知道对方的buffer有多大。
5. TCP needs a mechanism using which the sending side will learn the capacity of the network。同样,TCP也需要有一个机制来让发送方学到网络的容量是多少,这涉及到Congestion control。如果现在的网络比较拥塞,那么capacity就比较小,否则,capacity就较大。
3 TCP Segment
1. TCP is a byte-oriented protocol.
2. The sender writes bytes into a TCP connection and the receiver reads bytes out of the TCP connection.
3. However, TCP does not transmit individual bytes over the Internet. TCP本身不会一个一个byte的发送,因为对一个byte封装成封包很浪费,因此TCP会先将资料收集起来,也就是将上层交给它的资料buffer起来。
4. The source TCP buffers enough bytes from the sending process to fill a reasonably sized packet and then sends this packet to its peer on the destination host. 当TCP buffer到了一个合理size的packet,就可以将该封包丢出去。
5. The destination TCP then puts the contents of the packet into a receive buffer, and the receiving process reads from this buffer.
Destination同样有一个buffer,将封包收进来,等buffer足够量大时,通知Application来取走资料。
6. The packets exchanged between TCP peers are called segments. Tcp在网络中传送的单位称为segment。
4 Tcp Header
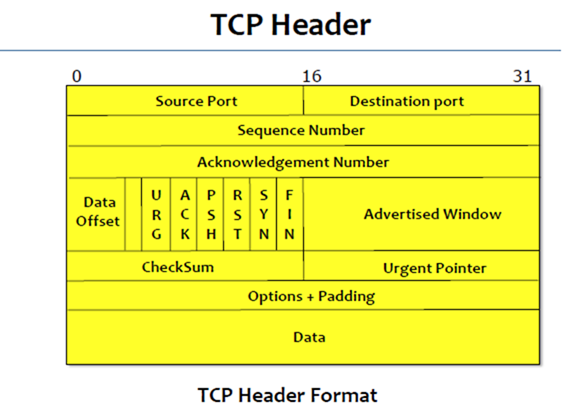
Sequence Number:长度为32bit。Sliding Window本身会将每个封包编号,有了sequence number之后我们才知道封包有没有重复接收。receiver有个receiver sliding window,如果封包的sequence number没有落在receiver sliding window这个视窗中,那么不会接收这个封包,因为可能重复了。在layer 2的link上所用到的Sliding Window algorithm所用到的sequence number,是针对每一个封包,每一个封包都有一个sequence number。然而,TCP是byte-oriented protocol,单位是每一个byte,因此sequence number也必须细到每一个byte。如下图:
----------------------------------------------------------------
Data
----------------------------------------------------------------
