2. Fluentd事件的生命周期
事件(Event)是Fluentd内部处理流程使用的数据结构,日志记录一旦进入Fluentd便被封装成一个event。Event由三部分组成:tag、time、record。
- tag: 标识事件的来源,或者说类型,用于内部消息路由,即后续交由哪个插件处理;
- time: 是事件的发生时间;
- record: 为日志的实际内容,这是一个JSON对象。
Input插件负责将源数据封装为event,比如input_tail插件从文本中生成event。对于下边这行文本:
192.168.0.1 - - [28/Feb/2013:12:00:00 +0900] "GET / HTTP/1.1" 200 777
将会产生下边的event对象:
tag: apache.access #根据插件的tag参数来设置
time: 1362020400 # 28/Feb/2013:12:00:00 +0900
record: {"user":"-","method":"GET","code":200,"size":777,"host":"192.168.0.1","path":"/"} #根据input_tail插件中的parse项来决定如何解析单行日志记录,并生成相应的JSON对象
通过一个具体的配置来讲解事件的处理过程。
本例使用一个很基础的配置片段来描述各插件是如何关联到一起的,它包括了如何定义输入源(或者说监听器),以及如何设置通用的匹配规则将event路由到输出端。
我们使用input_http和output_stdout这两个插件来描述event的循环过程。
<source>
@type http
@id input_http
port 8888
</source>
上边的配置使用input_http插件定义了一个HTTP服务器,监听端口为8888。然后我们再定义一个匹配(Match)规则,event路由引擎会根据这个规则将http请求派发到输出端。这里的输出端是stdout,仅仅将http请求打印到屏幕上。
<match test.cycle>
@type stdout
@id output_stdout
</match>
Match的作用是设置一个匹配规则test.cycle,对于每个进入Fluentd的event,如果其tag值和test.cycle相等(或者说匹配,因为match可以使用通配符。这里的tag是由input_http插件生成的。),那么这个event就会进入此match定义的output插件,本例中的output插件就是output_stdout。
至此,我们定义了三个基本项:Input、Match和Output,虽然仅仅使用两个配置段。这就是一个可以使用的采集配置了,可以通过以下命令进行测试:
curl -i -X POST -d 'json={"action":"login","user":2}' http://localhost:8888/test.cycle
会看到如下输出:
HTTP/1.1 200 OK
Content-Type: text/plain
Connection: Keep-Alive
Content-Length: 0
在/var/log/td-agent/td-agent.log中会有如下输出:
2020-11-03 14:34:09.624879668 +0800 test.cycle: {"action":"login","user":2}
下边开始了解一下事件是如何被处理和改变的。
当你准备好一个采集配置后,Fluentd就生成了用以处理输入数据的各种规则。日志事件会历经一系列的处理流程,从而决定了事件的循环周期。
1.过滤器(Filters)
过滤器用于对事件进行筛选,决定是否接收或者丢弃事件。我们可以在上边的示例中增加一个过滤器。
<source>
@type http
@id input_http
bind 0.0.0.0
port 8888
</source>
<filter test.cycle>
@type grep
<exclude>
key action
pattern ^logout$
</exclude>
</filter>
<match test.cycle>
@type stdout
@id output_stdout
</match>
添加过滤器之后,事件在路由到match之前必须经过过滤器的处理。过滤器根据事件的类型和过滤规则来决定是否接受此事件。
示例中使用的是grep过滤器,这个过滤器对test.cycle这类事件进行过滤,会排除http请求中action值为logout的事件。
所以,如果尝试发送下边的请求,在td-agent.log中是看不到任何输出的。
curl -i -X POST -d 'json={"action":"logout","user":2}' http://localhost:8888/test.cycle
从示例中可以看到,事件是根据配置顺序自上而下来被处理的。我们可以根据需要配置任意多个过滤器,这样一来,配置文件会变得很长很复杂。Fluentd提供了标签来解决此问题。
2.标签(Labels)
标签的作用是用来定义一组配置项,这组配置项可以被其他配置项引用,从而实现事件路由跳转。类似编程语言中的goto的功能。
还是上边的示例,我们定义一个标签来看一下效果。
<source>
@type http
@id input_http
bind 0.0.0.0
port 8888
@label @STAGING
</source>
<filter test.cycle>
@type grep
<exclude>
key action
pattern ^logout$
</exclude>
</filter>
<label @STAGING>
<filter test.cycle>
@type grep
<exclude>
key action
pattern ^login$
</exclude>
</filter>
<match test.cycle>
@type stdout
@id output_stdout
</match>
</label>
这个STARTING标签将之前的filter和match封装到了一起,然后在source中进行了引用。如此一来,事件由input插件生成后将会跳过那个独立的filter,直接进入STARTING定义的处理流程中。
# 如下这个没有输出,因为跳过了独立的filter
curl -i -X POST -d 'json={"action":"logout","user":2}' http://localhost:8888/test.cycle
# 如下这个有输出,直接进入STARTING定义的处理流程中开始filter
curl -i -X POST -d 'json={"action":"login","user":2}' http://localhost:8888/test.cycle
这种效果可以实现一些特定的处理逻辑,让事件快速到达指定目的地。
3.缓存(Buffers)
我们看到了事件从input产生,经由filter筛选,最后到达output的过程。在上边的示例中,我们使用的是stdout插件直接输出到控制台,并没有经过缓存。
实际应用中,一般会先把数据进行缓存,达到一定条件后再flush到目标存储中。这样可以提升系统可靠性,对于稳定系统吞吐量也很重要。
官方关于缓存的文档地址:https://docs.fluentd.org/configuration/buffer-section
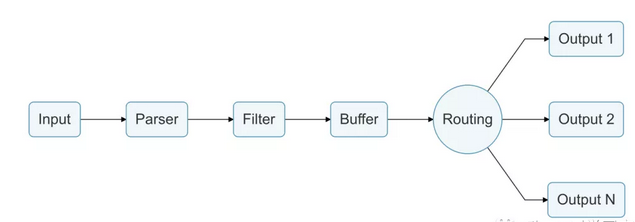
总的来说,事件会在各插件之间接续流转,直到到达output,结束整个生命周期。
如下图:
2. Fluentd事件的生命周期的更多相关文章
- iOS一些系统事件的生命周期
1.- (void)applicationWillResignActive:(UIApplication *)application 说明:当应用程序将要入非活动状态执行,在此期间,应用程序不接收消息 ...
