Golang 汇编asm语言基础学习
Golang 汇编asm语言基础学习
一、CPU 基础知识
cpu 内部结构
cpu 内部主要是由寄存器、控制器、运算器和时钟四个部分组成。
寄存器:用来暂时存放指令、数据等对象。它是一个更快的内存。cpu 内部一般有 20 - 100 个寄存器。不同类型的cpu,它内部的寄存器数量、种类以及寄存器存储的数值范围都不相同。
控制器:它负责把内存上的指令、数据等读入寄存器,根据指令执行的结果来控制整个计算机。
运算器:它负责运算从内存读入寄存器的数据。
时钟:它负责发出 cpu 开始计时的时钟信号。时钟信号频率越高,cpu 的运行速度越快。
cpu 指令集
指令集架构,又叫指令集体系或指令集,是计算机系统中与程序设计有关,包含基本数据类型,指令集,寄存器,寻址模式,存储体系,中断,异常处理以及外部I/O。指令集架构包含一系列的 opcode 即操作码(机器语言)-- 维基百科。
就是用机器语言规定了一系列的操作指令,这些指令用来对cpu进行操作,或者说cpu能够运行这些指令。
不同的 cpu 类型有不同的指令集,比如intel AI-32,X86-64,ARM 等处理器都有不同的指令集架构。
机器语言:它是由声明和指令组成。
而指令一般包含以下几个部分:
- 用于算术运算,寻址或控制功能的特定寄存器
- 存储空间地址或偏移量
- 解释操作数的特定寻址模式
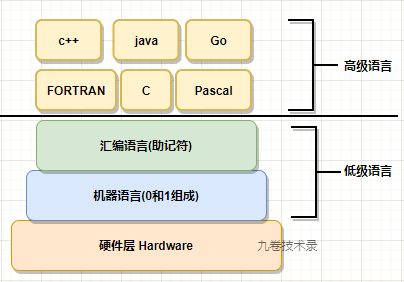
二、什么是汇编语言
维基百科解释:
汇编语言是任何一种用于电子计算机、微处理器、微控制器,或其他可编程器件的低级语言。在不同设备中,汇编语言对应着不同的机器语言指令集。
一种汇编语言专用于某种计算机系统结构,而不像许多高级语言,可以在不同系统平台之间移植
上面的解释一看,还是会让一般人起一头包,无法理解。
那就从另外一个方面来理解下,汇编语言的来历。
我们都知道计算机的组成,一般有 CPU,内存,主板,I/O 设备等。那 cpu 能够运行什么程序?我们可能会说,c,java 这种语言都可以运行啊。对又不对,对是因为我们平常编写的程序就是 c,c++,java,js,go 等这些语言,不对是因为这些语言是高级程序语言,从高级语言到 cpu 能够运行的语言,一般要经过一段旅程:
预处理 -> 编译 -> 汇编 -> 链接 -> 可执行程序
用 c 编写的程序编译流程图:

最后的可执行程序才是 cpu 可以运行的程序,cpu 只能运行由 0 和 1 组成的机器语言。比如规定0011,表示增加,0111,表示减少 。
最开始打孔编程时,程序员就是用这种用 0 和 1 组合方式来编写程序。想象一下,这种编程方式不仅编写速度慢,效率低下,更不容易阅读,且查找程序错误也非常困难。
为了解决这个问题,随着编程的发展,人们发明了汇编语言,汇编语言使用助记符来代替和表示低级机器语言(0 和 1)的操作,从而提高了编程的效率。比如汇编规定 add ,表示增加;sub ,表示减少。
但是我们仍然要为不同的 cpu 编写不同的汇编程序,因为每个 cpu 的机器指令集各不相同,汇编语言仍是一门低级语言。为了进一步提高效率,又发明了第一个正式推广的高级语言 FORTRAN。随后,各种高级语言不断出现。用各种高级语言编写程序符合人们思考事物、解决问题的习惯。
汇编语言是低级语言,用来描述、控制 cpu 的运行。如果想要了解 cpu 到底干了些啥,以及代码运行的步骤,可以学习汇编语言,来帮助你
了解 cpu 运行情况。汇编语言最终会编译成机器语言。
每一个原本是电子信号的机器语言指令都会有一个对应的助记符,而助记符通常为英文单词的缩写。
比如:mov 和 add 分别是 move(数据的存储) 和 addition(相加) 的缩写。汇编语言和机器语言基本是一一对应的。
把汇编语言转化为机器语言的程序称为汇编器。
三、Go 汇编和寄存器简介
plan9 汇编简介
通过上面内容知道,CPU 内部的存储单元是寄存器,用于存放从内存读取而来的数据、指令和存储 CPU 运算的中间结果。怎么操作这些寄存器?用机器语言,但是机器语言程序编写耗时耗力,排错也很困难,为了解决这些问题,人们发明了汇编语言。
