聊聊如何用 Redis 实现分布式锁?
作者:小林coding
计算机八股文网站:https://xiaolincoding.com
哈喽,我是小林。
今天跟大家聊聊两个问题:
- 如何用 Redis 实现分布式锁?
- Redis 是如何解决集群情况下分布式锁的可靠性问题的?
如何用 Redis 实现分布式锁的?
分布式锁是用于分布式环境下并发控制的一种机制,用于控制某个资源在同一时刻只能被一个应用所使用。如下图所示:
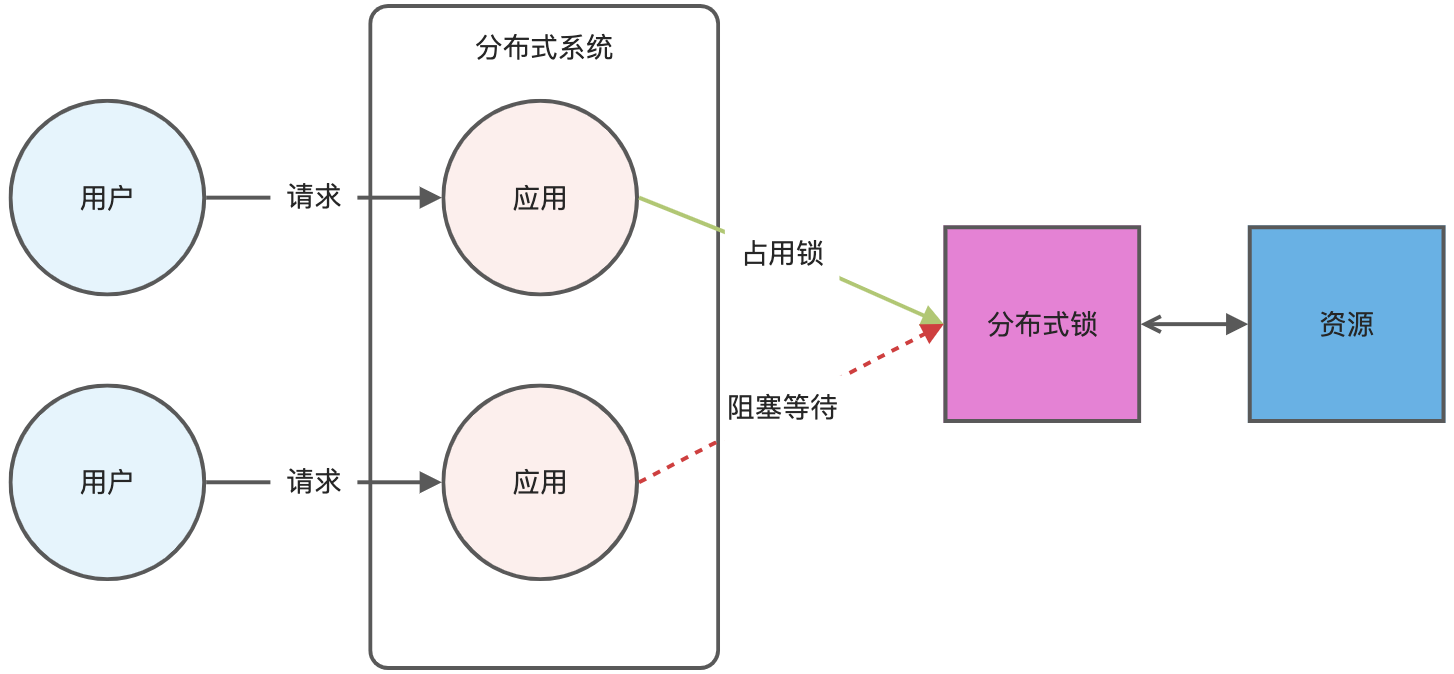
Redis 本身可以被多个客户端共享访问,正好就是一个共享存储系统,可以用来保存分布式锁,而且 Redis 的读写性能高,可以应对高并发的锁操作场景。
Redis 的 SET 命令有个 NX 参数可以实现「key不存在才插入」,所以可以用它来实现分布式锁:
- 如果 key 不存在,则显示插入成功,可以用来表示加锁成功;
- 如果 key 存在,则会显示插入失败,可以用来表示加锁失败。
基于 Redis 节点实现分布式锁时,对于加锁操作,我们需要满足三个条件。
- 加锁包括了读取锁变量、检查锁变量值和设置锁变量值三个操作,但需要以原子操作的方式完成,所以,我们使用 SET 命令带上 NX 选项来实现加锁;
- 锁变量需要设置过期时间,以免客户端拿到锁后发生异常,导致锁一直无法释放,所以,我们在 SET 命令执行时加上 EX/PX 选项,设置其过期时间;
- 锁变量的值需要能区分来自不同客户端的加锁操作,以免在释放锁时,出现误释放操作,所以,我们使用 SET 命令设置锁变量值时,每个客户端设置的值是一个唯一值,用于标识客户端;
满足这三个条件的分布式命令如下:
SET lock_key unique_value NX PX 10000
- lock_key 就是 key 键;
- unique_value 是客户端生成的唯一的标识,区分来自不同客户端的锁操作;
- NX 代表只在 lock_key 不存在时,才对 lock_key 进行设置操作;
- PX 10000 表示设置 lock_key 的过期时间为 10s,这是为了避免客户端发生异常而无法释放锁。
而解锁的过程就是将 lock_key 键删除(del lock_key),但不能乱删,要保证执行操作的客户端就是加锁的客户端。所以,解锁的时候,我们要先判断锁的 unique_value 是否为加锁客户端,是的话,才将 lock_key 键删除。
可以看到,解锁是有两个操作,这时就需要 Lua 脚本来保证解锁的原子性,因为 Redis 在执行 Lua 脚本时,可以以原子性的方式执行,保证了锁释放操作的原子性。
// 释放锁时,先比较 unique_value 是否相等,避免锁的误释放
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
这样一来,就通过使用 SET 命令和 Lua 脚本在 Redis 单节点上完成了分布式锁的加锁和解锁。
基于 Redis 实现分布式锁有什么优缺点?
