vivo版本发布平台:带宽智能调控优化实践-平台产品系列03
vivo 互联网平台产品研发团队 - Peng Zhong
随着分发规模地逐步增长,各企业对CDN带宽的使用越来越多。并且,各类业务使用CDN的场景各式各样,导致带宽会不断地出现骤增骤降等问题。基于成本考虑,国内CDN厂商的计费模式主要用峰值点的带宽来计费,就算不用峰值点的带宽,也会因为峰值问题所产生的成本而抬高带宽单价。基于此,控制CDN带宽的峰谷具有重要意义,降低峰值就意味着成本节省。
一、背景
伴随着互联网地兴起,很多企业都经历过互联网野蛮生长的一段岁月。然而,在互联网市场逐步成熟稳定之后,各大企业在业务上的增长速度逐渐放缓,也纷纷开始“对内挖掘成本方面”的产出,对成本做更加精细化的管控,提升企业的竞争力。
特别是随着“互联网寒冬”的来临,“冷气”传导到各行各业,“降本增效”的概念也纷纷被重新提起。有拉闸限电的,扣成本扣细节;也有大规模裁员一刀切的,淘汰部分业务,压缩人力;还有些团队直接组建横向团队,通过顶层思维,在不影响团队运作的情况下,专攻核心成本技术难题,保障降本效果。
本文,基于作者在CDN带宽利用率优化方面的实践,跟大家分享一下我们的降本思路和实操方法。“降本增效”作为持续的创新方向,并不局限于某个部门,企业价值链的任何一个环节都可能会成为突破点。作为技术开发人员,我们则更多的需要“从各自负责的业务方向出发”,对公司成本有触点的业务进行分析和挖掘,针对性的从技术的角度出发,技术攻关,深入探索,降本增效,为公司带来真实价值。
通过本文,你可以:
1)打开思路,为“降本增效”提供可能的思考方向,助力大家挖掘轻量化但是价值大的目标。
2)一览无遗,了解我们CDN带宽利用率优化的核心方法。
名词解释:
【CDN】内容分发网络。
本文的CDN专指静态CDN,动态CDN主要是对路由节点的加速,带宽成本规模相对小的多。通俗的解释:CDN厂商在各地部署了很多节点,缓存你的资源,当用户下载时,CDN网络帮用户找到最近的一个节点,通过这个节点用户下载速度大大提升。
【CDN带宽利用率】
带宽利用率=真实带宽/计费带宽,可以理解为投入产出比一样性质的东西。为何要提升利用率?打个比方:你不会愿意花一亿够买价值一千万的东西,如果你的利用率只有10%的话,你其实就做了这样一件不合逻辑的事。
【愚公平台】通过带宽预测和削峰填谷,大幅度提升企业总的CDN带宽利用率的平台。
二、“寻寻觅觅”找降本
作为CDN的使用大户,在CDN带宽成本指数级增长的情况下,笔者有幸见证并参与了我司CDN降本的每一个环节,从最初基于各自业务CDN带宽利用率的优化到后来基于可控带宽调控的思路。本章,我们来聊聊我们CDN降本的几个重要阶段,并跟大家分享一下,为什么我会选择CDN带宽利用率这一个方向去研究?
2.1 CDN带宽计费模式
首先,不得不讲下我们的计费模式,峰值平均值计费:每天取最高值,每月取每日最高值的平均值作为计费带宽。
