DataX插件二次开发指南
一、 DataX为什么要使用插件机制?
从设计之初,DataX就把异构数据源同步作为自身的使命,为了应对不同数据源的差异、同时提供一致的同步原语和扩展能力,DataX自然而然地采用了框架 + 插件 的模式:
- 插件只需关心数据的读取或者写入本身。
- 而同步的共性问题,比如:类型转换、性能、统计,则交由框架来处理。
作为插件开发人员,则需要关注两个问题:
- 数据源本身的读写数据正确性。
- 如何与框架沟通、合理正确地使用框架。
二、插件视角看框架
逻辑执行模型
插件开发者基本只需要关注特定数据源系统的读和写,以及自己的代码在逻辑上是怎样被执行的,哪一个方法是在什么时候被调用的。开发之前需要明确以下概念:
Job:Job是DataX用以描述从一个源头到一个目的端的同步作业,是DataX数据同步的最小业务单元。比如:从一张mysql的表同步到odps的一个表的特定分区。Task:Task是为最大化而把Job拆分得到的最小执行单元。比如:读一张有1024个分表的mysql分库分表的Job,拆分成1024个读Task,用若干个并发执行。TaskGroup: 描述的是一组Task集合。在同一个TaskGroupContainer执行下的Task集合称之为TaskGroupJobContainer:Job执行器,负责Job全局拆分、调度、前置语句和后置语句等工作的工作单元。类似Yarn中的JobTrackerTaskGroupContainer:TaskGroup执行器,负责执行一组Task的工作单元,类似Yarn中的TaskTracker。
简而言之, Job拆分成Task,在分别在框架提供的容器中执行,插件只需要实现Job和Task两部分逻辑。
物理执行模型
框架为插件提供物理上的执行能力(线程)。DataX框架有三种运行模式:
Standalone: 单进程运行,没有外部依赖。Local: 单进程运行,统计信息、错误信息汇报到集中存储。Distrubuted: 分布式多进程运行,依赖DataX Service服务。
当然,上述三种模式对插件的编写而言没有什么区别,你只需要避开一些小错误,插件就能够在单机/分布式之间无缝切换了。
当JobContainer和TaskGroupContainer运行在同一个进程内时,就是单机模式(Standalone和Local);当它们分布在不同的进程中执行时,就是分布式(Distributed)模式。
编程接口
Job和Task的逻辑是怎么对应到具体的代码中的?
首先,插件的入口类必须扩展Reader或Writer抽象类,并且实现分别实现Job和Task两个内部抽象类,Job和Task的实现必须是 内部类 的形式,原因见 加载原理 一节。以Reader为例:
public class SomeReader extends Reader {
public static class Job extends Reader.Job {
@Override
public void init() {
}
@Override
public void prepare() {
}
@Override
public List<Configuration> split(int adviceNumber) {
return null;
}
@Override
public void post() {
}
@Override
public void destroy() {
}
}
public static class Task extends Reader.Task {
@Override
public void init() {
}
@Override
public void prepare() {
}
@Override
public void startRead(RecordSender recordSender) {
}
@Override
public void post() {
}
@Override
public void destroy() {
}
}
}
Job接口功能如下:
init: Job对象初始化工作,此时可以通过super.getPluginJobConf()获取与本插件相关的配置。读插件获得配置中reader部分,写插件获得writer部分。prepare: 全局准备工作,比如mysqlwriter在写入新数据之前执行一个truncate table的操作、读取Hive数据之前,完成Kerberos认证等。split: 拆分Task。参数adviceNumber框架建议的拆分数,一般是运行时所配置的并发度。值返回的是Task的配置列表。post: 全局的后置工作,比如mysqlwriter同步完影子表后的rename操作。destroy: Job对象自身的销毁工作。
Task接口功能如下:
init:Task对象的初始化。此时可以通过super.getPluginJobConf()获取与本Task相关的配置。这里的配置是Job的split方法返回的配置列表中的其中一个。prepare:局部的准备工作。startRead: 从数据源读数据,写入到RecordSender中。RecordSender会把数据写入连接Reader和Writer的缓存队列。startWrite:从RecordReceiver中读取数据,写入目标数据源。RecordReceiver中的数据来自Reader和Writer之间的缓存队列。post: 局部的后置工作。destroy: Task象自身的销毁工作。
需要注意的是:
Job和Task之间一定不能有共享变量,因为分布式运行时不能保证共享变量会被正确初始化。两者之间只能通过配置文件进行依赖。prepare和post在Job和Task中都存在,插件需要根据实际情况确定在什么地方执行操作。
框架按照如下的顺序执行Job和Task的接口:
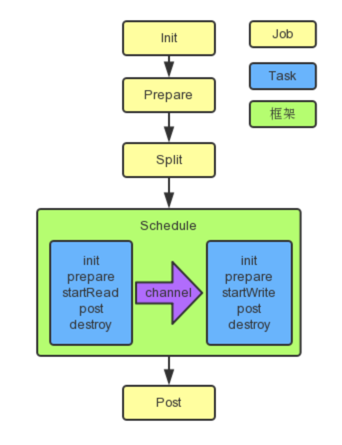
上图中,黄色表示Job部分的执行阶段,蓝色表示Task部分的执行阶段,绿色表示框架执行阶段。
相关类关系如下:
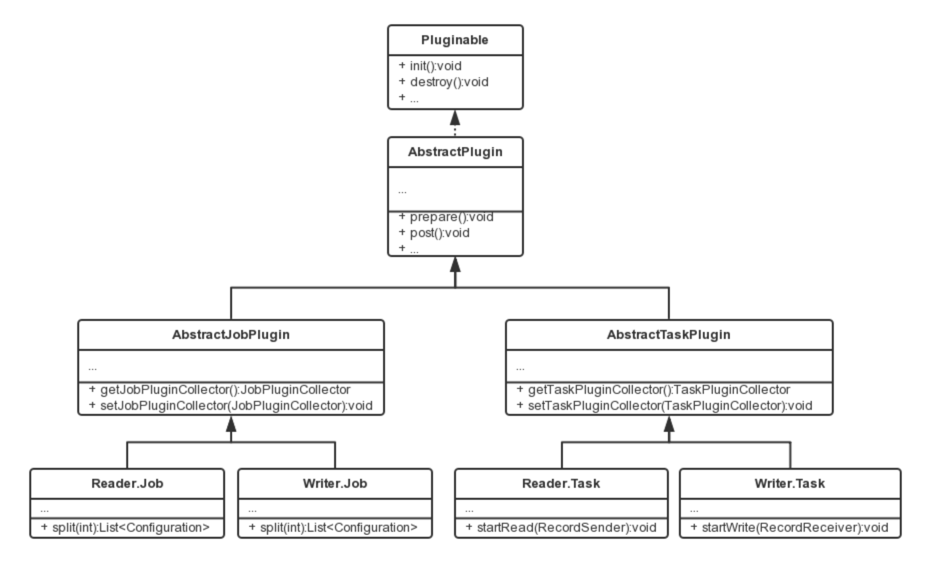
插件定义
代码写好了,有没有想过框架是怎么找到插件的入口类的?框架是如何加载插件的呢?
在每个插件的项目中,都有一个plugin.json文件,这个文件定义了插件的相关信息,包括入口类。例如:
{
"name": "mysqlwriter",
"class": "com.alibaba.datax.plugin.writer.mysqlwriter.MysqlWriter",
"description": "Use Jdbc connect to database, execute insert sql.",
"developer": "alibaba"
}
name: 插件名称,大小写敏感。框架根据用户在配置文件中指定的名称来搜寻插件。 十分重要 。class: 入口类的全限定名称,框架通过反射插件入口类的实例。十分重要 。description: 描述信息。developer: 开发人员。
打包发布
DataX使用assembly打包,assembly的使用方法请咨询谷哥或者度娘。打包命令如下:
mvn clean package -DskipTests assembly:assembly
DataX插件需要遵循统一的目录结构:
${DATAX_HOME}
|-- bin
| `-- datax.py
|-- conf
| |-- core.json
| `-- logback.xml
|-- lib
| `-- datax-core-dependencies.jar
`-- plugin
|-- reader
| `-- mysqlreader
| |-- libs
| | `-- mysql-reader-plugin-dependencies.jar
| |-- mysqlreader-0.0.1-SNAPSHOT.jar
| `-- plugin.json
`-- writer
|-- mysqlwriter
| |-- libs
| | `-- mysql-writer-plugin-dependencies.jar
| |-- mysqlwriter-0.0.1-SNAPSHOT.jar
| `-- plugin.json
|-- oceanbasewriter
`-- odpswriter