Go 用了 plan9 汇编,使用的是 GAS 汇编语法(Gnu ASsembler),与 AT&T 汇编格式有很多相同之处,但也有不同之处。plan9 作者们是写 unix 操作系统的同一批人,大名鼎鼎的贝尔实验室开发的(Plan 9 From Bell Labs),其实 plan9 是一个操作系统。
plan9 汇编与 Intel 的汇编语法有明显的区别。
2 者指令和操作数位置是相反的:
GAS: MOVL AX BX // 将 AX 寄存器的值复制到 BX 寄存器中(复制也就是移动,移动数据)
Intel: MOV EBX EAX // 将 EAX 寄存器的值复制到 EBX 寄存器中
还有一些命令也不同,比如在 GAS 中,操作数的字长,movq 表示移动 8byte=64位 长度,movl 表示移动 4byte=32位 长度。在 intel 的汇编规则中则有不同,
GAS: MOVB $1 AL // 将 $1 的值复制到 AL 寄存器里
Intel-x64:
mov al, 0x44 // 1 byte
mov ah, 0x33 // 1 byte
mov rax, 0x1 // 8 bytes
汇编一般有2大分类:Intel 汇编 和 AT&T 汇编
- Intel 汇编:windows 系列的,因为有 win-intel 联盟,一般是 win 派系的 VC 编译器
- AT&T 汇编:Unix、Linux 和 Max OS ,一般是 GCC 编译器
plan9 通用寄存器
AX BX CX DX DI SI BP SP R8 R9 R10 R11 R12 R13 R14 R15 PC
BP : 基准指针寄存器。
应用代码用到的通用寄存器有14个:
AX, BX, CX, DX, DI, SI, R8~R15
伪寄存器
Go 汇编中有 4 个伪寄存器,这个 4 个伪寄存器是编译器用来维护上下文、特殊标识等作用的。
伪寄存器不是真正的寄存器,而是由工具链维护的虚拟(伪)寄存器,例如帧指针。
- FP, Frame Pointer, arguments and locals:帧指针,参数和本地 。指向当前 frame 起始位置
- SP, Stack Pointer, top of stack: 指向栈顶
- PC, Program Counter, jumps and branches: 程序计数器,跳转和分支
- SB, Static Base, global symbols: 静态基指针, 全局符号
所有用户定义的符号(局部数据、参数名等)都作为偏移量写入伪寄存器 FP(局部数据、输入参数、返回值) 和 SB(全局数据)。
也就是说 FP 和 SB 维护了用户空间的所有数据。
FP: 这个伪寄存器用来标识函数参数、返回值、局部数据。
用法:symbol+offset(FP)
symbol(符号) 表示参数变量名,offset 表示偏移量,相对于 FP 的偏移量, 比如:first_arg+0(FP) 表示函数第一个参数位置,偏移 0byte; second_arg+8(FP) 表示函数参数偏移 8byte 的另外参数。first_arg 只是一个标记,在汇编中first_arg 是不存在的。
操作命令:movq arg+8(FP), BX
前面知道 movq 命令是移动 8byte 长度的数据。这个命令意思:移动 8byte 长度的数据到 BX 寄存器,这个数据(arg+8(FP))偏移 FP 8byte。
SB:用来声明全局变量或声明函数
package main
func add() {}
上面的函数用命令编译后:
go tool compile -S -N -l .\demo1.go
"".add STEXT nosplit size=1 args=0x0 locals=0x0
0x0000 00000 (.\demo1.go:3) TEXT "".add(SB), NOSPLIT|ABIInternal, $0-0
... 其余的省略 ...
