Android 12(S) 图形显示系统 - 解读Gralloc架构及GraphicBuffer创建/传递/释放(十四)
必读:
Android 12(S) 图形显示系统 - 开篇
一、前言
在前面的文章中,已经出现过 GraphicBuffer 的身影,GraphicBuffer 是Android图形显示系统中的一个重要概念和组件,顾名思义,它就是用来存储和传递需要绘制的图像数据的。GraphicBuffer 可以在应用程序和 BufferQueue 或 SurfaceFlinger 间传递。
本文及接下来的几篇文章,将聚焦分析 GraphicBuffer 创建的流程,相关组件、服务的基本架构和基本实现原理。
二、GraphicBuffer 相关组件/层级结构预览
Android 图形显示系统中管理、分配、使用 GraphicBuffer 涉及众多组件,我的理解:
1. 生产者、消费者一般是作为 GraphicBuffer 的使用者,或写数据,或读数据;
2. BufferQueue 可以视作 GraphicBuffer 的管理者,它统一处理来自使用者的请求,从而统一管理 GraphicBuffer 的分配、释放及流转;
3. Gralloc HAL 是实际缓存memory的分配模块,它负责分配可以在进程间共享的图形buffer;
不同的功能逻辑被封装为不同的组件/子系统, 从系统层级来看,gralloc属于最底层的HAL层模块,为上层的libui、libgui 库提供服务,整个层级结构如下所示:
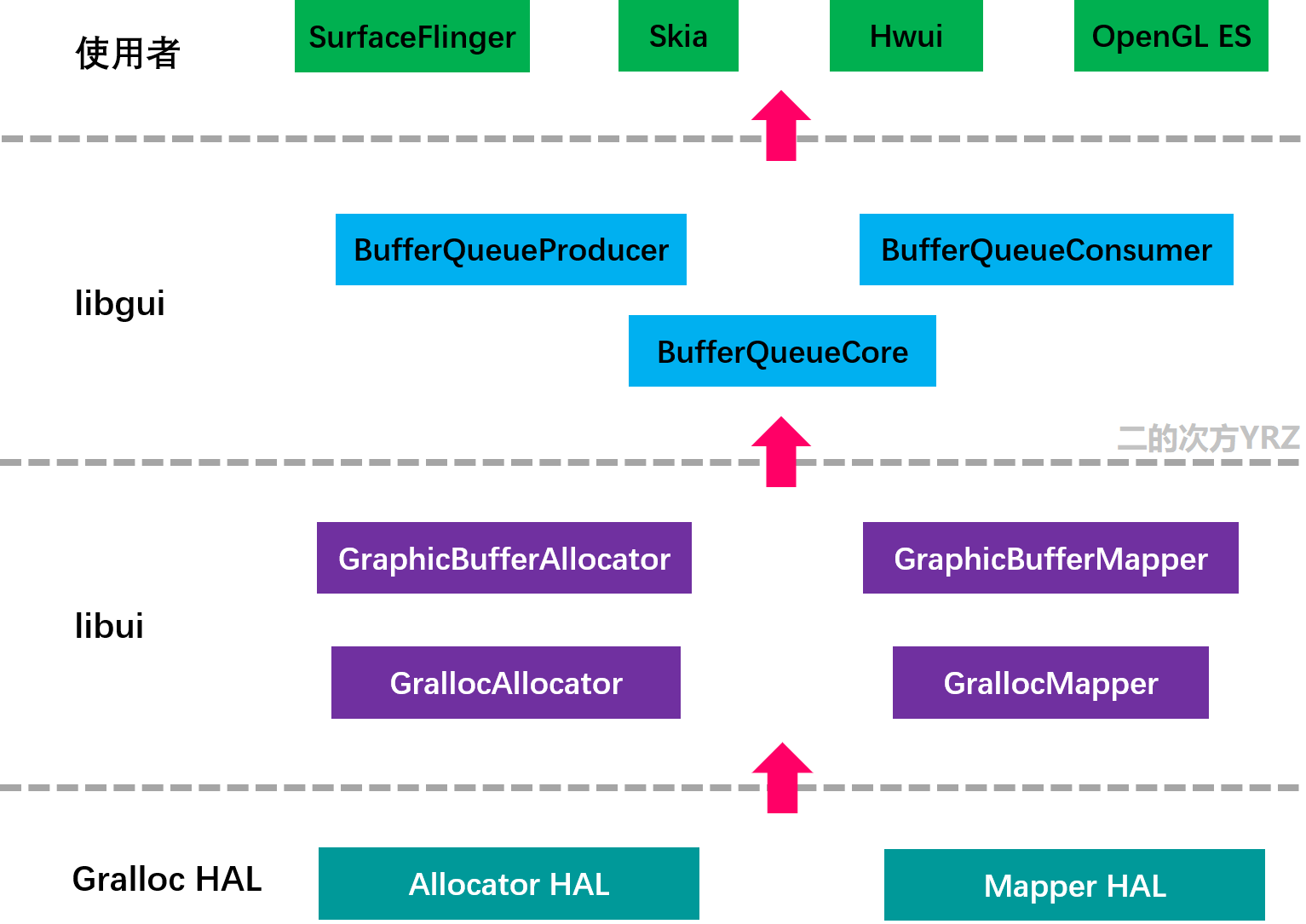
如上图所示,简单概述
最底层是 Gralloc HAL 模块,这部分按照功能划分为两部分:allocator 和 mapper。Gralloc 是Android中负责为GraphicBuffer申请和释放内存的HAL层模块,由硬件驱动提供实现,为BufferQueue机制提供了基础。Gralloc 分配的图形Buffer是进程间共享的,且根据其Flag支持不同硬件设备的读写。同其它HAL模块一样,Gralloc 也是实现为 HIDL service的方式,我们暂且称为 gralloc-allocator hidl service 和 gralloc-mapper hidl service;
上面一层 libui 库,主要功能是封装对 Gralloc HAL 层的调用。代码目录是 frameworks/native/include/ui 和 frameworks/native/libs/ui。其中的 GrallocAllocator看作 gralloc-allocator hal 代理,GrallocMapper 看作 gralloc-mapper hal 的代理;
再向上一层是 libgui 库,主要功能是封装连接生产者和消费者的BufferQueue,向下依赖于于libui。代码目录是 frameworks/native/include/gui 和 frameworks/native/libs/gui;
最上面是使用者,他们对 GraphicBuffer 进行读写处理,Skia、Hwui 和 OpenGL ES 是BufferQueue的生产方,SurfaceFlinger 是BufferQueue的消费方;
三、Gralloc HAL介绍
Gralloc HAL 分为了两部分:一个是 allocator ,一个是 mapper。Android系统定义了标准的 Gralloc HAL interface,具体实现有OEM/芯片厂商完成。
3.1 allocator HAL interface 的定义
[ /hardware/interfaces/graphics/allocator/4.0/IAllocator.hal]
interface IAllocator {
/**
* Allocates buffers with the properties specified by the descriptor.
*
* Allocations should be optimized for usage bits provided in the