${DATAX_HOME}/bin: 可执行程序目录。${DATAX_HOME}/conf: 框架配置目录。${DATAX_HOME}/lib: 框架依赖库目录。${DATAX_HOME}/plugin: 插件目录。
插件目录分为reader和writer子目录,读写插件分别存放。插件目录规范如下:
${PLUGIN_HOME}/libs: 插件的依赖库。${PLUGIN_HOME}/plugin-name-version.jar: 插件本身的jar。${PLUGIN_HOME}/plugin.json: 插件描述文件。
尽管框架加载插件时,会把${PLUGIN_HOME}下所有的jar放到classpath,但还是推荐依赖库的jar和插件本身的jar分开存放。
注意:
插件的目录名字必须和plugin.json中定义的插件名称一致。
配置文件
DataX使用json作为配置文件的格式。一个典型的DataX任务配置如下:
{
"job": {
"content": [
{
"reader": {
"name": "odpsreader",
"parameter": {
"accessKey": "",
"accessId": "",
"column": [""],
"isCompress": "",
"odpsServer": "",
"partition": [
""
],
"project": "",
"table": "",
"tunnelServer": ""
}
},
"writer": {
"name": "oraclewriter",
"parameter": {
"username": "",
"password": "",
"column": ["*"],
"connection": [
{
"jdbcUrl": "",
"table": [
""
]
}
]
}
}
}
]
}
}
DataX框架有core.json配置文件,指定了框架的默认行为。任务的配置里头可以指定框架中已经存在的配置项,而且具有更高的优先级,会覆盖core.json中的默认值。
配置中job.content.reader.parameter的value部分会传给Reader.Job;job.content.writer.parameter的value部分会传给Writer.Job ,Reader.Job和Writer.Job可以通过super.getPluginJobConf()来获取。
DataX框架支持对特定的配置项进行RSA加密,例子中以*开头的项目便是加密后的值。 配置项加密解密过程对插件是透明,插件仍然以不带*的key来查询配置和操作配置项 。
如何设计配置参数
配置文件的设计是插件开发的第一步!
任务配置中reader和writer下parameter部分是插件的配置参数,插件的配置参数应当遵循以下原则:
驼峰命名:所有配置项采用驼峰命名法,首字母小写,单词首字母大写。
正交原则:配置项必须正交,功能没有重复,没有潜规则。
富类型:合理使用json的类型,减少无谓的处理逻辑,减少出错的可能。
- 使用正确的数据类型。比如,bool类型的值使用
true/false,而非"yes"/"true"/0等。 - 合理使用集合类型,比如,用数组替代有分隔符的字符串。
- 使用正确的数据类型。比如,bool类型的值使用
类似通用:遵守同一类型的插件的习惯,比如关系型数据库的
connection参数都是如下结构:{
"connection": [
{
"table": [
"table_1",
"table_2"
],
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:3306/database_1",
"jdbc:mysql://127.0.0.2:3306/database_1_slave"
]
},
{
"table": [
"table_3",
"table_4"
],
"jdbcUrl": [
"jdbc:mysql://127.0.0.3:3306/database_2",
"jdbc:mysql://127.0.0.4:3306/database_2_slave"
]
}
]
}
...