编号: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16…
Data是一个byte stream,我们对Data本身分割在哪边并不care,因为切在哪边都无所谓。一个封包将这些内容送完,还是两个封包、三个封包送完,都无所谓,但是你必须告诉我Data带的第一个byte的sequence number到底是多少,因此TCP的sequence number是说被分割的某个封包所携带的Data的第一个byte在整个资料的byte stream中的sequence number。sender将这个资料发送过去后 ,对方可以知道这个封包的sequence number是多少,同时又有封包长度的信息, 因此可以知道封包有多大。
Acknowledgement Number:长度为32bit。送过去的封包会带sequence number,回来的封包会带acknowledge number,告诉对方说acknowledge number以前的封包通通收到了,这就是所谓的accumulative acknowledge,这个number以前的我通通收到了,这个number以后的我还在等。
6个flag(URG、ACK、PSH、RST、SYN、FIN):
TCP在通讯之前必须先把连线建立起来,如何判断一个封包是否要建连线呢?看SYN(synchronous),代表要建连线,这个bit设为1,说明要建连线。
如何取消连线呢,看FIN(finish),如果对方送来的封包的这个bit设为1,说明对方要将这个连线close掉。
ACK(Ackmowledgement)设为1,代表这个封包的Acknowledgement number的值是有意义的。
连线建立之后开始送Data,只要有一端觉得连线的状况有异常,比如TCP hijack(网络黑客进行TCP劫持,明明双方建立了连线,但是被黑客拦截下来,送一些奇怪的东西给我们),就可以设置RST(reset)把连线切断,之后再重设。
Sender在发送封包时,往往先将资料丢给sender buffer,等sender buffer累积到一个较大的量后,才会送出segment到网络上。因此,如果sender buffer中累积的data不够多时,TCP暂时就不会将其打包发送到网络上。PSH(push)的意思就是说强制将buffer中的内容清空(无论Datad的量是多还是少)打包送到网络中。 到达receiver buffer后,receiver看到PSH被设为1了,也会强制交给Application。
URG(urgent)这个bit设为1,说明资料中带有紧急的内容,不是正常的Data,通常是一些控制信息要带给对方。那么urgent data到底在Data中的哪里呢?urgent pointer所指位置之前,均为urgent data,所指位置之后为普通的data。
Advertised Window:16个bit。可以表示65536个byte。该栏位专门用来做flow control,receiver会告诉sender你可以送多少量的资料过来,具体数值就放在Advertised Window中。receiver可以告诉sender,最多最多你可以送过来的量是65536(64K)。64K的byte送完之后,sender就必须停下来,等receiver再给它这个量。注意,这个量只是做flow control,而不是做congestion control,receiver控制sender传送的量。congestion control并没有在TCP header中,它要靠另外的方式。
