Python数据科学手册-机器学习: 主成分分析
PCA principal component analysis
主成分分析是一个快速灵活的数据降维无监督方法,
可视化一个包含200个数据点的二维数据集
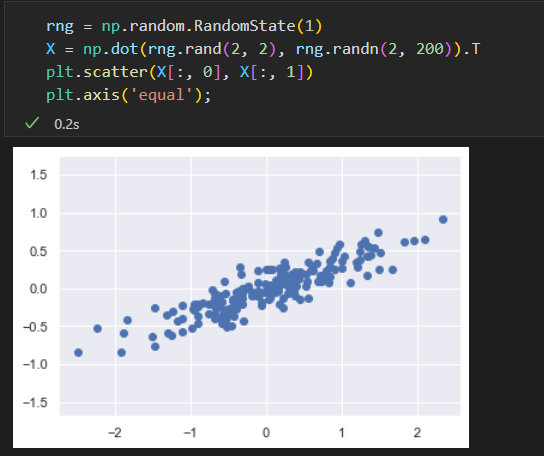
x 和 y有线性关系,无监督学习希望探索x值和y值之间的相关性
在主成分分析中。一种量化俩变量之间关系的方法 是在数据中找到一组主轴,并用这些主轴来描述 数据集。
利用PCA评估器
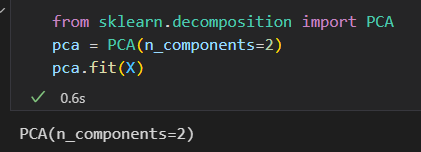
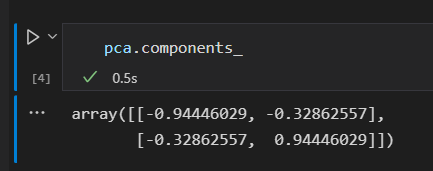
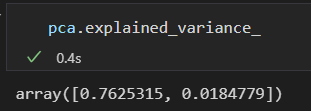
该拟合从数据中心学习到了一些指标,其中最重要的是 “成分” 和 “可解释差异”
在数据图上将这些指标以向量形式画出来。
成分 定义向量的方向。
可解释差异 作为向量的平方长度。
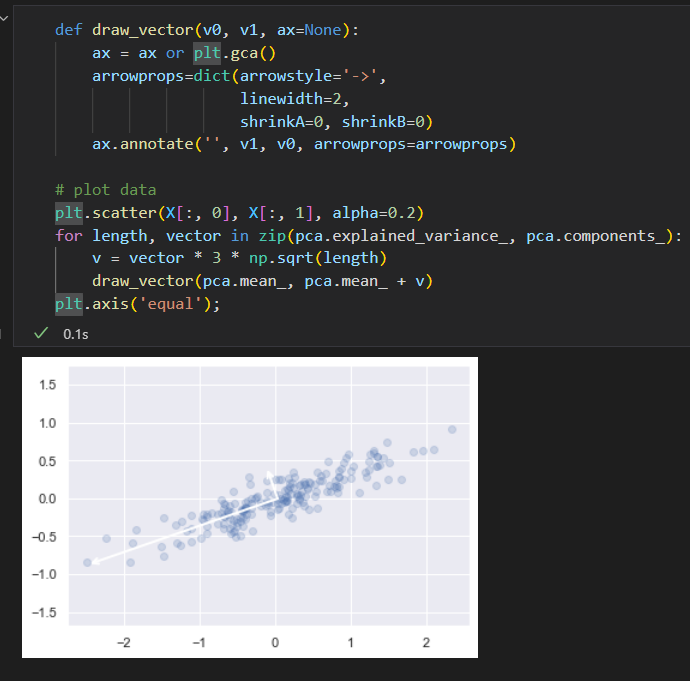
这些向量表示数据主轴,箭头长度表示输入数据中各个轴的 重要程度,衡量了数据投影到主轴上的方差的大小。
每个数据点在主轴上的投影就是数据 的主成分
这种从数据的坐标轴变换到主轴的编号 是一个 仿射变换,
仿射变换包含 平移 translation 旋转 rotation 均匀缩放 uniform scaling
用PCA降维
用PCA降为意味着去除一个 或 多个 最小主成分,从而得到一个更低维度且保留最大数据方差的数据投影。
PCA降维示例:
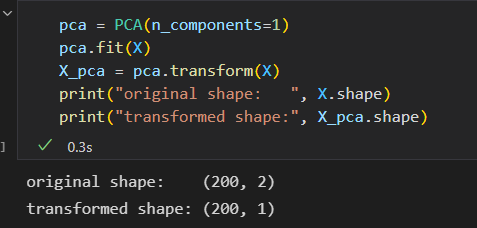
变换的数据投影到一个单一维度。
把降维的数据进行逆变换 ,来和原始数据对比
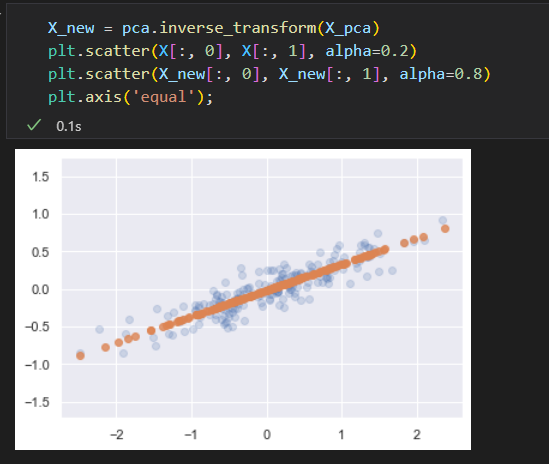
可以看出,沿着最不重要的主轴的信息都被去除了,仅留下了含有最高方差值得数据成分。
这种降维后的数据集在某种程度上足以体现数据中最主要的关系
用PCA作数据可视化:手写数字