* descriptor.
*
* @param descriptor Properties of the buffers to allocate. This must be
* obtained from IMapper::createDescriptor().
* @param count The number of buffers to allocate.
* @return error Error status of the call, which may be
* - `NONE` upon success.
* - `BAD_DESCRIPTOR` if the descriptor is invalid.
* - `NO_RESOURCES` if the allocation cannot be fulfilled at this time.
* - `UNSUPPORTED` if any of the properties encoded in the descriptor
* are not supported.
* @return stride The number of pixels between two consecutive rows of
* an allocated buffer, when the concept of consecutive rows is defined.
* Otherwise, it has no meaning.
* @return buffers Array of raw handles to the allocated buffers.
*/
allocate(BufferDescriptor descriptor, uint32_t count)
generates (Error error,
uint32_t stride,
vec<handle> buffers);
};IAllocator接口的定义很简单,只有一个方法allocate,其中参数 descriptor 描述了需要分配的buffer的属性,它是通过 IMapper::createDescriptor()获取的,count 标识需要分配的buffer数量。
调用成功后返回 raw handle 的数组buffers。
Allocator 实现为一个 Binderized HAL Service(绑定式HAL),运行在独立的进程中,使用者通过 HwBinder 与之建立连接,类似与AIDL获取服务的方式。
Android 框架层libui库中的Gralloc4Allocator 就是作为一个代理并对其功能的封装:
[/frameworks/native/libs/ui/Gralloc4.cpp]
Gralloc4Allocator::Gralloc4Allocator(const Gralloc4Mapper& mapper) : mMapper(mapper) {
mAllocator = IAllocator::getService();
...
}其中成员sp<hardware::graphics::allocator::V4_0::IAllocator> mAllocator;通过调用 IAllocator::getService()便建立了和 allocator hal 的远程连接。
3.2 mapper HAL interface 的定义
mapper HAL 的定义稍稍复杂一些,源码位于/hardware/interfaces/graphics/mapper/4.0/
types.hal 中定义了 Error values 和 BufferDescriptor,比较简单
IMapper.hal 中定义了接口 IMapper还有一些struct等类型,具体的内容建议直接阅读源码的英文注释,很详细。在此我们只列举几个主要的相关方法。
[ /hardware/interfaces/graphics/mapper/4.0/IMapper.hal]
interface IMapper {
// BufferDescriptorInfo用于描述图形buffer的属性(宽、高、格式...)