如何使用Configuration类
为了简化对json的操作,DataX提供了简单的DSL配合Configuration类使用。
Configuration提供了常见的get, 带类型get,带默认值get,set等读写配置项的操作,以及clone, toJSON等方法。配置项读写操作都需要传入一个path做为参数,这个path就是DataX定义的DSL。语法有两条:
- 子map用
.key表示,path的第一个点省略。 - 数组元素用
[index]表示。
比如操作如下json:
{
"a": {
"b": {
"c": 2
},
"f": [
1,
2,
{
"g": true,
"h": false
},
4
]
},
"x": 4
}
比如调用configuration.get(path)方法,当path为如下值的时候得到的结果为:
x:4a.b.c:2a.b.c.d:nulla.b.f[0]:1a.b.f[2].g:true
注意,因为插件看到的配置只是整个配置的一部分。使用Configuration对象时,需要注意当前的根路径是什么。
更多Configuration的操作请参考ConfigurationTest.java。
插件数据传输
跟一般的生产者-消费者模式一样,Reader插件和Writer插件之间也是通过channel来实现数据的传输的。channel可以是内存的,也可能是持久化的,插件不必关心。插件通过RecordSender往channel写入数据,通过RecordReceiver从channel读取数据。
channel中的一条数据为一个Record的对象,Record中可以放多个Column对象,这可以简单理解为数据库中的记录和列。
Record有如下方法:
public interface Record {
// 加入一个列,放在最后的位置
void addColumn(Column column);
// 在指定下标处放置一个列
void setColumn(int i, final Column column);
// 获取一个列
Column getColumn(int i);
// 转换为json String
String toString();
// 获取总列数
int getColumnNumber();
// 计算整条记录在内存中占用的字节数
int getByteSize();
}
因为Record是一个接口,Reader插件首先调用RecordSender.createRecord()创建一个Record实例,然后把Column一个个添加到Record中。
Writer插件调用RecordReceiver.getFromReader()方法获取Record,然后把Column遍历出来,写入目标存储中。当Reader尚未退出,传输还在进行时,如果暂时没有数据RecordReceiver.getFromReader()方法会阻塞直到有数据。如果传输已经结束,会返回null,Writer插件可以据此判断是否结束startWrite方法。
Column的构造和操作,我们在《类型转换》一节介绍。
类型转换
为了规范源端和目的端类型转换操作,保证数据不失真,DataX支持六种内部数据类型:
Long:定点数(Int、Short、Long、BigInteger等)。Double:浮点数(Float、Double、BigDecimal(无限精度)等)。String:字符串类型,底层不限长,使用通用字符集(Unicode)。Date:日期类型。Bool:布尔值。Bytes:二进制,可以存放诸如MP3等非结构化数据。
对应地,有DateColumn、LongColumn、DoubleColumn、BytesColumn、StringColumn和BoolColumn六种Column的实现。
Column除了提供数据相关的方法外,还提供一系列以as开头的数据类型转换转换方法。
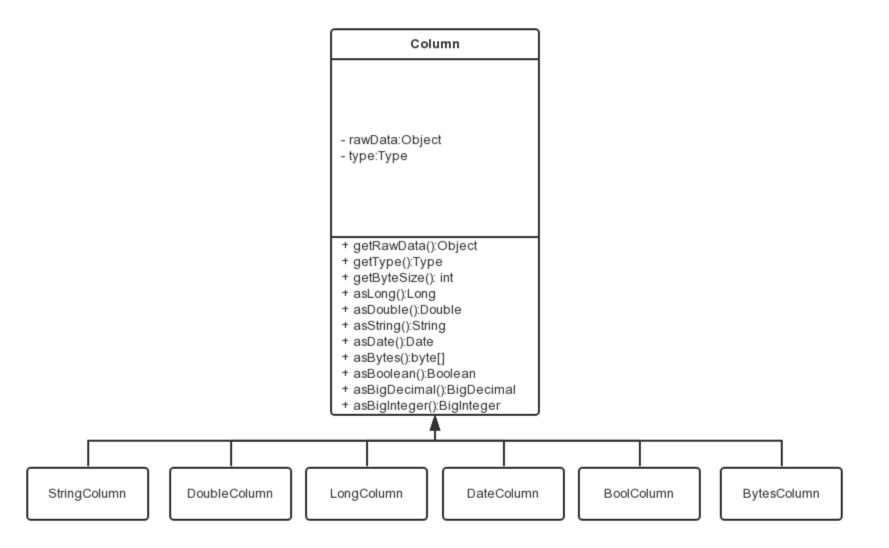
DataX的内部类型在实现上会选用不同的java类型:
| 内部类型 | 实现类型 | 备注 |
|---|---|---|
| Date | java.util.Date | |
| Long | java.math.BigInteger | 使用无限精度的大整数,保证不失真 |
| Double | java.lang.String | 用String表示,保证不失真 |
| Bytes | byte[] | |
| String | java.lang.String | |
| Bool | java.lang.Boolean |
类型之间相互转换的关系如下:
| from\to | Date | Long | Double | Bytes | String | Bool |
|---|---|---|---|---|---|---|
| Date | - | 使用毫秒时间戳 | 不支持 | 不支持 | 使用系统配置的date/time/datetime格式转换 | 不支持 |
| Long | 作为毫秒时间戳构造Date | - | BigInteger转为BigDecimal,然后BigDecimal.doubleValue() | 不支持 | BigInteger.toString() | 0为false,否则true |
| Double | 不支持 | 内部String构造BigDecimal,然后BigDecimal.longValue() | - | 不支持 | 直接返回内部String | |
| Bytes | 不支持 | 不支持 | 不支持 | - | 按照common.column.encoding配置的编码转换为String,默认utf-8 |
不支持 |
| String | 按照配置的date/time/datetime/extra格式解析 | 用String构造BigDecimal,然后取longValue() | 用String构造BigDecimal,然后取doubleValue(),会正确处理NaN/Infinity/-Infinity |
按照common.column.encoding配置的编码转换为byte[],默认utf-8 |
- | "true"为true, "false"为false,大小写不敏感。其他字符串不支持 |
| Bool | 不支持 | true为1L,否则0L |
true为1.0,否则0.0 |
不支持 | - |
脏数据处理
什么是脏数据?