降维的有用之处在俩个维度时不明显。 当数据维度很高是,价值就有所体现。
导入数据:
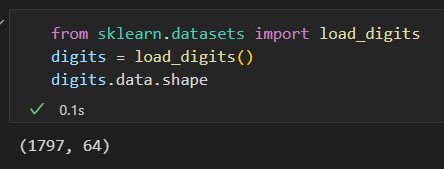
该数据包含 8* 8 像素的图像。是64维的。 将这些数据投影到一个可操作的维度。 二维
画出每个点的前俩个主成分,
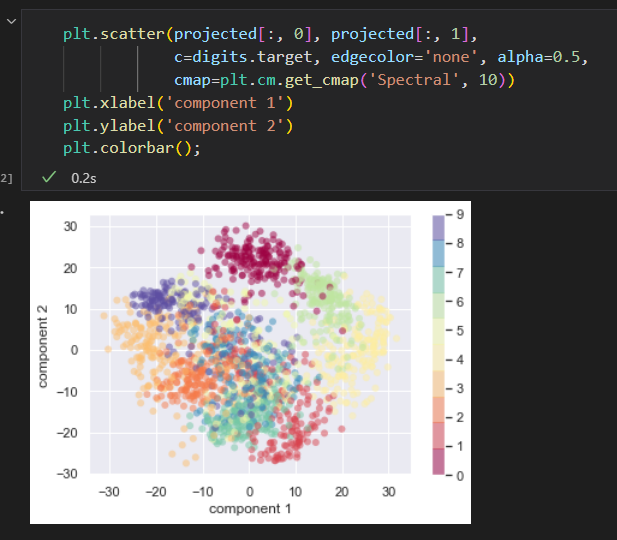
成分的含义:
消减的维度有什么含义?
每幅图像 由一组 64像素值 的 集合定义。将其称为 向量x
x=[x1,x2,x3⋯x64]
为了构建一幅图像,将向量的每个元素与对应描述的像素(单位列向量)相乘,然后将这些结果加和就是这幅图像
image(x)=x1⋅(pixel 1)+x2⋅(pixel 2)+x3⋅(pixel 3)⋯x64⋅(pixel 64)
我们可以将降维理解为删除绝大部分元素,保留少量元素的基向量,basis vector .
仅使用前8个像素,我们会得到数据的8维投影,但是它并不能反映整幅图像。

上面一行是单独的像素信息,下面一行是这些像素值的累加,累加值最终构成这幅图像。
但是逐像素表示方法并不是选择基向量的唯一方式,我们可以使用其他基函数,这些基函数包含预定义的每个像素的贡献。
PCA可以被认为 是选择最优基函数的过程,这样将这些基函数中前几个加起来就足以重构数据中 的大部分元素。
用低维形式表现数据的主成分,
用均值加上前8个PCA基函数重构数字的效果。

Python数据科学手册-机器学习: 主成分分析的更多相关文章
- Python数据科学手册-机器学习:朴素贝叶斯分类
朴素贝叶斯模型 朴素贝叶斯模型是一组非常简单快速的分类方法,通常适用于维度非常高的数据集.因为运行速度快,可调参数少.是一个快速粗糙的分类基本方案. naive Bayes classifiers 贝 ...
- Python数据科学手册-机器学习介绍
机器学习分为俩类: 有监督学习 supervised learning 和 无监督学习 unsupervised learning 有监督学习: 对数据的若干特征与若干标签之间 的关联性 进行建模的过 ...