struct BufferDescriptorInfo {
string name; // buffer的名字,用于debugging/tracing
uint32_t width; // width说明了分配的buffer中有多少个像素列,但它并不表示相邻行的同一列元素的偏移量,区别stride。
uint32_t height; // height说明了分配的buffer中有多少像素行
uint32_t layerCount; // 分配的缓冲区中的图像层数
PixelFormat format; // 像素格式 (参见/frameworks/native/libs/ui/include/ui/PixelFormat.h中的定义)
bitfield<BufferUsage> usage;buffer使用方式的标志位(参见/frameworks/native/libs/ui/include/ui/GraphicBuffer.h的定义)。
uint64_t reservedSize; // 与缓冲区关联的保留区域的大小(字节)。
};
/**
* 创建一个 buffer descriptor,这个descriptor可以用于IAllocator分配buffer
* 主要完成两个工作:
* 1. 检查参数的合法性(设备是否支持);
* 2. 把BufferDescriptorInfo这个结构体变量进行重新的包装,本质就是转化为byte stream,这样可以传递给IAllocator
*/
createDescriptor(BufferDescriptorInfo description)
generates (Error error,
BufferDescriptor descriptor);
/**
* 把raw buffer handle转为imported buffer handle,这样就可以在调用进程中使用了
* 当其他进程分配的GraphicBuffer传递到当前进程后,需要通过该方法映射到当前进程,为后续的lock做好准备
*/
importBuffer(handle rawHandle) generates (Error error, pointer buffer);
/**
* importBuffer()返回的buffer handle不再使用后必须调用freeBuffer()释放
*/
freeBuffer(pointer buffer) generates (Error error);
/**
* 已指定的CPU usage 锁定缓冲区的指定区域accessRegion。lock之后就可以对buffer进行读写了
*/
lock(pointer buffer,
uint64_t cpuUsage,
Rect accessRegion,
handle acquireFence)
generates (Error error,
pointer data);
/**
* 解锁缓冲区以指示对缓冲区的所有CPU访问都已完成
*/
unlock(pointer buffer) generates (Error error, handle releaseFence);
/**
* 根据给定的MetadataType获取对应的buffer metadata
*/
get(pointer buffer, MetadataType metadataType)
generates (Error error,
vec<uint8_t> metadata);
/**
* 设置给定的MetadataType对应的buffer metadata
*/
set(pointer buffer, MetadataType metadataType, vec<uint8_t> metadata)
generates (Error error);
};IMapper 我们可以理解为完成了 buffer handle 所指向的图形缓存到运行进程的映射。访问 buffer 数据一般遵循这样的流程:
importBuffer -> lock -> 读写GraphicBuffer-> unlock -> freeBuffer
Mapper 实现为一个 Passthrough HAL Service(直通式HAL), 运行在调用它的进程中。本质上 Mode of HIDL in which the server is a shared library, dlopened by the client. In passthrough mode, client and server are the same process but separate codebases.
Android 框架层libui库中的Gralloc4Mapper 就是作为一个代理并对其功能的封装:
Gralloc4Mapper::Gralloc4Mapper() {
mMapper = IMapper::getService();
...
}其中成员sp<hardware::graphics::mapper::V4_0::IMapper> mMapper;通过调用 IMapper::getService()便建立了和 mapper hal 的连接。
对于 Passthrough mode下,IMapper::getService()服务建立的过程,下篇文中有分析,可以参考。为什么 passthrough mode 下,client and server are the same process 运行在同一个进程中?
下一篇文章中我有做一点简单的探索,感兴趣的可以参考:Android 12(S) 图形显示系统 - 简述Allocator/Mapper HAL服务的获取过程(十五)
3.3 Gralloc Allocator & Mapper HAL 的实现
Gralloc HAL 一般是由硬件厂商完成的,Android 源码中有高通的一些参考,不过貌似是一些旧的适配模式。比如 /hardware/qcom/display/msm8998/libgralloc1/
