HBase概念入门
HBase简介
HBase基于Google的BigTable论文而来,是一个分布式海量列式非关系型数据库系统,可以提供大规模数据集的实时随机读写。
下面通过一个小场景认识HBase存储。同样的一个数据
用Mysql存储是这样的:
| id | name | age | salary | job |
|---|---|---|---|---|
| 1 | 小明 | 23 | 学生 | |
| 2 | 小红 | 1000 | 律师 |
如果是HBase的话,存储是类似这样列式存储的:
| field1 | filed2 |
|---|---|
| rowkey:1 | name:小明 |
| rowkey:1 | age:23 |
| rowkey:1 | job:学生 |
| rowkey:2 | name:小红 |
| rowkey:2 | salary:1000 |
| rowkey:2 | job:律师 |
HBase这样存储的优点是:
- 有空值字段的情况下,能减少存储空间占用
- 支持好多列
HBase的特点
- 海量存储:底层基于HDFS存储海量数据
- 列式存储:HBase表的数据是基于列族进行存储的,一个列族包含若干列
- 极易扩展:底层依赖HDFS,当磁盘空间不足的时候,只需要动态添加DataNode服务节点就行了
- 高并发:支持高并发的读写请求
- 稀疏性:稀疏主要是针对HBase列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的。
- 数据的多版本:HBase表中的数据可以有多个版本值,默认情况下是根据版本号取区分,版本号就是插入数据的时间戳
- 数据类型单一:所有的数据在HBase中是以字节数组进行存储
HBase的应用
- 交通方面:船只GPS信息,每天都有成千上万的数据存储
- 金融方面:消费信息、贷款信息、信用卡还款信息
- 电商方面:电商网站的交易信息、物流信息、游览信息等
- 电信、移动等:通话信息
HBase的缺点
- HBase的有效性存在一定的问题,集群中一个节点宕机,这个节点的数据暂时就不能访问了,需要等待一定的时间进行同步处理。
- HBase的监控粒度太粗
- 查询简单,只能根据key扫描一条信息或者全部扫描
- 不支持交叉表、事务、连接查询
总结:HBase适合海量明细数据的存储,并且后期能有很好的查询性能(单表超千万、上亿,且并发要求高)
HBase数据模型
HBase逻辑结构
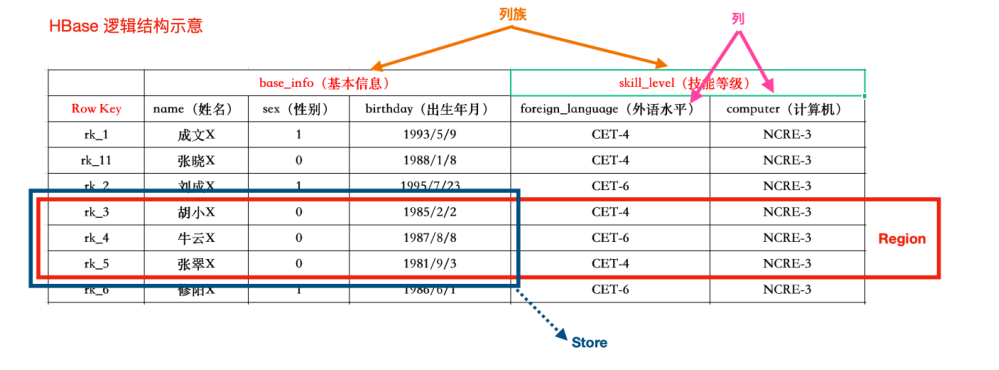
HBase物理存储

HBase存储的时候是以列族为单位进行存储的。
HBase模型描述
- NameSpace
命名空间,类似于关系型数据库的database概念。每个namespace下有多个表。HBase两个自带的namespace,分别是hbase和default,hbase中存放的是HBase内置的表,default表是用户默认使用的namespace。一个表可以自由选择是否有namespace,如果创建表的时候加了namespace,这个表名字以:作为区分
- Table
类似于关系型数据库的表的概念。不同的是,HBase定义表时只需要声明列族即可,数据属性:如超时时间、压缩算法等,都在列族的定义中定义,不需要声明具体的列
