步态识别《GaitSet: Regarding Gait as a Set for Cross-View Gait Recognition》2018 CVPR
Motivation:
步态可被当作一种可用于识别的生物特征在刑侦或者安全场景发挥重要作用。但是现有的方法要么是使用步态模板(能量图与能量熵图等)导致时序信息丢失,要么是要求步态序列连续,导致灵活性差。这篇文章是将步态当成包含独立帧的集合,不要求帧的排列顺序甚至可以把不同场景下的视频帧整合在一起。
Method:
问题定义:给定一个有N个人的数据集$y_{i}, i \in 1,2,...,N$, 我们假定某个人的步态遮罩属于分布$\mathcal{P}_{i}$,这是个只与行人身份有关的量。因此,某个人的一个或者多个序列的所有遮罩可以视为$n$个剪影的集合$\mathcal{X}_{i}=\left\{x_{i}^{j} | j=1,2,...,n\right\}$。这里的$x_{i}^{j} \sim \mathcal{P}_{i}$。
在前面这种假设下,我们通过三步解决步态识别任务,可以公式化为:
$f_{i}=H\left(G\left(F\left(\mathcal{X}_{i}\right)\right)\right)$
这里的$F$是一个用来提取帧级特征的卷积神经网络。公式$G$是一个置换不变函数来将frame-level特征变成set level特征,具体是通过下面提到的$Set Pooling$来实现的。$H$则是从set-level特征中提取有区分力的表达$\mathcal{P}_{i}$,是通过$HPM$(水平金字塔映射)实现的。输入$\mathcal{X}_{i}$则是一个四维张量,也就是set维,通道维,高度,宽度。
放一张网络框架图:
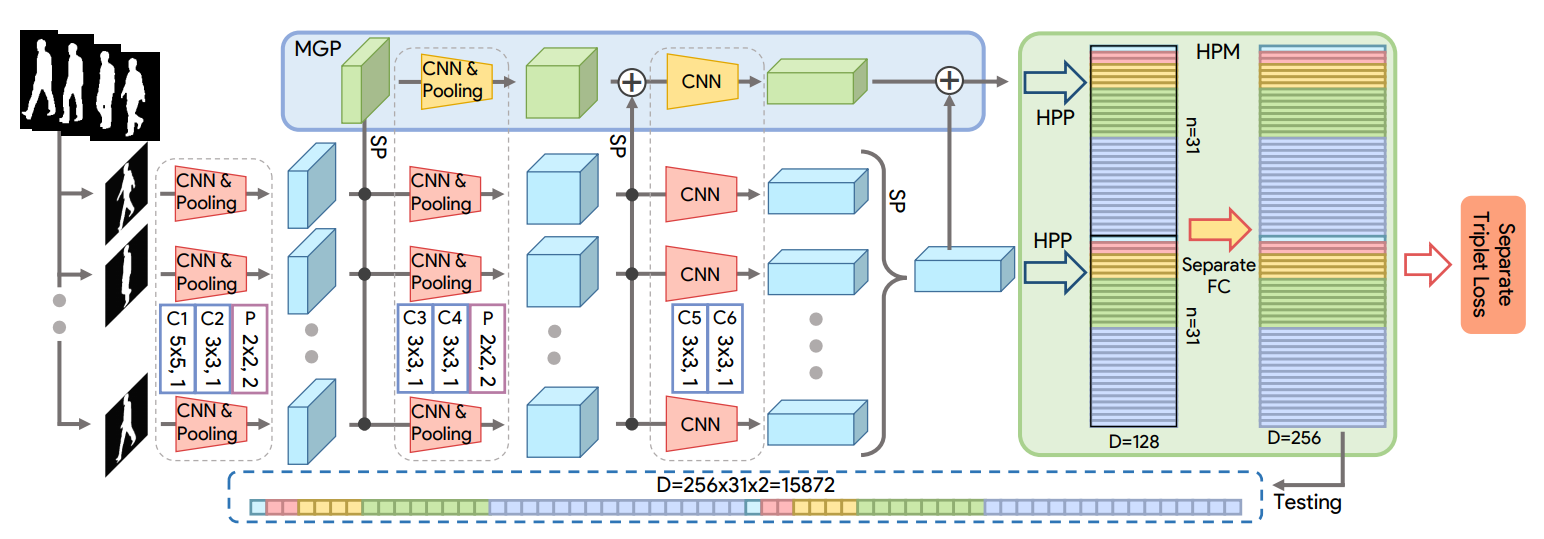
Set Pooling:
Set pooling的目的是将集合中的步态信息整合在一起,也就是$z=G(V)$,这里$z$表示set-level特征,$V=\left\{v^{j} | j=1,2, \ldots, n\right\}$表示frame-level特征。Set Pooling接收set作为输入,是一个排列不变函数,公式化为:
$G\left(\left\{v^{j} | j=1,2, \ldots, n\right\}\right)=G\left(\left\{v^{\pi(j)} | j=1,2, \ldots, n\right\}\right)$
这里的$\pi$是任何一种排列。因为现实场景下,人物步态遮罩数目是任意的,函数$G$应该能够处理任意任意基数的set。
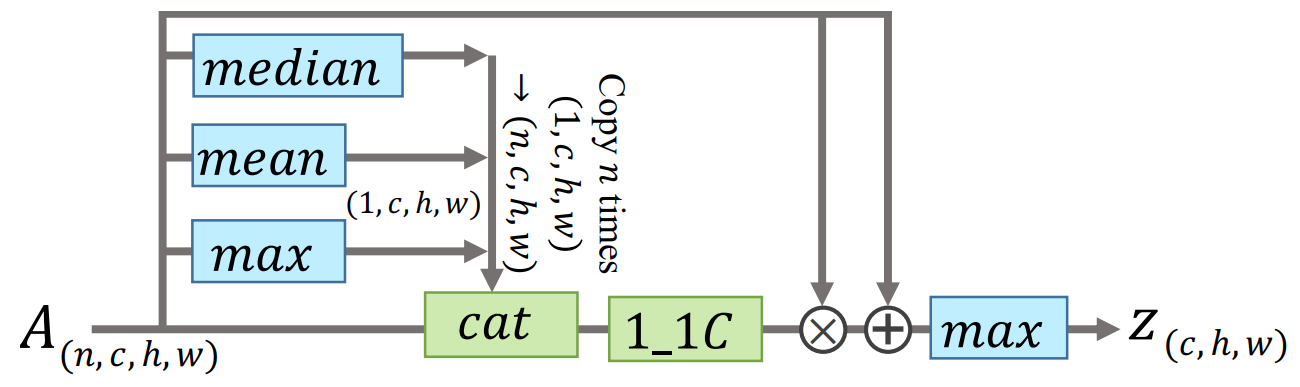
1.统计函数:为了满足前面的要求也就是排列不变,数目容量可变,在set维使用统计函数是一个自然的选择。本文是使用了$max()$,$mean()$,$median()$三种。
2.联合函数:也就是前面三者的结合,可以分为两种:1)$G(\cdot)=\max (\cdot)+\operatorname{mean}(\cdot)+\operatorname{median}(\cdot)$,2)$G(\cdot)=1_{-} 1 \mathrm{C}(\operatorname{cat}(\max (\cdot), \operatorname{mean}(\cdot), \operatorname{median}(\cdot)))$。
这里cat表示的是通道维拼接,$1_{-} 1 C$表示1*1卷积。
作者也使用了注意力机制来提高SP的表现,motivation是利用全局信息来学习元素级注意力图来修正frame-level特征。全局特征先通过左侧的统计函数获取,之后将它输入进$1*1$卷积层同原始特征图计算注意力。最终的set-level级特征是通过在修正后的全局特征上应用MAX得到。采用了残差结构来加速与稳定收敛。
水平金字塔映射(HPM):
在行人重识别任务中经常把特征划分为水平块,这里也是借鉴了这个做法。$HPM$有4个不同尺寸能够帮助神经网络聚焦到不同的局部特征和全局特征。下图描述得比较清楚,假设共有$S$个尺寸,在s这个尺寸,特征在高度维上进行切分被分成了$2^{s-1}$块,所以总共是可以分成$\sum_{s=1}^{S} 2^{s-1}$块。接着利用全局池化($Global Pooling$)来将划分得到的$3D$块变成$1D$的$f^{\prime}$。最后对$f^{\prime}$使用不同的$FC$层做映射得到有区分力的$f$。