如果是使用的是 ARM Mali GPUs 可以参考官网的开源代码 :Open Source Mali GPUs Android Gralloc Module
我学习中就参考了最新的一个版本 :BX304L01B-SW-99005-r36p0-01eac0.tar在它的源码目录下 driver\product\android\gralloc\src\4.x就有 IAllocator 和 IMapper 的具体实现。这部分在此就不做分析了。
四、libui库中的基本组件
libui 库主要封装了对 gralloc allocator /mapper HAL模块的调用,管理GraphicBuffer的分配释放以及在不同进程间的映射,主要包含3个核心类,类图如下所示:
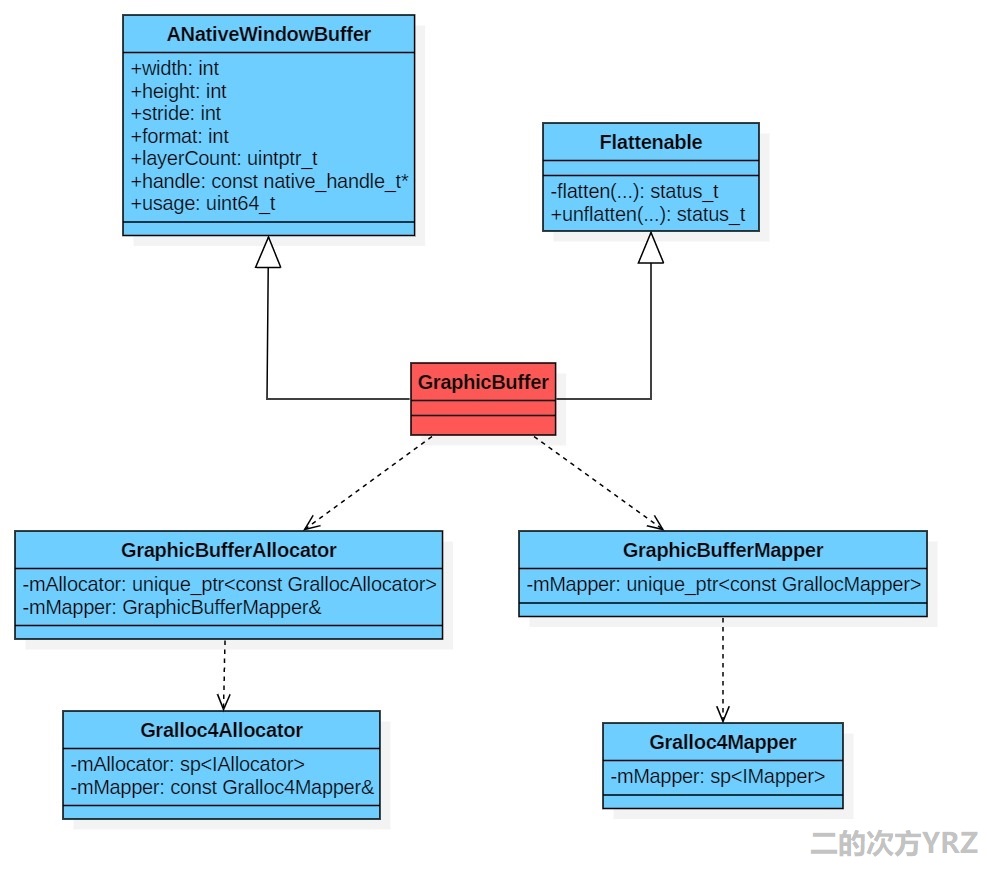
1. GraphicBuffer:对应gralloc分配的图形Buffer(也可能是普通内存,具体要看gralloc实现),它继承ANativeWindowBuffer结构体,核心成员是指向图形缓存的句柄(native_handle_t * handle),并且图形Buffer本身是多进程共享的,跨进程传输的是GraphicBuffer的关键属性,这样在使用进程可以重建GraphicBuffer,同时指向同一块图形Buffer。
2. GraphicBufferAllocator:向下对接gralloc allocator HAL服务,是进程内单例,负责分配进程间共享的图形Buffer,对外即GraphicBuffer。
3. GraphicBufferMapper:向下对接gralloc mapper HAL服务,是进程内单例,负责把GraphicBufferAllocator分配的GraphicBuffer映射到当前进程空间。
五、创建 CraphicBuffer 的基本流程
5.1 生产者请求去创建 GraphicBuffer
在之前讲解 BufferQueue 的工作流程 Android 12(S) 图形显示系统 - BufferQueue的工作流程(九)这篇文章中,应用程序作为生产者,在准备绘制图像时,调用 dequeuBuffer 函数向 BufferQueue 请求一块可用的图形缓存 GraphicBuffer。
在 dequeuBuffer 函数中,如果找到的 BufferSlot 没有绑定 GraphicBuffer 或者已绑定的 GraphicBuffer 的属性与我们需要的不一致,设置标志 BUFFER_NEEDS_REALLOCATION, 这个时候就要去分配图形缓存了,即需要去创建 GraphicBuffer 对象了。
可以先看看 dequeueBuffer 函数中代码:
[/frameworks/native/libs/gui/BufferQueueProducer.cpp]
status_t BufferQueueProducer::dequeueBuffer(int* outSlot, sp<android::Fence>* outFence,
uint32_t width, uint32_t height, PixelFormat format,
uint64_t usage, uint64_t* outBufferAge,
FrameEventHistoryDelta* outTimestamps) {
...
// 判断需要去分配图形缓存,创建 GraphicBuffer 对象
if (returnFlags & BUFFER_NEEDS_REALLOCATION) {
BQ_LOGV("dequeueBuffer: allocating a new buffer for slot %d", *outSlot);
sp<GraphicBuffer> graphicBuffer = new GraphicBuffer(
width, height, format, BQ_LAYER_COUNT, usage,
{mConsumerName.string(), mConsumerName.size()});
}
...
}5.2 GraphicBuffer 的定义
[/frameworks/native/libs/ui/include/ui/GraphicBuffer.h]
class GraphicBuffer
: public ANativeObjectBase<ANativeWindowBuffer, GraphicBuffer, RefBase>,
public Flattenable<GraphicBuffer>
{
...
}ANativeObjectBase 继承了 ANativeWindowBuffer 和 RefBase,GraphicBuffer 继承了 ANativeObjectBase和Flattenable,这样可以达到:
1. 继承了 RefBase,使 GraphicBuffer 支持引用计数;
2. 继承了 Flattenable,使 GraphicBuffer 支持序列化,可以透过 Binder IPC 进程间传递;
还有重要的一点,其父类 ANativeWindowBuffer 中保存有各种属性信息,摘取基本信息如下:
[/frameworks/native/libs/nativebase/include/nativebase/nativebase.h]
// 图形Buffer的Size = stride * height * 每像素字节数
typedef struct ANativeWindowBuffer
{
...
int width; // 图形Buffer的宽度
int height; // 图形Buffer的高度
int stride; // 图形Buffer的步长,为了处理对齐问题,与width可能不同
int format; // 图形Buffer的像素格式
const native_handle_t* handle; // 指向一块图形Buffer
uint64_t usage; // 图形Buffer的使用规则(gralloc会分配不同属性的图形Buffer)
...