- Python数据科学手册-机器学习: k-means聚类/高斯混合模型
前面学习的无监督学习模型:降维 另一种无监督学习模型:聚类算法. 聚类算法直接冲数据的内在性质中学习最优的划分结果或者确定离散标签类型. 最简单最容易理解的聚类算法可能是 k-means聚类算法了. ...
- Python数据科学手册-机器学习: 流形学习
PCA对非线性的数据集处理效果不太好. 另一种方法 流形学习 manifold learning 是一种无监督评估器,试图将一个低维度流形嵌入到一个高纬度 空间来描述数据集 . 类似 一张纸 (二维) ...
- Python数据科学手册-机器学习: 决策树与随机森林
无参数 算法 随机森林 随机森林是一种集成方法,集成多个比较简单的评估器形成累计效果. 导入标准程序库 随机森林的诱因: 决策树 随机森林是建立在决策树 基础上 的集成学习器 建一颗决策树 二叉决策树 ...
- Python数据科学手册-机器学习: 支持向量机
support vector machine SVM 是非常强大. 灵活的有监督学习算法, 可以用于分类和回归. 贝叶斯分类器,对每个类进行了随机分布的假设,用生成的模型估计 新数据点 的标签.是属于 ...
- Python数据科学手册-机器学习:线性回归
朴素贝叶斯是解决分类任务的好起点,线性回归是解决回归任务的好起点. 简单线性回归 将数据拟合成一条直线. y = ax + b , a 是斜率, b是直线截距 原始数据如下: 使用LinearRegr ...
- Python数据科学手册-机器学习之特征工程
特征工程常见示例: 分类数据.文本.图像. 还有提高模型复杂度的 衍生特征 和 处理 缺失数据的填充 方法.这个过程被叫做向量化.把任意格式的数据 转换成具有良好特性的向量形式. 分类特征 比如房屋数 ...
- Python数据科学手册-机器学习之模型验证
模型验证 model validation 就是在选择 模型 和 超参数 之后.通过对训练数据进行学习.对比模型对 已知 数据的预测值和实际值 的差异. 错误的模型验证方法. 用同一套数据训练 和 评 ...
随机推荐
- 编译调试Net6源码
前言 编辑调试DotNet源码可按照官网教程操作,但因为网络问题中间会出现各种下载失败的问题,这里出个简单的教程(以6为版本) 下载源码 下载源码 GitHub下载源码速度极慢,可替换为国内仓库htt ...
- identityserver4 (ids4)中如何获取refresh_token刷新令牌token 使用offline_access作用域
ids4默认自带的api接口/api/connect/token 调用这个接口的时候,需要在body里面的 x-www-form-urlencoded模式下写 { grant_type: &q ...
- 6 分钟看完 BGP 协议。
上一篇文章见 万字长文爆肝路由协议! 上面我们聊 RIP .OSPF 协议都是基于 AS 即自治系统内的协议,可以把它们认为是域内路由协议:而下面我们要聊的就是 AS 之间的协议了,这也叫做域间路由协 ...
- 浅学hello world
Hello world 1.随便新建一个文件夹,存放代码 2.新建一个java文件 .后缀名为.java .Hello.java .[注意点]系统没显示后缀名的可以自己手动打开 3.编写代码 publ ...
- jdbc 11: 封装自己的jdbc工具类
jdbc连接mysql,封装自己的jdbc工具类 package com.examples.jdbc.utils; import java.sql.*; import java.util.Resour ...
- logstash在windows系统下的安装与使用
前言: Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到 Elasticsearch. ES官网:https://www.elastic.co/p ...
- MYSQL(基本篇)——一篇文章带你走进MYSQL的奇妙世界
MYSQL(基本篇)--一篇文章带你走进MYSQL的奇妙世界 MYSQL算是我们程序员必不可少的一份求职工具了 无论在什么岗位,我们都可以看到应聘要求上所书写的"精通MYSQL等数据库及优化 ...
- composer常用命令(部分摘抄)
1. 仅更新单个库 composer update foo/bar 2. 不编辑composer.json的情况下安装库 composer require "foo/bar:1.0.0&qu ...
- 流量如何才能变现?实际测试谷歌广告联盟(Google Adsense)的广告效果以及如何优化相关代码
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_150 2010年,谷歌正式退出中国市场,无数人扼腕叹息,如今十年过去了,谷歌还有两条重要的业务线并没有完全退出,一个是页面统计业务 ...
- 妙用 CSS 构建花式透视背景效果
本文将介绍一种巧用 background 配合 backdrop- filter 来构建有趣的透视背景效果的方式. 本技巧源自于一名群友的提问,如何构建如 ElementUI 文档的一种顶栏背景特效, ...