TEXT "".add(SB), NOSPLIT|ABIInternal, $0-0 这里声明了一个 add 函数。后面在详解。
一般情况下,都不会对 FP,SB 寄存器进行运算操作,而是以他们作为基准地址,进行偏移(上面的 offset)解引用操作。
PC:程序计数器,程序运行的下一个指令地址。
SP:plan9 中的 SP 指向当前栈帧的局部变量的开始位置。
SP: symbol+offset(SP) ,引用函数的局部变量,symbol 一般表示变量名,offset 表示局部变量距离 SP 的偏移量。
伪寄存器和硬件寄存器区别:
SP 有对应的硬件寄存器和伪寄存器,区分 SP 到底是指硬件寄存器还是指伪寄存器,需要以特定的格式来区分。
symbol+offset(SP) 则表示伪寄存器 SP。
offset(SP) 则表示硬件寄存器 SP。
这里 SP(Stack Pointer) 和 FP(Frame Pointer),很容易区别,SP 是整个函数栈起始位置指针。
把函数栈分成了很多小块 Frame , FP 就是指向这些小块 Frame 的指针。
想要了解汇编,我们还要继续学习一些计算机基础知识。下面从进程内存角度理解下伪寄存器 FP 和 SP。
四、进程的虚拟内存布局
在这篇 深入理解Go语言(07):内存分配原理 文章中,有一张图表示了进程在 linux 32位中的虚拟内存布局。根据这张图在画一个稍微简略点的内存模型图,
以便能更好的理解程序的栈和堆。

这里重点看 user stack 和 heap。
stack,编译器自动维护的内存空间,向下增长。heap,用户手动分配的内存空间,向上增长,比如 c 语言里 malloc 函数分配的内存空间就位于 heap 里。
常常说的函数调用栈,用的就是 user stack 这块内存空间。
前文提到的伪寄存器 FP、SP,没有关于 golang 调用栈的基础知识,一头包,很难理解,这里再进一步加强理解。
把上面的 user stack 栈内存空间单独拿出来,如下图:
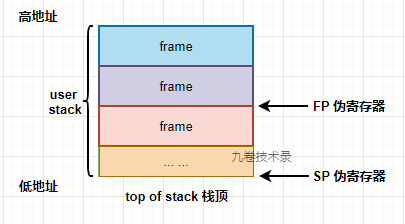
把 stack 栈空间又分割成了小块,叫 frame(帧),也叫 stack frame(栈帧)。
- FP, Frame Pointer, 指向当前 frame 起始位置
- SP, Stack Pointer, 指向栈顶,top of stack
五、Go 函数调用栈
在官方 stack.go 程序中的 Stack frame layout 图:
// Stack frame layout
//
// (x86)
// +------------------+
// | args from caller |
// +------------------+ <- frame->argp
// | return address |
// +------------------+
// | caller's BP (*) | (*) if framepointer_enabled && varp < sp
// +------------------+ <- frame->varp
// | locals |
// +------------------+
// | args to callee |
// +------------------+ <- frame->sp
//
// (arm)
// +------------------+
// | args from caller |
// +------------------+ <- frame->argp
// | caller's retaddr |
// +------------------+ <- frame->varp
// | locals |
// +------------------+
// | args to callee |
// +------------------+
// | return address |
// +------------------+ <- frame->sp
六、Go 汇编例子学习
Go 编译器会输出一种抽象可移植的汇编代码,这种汇编代码并不对应某种真实的硬件架构。Go 的汇编器会使用这些伪汇编,再为目标硬件生成具体的机器指令。
上面说了那么多,我们还没有真正感受到 go 的汇编语言,下面就来看看 go 语言编译成汇编是个啥样?