CheckSum:TCP在传送时也会受到一些干扰,因此需要检查header到底有没有错。CheckSum检查完之后,如果发现是错误的,那么这个封包就会丢掉。丢掉,一定要让对方重送,因为我们要的是reliable的service。CheckSum本身除了对TCP header做检查之外,也会把IP header的某一些栏位(source address, destination address, and length fields from the IP header)一起加进来做检查。
5 TCP Connection Management
TCP sender, receiver establish “connection” before exchanging data segments。TCP在正式送Data之前,必须先建立connection。
Initialize TCP variables:
1)Sequence numbers
2)Buffers, flow control info (e.g. RcvWindow(advertised window))
在建connection时,需要带上sequence number,因为TCP是byte-stream oriented的protocol;同时自己要保留buffer,因为等会就会收对方送过来的data。
建连线必然要由一端来发起,通常连线的发起者是client,而server等着别人来建连线。
// Client: connection initiator
Socket clientSocket = new Socket("hostname","port number");// Server: contacted by client
Socket connectionSocket = welcomeSocket.accept();
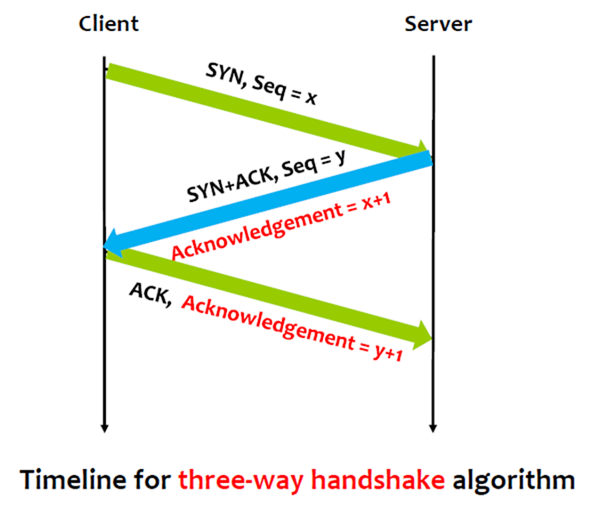
TCP使用“三次握手”建立连线。

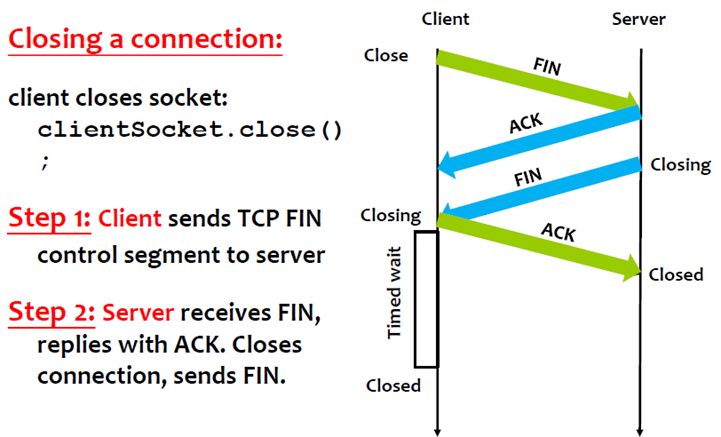
四次挥手解除连线。
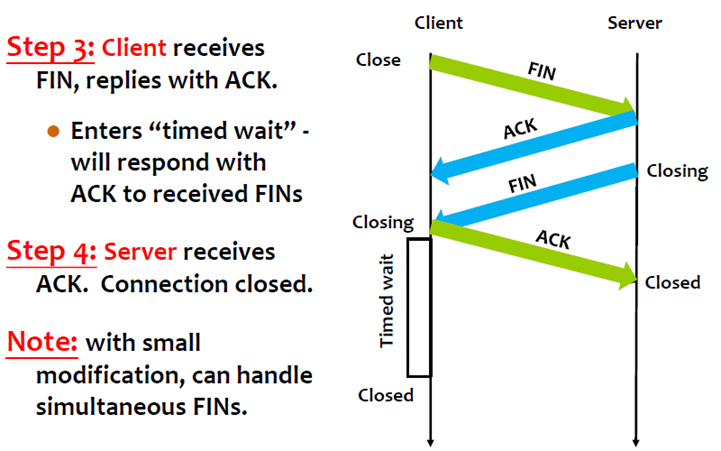
注意,client收到FIN并发出Ack后,还要再等一段时间(通常是30秒)才会close连线,因为可能还有一些封包还在网络中传送。
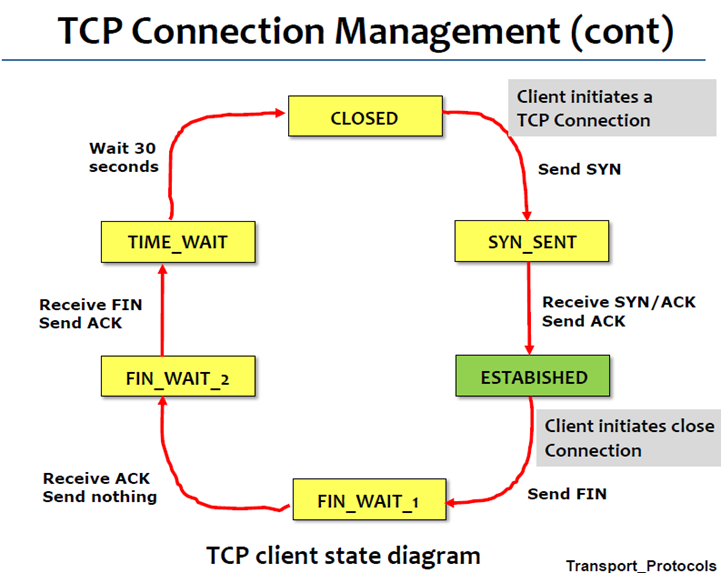
以下为状态图:
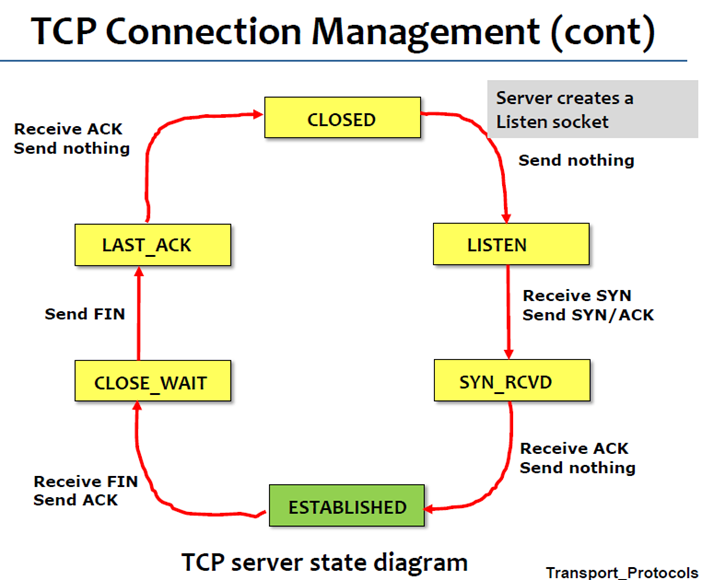
6 Timeout value for Retransmission
TCP本身提供reliable transmission,每一个封包送出去的时候都会设置一个Timer,期望在timeout之前收到对方的acknowledgement。Timer本身的设计很重要,如果Timer设的太短,可能送出去的封包的acknowledgement还没有回来就timeout了(一个RTT),这样会引发不必要的retransmission;如果Timer设的太大,(无论是送出去的封包掉了,还是送回来的针对该封包的acknowledgement掉了,都是等timeout)那么如果封包(或者acknowledgement掉了)真的掉了,我们就需要等很久(等timeout)才会知道,进而retransmission。
一个封包出去,一个acknowledgement回来,这样一个来回的时间并非一个常量,这与网络状况有关。如果网络状况良好,那么来回的时间会相对较短,如果网络拥塞或者一个封包被绕远路了,那么来回的时间会相对较长。那么,我们是否可以根据网络的状况来衡量Timer呢?