- Row
HBase表中的每行数据都由一个RowKey和多个Column列组成。一个行包含了多个列,这些列通过列族来分类,行中的数据所属列族只能从表所定义的列族中选取
- RowKey
Rowkey由用户指定的一串不重复的字符串定义,是一行的唯一标识。数据是按照Rowkey的字典顺序存储的,并且查询数据时只能根据Rowkey进行检索,所以Rowkey的设计十分重要。如果使用了之前已经定义的RowKey,那么会将之前的数据更新掉
- Column Family(列族)
列族是多个列的集合,一个列族可以动态灵活的定义多个列。表的相关属性大部分都定义在列族上,同一个表里的不同列族可以有完全不同的属性配置,但是同一个列族内的所有列都会有相同的属性。列族存在的意义是HBase会把相同列族的列尽量放在同一台机器上。
- Column Wualifier(列)
HBase中的列是可以随意定义的,一个行中的列不限名字、不限数量、只限定列族。因此列必须依赖于列族存在。列的名称前必须带着所属的列族
- TimeStamp(版本)
用于标识数据的不同版本,时间戳默认由系统指定,也可以用户显式指定。在读取数据的单元格时,版本号可以忽略,如果不指定,HBase默认会获取最后一个版本的数据返回
- Cell
一个列中可以存储多个版本的数据。而每个版本就称为一个单元格
- Region
HBase 将表中的数据基于RowKey的不同范围划分到不同Region上,每个Region都负责一定范围的数据存储和访问。每个表一开始只有一个Region,随着数据不断插入表,Region不断增大,当增大到一个阀值的时候,Region就会等分成两个新的Region。当table中的行不断增多,就会有越来越多的Region。
HBase整体架构
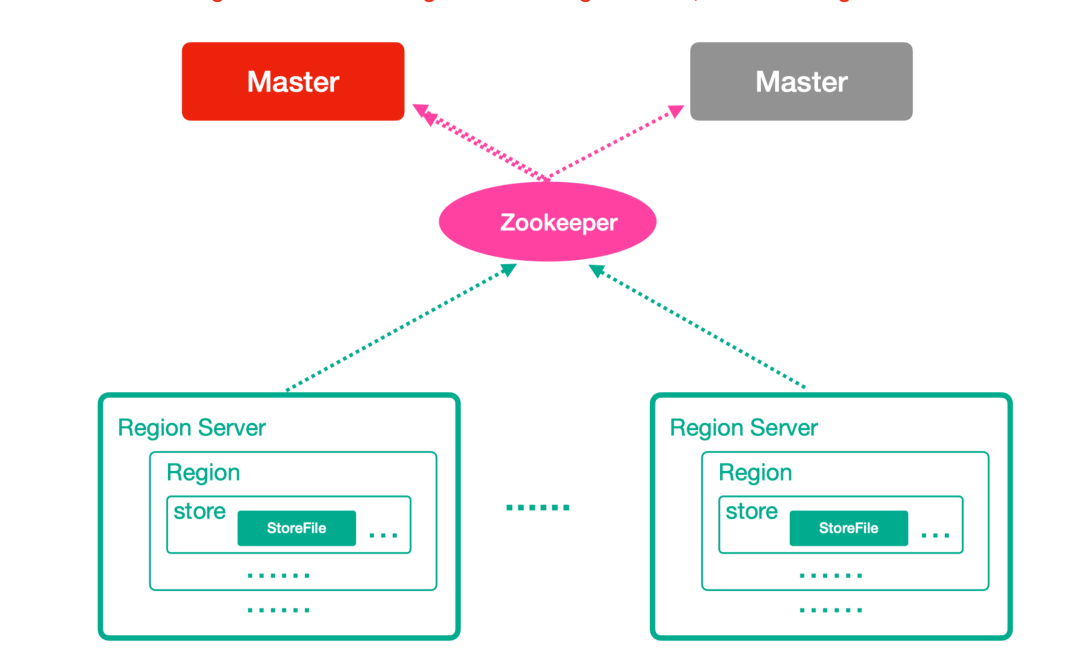
Zookeeper
- 实现了HMaster的高可用,保存了HBase的元数据信息,是所有HBase表的寻址入口
- 对HMaster和HRegionServer实现了监控
HMaster(Master)
- 为HRegionServer分配Region
- 维护整个集群的负载均衡
- 发现失效的Region,并将失效的Region分配到正常的HRegionServer上
HRegionServer(RegionServer)
- 负责管理Region
- 接受客户端的读写数据请求
- 切分在运行过程中变大的Region
Region
- 每个HRegion由多个Store构成
- 每个Store保存一个列族,表有几个列族,则有几个Store
- 每个Store由一个MemStore和多个StoreFile组成,MemStore是Store在内存中的内容,写到文件后就是StoreFile。StoreFile底层就是以HFile的格式保存。
HBase概念入门的更多相关文章
- HBase概念及表格设计
HBase概念及表格设计 1. 概述(扯淡~) HBase是一帮家伙看了Google发布的一片名为“BigTable”的论文以后,犹如醍醐灌顶,进而“山寨”出来的一套系统. 由此可见: 1. 几乎所有 ...