第一个汇编例子
编写一个 go 文件,demo1.go,例子来自《Go语言高级编程》:
package main
var Id = 9876
然后编译成 go 汇编语言, go1.15.13 windows/amd64
$ go tool compile -S .\demo1.go
go.cuinfo.packagename. SDWARFINFO dupok size=0
0x0000 6d 61 69 6e main
""..inittask SNOPTRDATA size=24
0x0000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
0x0010 00 00 00 00 00 00 00 00 ........
"".Id SNOPTRDATA size=8
0x0000 94 26 00 00 00 00 00 00 .&......
go tool compile:调用 go 语言提供的底层命令工具,-S 参数,表示输出汇编格式。
了解跟更多 compile 命令: go tool compile -h 。
在来看看汇编,前面的内容可以先不管,主要看最后一段:
"".Id SNOPTRDATA size=8
0x0000 94 26 00 00 00 00 00 00 .&......
"".Id:对应 Id 变量符号
size=8:变量的内存大小为 8 个字节,初始化内容 94 26 00 00 00 00 00 00,这个对应的是十六进制
SNOPTRDATA:相关标识,其中 NOPTR 表示不包含指针数据
// 还可以加上 -N -l 禁止内联优化
go tool compile -S -N -l demo1.go
第二个例子
写个复杂点的程序,demo2.go。
package pkg
func add(a, b int) int {
return a + b
}
go1.15.13 windows/amd64 下编译。
编译程序: go tool compile -S -N -l demo2.go
1 "".add STEXT nosplit size=25 args=0x18 locals=0x0
2 0x0000 00000 (demo2.go:3) TEXT "".add(SB), NOSPLIT|ABIInternal, $0-24
3 0x0000 00000 (demo2.go:3) FUNCDATA $0, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
4 0x0000 00000 (demo2.go:3) FUNCDATA $1, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
5 0x0000 00000 (demo2.go:3) MOVQ $0, "".~r2+24(SP)
6 0x0009 00009 (demo2.go:4) MOVQ "".a+8(SP), AX
7 0x000e 00014 (demo2.go:4) ADDQ "".b+16(SP), AX
8 0x0013 00019 (demo2.go:4) MOVQ AX, "".~r2+24(SP)
9 0x0018 00024 (demo2.go:4) RET
0x0000 48 c7 44 24 18 00 00 00 00 48 8b 44 24 08 48 03 H.D$.....H.D$.H.
0x0010 44 24 10 48 89 44 24 18 c3 D$.H.D$..
go.cuinfo.packagename. SDWARFINFO dupok size=0
0x0000 70 6b 67 pkg
gclocals·33cdeccccebe80329f1fdbee7f5874cb SRODATA dupok size=8
0x0000 01 00 00 00 00 00 00 00
第2行:TEXT "".add(SB), NOSPLIT|ABIInternal, $0-24
- TEXT "".add(SB):
TEXT, 指令声明 "".add 是一个 .text 文本段。在文章《深入理解Go语言(07):内存分配原理》中有进程的内存布局说明。
"".add,这是声明了一个函数的函数体。
""表示函数所在的包名,默认省略了,链接期间会替换为当前包名,pkg.add。SB,它是一个虚拟寄存器,保存了静态基地址指针,即是程序地址空间开始的地址。
- NOSPLIT|ABIInternal:
用于标识函数的一些特殊行为。NOSPLIT 表示子函数不进行栈分裂。ABIInternal 实验版本的calling convention,详情看这里
- $0-24:
常用 $framesize[-argsize] 表示,$framesize 表示将要分配的函数栈帧大小,包含调用其它函数时准备调用参数的隐式栈空间。argsize 表示参数和返回值的大小,-argsize 前面
-不是减号,而是一个分隔符。$0 代表将要分配的栈帧大小;24 代表调用方传入的参数大小。
第 3 、4 两行:FUNCDATA 都是与垃圾回收有关的信息,暂时不了解。
第 5 行:MOVQ $0, "".~r2+24(SP)
来一个复杂点的程序,相加相减例子 func_cal.go:
go1.15.13 windows/amd64
package main
func calculate(val1, val2 int) (sumret int, subret int) {
res1 := val1 + val2