我们可以测量每一个segment/ACK pair(封包出去,然后acknowledgement回来)来回的时间,记为SampleRTT。既然,SampleRTT并非一个常数,那么我们就来计算weighted average of RTT:
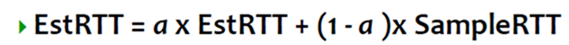
现在的RTT等于过去的RTT乘上一个权重+最后的RTT乘上一个权重。为了保险起见,我们将Timeout设为RTT的两倍。
这样做也可能会产生问题。如果timeout,就会重送封包,但是sender无法判断回来的acknowledgement,是重送封包的还是之前超时封包的(之前超时封包的acknowledgement可能由于delay还在网络中),因此就无法得出此次SampleRTT。来看下图:
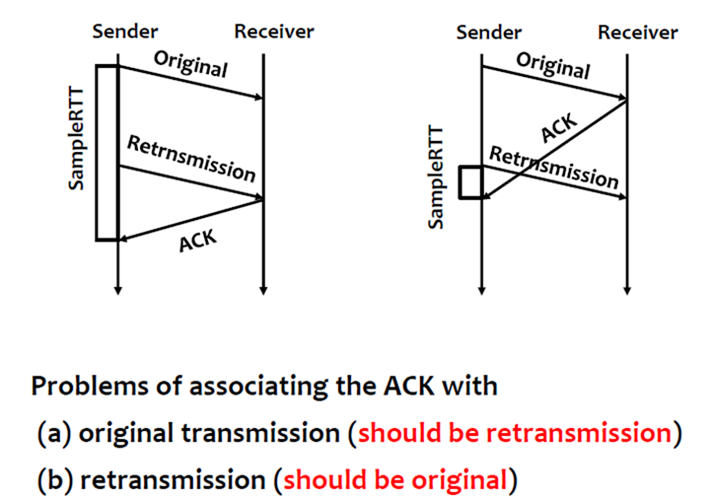
左边的图:如果ACK和Original封包作为一个SampleRTT显然不合适。
右边的图:如果ACK和Retransmission封包作为一个SampleRTT显然也是不合适的。
因此问题就在于当我们收到一个Acknowledgment时,我们并不知道是原始封包的,还是重送封包的。
7 Karn/Partridge Algorithm
由于以上的问题,所以就有人提出了Karn/Partridge Algorithm。

如果做retransmitting,那么这一次就不要sample RTT了,因为这个时候我们根本无法正确得出SampleRTT。每一次做retransmission,就double timeout,因为做retransmission意味着发生了timeout,为什么timeout?封包可能掉了或者delay。为什么封包掉或者delay?因为网络可能发生了阻塞。既然网络可能发生了阻塞,那么就将timeout再放长些,让封包在网络上呆久些。
该方法本身对原来的方法有些改善,但是还是没有办法来消除congestion。我们要消除网络的congestion,就要明白timeout的值的设定到底与congestion有什么样的关联。如果将timeout的值设的过小,会造成不必要的retransmission,这些retransmission反而会造成网络更拥挤。
以上方法的问题在于计算EstimatedRTT时没有考虑到SampleRTTs的变化。如果SampleRTTs变化较小,说明网络很稳定,那么EstimatedRTT的值是可以信任的,那么在timeout时也不用乘以2倍,免得浪费timeout的时间;如果SampleRTTs变化较大,说明网络并不稳定,那么timeout的值不可以与EstimatedRTT的值关联的太过紧密。
8 Jacobson/Karels Algorithm
基于以上观点,我们需要把SampleRTTs的variance考虑进来,因此就有了Jacobson/Karels Algorithm,方法就是测量variance。

Difference = SampleRTT − EstimatedRTT,difference的值就是将最后一次测到的SampleRTT与过去测到的EstimatedRTT之差。
EstimatedRTT = EstimatedRTT + (d × Difference),Difference 可正可负,因此EstimatedRTT可能比原来小,也可能比原来大。
Deviation = Deviation + d (|Difference| − Deviation),偏差,代表了variance。
Timeout的计算就由上图黄颜色部分得出,显然,当variance(Deviation)很小时,EstimatedRTT主导了timeout,当variance很大时,Deviation主导了Timeout。
9 TCP retransmission scenarios
来看以下几种情况:
1. Lost ACK
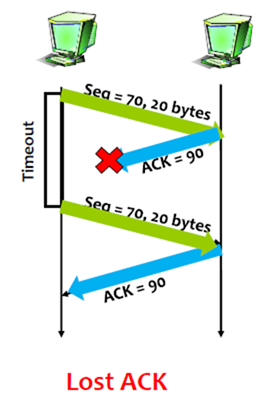
很简单,如果ACK丢了,那么sender端超时后,会重送封包。在上图中,sender发出的封包sequence number为70,size为20个byte,说明传送序号70-89这些字节,receiver回复的acknowledgment为90,代表序号90之前的封包(字节)都收到了,现在期待sequence number为90的封包。
2. Delayed ACK
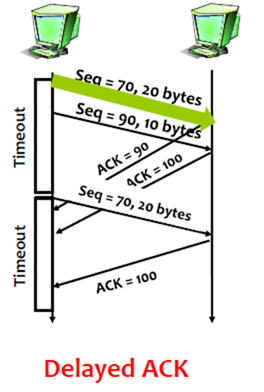