} ANativeWindowBuffer_t;5.3 GraphicBuffer 的构造函数
GraphicBuffer有好几个,我们仅列出上述过程中涉及到的,源码如下:
[/frameworks/native/libs/ui/GraphicBuffer.cpp]
GraphicBuffer::GraphicBuffer()
: BASE(), mOwner(ownData), mBufferMapper(GraphicBufferMapper::get()), // 注意这里去初始化了 mBufferMapper
mInitCheck(NO_ERROR), mId(getUniqueId()), mGenerationNumber(0)
{
width =
height =
stride =
format =
usage_deprecated = 0;
usage = 0;
layerCount = 0;
handle = nullptr;
}
GraphicBuffer::GraphicBuffer(uint32_t inWidth, uint32_t inHeight, PixelFormat inFormat,
uint32_t inLayerCount, uint64_t inUsage, std::string requestorName)
: GraphicBuffer() {
// 调用 initWithSize 去完成内存分配
mInitCheck = initWithSize(inWidth, inHeight, inFormat, inLayerCount, inUsage,
std::move(requestorName));
}GraphicBuffer 的构造函数非常简单, 它只是调用了一个初始化函数 initWithSize,还有一点要注意就是去调用 GraphicBufferMapper::get() 初始化了 mBufferMapper。
GraphicBufferMapper 是一个单例模式的类,每个进程中只有一个实例,它向下对接 gralloc-mapper hal 的功能,负责把GraphicBufferAllocator分配的GraphicBuffer映射到当前进程空间。先简单看一下 GraphicBufferMapper 构造函数:
[/frameworks/native/libs/ui/GraphicBufferMapper.cpp]
GraphicBufferMapper::GraphicBufferMapper() {
// 按照版本由高到低的顺序加载 gralloc mapper, 成功则记录版本,然后退出
mMapper = std::make_unique<const Gralloc4Mapper>(); // 创建 Gralloc4Mapper 对象
if (mMapper->isLoaded()) {
mMapperVersion = Version::GRALLOC_4; // 加载成功 设置 mapper 的版本
return;
}
...
LOG_ALWAYS_FATAL("gralloc-mapper is missing");
}创建 GraphicBufferMapper 对象时,其构造函数中会去创建GrallocMapper对象,系统中会有不同版本的 grolloc-mapper,优先使用高版本,所以创建 Gralloc4Mapper 对象,再看 Gralloc4Mapper 的构造函数:
[/frameworks/native/libs/ui/Gralloc4.cpp]
Gralloc4Mapper::Gralloc4Mapper() {
mMapper = IMapper::getService(); // 去获取 gralloc mapper 服务,
...
}Gralloc4Mapper 的构造函数中去获取 gralloc-mapper hal service,这是一个 passthrough hal service,具体的信息我们等之后在讲解。
这里我们先暂时理解为:透过 GraphicBufferMapper & Gralloc4Mapper 我们就可以使用 gralloc-mapper hal 的功能了。
5.4 GraphicBuffer::initWithSize
这个函数是核心功能的实现的地方,
[ /frameworks/native/libs/ui/GraphicBuffer.cpp]
status_t GraphicBuffer::initWithSize(uint32_t inWidth, uint32_t inHeight,
PixelFormat inFormat, uint32_t inLayerCount, uint64_t inUsage,
std::string requestorName)
{
// 获取 GraphicBufferAllocator 对象,进程中单例
// GraphicBufferAllocator负责分配进程间共享的图形Buffer
GraphicBufferAllocator& allocator = GraphicBufferAllocator::get();
uint32_t outStride = 0;
// 分配一块指定宽高的 GraphicBuffer
status_t err = allocator.allocate(inWidth, inHeight, inFormat, inLayerCount,
inUsage, &handle, &outStride, mId,
std::move(requestorName));
if (err == NO_ERROR) {
mBufferMapper.getTransportSize(handle, &mTransportNumFds, &mTransportNumInts);
width = static_cast<int>(inWidth);
height = static_cast<int>(inHeight);
format = inFormat;
layerCount = inLayerCount;
usage = inUsage;
usage_deprecated = int(usage);
stride = static_cast<int>(outStride);
}
return err;
}申请成功的图形Buffer的属性会保存在GraphicBuffer父类ANativeWindowBuffer对应字段中:width/height/stride/format/usage/handle 。
图形buffer的分配,最终是通过 GraphicBufferAllocator 完成的,GraphicBufferAllocator 向下对接 gralloc-allocator hal 的功能。它是进程内单例,负责分配进程间共享的图形Buffer,对外即GraphicBuffer。简单看看其构造函数:
[/frameworks/native/libs/ui/GraphicBufferAllocator.cpp]
GraphicBufferAllocator::GraphicBufferAllocator() : mMapper(GraphicBufferMapper::getInstance()) {
// 按照版本由高到低的顺序加载 gralloc allocator, 成功则退出
mAllocator = std::make_unique<const Gralloc4Allocator>(
reinterpret_cast<const Gralloc4Mapper&>(mMapper.getGrallocMapper())); // 创建 Gralloc4Allocator
...