res2 := val1 - val2
return res1, res2
}
func main() {
calculate(32, 53)
}
编译:go tool compile -S -N -l func_cal.go
输出汇编语言,先看看 add 函数的汇编:
1 "".calculate STEXT nosplit size=90 args=0x20 locals=0x18
2 0x0000 00000 (func_cal.go:3) TEXT "".calculate(SB), NOSPLIT|ABIInternal, $24-32
3 0x0000 00000 (func_cal.go:3) SUBQ $24, SP
4 0x0004 00004 (func_cal.go:3) MOVQ BP, 16(SP)
0x0009 00009 (func_cal.go:3) LEAQ 16(SP), BP
0x000e 00014 (func_cal.go:3) FUNCDATA $0, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x000e 00014 (func_cal.go:3) FUNCDATA $1, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x000e 00014 (func_cal.go:3) MOVQ $0, "".sumret+48(SP)
0x0017 00023 (func_cal.go:3) MOVQ $0, "".subret+56(SP)
0x0020 00032 (func_cal.go:4) MOVQ "".val1+32(SP), AX
0x0025 00037 (func_cal.go:4) ADDQ "".val2+40(SP), AX
0x002a 00042 (func_cal.go:4) MOVQ AX, "".res1+8(SP)
0x002f 00047 (func_cal.go:5) MOVQ "".val1+32(SP), AX
0x0034 00052 (func_cal.go:5) SUBQ "".val2+40(SP), AX
0x0039 00057 (func_cal.go:5) MOVQ AX, "".res2(SP)
0x003d 00061 (func_cal.go:6) MOVQ "".res1+8(SP), AX
0x0042 00066 (func_cal.go:6) MOVQ AX, "".sumret+48(SP)
0x0047 00071 (func_cal.go:6) MOVQ "".res2(SP), AX
0x004b 00075 (func_cal.go:6) MOVQ AX, "".subret+56(SP)
0x0050 00080 (func_cal.go:6) MOVQ 16(SP), BP
0x0055 00085 (func_cal.go:6) ADDQ $24, SP
0x0059 00089 (func_cal.go:6) RET
第2行:TEXT "".calculate(SB), NOSPLIT|ABIInternal, $24-32
TEXT:函数标识符的汇编指令
"".calculate(SB):"",这个地方应该是包名,这里省略了,用
""表示。calculate 函数名。calculate(SB) 表示函数名相对于 SB 伪寄存器的偏移量,二者组合就可以表示函数的具体位置。NOSPLIT|ABIInternal:函数标识位,用于表示函数的一些特殊行为。NOSPLIT 表示子函数不进行栈分裂。ABIInternal 实验版本的calling convention,详情看这里
$24-32:常用 $framesize[-argsize] 表示,$framesize 表示函数栈帧大小,包含调用其它函数时准备调用参数的隐式栈空间。argsize 表示参数和返回值的大小,前面
-不是减号,而是一个连接符。
第3行:SUBQ $24, SP
这里 SUBQ 做减法,为函数分配函数栈帧,SP 这里表示硬件寄存器。如果是 $0x 开头,那么表示十六进制数。这里默认为十进制,24个字节。
plan9 中操有 push 和 pop,但一般生成的代码中是没有的,它是通过 SUB 和 ADD 调整栈大小,是通过对硬件 SP 寄存器进行运算来实现的。
ADDQ $8, SP, 对 SP 做加法,清除函数栈帧。
把 Go 程序编译成汇编语言的命令:
go build -gcflags "-N -l" -ldflags=-compressdwarf=false -o main.out main.go
go tool objdump -s "main.main" main.out > main.S
// or
go tool compile -S main.go
// or
go build -gcflags -S main.go
汇编怎么定义变量
汇编代码中用来表示用户定义的符号(变量)时,可以用寄存器和偏移量还有变量名的组合来表示。
比如:x-8(SP),因为 SP 指向的是栈顶,所以偏移值都是负的,x则表示变量名
七、定义整型变量
package pkg
var Id = 9527
用下面的命令查看Go的语言程序对应的伪汇编代码:
$ go tool compile -S pkg.go # or: go build -gcflags -S pkg.go
"".Id SNOPTRDATA size=8
0x0000 37 25 00 00 00 00 00 00 '.......