Multilayer Global Pipeline :
简单来说越深的层有着越大的感受野,浅层关注的是局部和精细化特征,而深层关注全局和粗粒度特征。同理不同深度上SP得到的特征也是有这个特性的。为了利用不同深度的特征就提出了Multilayer Global Pipeline(MGP),和主pipline的流程是差不多的,就是把不同层的set-level特征加到MGP中。最后MGP也是通过前面的HPM划分为$\sum_{s=1}^{S} 2^{s-1}$个块。MGP后面的HPM和主pipline的HPM是不共享参数的。
训练和测试:
训练损失:网络的输出是$2 \times \sum_{s=1}^{S} 2^{s-1}$的d维向量。在这里使用的是批三元损失。使用了$p \times k$的采样策略。$p$是人物数,$k$是一批中每个人的样本数,这里的每个样本其实包含了从序列中采集的多个遮罩图。
测试:给定查询$\mathcal{Q}$,步态识别的目标是从图库集合$\mathbb{C}$中查询获得该人物所有序列。测试时先将$\mathcal{Q}$输入到GaitSet产生多种尺寸的特征然后concatenate到一起获得最终表达$\mathcal{F}_{\mathcal{Q}}$。同理我们对图库中的样本$\mathcal{G}$也进行这个操作得到$\mathcal{F}_{\mathcal{G}}$。最后计算$\mathcal{F}_{\mathcal{Q}}$与每个$\mathcal{F}_{\mathcal{G}}$的欧式距离作比较计算Rank 1识别率。
实验:
从作者的消融实验来看,其提出的几个模块是有效果的。带来效果比较突出的是使用set作为输入,以及使用独立FC和不同深度特征融合这几大点。

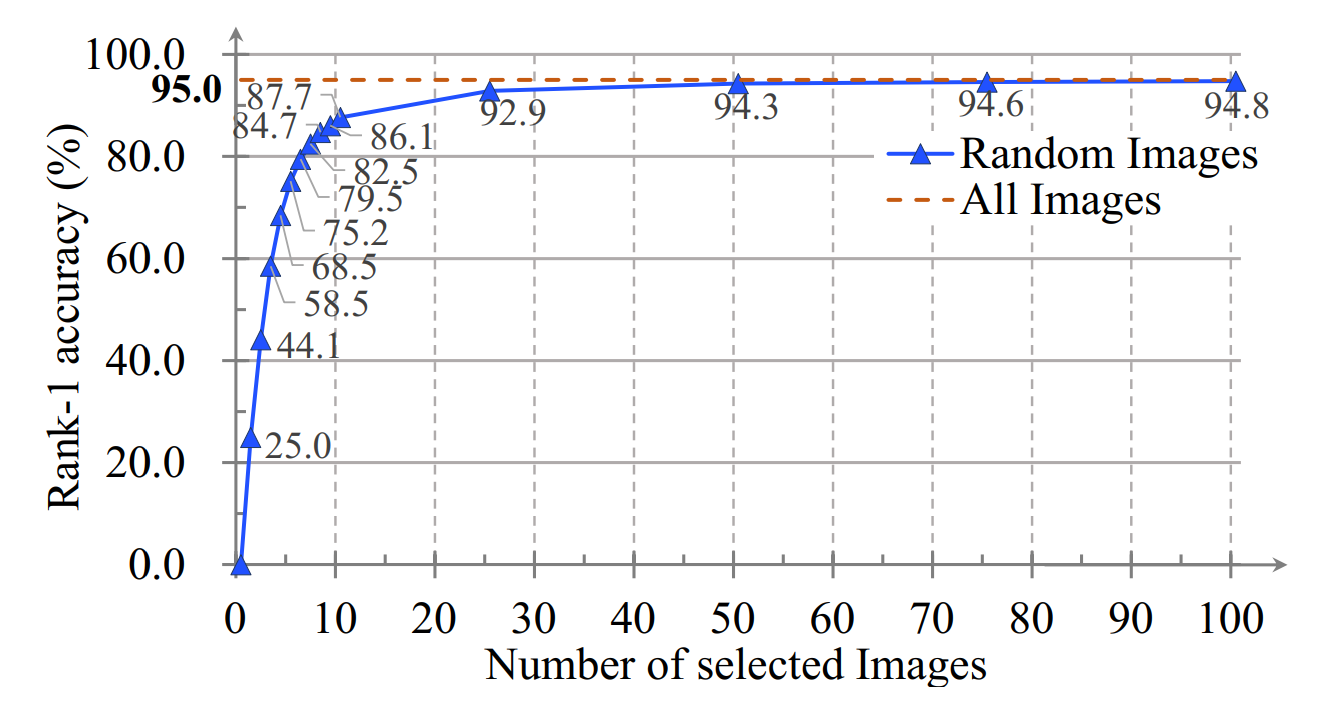