目前主要有三类脏数据:
- Reader读到不支持的类型、不合法的值。
- 不支持的类型转换,比如:
Bytes转换为Date。 - 写入目标端失败,比如:写mysql整型长度超长。
如何处理脏数据
在Reader.Task和Writer.Task中,通过AbstractTaskPlugin.getTaskPluginCollector()可以拿到一个TaskPluginCollector,它提供了一系列collectDirtyRecord的方法。当脏数据出现时,只需要调用合适的collectDirtyRecord方法,把被认为是脏数据的Record传入即可。
用户可以在任务的配置中指定脏数据限制条数或者百分比限制,当脏数据超出限制时,框架会结束同步任务,退出。插件需要保证脏数据都被收集到,其他工作交给框架就好。
加载原理
- 框架扫描
plugin/reader和plugin/writer目录,加载每个插件的plugin.json文件。 - 以
plugin.json文件中name为key,索引所有的插件配置。如果发现重名的插件,框架会异常退出。 - 用户在插件中在
reader/writer配置的name字段指定插件名字。框架根据插件的类型(reader/writer)和插件名称去插件的路径下扫描所有的jar,加入classpath。 - 根据插件配置中定义的入口类,框架通过反射实例化对应的
Job和Task对象。
三、插件介绍文档
每个插件都必须在DataX官方wiki中有一篇文档,文档需要包括但不限于以下内容:
- 快速介绍:介绍插件的使用场景,特点等。
- 实现原理:介绍插件实现的底层原理,比如
mysqlwriter通过insert into和replace into来实现插入,tair插件通过tair客户端实现写入。 - 配置说明
- 给出典型场景下的同步任务的json配置文件。
- 介绍每个参数的含义、是否必选、默认值、取值范围和其他约束。
- 类型转换
- 插件是如何在实际的存储类型和
DataX的内部类型之间进行转换的。 - 以及是否存在特殊处理。
- 插件是如何在实际的存储类型和
- 性能报告
- 软硬件环境,系统版本,java版本,CPU、内存等。
- 数据特征,记录大小等。
- 测试参数集(多组),系统参数(比如并发数),插件参数(比如batchSize)
- 不同参数下同步速度(Rec/s, MB/s),机器负载(load, cpu)等,对数据源压力(load, cpu, mem等)。
- 约束限制:是否存在其他的使用限制条件。
- FAQ:用户经常会遇到的问题。
DataX插件二次开发指南的更多相关文章
- ECSHOP二次开发指南
ECSHOP二次开发指南 发布时间:2013-05-28 12:47:00 来源: 评论:0 点击: 次 [字号:大 中 小] QQ空间新浪微博腾讯微博人人网豆瓣网百度空间百度搜藏开心网复制更 ...
- 金蝶K3 wise 插件二次开发与配置
金蝶K3 wise 插件二次开发与配置 开发环境:K/3 Wise 13.0.K/3 Bos开发平台.Visual Basic 6.0 目录 一.二次开发插件编程二.代码演示三.配置插件四.测试插件五 ...
- [PC]PHPCMS二次开发指南(上)
------------------------------------------------------------------------------------- PHPCMS本身功能已经很完 ...
- ECMALL模板解析机制.MVC架构分析及文件目录说明.二次开发指南手册(转)
ECMALL模板解析语法与机制 http://www.nowamagic.net/architecture/archt_TemplateSyntaxAndAnalysis.php ECMALL模块开发 ...