- Page的生命周期及相关事件苛
(1)请求页面:页请求发生在页生命周期开始之前. (2)开始:在开始阶段,将设置页属性,如Request和Response.在此阶段,页还将确定请求是回发请求还是新请求,并设置IsPostBack属性 ...
- asp.net 页面生命周期事件详细
(1)请求页面:页请求发生在页生命周期开始之前. (2)开始:在开始阶段,将设置页属性,如Request和Response.在此阶段,页还将确定请求是回发请求还是新请求,并设置IsPostBack属性 ...
- 重新想象 Windows 8 Store Apps (70) - 其它: 文件压缩和解压缩, 与 Windows 商店相关的操作, app 与 web, 几个 Core 的应用, 页面的生命周期和程序的生命周期
[源码下载] 重新想象 Windows 8 Store Apps (70) - 其它: 文件压缩和解压缩, 与 Windows 商店相关的操作, app 与 web, 几个 Core 的应用, 页面的 ...
- ASP.NET 应用程序生命周期概述[转自MSDN]
本文转自:http://msdn.microsoft.com/zh-cn/library/ms178473(VS.80).aspx 下表描述了 ASP.NET 应用程序生命周期的各个阶段. 阶段 ...
- ASP.NET 应用程序(Application)生命周期概述
原文:ASP.NET 应用程序(Application)生命周期概述 引用MSDN:ASP.NET 应用程序生命周期概述 本 主题概述应用程序生命周期,列出重要的生命周期事件,并描述如何编写适合应用程 ...
- vue的组件和生命周期
Vue里组件的通信 通信:传参.控制.数据共享(A操控B做一个事件) 模式:父子组件间.非父子组件 父组件可以将一条数据传递给子组件,这条数据可以是动态的,父组件的数据更改的时候,子组件接收的也会变化 ...
- vue的生命周期的理解
Vue实例有一个完整的生命周期,也就是从开始创建.初始化数据.编译模板.挂载Dom.渲染→更新→渲染.销毁等一系列过程,我们称这是Vue的生命周期.通俗说就是Vue实例从创建到销毁的过程,就是生命周期 ...
- vue生命周期-mounted和created的区别
详情请查看:https://blog.csdn.net/xdnloveme/article/details/78035065 自己做个总结: beforeCreate 创建之前:已经完成了 初始化事件 ...
随机推荐
- 74HC595驱动(并转串,fpga与时钟匹配,fpga与外部芯片的连接注意事项)
上一次设计的动态扫描数码管显示电路模型如上,这是一个32位并行数据[31:0]disp_num选通输出并行数据[7:0]select和[7:0]段选的电路.因此需要输出16个信号 而在开发板上的电路与 ...
- MPI学习笔记(二):矩阵相乘的两种实现方法
mpi矩阵乘法(C=αAB+βC) 最近领导让把之前安装的软件lapack.blas里的dgemm运算提取出来独立作为一套程序,然后把这段程序改为并行的,并测试一下进程规模扩展到128时的并行效率. ...
- 向docker镜像中传递变量的两种方式
测试用到的python文件: #!/usr/bin/env python3 #conding: utf-8 from http.server import HTTPServer, BaseHTTPRe ...
- 乘风破浪,遇见未来新能源汽车(Electric Vehicle)之特斯拉提车必须知道的十个流程
订车 线下门店或者官网可以咨询和下单,一般来说,订金就是1000,还算可以接受. 订单账号 特斯拉账号是以邮箱为区分的,而不是手机号,我们下单的时候需要提供一个邮箱用来注册特斯拉账号. 注意了,敲黑板 ...
- mysql like 命中索引
反向索引案例:CREATE TABLE my_tab(x VARCHAR2(20)); INSERT INTO my_tab VALUES('abcde'); COMMIT; CREATE INDEX ...
- Java核心知识体系3:异常机制详解
1 什么是异常 异常是指程序在运行过程中发生的,由于外部问题导致的运行异常事件,如:文件找不到.网络连接失败.空指针.非法参数等. 异常是一个事件,它发生在程序运行期间,且中断程序的运行. Java ...
- 在Go中如何正确重试请求
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com/archives/677 我们平时在开发中肯定避不开的一个问题是如何在不可靠的网络服务中 ...
- CF708C Centroids(树形DP)
发现变重心就是往重心上割,所以\(\text{up and down}\),一遍统计子树最大\(size\),一遍最优割子树,\(down\),\(up\)出信息,最后\(DFS\)出可行解 #inc ...
- Git 08 IDEA撤销添加
参考源 https://www.bilibili.com/video/BV1FE411P7B3?spm_id_from=333.999.0.0 版本 本文章基于 Git 2.35.1.2 如果将不想添 ...
- 百亿数据百亿花, 库若恒河沙复沙,Go lang1.18入门精炼教程,由白丁入鸿儒,Go lang数据库操作实践EP12
Golang可以通过Gorm包来操作数据库,所谓ORM,即Object Relational Mapping(数据关系映射),说白了就是通过模式化的语法来操作数据库的行对象或者表对象,对比相对灵活繁复 ...