作者做了几个有意思的实验,一个是遮罩数目对识别准确率的影响,可以看到1)精度随着轮廓数量的增加而单调增加;2)当样本包含25个以上轮廓时,精度接近最佳性能。这个数字与一个步态周期包含的帧数一致。
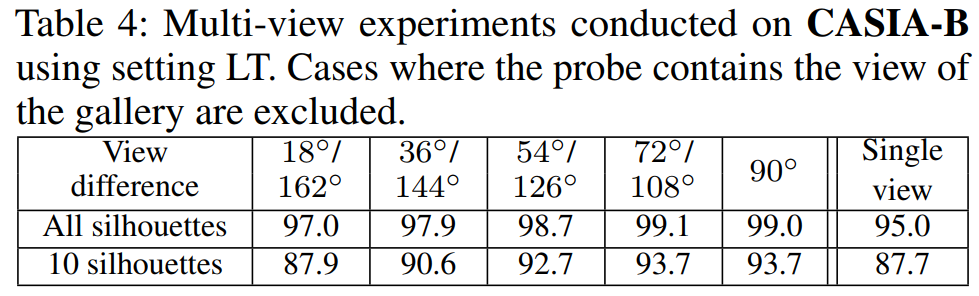
下面的实验是将不同视角的遮罩放在一起组成查询(图库不变),比如第二行前几列是从两个相差一定角度间隔的序列中各采样5张,而最后一列Sigle view是从单个序列中选择10张。可以看到多视角的更好一点,这表明改模型能够利用多视角带来的平行以及垂直信息。
作者同时还做了不同行走条件的影响,结果如下所示,表明增加遮罩数是可以带来效果提升的,即使是背包或者穿大衣这种带有噪声的遮罩。

步态识别《GaitSet: Regarding Gait as a Set for Cross-View Gait Recognition》2018 CVPR的更多相关文章
- 记C# 调用虹软人脸识别 那些坑
上一个东家是从事安防行业的,致力于人工智能领域,有自主人脸识别.步态识别的算法.C++同事比较称职有什么问题都可以第一时间反馈,并得到合理的处理,封装的DLL 是基于更高性能的GPU算法,可支持更多线 ...
- 基于安卓高仿how-old.net实现人脸识别估算年龄与性别
前几段微软推出的大数据人脸识别年龄应用how-old.net在微博火了一把,它可以通过照片快速获得照片上人物的年龄,系统会对瞳孔.眼角.鼻子等27个“面部地标点"展开分析,进而得出你的“颜龄 ...
- Activity Recognition行为识别
暑假听了computer vision的一个Summer School,里面Jason J. Corso讲了他们运用Low-Mid-High层次结构进行Video Understanding 和 Ac ...
- 第十八节、基于传统图像处理的目标检测与识别(HOG+SVM附代码)
其实在深度学习中我们已经介绍了目标检测和目标识别的概念.为了照顾一些没有学过深度学习的童鞋,这里我重新说明一次:目标检测是用来确定图像上某个区域是否有我们要识别的对象,目标识别是用来判断图片上这个对象 ...