- 【转】kafka概念入门[一]
转载的,原文:http://www.cnblogs.com/intsmaze/p/6386616.html ---------------------------------------------- ...
- [转帖]新手必读,16个概念入门 Kubernetes
新手必读,16个概念入门 Kubernetes https://www.kubernetes.org.cn/5906.html 2019-09-29 22:13 中文社区 分类:Kubernetes教 ...
- HBASE概念补充
HBASE概念补充 HBase的工作方式: hbase中的表在行的方向上分隔为多个HRegion,分散在不同的RegionServer中 这样做的目的是在查询时可以将工作量分布到多个RegionSer ...
- Serverless 基本概念入门
从行业趋势看,Serverless 是云计算必经的一场革命 2019 年,Serverless 被 Gartner 称为最有潜力的云计算技术发展方向,并被赋予是必然性的发展趋势.Serverless ...
- GraphQL 概念入门
GraphQL 概念入门 Restful is Great! But GraphQL is Better. -- My Humble Opinion. GraphQL will do to REST ...
- HBase轻松入门之HBase架构图解析
2018-12-13 2018-12-20 本篇文章旨在针对初学者以我本人现阶段所掌握的知识就HBase的架构图中各模块作一个概念科普.不对文章内容的“绝对.完全正确性”负责. 1.开胃小菜 关于HB ...
- hbase概念
1. 概述(扯淡~) HBase是一帮家伙看了Google发布的一片名为“BigTable”的论文以后,犹如醍醐灌顶,进而“山寨”出来的一套系统. 由此可见: 1. 几乎所有的HBase中的理念,都可 ...
- Docker K8s基本概念入门
原文地址:https://blog.csdn.net/TM6zNf87MDG7Bo/article/details/79621510 k8s是一个编排容器的工具,其实也是管理应用的全生命周期的一个工具 ...
随机推荐
- 19.Tomcat多实例部署及负载均衡、动静分离
Tomcat多实例部署及负载均衡.动静分离 目录 Tomcat多实例部署及负载均衡.动静分离 Tomcat多实例部署 安装jdk 设置jdk环境变量 安装tomcat 配置 tomcat 环境变量 修 ...
- crane:字典项与关联数据处理的新思路
前言 在我们日常开发中,经常会遇到一些烦人的数据关联和转换问题,比如典型的: 对象属性中个有字典 id,需要获取对应字典值并填充到对象中: 对象属性中有个外键,需要关联查询对应的数据库表实体,并获取其 ...
- 如何通过WinDbg获取方法参数值
引入 我们在调试的过程中,经常会通过查看方法的输入与输出来确定这个方法是否异常.那么我们要怎么通过 WinDbg 来获取方法的参数值呢? WinDbg 中主要包含三种命令:标准命令.元命令(以 . 开 ...
- go-zero微服务实战系列(八、如何处理每秒上万次的下单请求)
在前几篇的文章中,我们花了很大的篇幅介绍如何利用缓存优化系统的读性能,究其原因在于我们的产品大多是一个读多写少的场景,尤其是在产品的初期,可能多数的用户只是过来查看商品,真正下单的用户非常少.但随着业 ...
- Halcon 条形码识别
read_image (Image, 'C:/Users/HJ/Desktop/test_image/image.png') create_bar_code_model([], [], BarCode ...
- Pytorch从0开始实现YOLO V3指南 part5——设计输入和输出的流程
本节翻译自:https://blog.paperspace.com/how-to-implement-a-yolo-v3-object-detector-from-scratch-in-pytorch ...
- lerna源码阅读
能够找到入口文件 能够本地调试
- pyinstaller打包一些三方库后,报资源不存在
在目录site-packages\PyInstaller\hooks下新建对应文件hook-对应三方库名字.py,如hook-ngender.py 编辑hook-ngender.py: from Py ...
- CF1705A Mark the Photographer 题解
题意: 给定一队人的身高,将其分成两队,问能否实现前面的人均低于后面的人至少 \(x\) 个单位长度. 做法: 将这队人的身高进行排序,\(h_1 \sim h_n\) 即为第一队,\(h_{n+1} ...
- maven的常见问题
idea2021.3报错-Maven-Terminated-with-exit-code-1