}构造函数中会去创建一个 Gralloc4Allocator 对象,并且传递一个 Gralloc4Mapper 对象作为参数:
[/frameworks/native/libs/ui/Gralloc4.cpp]
Gralloc4Allocator::Gralloc4Allocator(const Gralloc4Mapper& mapper) : mMapper(mapper) {
mAllocator = IAllocator::getService(); // 获取 gralloc allocator 服务
if (mAllocator == nullptr) {
ALOGW("allocator 3.x is not supported");
return;
}
}Gralloc4Allocator 的构造函数中去获取 gralloc-allocator hal service,这是一个 binderized hal service,具体的信息我们等之后在讲解。
这里我们先暂时理解为:透过 GraphicBufferAllocator & Gralloc4Allocator 我们就可以使用 gralloc-alloctor hal 的功能了。
申请图形Buffer时,除了宽、高、像素格式,还有一个usage参数,它表示申请方使用GraphicBuffer的行为,gralloc可以根据usage做对应优化,如下部分的 usage 枚举值:
[/frameworks/native/libs/ui/include/ui/GraphicBuffer.h]
[/hardware/libhardware/include/hardware/gralloc.h]
enum {
USAGE_SW_READ_NEVER = GRALLOC_USAGE_SW_READ_NEVER, // CPU不会读GraphicBuffer
USAGE_SW_READ_RARELY = GRALLOC_USAGE_SW_READ_RARELY, // CPU很少读GraphicBuffer
USAGE_SW_READ_OFTEN = GRALLOC_USAGE_SW_READ_OFTEN, // CPU经常读GraphicBuffer
USAGE_SW_READ_MASK = GRALLOC_USAGE_SW_READ_MASK,
USAGE_SW_WRITE_NEVER = GRALLOC_USAGE_SW_WRITE_NEVER, // CPU不会写GraphicBuffer
USAGE_SW_WRITE_RARELY = GRALLOC_USAGE_SW_WRITE_RARELY, // CPU很少写GraphicBuffer
USAGE_SW_WRITE_OFTEN = GRALLOC_USAGE_SW_WRITE_OFTEN, // CPU经常写GraphicBuffer
USAGE_SW_WRITE_MASK = GRALLOC_USAGE_SW_WRITE_MASK,
USAGE_SOFTWARE_MASK = USAGE_SW_READ_MASK|USAGE_SW_WRITE_MASK,
USAGE_PROTECTED = GRALLOC_USAGE_PROTECTED,
USAGE_HW_TEXTURE = GRALLOC_USAGE_HW_TEXTURE, // GraphicBuffer可以被上传为OpenGL ES texture,相当于GPU读GraphicBuffer
USAGE_HW_RENDER = GRALLOC_USAGE_HW_RENDER, // GraphicBuffer可以被当做OpenGL ES的渲染目标,相当于GPU写GraphicBuffer
USAGE_HW_2D = GRALLOC_USAGE_HW_2D, // GraphicBuffer will be used by the 2D hardware blitter
USAGE_HW_COMPOSER = GRALLOC_USAGE_HW_COMPOSER, // HWC可以直接使用GraphicBuffer进行合成
USAGE_HW_VIDEO_ENCODER = GRALLOC_USAGE_HW_VIDEO_ENCODER, // GraphicBuffer可以作为Video硬编码器的输入对象
USAGE_HW_MASK = GRALLOC_USAGE_HW_MASK,
USAGE_CURSOR = GRALLOC_USAGE_CURSOR, // buffer may be used as a cursor
};图形Buffer的申请方可以根据场景,使用不同的usage组合。
5.5 GraphicBufferAllocator::allocate
GraphicBufferAllocator 它是一个单例,外部使用时可以通过它来为 GraphicBuffer 来分配内存,Android 系统是为了屏蔽不同硬件平台的差异性,所以在framework 层使用它来为外部提供一个统一的接口。allocate 方法就是对外提供的分配内存的接口。
[/frameworks/native/libs/ui/GraphicBufferAllocator.cpp]
status_t GraphicBufferAllocator::allocate(uint32_t width, uint32_t height, PixelFormat format,
uint32_t layerCount, uint64_t usage,
buffer_handle_t* handle, uint32_t* stride,
uint64_t /*graphicBufferId*/, std::string requestorName) {
return allocateHelper(width, height, format, layerCount, usage, handle, stride, requestorName,
true);
}继续调用到 allocateHelper
status_t GraphicBufferAllocator::allocateHelper(uint32_t width, uint32_t height, PixelFormat format,
uint32_t layerCount, uint64_t usage,
buffer_handle_t* handle, uint32_t* stride,
std::string requestorName, bool importBuffer) {
// 前面一些代码都是在判断 width/height/format/layerCount 等信息是否合法及预处理
// 分配内存,调用 Gralloc4Allocator::allocate 去分配指定 width/height/format..的图形buffer
// 完成后handle就指向了这块图形缓存
status_t error = mAllocator->allocate(requestorName, width, height, format, layerCount, usage,
1, stride, handle, importBuffer);
...