- face recognition[翻译][深度人脸识别:综述]
这里翻译下<Deep face recognition: a survey v4>. 1 引言 由于它的非侵入性和自然特征,人脸识别已经成为身份识别中重要的生物认证技术,也已经应用到许多领 ...
- 使用OpenCV进行人脸识别
不断维护的地址:http://plzcoding.com/face-recognition-with-opencv/ 怎样使用OpenCV进行人脸识别 本文大部分来自OpenCV官网上的Face Re ...
- 生物医学命名实体识别(BioNER)研究进展
生物医学命名实体识别(BioNER)研究进展 最近把之前整理的一些生物医学命名实体识别(Biomedical Named Entity Recognition, BioNER)相关的论文做了一个Bio ...
- Appium自动化测试之微信h5元素识别和代码实战
总会有人问微信的自动化测试怎么做.其实我不太明白,为啥你要对ta做自动化测试啊,除非你们公司产品是基于微信做的开发否则没必要.即使一个公众号我也觉得没必要做自动化测试,基本功能点下没问题就可以了,毕竟 ...
- (转载)人脸识别中Softmax-based Loss的演化史
人脸识别中Softmax-based Loss的演化史 旷视科技 近期,人脸识别研究领域的主要进展之一集中在了 Softmax Loss 的改进之上:在本文中,旷视研究院(上海)(MEGVII Re ...
随机推荐
- Glade To Code 介绍
Glade To Code 简介 根据 Glade 文件生成指定语言的 GTK 代码的工具 使用说明 python3 glade-to-code.py -l [语言类型] -i [输入 Glade 文 ...
- ICO图标在线生成转换网站
ico是Icon file的缩写,是Windows的图标文件格式的一种,可以存储单个图案.多尺寸.多色板的图标文件. 在Windows操作系统中,单个图标的文件名后缀是.ICO.这种格式的图标可以在W ...
- Synchronized锁及其膨胀
一.序言 在并发编程中,synchronized锁因其使用简单,在线程间同步被广泛应用.下面对其原理及锁升级过程进行探究. 二.如何使用 1.修饰实例方法 当实例方法被synchronized修饰时, ...
- python跑机器学习时报错:Process finished with exit code -1073740791 (0xC0000409)
emmm...第二次遇到这个错误了,好好的好好的卷积神经网络突然就跑不起了.就弹出一堆信息也不报那行代码错了... 记录一下: 两次解决方法相同,删h5py包 Process finished wit ...
- [题解] trip
题目大意 给定一颗大小为 \(N\) 的树, \(1\)的度数不小于 \(2\) .每个点有一个颜色,要么为黑色要么为白色. 从 \(1\) 号点开始游走,计数器初始为 \(0\). 如果当前为黑点计 ...
- 一次 HTTP 请求就需要一次 TCP 连接吗?
一次 HTTP 请求就需要一次 TCP 连接吗? 本文写于 2021 年 2 月 9 日 太长不看版本:短连接需要,长连接不需要. 一次 HTTP 请求就需要一次 TCP 连接吗? TCP 的连接与断 ...
- mybatis plus 的 ActiveRecord 模式
实体类继承 Model public class Test extends Model<Test> implements Serializable {} 就可以 new Test().in ...
- Install Ubuntu on Windows Subsystem for Linux
安装参考 ubuntu.com/wsl microsoft/wsl/install-manual microsoft/terminal 错误解决方案 github/启动 WSL 2时警告"参 ...
- Spring Boot整合模板引擎freemarker
jsp本质是servlet,渲染都在服务器,freemarker模板引擎也是在服务器端渲染. 项目结构 引入依赖pom.xml <!-- 引入 freemarker 模板依赖 --> &l ...
- linux篇-linux面试题汇总
Linux经典面试题,看看你会几题? 1. 在Linux系统中,以 文件 方式访问设备 . 2. Linux内核引导时,从文件 /etc/fstab 中读取要加载的文件系统. 3. Linux文件系统 ...