月度计费=Avg(每日峰值)
该计费模式意味着:每日峰值越低,成本越低。带宽的利用率决定了成本。由此,我们从未放弃过对带宽利用率的追求,下面看看我们都有哪些优化带宽利用率的经历吧。
2.2 CDN降本三部曲
我们CDN降本优化主要分为三个阶段。三阶段各有妙用,在当时的环境下,都有相当不错的战果。并且均是基于当时的情况,探索出来的相对合理的优化方向。

2.1.1 局部优化
局部优化是基于我司的主要CDN使用情况而产生的一种思路。作为手机生产制造厂商,我们的静态CDN使用场景的核心业务是应用分发类,如:应用商店app分发,游戏中心app分发,版本自升级分发。归纳一下,核心六大业务占据了我司带宽的90%以上,只要把这六大业务的带宽利用率提升上去,我们的带宽利用率就可以得到明显的提升。
基于这样一个情况,CDN运维工经常找到核心业务,给一个带宽利用率的指标,让各业务把带宽利用率提升上去。归纳一下,核心思路就是:找到核心CDN使用业务方、分别给他们定好各自的利用率指标、提需求任务、讲清楚优化的价值。在这一阶段优化之后,我们核心业务的带宽突发场景得到收口,整体带宽利用率明显得到提升。
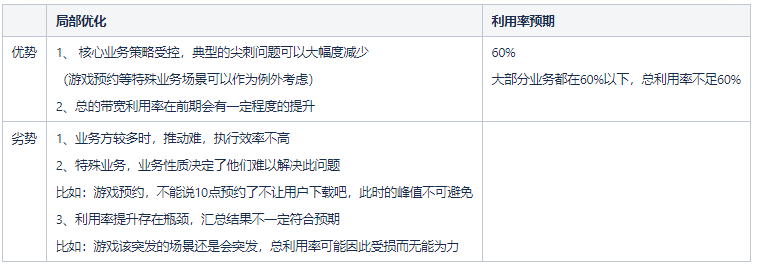
2.1.2 全局优化
由于局部优化是各自业务优化,在大量突刺问题解决之后,各业务的带宽利用率优化会进入一个瓶颈区。其中,效果比较好的,单业务带宽利用率也很难突破60%,除非是特殊的业务形式,带宽完全受控这种情况。此时,我们业务把部分带宽抽离出来,用以调控公司整体带宽,进一步提升公司整体带宽利用率,我们把他定义为全局优化阶段。
基于这样一个全局优化的思路,各个业务只要没有太大的突刺,总体带宽利用率就会得到一个较大幅度的提升。首先,我们把带宽进行划分,抽取部分可以受服务器控制的带宽拆分为可控带宽,主要是工信部许可的wlan下载部分带宽;然后,我们观测带宽走势,根据带宽历史走势,分离出各个时段的带宽数据,针对不同时段控制不同的带宽量级放量,最终达到一个“削峰填谷”的目的。此策略是通过阈值控制放量速度的,每小时设置一个阈值,以每小时阈值生成每秒的令牌数,进行令牌桶控量。
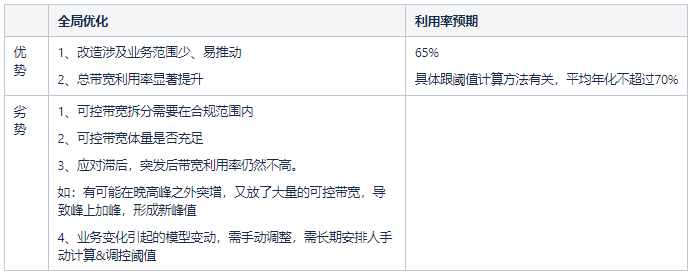
2.1.3 自动化控制
全局优化之后,作为技术开发人员,更进一步的方法就是利用程序取代人工,往更精细化控制方向控量。
基于这样一个思路,笔者开始探索机器学习方面的预测技术,想象着有规律、有特征,就有一定的预测的可能性。跟股票不同,虽然CDN带宽的影响因素也有很多,但是影响最大的几个因素却是显而易见的。所以我们分析这些因素,先归因,后提取特征和特征分解,预测阈值,预测各点的带宽值。最终攻克了这一预测难题,实现了通过预测技术来调节CDN带宽峰谷问题。
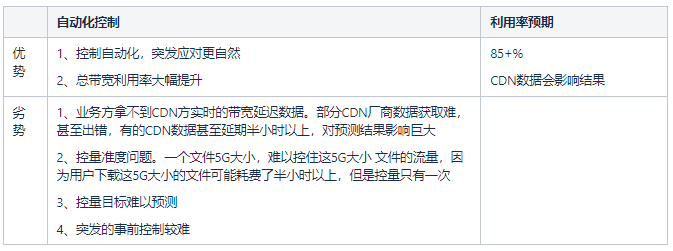
