论文笔记: Mutual Learning to Adapt for Joint Human Parsing and Pose Estimation
Mutual Learning to Adapt for Joint Human Parsing and Pose Estimation
2018-11-03 09:58:58
Code: https://github.com/NieXC/pytorch-mula
Related Paper: Deep mutual learning Code: https://github.com/YingZhangDUT/Deep-Mutual-Learning
1. Background and Motivation:
本文提出一种模型 MuLA(Mutual Learning to Adapt)来调整模型,来更好的完成行人解析和姿态估计的问题。之所以会这么做,是因为这两个任务是可以相互协助,互相补充的:Human pose can offer structured information for body part segmentation and lebelling, and on the other hand human parsing can facilitate localizing body joints in difficult scenarios,如图 1 所示:

图 1 给出了案例,考虑到这两个任务之间的 mutual guidance information,可以有效的协助改善 parsing 和 localization 的精度。
受到该观察的启发,已经有工作开始借助这种引导信息,来改善这两个任务的性能。但是,现有的方法通常分别训练一个特定的模型,并且用这种引导信息来作为后期处理,从而有如下几个劣势:
1). 严重依赖于手工设计的特征;
2). 仅在 inference procedure 利用该 guidance information,而在 training stage 并没有增强模型的 capacity;
3). 前人工作都是 one-stop solutions,而不能迭代的增强模型,从而改善结果;
4). 这些模型都不是 end-to-end learning。
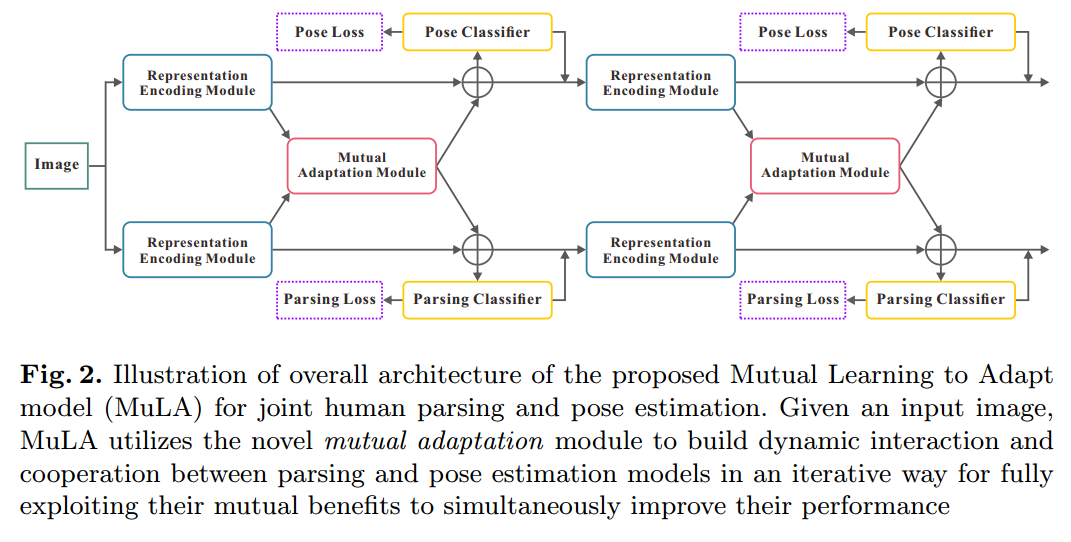
为了解决上述问题,本文提出一种 Mutual Learning to Adapt (MuLA)model 来充分,系统的探索 mutual guidance information。流程图如下所示,该 Mutual Adaptation Module 可以是一个迭代的过程,从而可能会学习到更好的表达。
2. The Details of MuLA:
本文采用 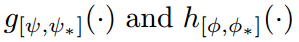 来表示 parsing 和 pose models。带有星号 * 的下标表示 the parameters are adaptable to other task。然后本文所提出的 MuLA 模型可以表达成如下迭代学习的形式:
来表示 parsing 和 pose models。带有星号 * 的下标表示 the parameters are adaptable to other task。然后本文所提出的 MuLA 模型可以表达成如下迭代学习的形式:
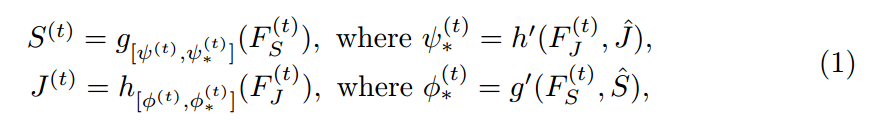
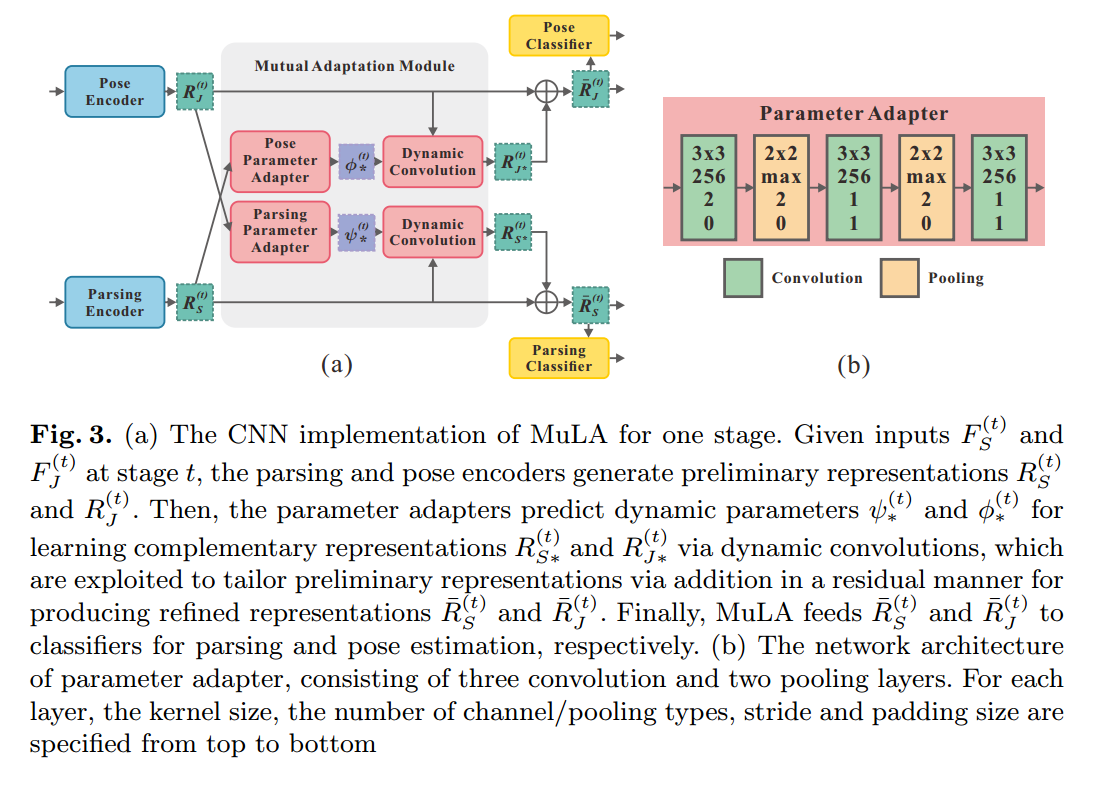
其中,t 表示的迭代次数。$\hat(S)$ 和 $\hat{J}$ 是 parsing 和 pose annotations,F 表示提取出来的特征。如图 2 所示,MuLA 是由三个部分构成的:a representation encoding module, a mutual adaptation module and a classification module。 具体来说,the representation encoding module 是由两个 encoders 对特征进行转换,得到 high-level preliminary representations。the mutual adaptation module 的目标是调整参数,通过两个任务的辅助引导信息,使其增强原始的特征表达。受到 “Learning to Learn” framework 的启发,为了达到快速和高效的 adaptation,在函数 g'(*), h'(*) 的内部,我们设计了两个可学习的 adapters 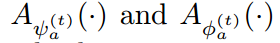 ,来学习预测这些 adaptive parameters。对于可靠和鲁棒的参数预测,我们从
,来学习预测这些 adaptive parameters。对于可靠和鲁棒的参数预测,我们从 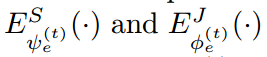 中得到最高层的表达,作为 mutual guidance information。也就是说,所设计的两个 adapters
中得到最高层的表达,作为 mutual guidance information。也就是说,所设计的两个 adapters 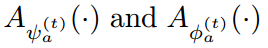 将特征作为输入,然后输出调整后的参数,即:
将特征作为输入,然后输出调整后的参数,即:
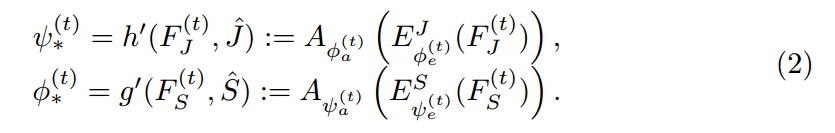
此处,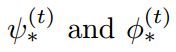 可以通过结合两个任务之间的互引导信息(mutual guidance information),制作原始的表达,以得到更好的解析和姿态估计的结果,并且用