Seq为70的封包的acknowledgment由于delay导致sender端timeout,因此重送Seq为70的封包。因为是cumulative ACKs,既然之前Seq为70的封包已经到达了receiver端(虽然回复的ACK延迟了),那么Seq为90的封包的acknowledgment就回复100,代表100之前的封包都收到了。Seq为70的重送的封包,根据cumulative ACKs,此时回的acknowledgment同样也为100。
3. Cumulative ACKs
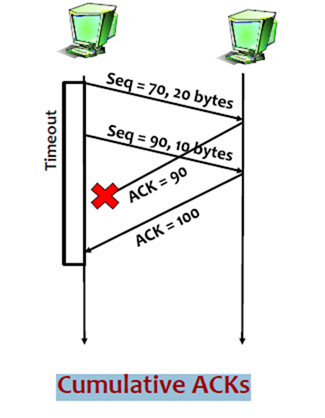
如果Seq为70的封包的acknowledgment直接掉了,但是在timeout期间,Seq为90的封包的acknowledgment回复了,那么receiver就直接回复acknowledgment为100的ACK,代表seq为100之前的封包都已经收到了。
10 TCP Fast Retransmission
TCP Fast Retransmission:如果封包在timeout这段时间内已经lost了,那么是否有办法提前知道从而retransmission,而不是等到timeout呢?
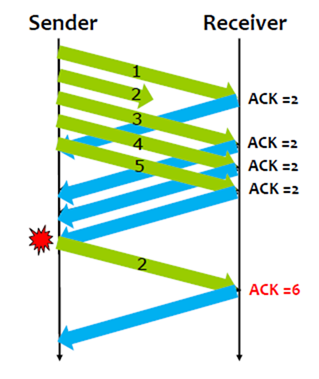
每次一个封包从发送端到达接收端,receiver都会回一个acknowledgment,即使带有这个序号封包的acknowledgment已经回过了。因此,如果封包到达接收端out of order,TCP会重送它之前所发的最后一个acknowledge。第二次重送的相同的acknowledgment称为duplicate ACK。
当发送端看到一个重复的ACK(duplicate ACK)时,它必然知道接收端收到一个out of order的封包,这意味着一个序号更靠前的封包可能lost了。当然,这个序号更靠前的封包可能只是发生了delay而非lost,因此sender只会在看到更多duplicate ACK时才会retransmit这个封包。
TCP waits until it has seen three duplicate ACKs before retransmitting the packet.
4 TCP Congestion Control
1 Introduction
TCP Congestion Control的idea在于:当TCP连线建立后,需要知道针对每一个连线网络允许的capacity,这样连线才能以合适的速度发送封包。如果真的发生了拥塞,也需要有办法知道网络发生了拥塞,随后自行调整,放慢传输速度。总结下,Congestion Control的机制就在于两点:一是怎么知道网络发生了拥塞,二是发生了拥塞后怎么调整。
由于TCP通讯的机制依赖于acknowledgment,如果acknowledgment都能流畅且正确的送达,那么封包会越送越多;如果网络发生了拥塞(发生拥塞会表现为两种情况:一是掉封包,而是封包被延迟送达发生timeout),就需要降速。因此,无论封包传送的快或是慢,都是根据acknowledgment。
2 AIMD
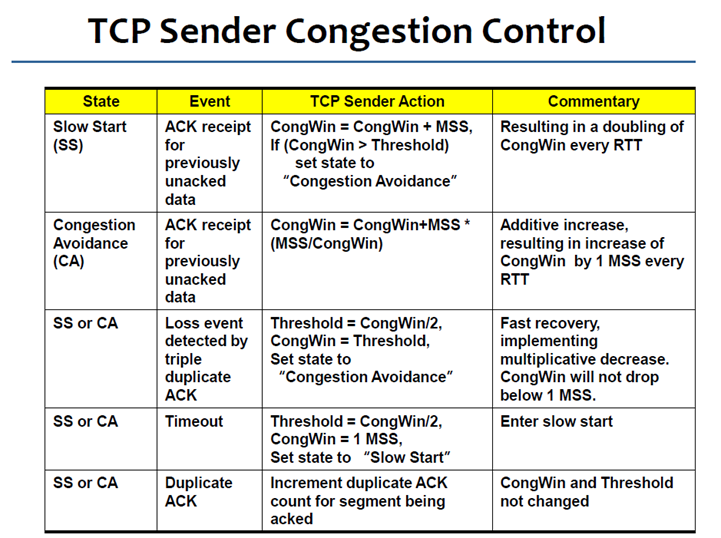
TCP Congestion Control中有一个重要的机制称为Additive Increase Multiplicative Decrease (AIMD)。连线刚建立时,此时并不知道网络的状态,就慢慢的加速(Additive Increase,线性加速),如果网络发生了阻塞(记得之前的three duplicate ACKs可以判断网络发生阻塞吗?另一种情况,如果发生timeout,可能网络阻塞的更严重,因为连acknowledgment都收不到了),速度马上减一半(Multiplicative Decrease )。
Congestion Window: used by the source to limit how much data it is allowed to have in transit simultaneously for a connection. Congestion Window是网络可以让sender送的量,用来限制sender在同一时间可以送多少量出去,从而控制congestion。
The congestion window is congestion control’s counterpart to flow control’s advertised window.