2.3 降本思路的由来
说到降本增效,作为技术开发,首先想到的就是利用技术取代人工,利用程序提升大家的工作效率。比如:自动化测试、自动化点检、自动化监测归类告警等等,不管哪个团队都不少见。甚至自动化代码生成器,提升大家的编码效率,都已经孵化了大量平台。
下面,分析一下我们降本增效的主要思路。
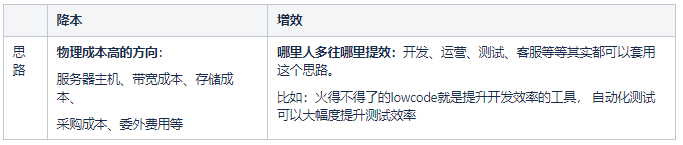
笔者主要负责的技术模块偏应用分发,涉及的成本方向有:CDN带宽成本、存储成本、主机成本。相对于CDN的巨大成本,存储成本和主机成本部分,少量业务的体量微不足道。至此,我们最合适的方向是往CDN成本方向突破。
CDN成本方向有两个细分方向:降低带宽体量、提升带宽利用率。
小结:
降低带宽体量复杂度高,基于当前情况,如果能够自动预测带宽,并且做到自动化控制,可以大幅度提升带宽利用率,达成显而易见的降本效果。并且企业CDN费用越高,降本收益显著。
三、“踏踏实实”搞预测
确定目标之后,该专题最初是放在“个人OKR目标里”里缓慢推进的。本章,笔者跟大家聊聊我们最主要“预测方向”的探索思路。
3.1 带宽预测探索
我们的探索期主要分两个阶段。前期主要是围绕:观察→ 分析 → 建模 开展,类似于特征分析阶段;后期主要是进行算法模拟→算法验证,选择效果相对满意的算法,继续深入分析探索,深挖价值,研究算法最终突破可用的可能性。
3.1.1 观察规律
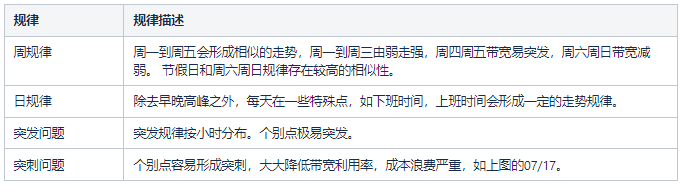
如图是我司三大项目今年7月1日~7月31日 的带宽走势图(数据已脱敏):

可以观察出一些比较明显的规律性:
3.1.2 成因分析
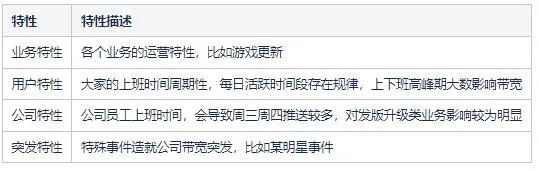
我们的带宽会走出如此趋势,跟它的影响因素有关,下面列出了“显而易见的”一些影响因素。
3.1.3 模型拆分
了解带宽成因之后,我们主要的研究方向为:机器学习、残差分析、时间序列拟合等方向。然而,最终契合我们的预测模式是:阈值时间序列预测、带宽实时预测模型。从最初探索到最终成型,我们的模型探索也是多次转变方向,逐渐变得成熟。
3.2 算法关键
【最近数据】虽然CDN厂商没法提供实时带宽数据,但是却可以提供一段时间之前的数据,比如15分钟之前的带宽数据,我们简称之为最近数据。
基于最近的带宽数据,我们尝试结合延期数据和历史数据之间的关系,纳入模型,研究出一种自研的算法(主要周期单位为周),进行实时预测。
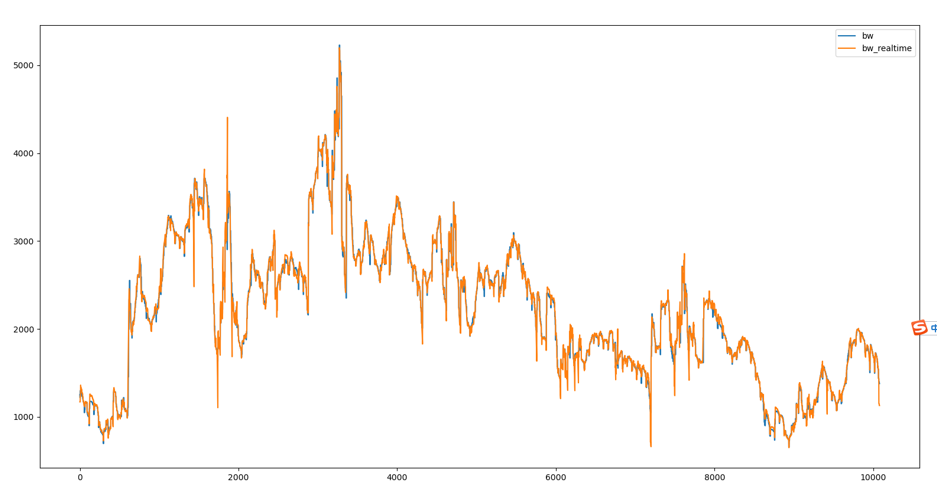
下图(数据已脱敏)是纳入最近数据之后的一周预测拟合效果。并且,区别于残差学习对突变点的敏感,我们的模型预测主要问题出在带宽转折点,只要处理好转折点的带宽模型即可让算法效果得到保障。
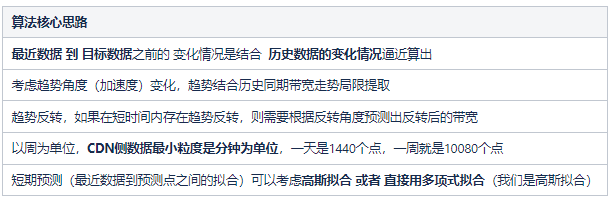
我们自研算法的核心思路:
算法的注意事项:
四、“兢兢业业”做愚公
假设你已经能够较为精准的预测带宽(标准是:特殊突变点之外,方差5%以内),那么真正要投产其实还有很多细节要做,你可能会一些面临模型优化的些许问题 或者 技术处理的问题。
下面,我们主要讲讲我们《愚公平台》处理从预测到控量的一系列方案,并针对落地实践问题,我们做了些说明,让大家少走弯路。
4.1 我们的落地方案
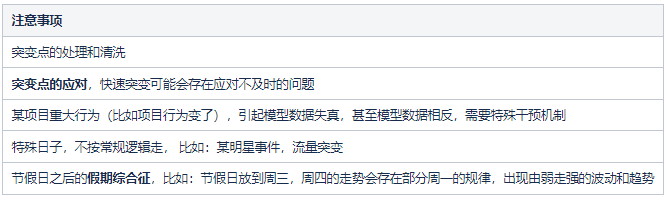
总体上,我们方案的最终目标还是降本,降本思路是基于计费模式。我用一句话概括了我们的方案,如下图,预测蓝色线、控制阴影区,最终压低蓝色线,也就是我们的计费带宽,从而达到如图的降本效果。
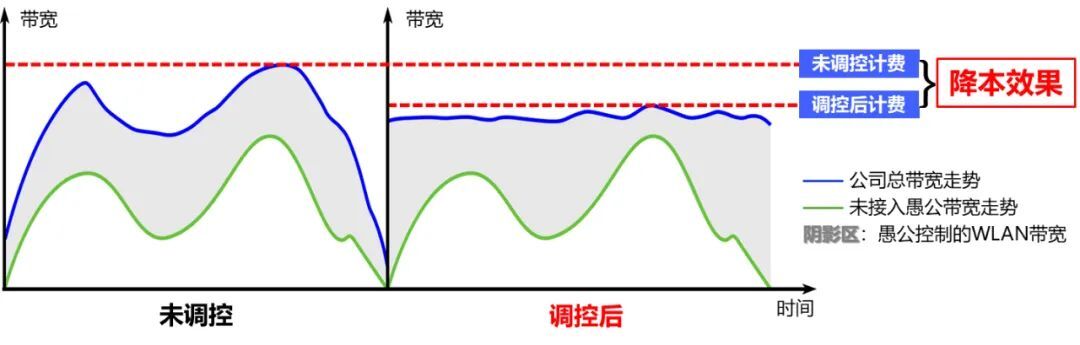
4.2 愚公平台的实践思路
如下图,愚公平台的核心思路可以概括为:
通过离线模型预测明日的阈值
使用自研模型,实时预测未来一段时间的带宽值
结合阈值与预测值,算出一个控量值
控量值写入令牌桶,每秒生成令牌给端侧消费
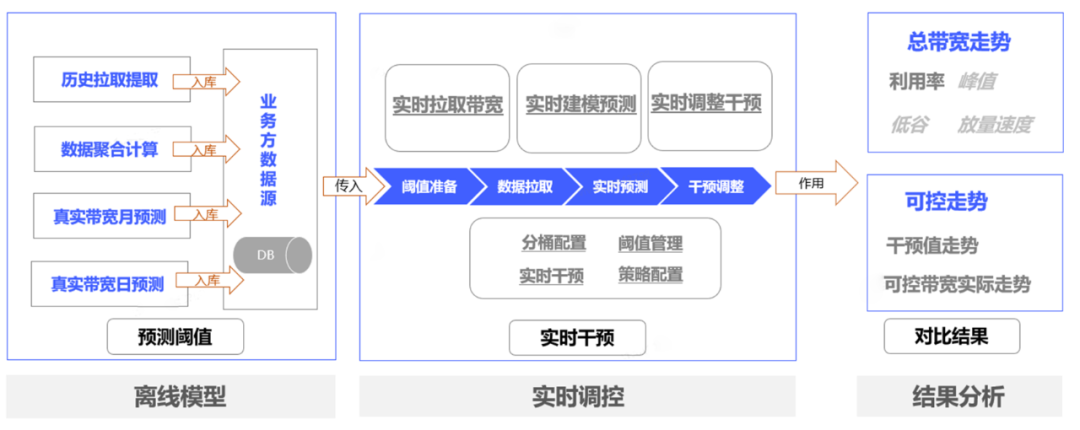
4.2.1 使用Prophet预测阈值
首先是阈值预测,基于之前做带宽预测的时候也研究过prophet预测,所以最终选择其作为阈值预测的核心算法。其时间序列特性配合突变点的识别非常契合我们的场景,最终的效果也是非常优秀的。
如下图(数据已脱敏),除少量特别突发点以外,大部分阈值点基本上落在预测范围内。
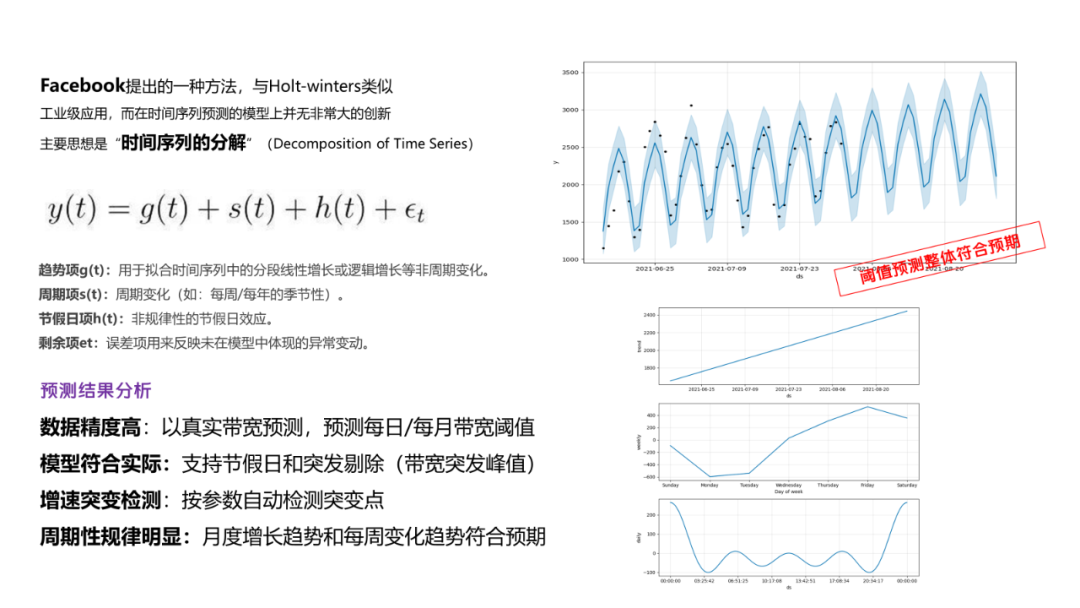
最后,阈值预测本身是一种时间序列预测模型,网上也有较多的类似的选型方案,我们使用prophet预测阈值,并且我们也设计了阈值自适应模型,自动扩充带宽阈值,可以一定程度降低阈值偏离风险。所以,我们使用的阈值一般是体量阈值,结合其自适应特性,加上一些干预手段,可以极大的保障我们的调控效果。
4.2.2 使用自研算法预测带宽
这部分内容在预测部分已经有较为详细的介绍,这里就不再赘述。总体上,还是用最近的带宽,结合历史走势,拟合出未来一段时间的带宽走势,从而预测未来短暂的带宽走势。
4.2.3 子模型解决调控问题
这里主要是针对预测之后的数据,到控制数据之间的转换,做一些细化处理。对突发、边界、折算、干预等问题给予关注,需要根据业务实际情况做分析和应对。
4.2.4 流控SDK问题
研究发现,许多业务可能都存在可控制的带宽,基于此,我们统一做了一个流控SDK。把更多带宽纳入管控,控制的带宽体量越大,带来的效果相对会更好。这里的SDK本质还是一种令牌桶技术,通过此SDK完成所有带宽的统一控制,可以大幅度减少各个业务处理带宽问题的烦恼。
4.3 精细化控制能力
阈值预测之后,到最后控量,期间存在较大的转换关系,可能还需要进一步思考和优化才能让带宽利用率得到较大的提升。本节例举了我们遇到的挑战,针对我们流控问题,做了些例举,并做了些分解说明。