基于 Redis 实现分布式锁的优点:
- 性能高效(这是选择缓存实现分布式锁最核心的出发点)。
- 实现方便。很多研发工程师选择使用 Redis 来实现分布式锁,很大成分上是因为 Redis 提供了 setnx 方法,实现分布式锁很方便。
- 避免单点故障(因为 Redis 是跨集群部署的,自然就避免了单点故障)。
基于 Redis 实现分布式锁的缺点:
超时时间不好设置。如果锁的超时时间设置过长,会影响性能,如果设置的超时时间过短会保护不到共享资源。比如在有些场景中,一个线程 A 获取到了锁之后,由于业务代码执行时间可能比较长,导致超过了锁的超时时间,自动失效,注意 A 线程没执行完,后续线程 B 又意外的持有了锁,意味着可以操作共享资源,那么两个线程之间的共享资源就没办法进行保护了。
- 那么如何合理设置超时时间呢? 我们可以基于续约的方式设置超时时间:先给锁设置一个超时时间,然后启动一个守护线程,让守护线程在一段时间后,重新设置这个锁的超时时间。实现方式就是:写一个守护线程,然后去判断锁的情况,当锁快失效的时候,再次进行续约加锁,当主线程执行完成后,销毁续约锁即可,不过这种方式实现起来相对复杂。
Redis 主从复制模式中的数据是异步复制的,这样导致分布式锁的不可靠性。如果在 Redis 主节点获取到锁后,在没有同步到其他节点时,Redis 主节点宕机了,此时新的 Redis 主节点依然可以获取锁,所以多个应用服务就可以同时获取到锁。
Redis 如何解决集群情况下分布式锁的可靠性?
为了保证集群环境下分布式锁的可靠性,Redis 官方已经设计了一个分布式锁算法 Redlock(红锁)。
它是基于多个 Redis 节点的分布式锁,即使有节点发生了故障,锁变量仍然是存在的,客户端还是可以完成锁操作。
Redlock 算法的基本思路,是让客户端和多个独立的 Redis 节点依次请求申请加锁,如果客户端能够和半数以上的节点成功地完成加锁操作,那么我们就认为,客户端成功地获得分布式锁,否则加锁失败。
这样一来,即使有某个 Redis 节点发生故障,因为锁的数据在其他节点上也有保存,所以客户端仍然可以正常地进行锁操作,锁的数据也不会丢失。
Redlock 算法加锁三个过程:
第一步是,客户端获取当前时间。
第二步是,客户端按顺序依次向 N 个 Redis 节点执行加锁操作:
- 加锁操作使用 SET 命令,带上 NX,EX/PX 选项,以及带上客户端的唯一标识。
- 如果某个 Redis 节点发生故障了,为了保证在这种情况下,Redlock 算法能够继续运行,我们需要给「加锁操作」设置一个超时时间(不是对「锁」设置超时时间,而是对「加锁操作」设置超时时间)。
第三步是,一旦客户端完成了和所有 Redis 节点的加锁操作,客户端就要计算整个加锁过程的总耗时(t1)。
加锁成功要同时满足两个条件(简述:如果有超过半数的 Redis 节点成功的获取到了锁,并且总耗时没有超过锁的有效时间,那么就是加锁成功):
- 条件一:客户端从超过半数(大于等于 N/2+1)的 Redis 节点上成功获取到了锁;
- 条件二:客户端获取锁的总耗时(t1)没有超过锁的有效时间。
加锁成功后,客户端需要重新计算这把锁的有效时间,计算的结果是「锁的最初有效时间」减去「客户端为获取锁的总耗时(t1)」。
加锁失败后,客户端向所有 Redis 节点发起释放锁的操作,释放锁的操作和在单节点上释放锁的操作一样,只要执行释放锁的 Lua 脚本就可以了。
系列《图解Redis》文章:
面试篇:
数据类型篇:
持久化篇:
功能篇:
高可用篇:
缓存篇:
聊聊如何用 Redis 实现分布式锁?的更多相关文章
- 【转】Redis学习笔记(四)如何用Redis实现分布式锁(1)—— 单机版
原文地址:http://bridgeforyou.cn/2018/09/01/Redis-Dsitributed-Lock-1/ 为什么要使用分布式锁 这个问题,可以分为两个问题来回答: 为什么要使用 ...