if (!importBuffer) { // 如果不需要 注册buffer则返回,我们讲的流程 importBuffer = true
return NO_ERROR;
}
size_t bufSize;
// 计算 buffer size
if ((*stride) != 0 &&
std::numeric_limits<size_t>::max() / height / (*stride) < static_cast<size_t>(bpp)) {
bufSize = static_cast<size_t>(width) * height * bpp;
} else {
bufSize = static_cast<size_t>((*stride)) * height * bpp;
}
Mutex::Autolock _l(sLock);
KeyedVector<buffer_handle_t, alloc_rec_t>& list(sAllocList);
alloc_rec_t rec;
rec.width = width;
rec.height = height;
rec.stride = *stride;
rec.format = format;
rec.layerCount = layerCount;
rec.usage = usage;
rec.size = bufSize;
rec.requestorName = std::move(requestorName);
list.add(*handle, rec); // 把这块buffer的信息记录下来,放到sAllocList中,dumpsys SurfaceFlinger可以看到所有已分配的buffer的信息
return NO_ERROR;
}GraphicBufferAllocator::allocateHelper 的还是要继续调用 Gralloc4Allocator::allocate 去完成图形存储空间的分配,另一个就是它会把分配好的buffer的信息记录下来,放到 sAllocList 中,sAllocList 并不是保存具体的Buffer,而是Buffer的属性信息 alloc_rec_t。这样 dumpsys SurfaceFlinger可以看到所有已分配的buffer的信息。
比如下面我执行 dumpsys SurfaceFlinger 截取的部分信息,可以看到每一个 GraphicBuffer 的信息,包括 width/height/stride/usage/format/size
GraphicBufferAllocator buffers:
Handle | Size | W (Stride) x H | Layers | Format | Usage | Requestor
0xf2fc1060 | 8100.00 KiB | 1920 (1920) x 1080 | 1 | 1 | 0x 1b00 | FramebufferSurface
0xf2fc29c0 | 8100.00 KiB | 1920 (1920) x 1080 | 1 | 1 | 0x 1b00 | FramebufferSurface
0xf2fc32d0 | 8100.00 KiB | 1920 (1920) x 1080 | 1 | 1 | 0x 1b00 | FramebufferSurface
Total allocated by GraphicBufferAllocator (estimate): 24300.00 KB5.6 Gralloc4Allocator::allocate
GrallocAllocator 有多个实现版本,优先使用高版本 Gralloc4Allocator
[/frameworks/native/libs/ui/Gralloc4.cpp]
status_t Gralloc4Allocator::allocate(std::string requestorName, uint32_t width, uint32_t height,
android::PixelFormat format, uint32_t layerCount,
uint64_t usage, uint32_t bufferCount, uint32_t* outStride,
buffer_handle_t* outBufferHandles, bool importBuffers) const {
// 构建descriptorInfo对象,用于存储待创建的图形buffer的属性
IMapper::BufferDescriptorInfo descriptorInfo;
sBufferDescriptorInfo(requestorName, width, height, format, layerCount, usage, &descriptorInfo);
// 创建 BufferDescriptor 对象
// createDescriptor主要完成两个工作:1. 检查参数的合法性(设备是否支持);
// 2. 把BufferDescriptorInfo这个结构体变量进行重新的包装,
// 本质就是转化为byte stream,IPC时传递给IAllocator
BufferDescriptor descriptor;
status_t error = mMapper.createDescriptor(static_cast<void*>(&descriptorInfo),
static_cast<void*>(&descriptor));
if (error != NO_ERROR) {