可以通过结合两个任务之间的互引导信息(mutual guidance information),制作原始的表达,以得到更好的解析和姿态估计的结果,并且用 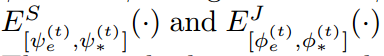 来解码推导出来的 adaptive encoders in MuLA。The mutual adaptation module allows for dynamic interaction and cooperation between two tasks within MuLA for fully exploiting their mutual benefits。
来解码推导出来的 adaptive encoders in MuLA。The mutual adaptation module allows for dynamic interaction and cooperation between two tasks within MuLA for fully exploiting their mutual benefits。
MuLA 利用两个分类器根据 mutual adaptation module 来预测行人解析结果 $S_{(t)}$ 和姿态估计结果 $J_{(t)}$。为了迭代的探索 mutual guidance information,我们设计了两个 mapping modules 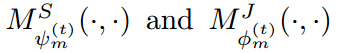 来特征表达以及预测结果映射到下一个阶段的输入,即:
来特征表达以及预测结果映射到下一个阶段的输入,即:
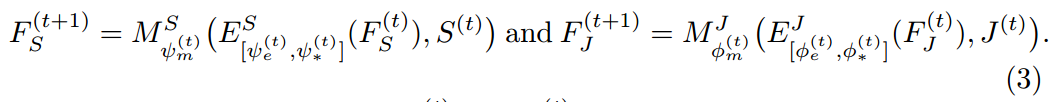
为了训练 MuLA,我们在 human parsing 和 pose estimation 的任务上利用 GT 监督信息,并且定义了如下的损失函数:
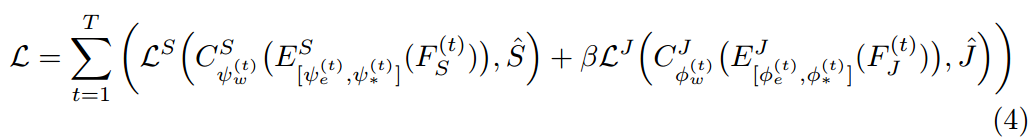
其中,T 是 MuLA 的总迭代次数。第一个和 第二项损失函数,分别是 human parsing 和 pose estimation 的损失函数。
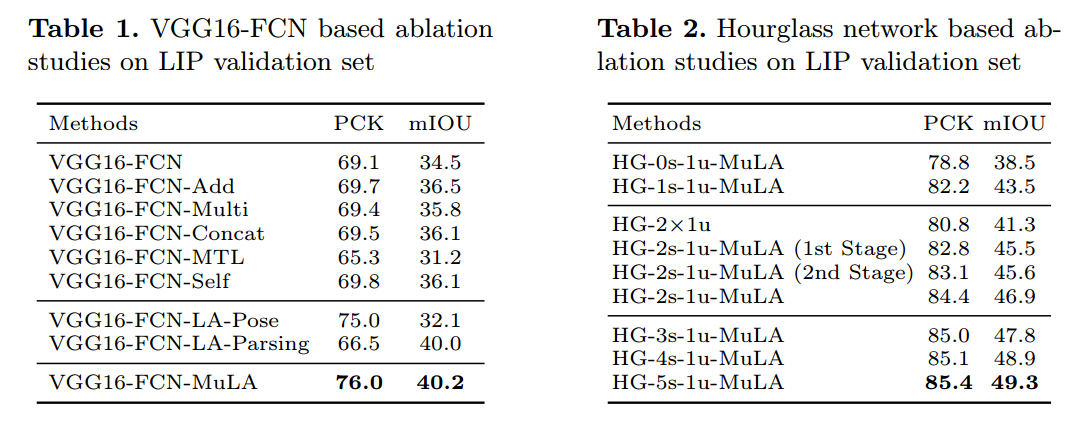
3. Experimental Results:
==
论文笔记: Mutual Learning to Adapt for Joint Human Parsing and Pose Estimation的更多相关文章
- 【论文笔记】Learning Fashion Compatibility with Bidirectional LSTMs
论文:<Learning Fashion Compatibility with Bidirectional LSTMs> 论文地址:https://arxiv.org/abs/1707.0 ...