- 【转】Redis学习笔记(五)如何用Redis实现分布式锁(2)—— 集群版
原文地址:http://bridgeforyou.cn/2018/09/02/Redis-Dsitributed-Lock-2/ 单机版实现的局限性 在上一篇文章中,我们讨论了Redis分布式锁的实现 ...
- 面试题详解:如何用Redis实现分布式锁?
说一道常见面试题: 使用Redis分布式锁的详细方案是什么? 一个很简单的答案就是去使用 Redission 客户端.Redission 中的锁方案就是 Redis 分布式锁的比较完美的详细方案. 那 ...
- 基于单机redis的分布式锁实现
最近我们有个服务经常出现存储的数据出现重复,首先上一个系统流程图: 用户通过http请求可以通知任务中心结束掉自己发送的任务,这时候任务中心会通过MQ通知结束服务去结束任务保存数据,由于任务结束数据计 ...
- Redis 中的原子操作(3)-使用Redis实现分布式锁
Redis 中的分布式锁如何使用 分布式锁的使用场景 使用 Redis 来实现分布式锁 使用 set key value px milliseconds nx 实现 SETNX+Lua 实现 使用 R ...
- 用Redis构建分布式锁-RedLock(真分布)
在不同进程需要互斥地访问共享资源时,分布式锁是一种非常有用的技术手段. 有很多三方库和文章描述如何用Redis实现一个分布式锁管理器,但是这些库实现的方式差别很大,而且很多简单的实现其实只需采用稍微增 ...
- Redis实现分布式锁
http://redis.io/topics/distlock 在不同进程需要互斥地访问共享资源时,分布式锁是一种非常有用的技术手段. 有很多三方库和文章描述如何用Redis实现一个分布式锁管理器,但 ...
- Java使用Redis实现分布式锁来防止重复提交问题
如何用消息系统避免分布式事务? - 少年阿宾 - BlogJavahttp://www.blogjava.net/stevenjohn/archive/2018/01/04/433004.html [ ...
- 《Redis官方文档》用Redis构建分布式锁
用Redis构建分布式锁 在不同进程需要互斥地访问共享资源时,分布式锁是一种非常有用的技术手段. 有很多三方库和文章描述如何用Redis实现一个分布式锁管理器,但是这些库实现的方式差别很大,而且很多简 ...
随机推荐
- JavaScript 数据结构与算法2(队列和双端队列)
学习数据结构的 git 代码地址: https://gitee.com/zhangning187/js-data-structure-study 1.队列和双端队列 队列和栈非常类似,但是使用了与 后 ...
- Blazor Hybrid / MAUI 简介和实战
1. Blazor Blazor 是一个使用 .NET 生成交互式客户端 Web UI 的框架: 使用 C# 代替 JavaScript 来创建信息丰富的交互式 UI. 共享使用 .NET 编写的服务 ...
- js实时查询,为空提示
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- HTTP.sys远程执行代码漏洞检测
1.漏洞描述:HTTP 协议栈 (HTTP.sys) 中存在一个远程执行代码漏洞,这是 HTTP.sys 不正确地分析特制 HTTP 请求时导致的.成功利用此漏洞的攻击者可以在系统帐户的上下文中执行任 ...
- 小数据池,is和==的区别,id()
小数据池 概念 存放数据缓存的地方 目的 节省内存,提高效率 什么数据会被缓存(什么数据会放在小数据池中) 数字 字符串 布尔 优点: 可以帮我们快速的创建对象.节省内存. 缺点: ...
- 溢出属性,定位,z-index,JS
溢出属性 1.visible(默认值):使溢出内容展示 2.hidden:隐藏溢出内容且不出现滚动条 3.scroll:隐藏溢出容器的内容,溢出的内容可以通过滚动呈现 4.auto:与scroll没啥 ...
- 114_Power Pivot 销售订单之销售额、成本、利润率相关
博客:www.jiaopengzi.com 焦棚子的文章目录 请点击下载附件 一.背景 双十二回来后遇到一个比较有意思的计算销售额和利润率的需求(见下文说明). 先看下效果. 结果 说明: 1.订单表 ...
- 牛客多校赛2K Keyboard Free
Description 给定 \(3\) 个同心圆,半径分别为 \(r1,r2,r3\) ,三个点分别随机分布在三个圆上,求这个三角形期望下的面积. Solution 首先可以固定 \(A\) 点,枚 ...
- 腾讯云Redis全面升级,性能提升400%,可用性高达5个9
2022年6月,腾讯云Redis全新升级,发布高性能版本,单节点可提供50W+吞吐,性能是原生Redis的4倍.同时,腾讯云Redis推出全球复制功能,解决原生Redis诸多痛点问题,可用性升级高达9 ...
- Acwing785.快速排序
Acwing785.快速排序 快排模板: y总教学大法好~: #include <iostream> using namespace std; const int N = 1000010; ...