其中go tool compile 命令用于调用Go语言提供的底层命令工具,其中-S参数表示输出汇编格式。
输出的汇编比较简单,其中 "".Id 对应 Id 变量符号,变量的内存大小为8个字节。变量的初始化内容为37 25 00 00 00 00 00 00,对应十六进制格式的0x2537,对应十进制为9527。
SNOPTRDATA是相关的标志,其中NOPTR表示数据中不包含指针数据。
以上的内容只是目标文件对应的汇编,和Go汇编语言虽然相似当并不完全等价。Go语言官网自带了一个Go汇编语言的入门教程,地址在:https://golang.org/doc/asm 。
DATA 命令用于初始化包变量
Go汇编语言提供了 DATA 命令用于初始化包变量,DATA命令的语法如下:
DATA symbol+offset(SB)/width, value
symbol 为变量在汇编语言中对应的标识符,
offset 是符号相对于SB的偏移量,
width 是要初始化内存的宽度大小,
value 是要初始化的值,
其中当前包中Go语言定义的符号symbol,在汇编代码中对应 ·symbol,其中“·”中点符号为一个特殊的unicode符号。
我们采用以下命令可以给Id变量初始化为十六进制的0x2537,对应十进制的9527(常量需要以美元符号$开头表示):
DATA ·Id+0(SB)/1, $0x37
DATA ·Id+1(SB)/1, $0x25
(未完待续)
八、参考
https://chai2010.cn/advanced-go-programming-book/ch3-asm/ch3-01-basic.html
https://studygolang.com/articles/12828
https://goroutines.com/asmhttps://golang.design/under-the-hood/zh-cn/part1basic/ch01basic/asm/
Golang 汇编asm语言基础学习的更多相关文章
- D02-R语言基础学习
R语言基础学习——D02 20190423内容纲要: 1.前言 2.向量操作 (1)常规操作 (2)不定长向量计算 (3)序列 (4)向量的删除与保留 3.列表详解 (1)列表的索引 (2)列表得元素 ...
- D01-R语言基础学习
R语言基础学习——D01 20190410内容纲要: 1.R的下载与安装 2.R包的安装与使用方法 (1)查看已安装的包 (2)查看是否安装过包 (3)安装包 (4)更新包 3.结果的重用 4.R处理 ...
- D03——C语言基础学习PYTHON
C语言基础学习PYTHON——基础学习D03 20180804内容纲要: 1 函数的基本概念 2 函数的参数 3 函数的全局变量与局部变量 4 函数的返回值 5 递归函数 6 高阶函数 7 匿名函数 ...
- D03-R语言基础学习
R语言基础学习——D03 20190423内容纲要: 1.导入数据 (1)从键盘输入 (2)从文本文件导入 (3)从excel文件导入 2.用户自定义函数 3.R访问MySQL数据库 (1)安装R ...
- go语言基础学习
go基础学习,面向对象-方法在Go语言中,可以给任意自定义类型(包括内置类型,但不包括指针类型)添加相应的方法 使用= 和:=的区别: // = 使用必须使用先var声明例如: var a a=100 ...
- C# 语言基础学习路线图
一直以来,对于很多知识点都是存于收藏夹中,随着时间地变更,收藏夹中链接也起来越多,从未进行整理,也很零散,所以想对曾经遇到并使用过的一些知识形成文档,作为个人知识库的一部分. 就从C# 语言基础开始, ...