- 论文笔记: Deep Learning based Recommender System: A Survey and New Perspectives
(聊两句,突然记起来以前一个学长说的看论文要能够把论文的亮点挖掘出来,合理的进行概括23333) 传统的推荐系统方法获取的user-item关系并不能获取其中非线性以及非平凡的信息,获取非线性以及非平 ...
- 深度学习论文笔记-Deep Learning Face Representation from Predicting 10,000 Classes
来自:CVPR 2014 作者:Yi Sun ,Xiaogang Wang,Xiaoao Tang 题目:Deep Learning Face Representation from Predic ...
- 论文笔记:Learning wrapped guidance for blind face restoration
这篇论文主要是讲人脸修复的,所谓人脸修复,其实就是将低清的,或者经过压缩等操作的人脸图像进行高清复原.这可以近似为针对人脸的图像修复工作.在图像修复中,我们都会假设退化的图像是高清图像经过某种函数映射 ...
- SfMLearner论文笔记——Unsupervised Learning of Depth and Ego-Motion from Video
1. Abstract 提出了一种无监督单目深度估计和相机运动估计的框架 利用视觉合成作为监督信息,使用端到端的方式学习 网络分为两部分(严格意义上是三个) 单目深度估计 多视图姿态估计 解释性网络( ...
- 论文笔记:Learning Attribute-Specific Representations for Visual Tracking
Learning Attribute-Specific Representations for Visual Tracking AAAI-2019 Paper:http://faculty.ucmer ...
- 论文笔记:Learning regression and verification networks for long-term visual tracking
Learning regression and verification networks for long-term visual tracking 2019-02-18 22:12:25 Pape ...
- 论文笔记:Learning Dynamic Memory Networks for Object Tracking
Learning Dynamic Memory Networks for Object Tracking ECCV 2018Updated on 2018-08-05 16:36:30 Paper: ...
- 论文笔记:Learning how to Active Learn: A Deep Reinforcement Learning Approach
Learning how to Active Learn: A Deep Reinforcement Learning Approach 2018-03-11 12:56:04 1. Introduc ...
随机推荐
- Nestjs 链接mysql
文档 下插件 λ yarn add @nestjs/typeorm typeorm mysql 创建 cats模块, 控制器,service λ nest g mo cats λ nest g co ...
- create database link
如果本地的tnsnames.ora中未建立数据库连接,那么就是用1,否则就是用2 1:create database link geelyin96 connect to geelyin identif ...
- HTML中的清除浮动的常用方法(转载)
以下面的div为例: HTML: <div class="test"> <div class="test1"></div> ...
- macOS Sierra上面的php开发环境安装
本文参考资料: 启动apache时,解决 How to Fix AH00558 and AH00557 httpd apr_sockaddr_info_get() Error Message ...
- 24.redux
Flux:Flux 是一种架构思想 https://facebook.github.io/flux/ 官网 资料: http://www.ruanyifeng.com/blog/2016/01/flu ...
- php验证18位身份证,准到必须输入正确的身份证号,
/** * 验证18位身份证(计算方式在百度百科有) * @param string $id 身份证 * return boolean */ function check_identity($id=' ...
- jquery怎么实现点击一个按钮控制一个div的显示和隐藏
示例html 1 2 <div class="abc" style="display:none"></div> <input ty ...
- 班级作业:Java Web环境的搭建
Java Web环境的搭建 一.开发所需工具.(根据你的电脑以及系统选择合适的版本下载) 1.JDK .下载链接:https://www.oracle.com/technetwork/java/jav ...
- Python学习之旅(七)
Python基础知识(6):基本数据类型之列表 在Python中,最基本的数据结构是序列.序列中的每个元素被分配一个序号——即元素的位置,也称为索引.第一个索引从0开始,如果要从右边开始,序列中的最后 ...
- ios学习--iphone 实现下拉菜单
原文地址:ios学习--iphone 实现下拉菜单作者:sdglyuan00 #import @interface DropDown1 : UIView <</span>UITabl ...