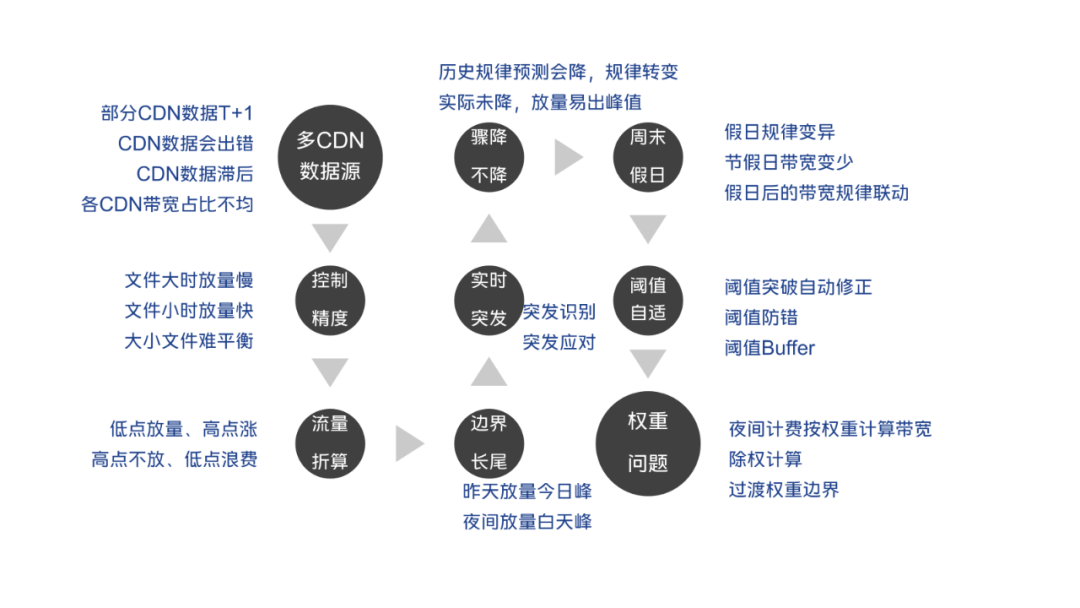
4.3.1 多CDN数据源问题
一般公司会对接多家CDN,各家CDN分配一定的量级,部分CDN不提供最近数据的拉取能力,或者对频率限制太严重,导致数据拉取困难。我们的解决思路:找一家比例相对尚可 且 数据拉取相对配合 的厂商, 用他们的数据和比例反推公司总带宽,减少对其它CDN厂商的依赖。
注意:因为公司业务多,小业务不支持多CDN比例调控能力,会导致这个比例存在波动,波动太大的情况下会导致调控失真,会导致你的利用率受损。
4.3.2 大小文件引起带宽控制不准
限流时,一般只能控制开始下载,但是一旦开始下载,不知道什么时候才会下载完成。小文件,下载耗时较短,控制精准度较高。(常见的小文件、小资源下发等。)大文件,如系统升级包,3G的包,下载可能要一小时以上,控制下载开始是会出问题的。下载时长引起的长尾会让你绝望。
我们的解决思路:
思路一:对于这种特别大的文件 但是 流量及时性要求不高的,拆分到粗控模型中(可以理解成全局控制那一套思路)。用小文件做精控。精控使用预测模型,对整体带宽做进一步补充。
思路二:对大文件的下载进行拆分,假设拆成100M, 每下载100M都请求一下流控服务器。 这里复杂度较高,依赖于客户端改造,作为一种思路考虑。
4.3.3 流量折算问题
其实也是流量长尾引起的,你控制每秒可以下载100个文件,每个文件100MB, 那么就是10000MB/s的带宽,实际上由于下载是连续的,这一秒并不会完成下载,实际跑出来的流量没这么多。
我们的解决思路:存在流量折算系数,就是你控制3Gbps,实际上打满之后只有2Gbps,这里需要手动设置一个折算系数,方便进行流量更精准的控制。
注意:这个折算系数因为包体的大小存在波动,会导致你的利用率受损。
4.3.4 边界长尾问题
一般情况下,边界在凌晨, 就是每天一计费。而昨天23:59,往往是大家的带宽低估,你如果控制了非常多的带宽(假设因为昨天有突发,导致你控制放量10Tbps),刚好流量又足够,这个流量可能会因为长尾问题,到今天00:01才放完。因为流量太过庞大,导致今天的计费带宽在凌晨形成巨峰。
我们的解决思路: 对边界点之前的一些点进行特殊控制。比如:23:50~ 23:59, 使用明天的峰值进行控量。
4.3.5 突发应对问题
这里主要是指模型识别的突发,比如数据显示20分钟之前带宽骤增,那么根据模型你其实已经可以根据这个突发识别到当前的带宽是在高位行走,且因为趋势的问题,带宽预测出一个较高的值。我们的解决思路: 根据总的增长值(或者增长值占比), 或者增长速度(或者增长速度占比), 或者增长最大步长(每分钟增长最大的数据) 考虑作为判断突发的方式,采取突发应对方案。
有人也发现了,上文讲过的,部分突发是预测不了的,我们是怎么应对来减少损失呢?