The maximum number of bytes of unacknowledged data allowed is now the minimum of the congestion window and the advertised window.Sender要将封包丢到网络中去,受两方面的影响,一是网络拥挤的程度,二是receiver buffer有多大。因此,在每个连线中sender到底可以送多少量到网络中去,取决于congestion window和advertised window之中的较小值。

上图中,EffectiveWindow是考虑之前已经用掉了MaxWindow中的一部分。注意,AdvertisedWindow是receiver告诉sender的,而CongestionWindow是sender自己获得的(注意网络不会告诉sender,CongestionWindow是多少,这个值必须由sender自己找出来)。

因此,CongestionWindow的值是sender自己观察网络状况得出的,最初的初始值设为MSS(TCP中最大segment的值,注意仅仅是Data域,不包括TCP header,MSS的值与主机所连的网络相关,如果是以太网,就是1500byte),之后遵循AIMD。

那么,TCP连线根据什么来判断网络是否拥挤呢?如果发生了所谓的three duplicate ACK,可能发生了packet lost,sender此时就将CongestionWindow变成原来的一半。来看以下一个例子:

事实上CongestionWindow的定义是以byte为单位的,但是有一个限制,最小不能CongestionWindow少于一个封包(用TCP的术语来说,就是不能小于MSS)。以上,我们已经知道CongestionWindow是如何减少的,下面来看看CongestionWindow是如何增加的。

如果在上一个RTT的时间内封包传送的很流畅,没有发生congestion,即所有封包都成功收到了acknowledgment,那么就将CongestionWindow加一个封包的大小(实际上就是一个MSS)。如果网络流畅,那么每经过一个RTT,CongestionWindow就加一个封包的大小。如下图所示:
一开始CongestionWindow为1个封包的量,
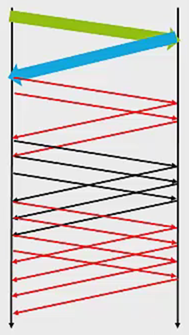
之后经过一个RTT,变成CongestionWindow变成2个封包的量,
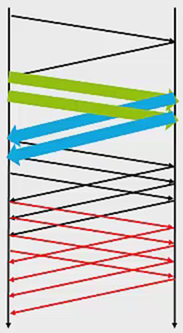
再然后是3个封包的量:
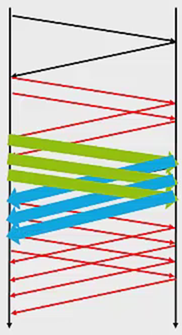
最后是4个封包的量:
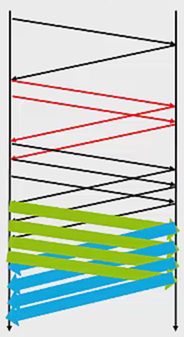
以上只是模拟,事实上TCP不会等一个CongestionWindow的所有acknowledgment都收到,才给CongestionWindow增加一个封包的量,而是每收到一个acknowledgment就先加一部分(CongestionWindow可以较早滑动)。例如,CongestionWindow = 5 * MSS,每收到一个acknowledgment就先加1/5MSS;如果,CongestionWindow = 8 * MSS,每收到一个acknowledgment就先加1/8MSS。
下图可以清晰的表明AIMD:
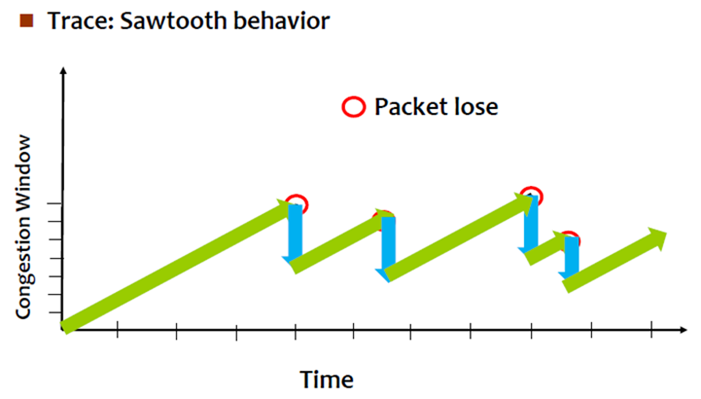