- C语言基础学习基本数据类型-变量的命名
变量的命名 变量命名规则是为了增强代码的可读性和容易维护性.以下为C语言必须遵守的变量命名规则: 1. 变量名只能是字母(A-Z,a-z),数字(0-9)或者下划线(_)组成. 2. 变量名第一个字母 ...
- 从零开始系列-R语言基础学习笔记之二 数据结构(二)
在上一篇中我们一起学习了R语言的数据结构第一部分:向量.数组和矩阵,这次我们开始学习R语言的数据结构第二部分:数据框.因子和列表. 一.数据框 类似于二维数组,但不同的列可以有不同的数据类型(每一列内 ...
- C语言基础学习
汇编语言又叫符号语言 出来机器语言和汇编语言外其他语言必须经过翻译(编译,和解释行)才可以执行 .c --> 编译(翻译成二进制代码 .obj) 链接 把目标程序和库函数以及其他目标程序链接起来 ...
随机推荐
- 每日一题20180330-Linux
一.问题 1.1 统计/var/log/下所有文件个数 1.2 查找出/var/log目录下面修改时间是7天以前,大小在50k到2M之间,并以.log结尾的文件把这些文件复制到/data目录中 1.3 ...
- 102_Power Pivot DAX 排名后加上总排名数
焦棚子的文章目录 请点击下载附件 1.背景 每次写rank的时候,有了排名就可以了,排名1,2,3,4,5这样不是很清晰吗?但是中国式报表的老板们说你能不能在排名后面加一个总排名数呢,就像1/5,2/ ...
- [漏洞复现] [Vulhub靶机] Struts2-045 Remote Code Execution Vulnerablity(CVE-2017-5638)
免责声明:本文仅供学习研究,严禁从事非法活动,任何后果由使用者本人负责. 0x00 背景知识 Apache Struts 2是美国Apache软件基金会的一个开源项目,是一套用于创建企业级Java W ...
- 安装Zookeeper到Linux
系统版本:Ubuntu 16.04.5 LTS 软件版本:apache-zookeeper-3.5.8 硬件要求:无 1.安装依赖 Zookeeper需要JDK的支持. 注:需要先去JDK官网下载安装 ...
- Vulhub靶场搭建教程
Vulhub靶机环境搭建 Vulhub地址: Vulhub下载地址 一.所需环境 1.Ubuntu16.04 2.最新版本Docker 二.安装之路 1.下载Ubuntu16.04下载地址(迅雷下载6 ...
- C#中的CSV文件读写
目录 CSV文件标准 文件示例 RFC 4180 简化标准 读写CSV文件 使用CsvHelper 使用自定义方法 基于简化标准的写CSV文件 使用TextFieldParser解析CSV文件 使用正 ...
- BUUCTF-来首歌吧
来首歌吧 歌曲题目一般就是整个摩斯电码 看上面的样子应该就是摩斯电码解密一下 ..... -... -.-. ----. ..--- ..... -.... ....- ----. -.-. -... ...
- RPA应用场景-公积金贷款业务数据整合和报送
场景概述 公积金贷款业务数据整合和报送 所涉系统名称 个贷系统.公积金管理系统 人工操作(时间/次) 0.5小时 所涉人工数量1000操作频率 每日 场景流程 1.机器人整理个人贷款信息.个人贷款账户 ...
- UiPath文本操作Get Text的介绍和使用
一.Get Text操作的介绍 从指定的UI元素提取文本值 二.Get Text在UiPath中的使用 1. 打开设计器,在设计库中新建一个Sequence,为序列命名及设置Sequence存放的路径 ...
- bat-配置环境变量2-给PATH追加环境变量
使用setx /M path "%path%;%%winrar%%"这种方式修改环境变量存在的问题 对于 path 这种 既有用户级变量和系统级变量的变量 直接使用setx /M ...