① 小突发预留阈值空间
比如预测目标阈值是2T,可能会放1.8T作为阈值,这样就算有短暂的突发,带宽突到2T,也在我们的目标范围内。预留的0.2T就是我们给自己留下的退路,我们的目标也从来不是100%的带宽利用率,这部分预留就是我们要牺牲掉的带宽利用率。并且,当带宽突到更高峰值之后,这部分预留值要合理配置。
②大突发收集统一接入
怎么定义大突发?有些业务,比如游戏发版、微信发版,涉及包体很大、涉及用户很广。只要发版,必定引起大突发,这种只有大业务才能引起的较大带宽突变,这就是大突发。如果这个突发走势非快,可以尝试控制速度,压一压这个走势(在我们第一阶段的带宽利用率优化其实已经做的不错了)。如果压成了缓慢突发,我们模式是可以识别到趋势,做好应对,至此,大突发就不是问题。反之,压不了的大突发,一下突增300G以上,迅雷不及掩耳之势突上去的,模型来不及调整,我们建议直接让类似的行为接入控制系统,让控制系统提前挖坑应对。
③容易突发的区段,带宽放量少放一些,牺牲一些量,来做防御
有些时段,比如晚高峰,就是容易突发,不是这事就是那事,总会出现意想不到的突发,建议直接压低阈值,本来阈值2T,直接控制一个时段压到1.5T。这0.5T就是对系统的保护,毕竟只挖一个时段,在其它时段把堵住的流量放出去就好,整体影响还好。
4.3.6 骤降不降问题
根据模型预测骤降(历史规律导致的),你知道这个点的带宽趋势是降低,并且有一些常规降低的降低数据。然而,实际可能没有降低那么多,最终因为调控问题可能会引起新峰值。
基于这个问题,我们的解决思路:定义骤降场景和骤降识别规律,对骤降点做特殊标记,处理好骤降带宽的放量策略,避免引入新峰值。
4.3.7 手动干预处理
部分特殊场景,比如,大型软件,可以预料到量级非常大,或者大型游戏预约(如:王者荣耀)更新。这部分可以提前知道突发。
我们的解决思路: 提供突发SDK接入能力和后台录入能力,对部分容易突发的业务,提供突发上报SDK,提前上报数据,方便模型做出突发应对。
比如:根据带宽体量,历史突发场景规律,建模拟合出突发峰值,在突发期间,降低阈值;在突发前,提升阈值。
4.3.8 特殊模式:周末&节假日模式
节假日不同于平时的带宽走势,会存在几个明显的规律:
大家不上班,可控带宽明显偏少
突发点往早高峰偏移
我们的解决思路:针对节假日单独建模,分析节假日的带宽走势。
4.3.9 阈值自适应调整问题
如果按阈值一成不变,那么突发之后,用之前的阈值会造成大量的带宽浪费。
我们的解决思路:设计阈值增长模型, 如果池外带宽峰值突破阈值,或者总带宽超过阈值一定比例,则考虑放大阈值。
4.3.10 带宽权重问题
在CDN竞争激烈的时代,由于用户习惯,导致白天带宽使用较多,而夜间带宽使用较少。所以部分CDN厂商支持了分段计费方案,这就意味着我们在有些时间段可以多用一些带宽,有些时间段需要少用一些带宽。
我们的解决思路: 此方案是基于分段计费, 所以需要设置不同时段的带宽权重,即可保障带宽模型平滑运行。当然,分段之后,会出现新的边界问题,边界问题需要重新应对解决。
4.4 技术问题
本节基于我们使用的技术,对大家最可能遇到的技术问题做些说明。
4.4.1 热点key问题
由于接入业务方多,且下载限流经过的流量巨大,可能是每秒百万级的,这里必然存在一个问题就是热点key问题。我们通过槽与节点的分布关系(可以找DBA获取),确定key前缀,每次请求随机到某个key前缀,从而随机到某个节点上。从而把流量均摊到各个redis节点,减少各个节点的压力。
下面是我们的流控SDK,LUA 脚本参考:
//初始化和扣减CDN流量的LUA脚本
// KEY1 扣减key
// KEY2 流控平台计算值key
// ARGV1 节点个数 30 整形
// ARGV2 流控兜底值MB/len 提前除好(防止平台计算出现延迟或者异常,设一个兜底值),整形
// ARGV3 本次申请的流量(统一好单位MB,而不是Mb) 整形
// ARGV4 有效期 整形
public static final String InitAndDecrCdnFlowLUA =