- ECShop二次开发指南(一)
ECSHOP是一套完整的网络商店解决方案,包括前台的商品展示.购物流程和强大易用的后台管理.由于 ecshop简单易用,使用者几乎可以在3几分钟简单的设置一下就可以拥有一个网上商店系统,所以很多的B2 ...
- Harbor 定制页面 和 二次开发指南
harbor的官方地址:https://github.com/goharbor/harbor 想对Harbor进行二次开发,首先要指定一个harbor的版本,这里我们以Harbor:1.6.2为例: ...
- ECShop二次开发指南-文件结构(二)
ecshop文件架构说明 注意:因各版权不一,大概参考/* ECShop 2.5.1 的结构图及各文件相应功能介绍 ECShop2.5.1_Beta upload 的目录 ┣ activity.p ...
- ECSHOP - 二次开发指南---购物车篇
第一个问题 保存用户购物车数据ECSHOP的购物车数据,是以Session 方式存储在数据库里,并在Session结束后 ,Distroy 掉,解决方法是: 1.购物车内容读取方式. 更改登陆后购物车 ...
- Knockout应用开发指南(完整版) 目录索引
http://learn.knockoutjs.com/ 所有示例和代码都在在上面直接运行预览 注意:因为它用了google的cdn加速,所要要用代_理+_翻_墙才能正常加载 使用Knockout有 ...
- Knockout应用开发指南
Knockout应用开发指南 第一章:入门 2011-11-21 14:20 by 汤姆大叔, 20799 阅读, 17 评论, 收藏, 编辑 1 Knockout简介 (Introductio ...
随机推荐
- 还在用双层for循环吗?太慢了
前情提要 我们在开发中经常碰到这样的场景,查出两个 list 集合数据,需要根据他们相同的某个属性为连接点,进行聚合.但是平时我们使用的时候关注过性能吗?下面让我们一起来看看它的表现如何. 来个例子 ...
- 成熟企业级开源监控解决方案Zabbix6.2关键功能实战-上
@ 目录 概述 定义 监控作用 使用理解 监控对象和指标 架构组成 常用监控软件分析 版本选型 俗语 安装 部署方式 部署 zabbix-agent 概述 定义 Zabbix 官网地址 https:/ ...
- 畅联新增物联网设备接入协议:精华隆的NB一键报警
这个是有点时间了,这里记录一下! ----------------------------------------------------------------------------------- ...
- 【云原生 · Kubernetes】配置 Rancher docker 云平台
个人名片: 因为云计算成为了监控工程师 个人博客:念舒_C.ying CSDN主页️:念舒_C.ying 1.1 Rancher 概述 Rancher 是一个开源的企业级容器管理平台.通过 Ranc ...
- 列表、集合、元组、字典、range
#列表y = [1,2,3]# 追加y.append(4)print(y)#删除del y[3]print(y)#查询存放个数print(len(y))#查询位置内容print(y[0]) #正序pr ...
- (工具) 性能测试基准软件 lmBench (待补充)
1. lmBench 介绍 Lmbench是一套简易,可移植的,符合ANSI/C标准为UNIX/POSIX而制定的微型测评工具.一般来说,它衡量两个关键特征:反应时间和带宽.Lmbench旨在使系统开 ...
- 【Serverless】Unity快速集成认证服务实现邮件登录
概述: 认证服务可以为您的应用快速构建安全可靠的用户认证系统,您只需在应用中访问认证服务的相关能力,而不需要关心云侧的设施和实现. 本次将带来如何使用Unity编辑器快速集成认证服务SDK并实现邮箱 ...
- vue-element Form表单验证没错却一直提示错误
在使用element-UI 的表单时,发生一个验证错误,已输入值但验证的时候却提示没有输入 修改前 <el-form-item>中的prop绑定的是cus_name,而item里面的控件绑 ...
- MyBatis详解(一)
MyBatis简单介绍 [1]MyBatis是一个持久层的ORM框架[Object Relational Mapping,对象关系映射],使用简单,学习成本较低.可以执行自己手写的SQL语句,比较灵活 ...
- 关于Wegame页面空白的问题解决
前言 前几天帮亲戚家装电脑系统,装好后发现 wegame 所有页面都不能正确加载(全部是空白页面),很神奇,在网上找了很多种解决办法都没有效果,后来不过细心的我发现360浏览器一直提示我证书不安全过期 ...