刚开始CongestionWindow的值为1,随着时间的增加CongestionWindow也慢慢增加,但是如果遇到封包lost(收到3的duplicate ACK),CongestionWindow的值就直接往下降一半。
3 Slow Start
TCP Congestion Control中还有一个非常重要的机制叫做Slow start。
当TCP传送的速度已经接近网络的上限(CongestionWindow的上限)时,用AIMD来线性的慢慢逼近网络的上限是合适的。但是,AIMD的问题在于当connection刚开始的时候,网络可能非常宽松,也就是说CongestionWindow应该较大,如果这个时候线性增长,时间花费太久。因此,我们希望在连线刚建立时,加速可以快些,这就是Slow start。

Slow start开始以指数级别的加速(油门踩到底,赶快加上去)。具体做法如下图:

AIMD,是每一个RTT,加一个MSS,而Slow start是每一个ACK,加一个MSS。想象一下,1个ACK之后封包变2个,2个ACK之后封包变4个,4个ACK之后封包变8个…指数级别的增长(每经过一个RTT,CongestionWindow的值就翻倍),这样虽然一开始的传输速度很慢,但是会以指数级别快速增长。
但是,注意无论是AIMD的线性增加,还是Slow Start的指数增加,都会遇到网络传输速度的上限。有什么方式可以判断这个上限呢?
1. after 3 dup ACKs
这个之前已经介绍过。遇到3个重复的ACK,我们认定packet lost,此时会将CongestionWindow减半,之后再线性的增加。
2. But after timeout event
一个特别的地方就是遇到了timeout。我们已经知道3个重复的ACK,代表网络只是偶尔掉一个封包,它还有能力来继续传送,因此我们将CongestionWindow减半,之后再增加。但是,如果发生了timeout(timeout这段时间内,连ACK都收不到了),说明网络阻塞的情况是比较严重的,此时Congestion Window不是减半,而是直接减到只有一个封包的量。之后再用Slow start的继续增长,增长到threshold(之前发生timeout的CongestionWindow值的二分之一)之后,再以线性增长。
具体如下所示:

4 summary
真正的TCP Congestion Control需要结合AIMD与Slow Start两种方式,如下图:

下图清晰的反应了TCP Congestion Control是如何运作的:
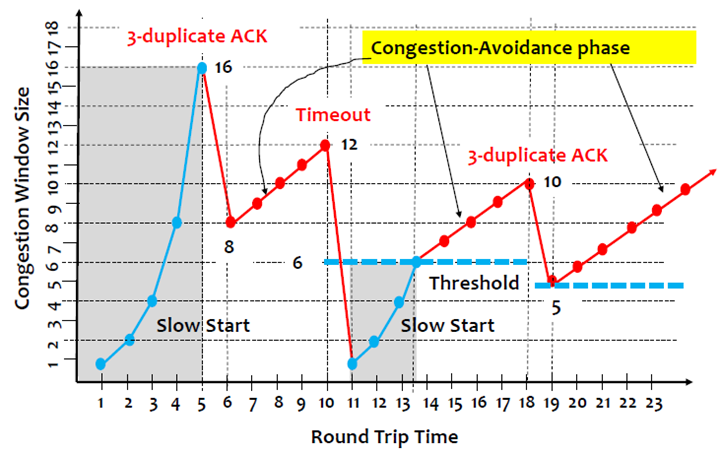
下图是各个状态的一些解释:
以下为TCP throughput:
就是看一个RTT内能传多少量。

5 本文总结
1. We have introduced how to convert host-to-host packet delivery service to process-to-process communication channel.
2. UDP for unreliable transmission service.
3. TCP for reliable transmission service。
1) 3-way handshaking connection establishment.
2) TCP connection state diagram.
3) TCP timeout value calculation.
4) TCP retransmission scenarios.