"local flow = redis.call('get', KEYS[1]) " +
//优先从控制值里取,没有则用兜底值
"if not flow then " +
" local ctrl = redis.call('get', KEYS[2]) " +
" if not ctrl then " +
//兜底
" flow = ARGV[2] " +
" else " +
" local ctrlInt = tonumber(ctrl)*1024 " +
//节点个数
" local nodes = tonumber(ARGV[1]) " +
" flow = tostring(math.floor(ctrlInt/nodes)) " +
" end " +
"end " +
//池子里的值
"local current = tonumber(flow) " +
//扣减值
"local decr = tonumber(ARGV[3]) " +
//池子里没流量,返回扣减失败
"if current <= 0 then " +
" return '-1' " +
"end " +
//计算剩余
"local remaining = 0 " +
"if current > decr then " +
" remaining = current - decr " +
"end " +
//执行更新
"redis.call('setex', KEYS[1], ARGV[4], remaining) " +
"return flow";
4.4.2 本地缓存
虽然解决了热点key的问题,但是真正流控控到0的时候(比如连续1小时控到0),还是会存在大量请求过来,特别是客户端重试机制导致请求更频繁的时候,这些请求全部都过一遍LUA有点得不偿失。
所以需要设计一套缓存,告诉你当前这一秒 流控平台没有流量了,减少并发。
我们的解决办法: 使用内存缓存。当所有节点都没有流量的时候,对指定秒的时间,设置一个本地缓存key,经过本地缓存key的过滤,可以大幅减少redis访问量级。
当然,除此之外,还有流量均衡问题,客户端的流量在1分钟内表现为:前面10s流量很多,导致触发限流,后面50s没什么流量。
这种问题我们服务端暂时还没有很好的解决办法。可能需要端侧去想办法,但是端侧又较多,推起来不容易。
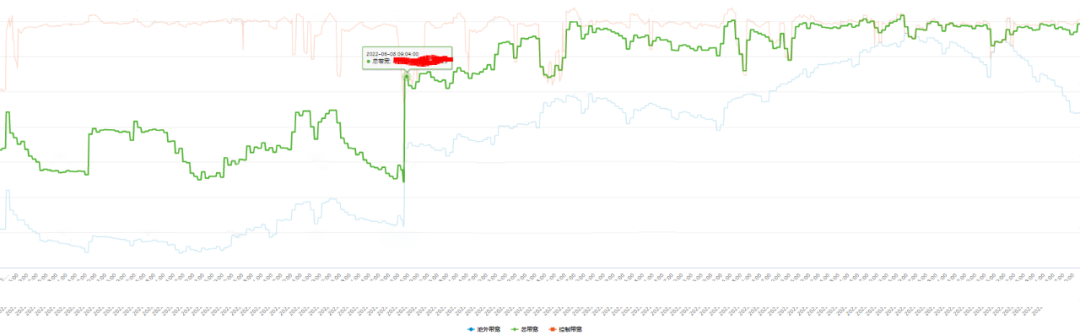
4.5 最终效果
如图是除权之后的带宽走势。从图中可以看出,使用《愚公平台》调控带宽,CDN带宽利用率显著提升。
五、写在最后
本文主要讲述了《愚公平台》从研究到落地实践的历程:
结合业务,选择了CDN降本方向作为技术研究方向。
观察规律,选择了Prophet作为离线阈值预测算法。
算法突破,自研出拟合算法作为实时预测算法。
持续思考,思考应对模型中的问题及持续优化方案。
最终,从技术的角度,为公司创造巨大的降本收益。
《平台产品》系列文章:
vivo版本发布平台:带宽智能调控优化实践-平台产品系列03的更多相关文章
- 国内物联网平台(5):机智云IoT物联网云服务平台及智能硬件自助开发平台
国内物联网平台(5)——机智云IoT物联网云服务平台及智能硬件自助开发平台 马智 平台定位 机智云平台是致力于物联网.智能硬件云服务的开放平台.平台提供了从定义产品.设备端开发调试.应用开发.产测.运 ...
- JeeWx全新版本发布!捷微二代微信活动平台1.0发布!活动插件持续开源更新!
JeeWx捷微二代微信活动平台 (专业微信营销活动平台,活动插件持续更新ing~) 终于等到你!还好我没放弃! 在团队持续多年的努力下,Jeewx微信管家和H5活动平台不断更新迭代,积累了许许多 ...
- Redis 在 vivo 推送平台的应用与优化实践
一.推送平台特点 vivo推送平台是vivo公司向开发者提供的消息推送服务,通过在云端与客户端之间建立一条稳定.可靠的长连接,为开发者提供向客户端应用实时推送消息的服务,支持百亿级的通知/消息推送,秒 ...
- 在线Online表单来了!JeecgBoot 2.1 版本发布——基于SpringBoot+AntDesign的快速开发平台
项目介绍 Jeecg-Boot 是一款基于SpringBoot+代码生成器的快速开发平台! 采用前后端分离架构:SpringBoot,Ant-Design-Vue,Mybatis,Shiro,JWT. ...
- Jeecg-Boot 2.0.1 版本发布,前后端分离快速开发平台
Jeecg-Boot项目简介 Jeecg-boot 是一款基于代码生成器的快速开发平台! 采用前后端分离技术:SpringBoot,Mybatis,Shiro,JWT,Vue & Ant De ...
- 国内物联网平台初探(五) ——机智云IoT物联网云服务平台及智能硬件自助开发平台
平台定位 机智云平台是致力于物联网.智能硬件云服务的开放平台.平台提供了从定义产品.设备端开发调试.应用开发.产测.运营管理等覆盖智能硬件接入到运营管理全生命周期服务的能力. 机智云平台为开发者提供了 ...
- 1024程序员节宅男节日快乐 -- JAVA快速开发平台,JEECG 3.8宅男优化版本发布
JEECG 3.8 版本发布,系统全面升级,重构上传组件.优化代码生成器机制! 导读 ⊙平台性能优化,系统更稳定,速度闪电般提升 ⊙系统上传组件全面重构,使用plupload组件,解决flash的 ...
- JEECG 3.7.2版本发布,企业级JAVA快速开发平台
JEECG 3.7.2版本发布 - 微云快速开发平台 JEECG是一款基于代码生成器的J2EE快速开发平台,开源界"小普元"超越传统商业企业级开发平台.引领新的开发模式(Onli ...
- JEECG 3.7.1 版本发布,企业级JAVA快速开发平台
JEECG 3.7.1 版本发布,企业级JAVA快速开发平台 ---------------------------------------- Version: Jeecg_3.7.1项 目: ...
- 基于SpringBoot+Mybatis+AntDesign快速开发平台,Jeecg-Boot 1.1 版本发布
Jeecg-Boot 1.1 版本发布,初成长稳定版本 导读 平台首页UI升级,精美的首页支持多模式 提供4套代码生成器模板(支持单表.一对多) 集成Excel简易工具类,支持单表.一对多导入 ...
随机推荐
- ArcObjects SDK开发 006 ICommand和ITool接口
1.ICommand接口 ICommand接口是插件协议之一,继承该接口的类都可以成为命令.即点击一下执行,不主动与宿主发生鼠标和键盘交互.该接口包含的重要成员如下表所示. 序号 名称 类型 描述 1 ...
- Dev-Cpp下载与安装
目录 一.介绍 Dev-Cpp 二.下载 Dev-Cpp 1.通过百度网盘下载 2.通过 SourceForge 官网下载 三.安装 Dev-Cpp 写在结尾的话 免责声明 大家好,这里是 main工 ...
- Dart语言简介
简单介绍Dart语言 Dart是一种针对客户优化的语言,亦可在任何平台上快速开发的应用陈旭. 目标是为多平台开发提供最高效的变成语言,并为应用程序框架搭配了领会的运行时执行平台. Dart特点 Dar ...
- JavaEE Day10 JavaScript高级
今日内容 JavaScript ECMAScript:客户端脚本语言标准() BOM对象 DOM对象 事件 学习顺序:DOM-事件-BOM-DOM 一.简单入门 1.DOM 功能:控制HTML文档的内 ...
- 【大数据课程】高途课程实践-Day03:Scala实现商品实时销售统计
〇.概述 1.实现内容 使用Scala编写代码,通过Flink的Source.Sink以及时间语义实现实时销量展示 2.过程 (1)导包并下载依赖 (2)创建数据源数据表并写⼊数据 (3)在Mysql ...
- 在Maven中出现javax.mail中文乱码问题解决记录
学习Java时,看廖雪峰大神文章使用了javax.mail来发送SMTP邮件.在加入中文时,发现收到的邮件里中文都是乱码. 按照一般经验,多半是编码的问题.然而在代码中,会涉及到编码的地方已经全部设置 ...
- [py]残留python.exe导致anaconda python路径无法识别
刚才重下anaconda真是给我整没脾气了 路径啥的都加好了,cmd输入python还是没有,给我跳应用商店去了- 重启也没用 经过一番搜索,找到解决办法: cmd输入"where pyth ...
- DID 2022-12-02
DID第二节课 最低工资对就业率影响(DID) 宾夕法尼亚VS新泽西的快餐店,用边界的好处:在用最低工资法之前,两地工资情况差不多,DID需要两期,92年11月实施,之前之后做电话访问. 数据越全的估 ...
- Clickhouse表引擎探究-ReplacingMergeTree
作者:耿宏宇 1 表引擎简述 1.1 官方描述 MergeTree 系列的引擎被设计用于插入极大量的数据到一张表当中.数据可以以数据片段的形式一个接着一个的快速写入,数据片段在后台按照一定的规则进行合 ...
- React报错之React.Children.only expected to receive single React element child
总览 当我们把多个子元素传递给一个只期望有一个React子元素的组件时,会产生"React.Children.only expected to receive single React el ...