5) TCP fast retransmission.(真等timeout时间太久,因此如果发生3-dup ACKs就判定packet lost,就retransmission)
4. TCP Congestion Control
1) AIMD (additive Increase Multiplicative Decrease)
2) Slow start
3) 3-duplicate ACKs (packet lose)
4) Timeout
Transport Layer Protocols的更多相关文章
- [Network]Transport Layer
1 Principles behind Transport Layer Services 1.1 Multiplexing/Demultiplexing Multiplexing at sender ...
- Transport layer and Network layer
http://stackoverflow.com/questions/13333794/networking-difference-between-transport-layer-and-networ ...
- Host Controller transport layer and AMPs
The logical Host Controller Interface does not consider multiplexing/routing over the Host Controlle ...
- 传输层-Transport Layer(上):传输层的功能、三次握手与四次握手、最大-最小公平、AIMD加法递增乘法递减
第六章 传输层-Transport Layer(上) 6.1传输层概述 在之前的几章内容中,我们自底向上的描述了计算机网络的各个层次,还描述了一些处于不同层次下的经典网络协议(如以太网.无线局域网.或 ...
- 传输层-Transport Layer(下):UDP与TCP报头解析、TCP滑动窗口、TCP拥塞控制详解
第六章 传输层-Transport Layer(下) 上一篇文章对传输层的寻址方式.功能.以及流量控制方法做了简短的介绍,这一部分将介绍传输层最重要的两个实例:TCP协议和UDP协议,看一看之前描述的 ...
- Elasticsearch client node 启动时出现警告:exception caught on transport layer 及java.net.NoRouteToHostException: No route to host
发现该问题源自发现kibana不能打开sense,并且看见elasticsearch插件处于服务不可用状态,但是在client node上curl localhost:9200发现能够返回ES基本信息 ...
- 计算机网络自顶向下方法第3章-传输层 (Transport Layer).1
3.1 概述和运输层服务 运输层协议为运行在不同主机上的应用进程之间提供了逻辑通信(logic communication)功能. 3.1.1 运输层和网络层的关系 网络层提供了主机之间的逻辑通信,而 ...
- 计算机网络自顶向下方法第3章-传输层 (Transport Layer).2
3.5 面向连接的运输: TCP 3.5.1 TCP连接 TCP是因特网运输层的面向连接的可靠的运输协议. TCP连接提供全双工服务(full-duplex service). TCP连接是点对点的连 ...
- Creating Your Own Server: The Socket API, Part 1
转:http://www.linuxforu.com/2011/08/creating-your-own-server-the-socket-api-part-1/ By Pankaj Tanwar ...
随机推荐
- Openface 入门
Openface 简单入门 背景 Openface是一个开源的人脸识别框架,同类软件产品还有 seetaface ,DeepID等,当然,如果算上商业的产品,那就更多了. Openface人脸比对结果 ...
- jquery与原生JS实现增加、减小字号功能
预览效果: 实现代码: <!DOCTYPE html> <html lang="en"> <head> <meta charset=&qu ...
- 简单快捷使用Git
1.简介和安装Git是世界上目前最先进的分布式版本控制系统.安装:https://git-for-windows.github.io下载.设置姓名和email:git config --global ...
- leetcode72
class Solution { private: ][]; public: int minDistance(string word1, string word2) { int len1 = word ...
- leetcode155
public class MinStack { Stack<int> S = new Stack<int>(); /** initialize your data struct ...
- leetcode394
class Solution { public: string decodeString(string s) { stack<string> chars; stack<int> ...
- 深度学习原理与框架-递归神经网络-RNN网络基本框架(代码?) 1.rnn.LSTMCell(生成单层LSTM) 2.rnn.DropoutWrapper(对rnn进行dropout操作) 3.tf.contrib.rnn.MultiRNNCell(堆叠多层LSTM) 4.mlstm_cell.zero_state(state初始化) 5.mlstm_cell(进行LSTM求解)
问题:LSTM的输出值output和state是否是一样的 1. rnn.LSTMCell(num_hidden, reuse=tf.get_variable_scope().reuse) # 构建 ...
- sql查询语句for xml path语法
[原地址] for xml path作用:将多行的查询结果,根据某一些条件合并到一行. 例:现有一张表 执行下面语句 select Department, (SELECT Employee+',' F ...
- C#对接JAVA系统遇到的AES加密坑
起因对接合作伙伴的系统,需要对数据进行AES加密 默认的使用了已经写好的帮助类中加密算法,发现结果不对,各种尝试改变加密模式改变向量等等折腾快一下午.最后网上查了下AES在JAVA里面的实现完整代码如 ...
- js原型继承四步曲
<sctript> //1.创建父类 function Parent(){ this.name = name; } Parent.prototype.age = 20; //2.创建子类 ...