return error;
}
// 调用 gralloc allocator hal service 去分配图形缓存
auto ret = mAllocator->allocate(descriptor, bufferCount,
[&](const auto& tmpError, const auto& tmpStride,
const auto& tmpBuffers) {
error = static_cast<status_t>(tmpError);
if (tmpError != Error::NONE) {
return;
}
if (importBuffers) {
for (uint32_t i = 0; i < bufferCount; i++) {
// importBuffer
error = mMapper.importBuffer(tmpBuffers[i],
&outBufferHandles[i]);
if (error != NO_ERROR) {
for (uint32_t j = 0; j < i; j++) {
mMapper.freeBuffer(outBufferHandles[j]);
outBufferHandles[j] = nullptr;
}
return;
}
}
} else {
for (uint32_t i = 0; i < bufferCount; i++) {
outBufferHandles[i] = native_handle_clone(
tmpBuffers[i].getNativeHandle());
if (!outBufferHandles[i]) {
for (uint32_t j = 0; j < i; j++) {
auto buffer = const_cast<native_handle_t*>(
outBufferHandles[j]);
native_handle_close(buffer);
native_handle_delete(buffer);
outBufferHandles[j] = nullptr;
}
}
}
}
*outStride = tmpStride;
});
// make sure the kernel driver sees BC_FREE_BUFFER and closes the fds now
hardware::IPCThreadState::self()->flushCommands();
return (ret.isOk()) ? error : static_cast<status_t>(kTransactionError);
}Gralloc4Allocator::allocate 中呼叫 gralloc-allocator hal service 完成最终的图形缓存分配,HAL 层调用使用的通信方式就是 HIDL,其实和我们使用的 AIDL 是类似的原理,最终得到指向图形buffer的 buffer_handle_t
本文作者@二的次方 2022-03-28 发布于博客园
ANativeWindowBuffer.handle是GraphicBuffer的核心数据成员,其类型native_handle_t的定义如下,其中还有定义 create, close, init, delete, clone等操作方法。[ /system/core/libcutils/include/cutils/native_handle.h]
typedef struct native_handle
{
int version; /* sizeof(native_handle_t) */
int numFds; /* number of file-descriptors at &data[0] */
int numInts; /* number of ints at &data[numFds] */
#if defined(__clang__)
#pragma clang diagnostic push
#pragma clang diagnostic ignored "-Wzero-length-array"
#endif
int data[0]; /* numFds + numInts ints */
#if defined(__clang__)
#pragma clang diagnostic pop
#endif
} native_handle_t;
typedef const native_handle_t* buffer_handle_t;
int native_handle_close(const native_handle_t* h);
native_handle_t* native_handle_init(char* storage, int numFds, int numInts);
native_handle_t* native_handle_create(int numFds, int numInts);
native_handle_t* native_handle_clone(const native_handle_t* handle);
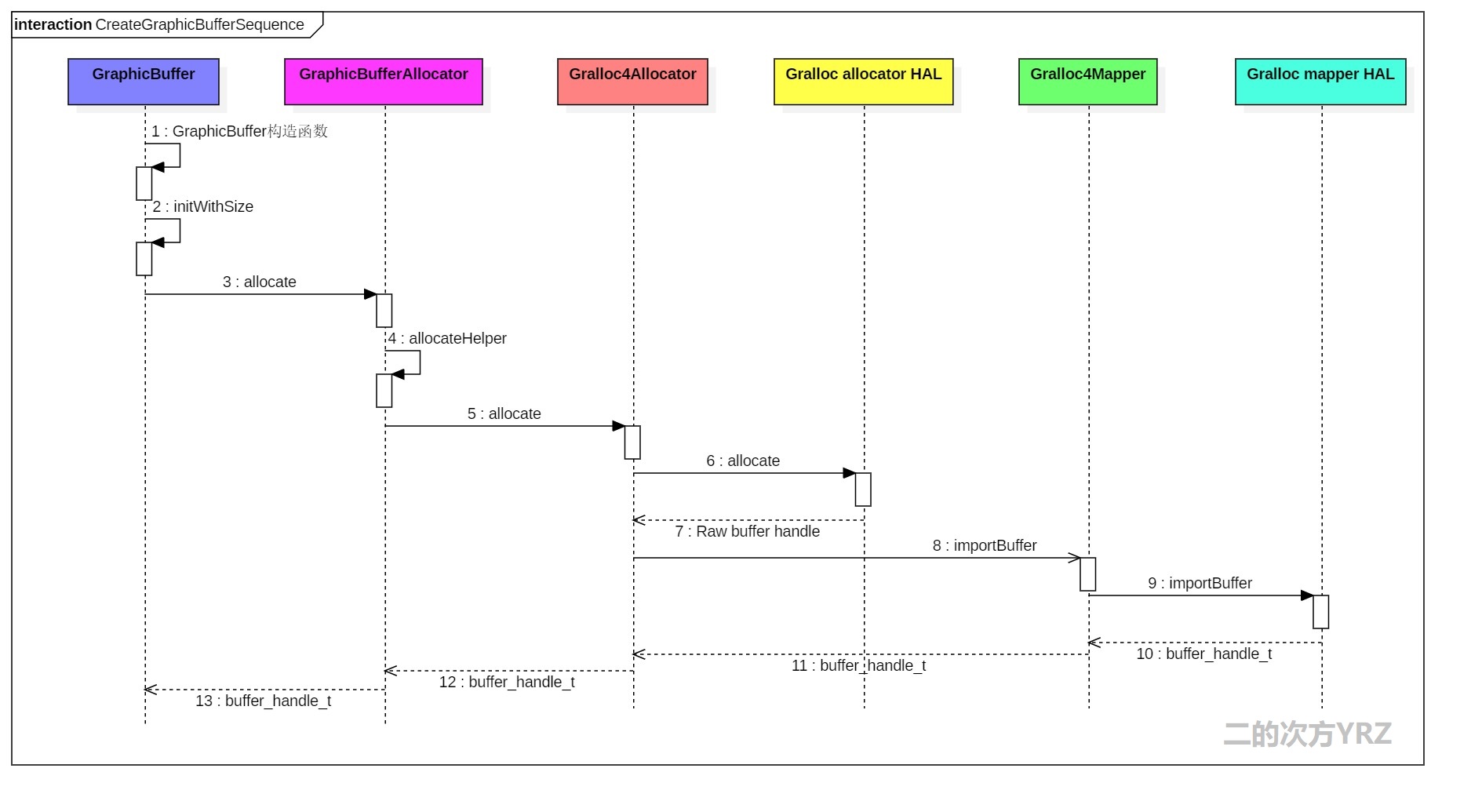
int native_handle_delete(native_handle_t* h);5.7 基本流程图
我们把上面代码描述的过程,简单总结为下面的图示。
六、GraphicBuffer的跨进程共享
在图形系统中,生产者和最终的消费者往往不在同一个进程中,所以 GraphicBuffer 需要跨进程传递,以实现数据共享。我们先用一张流程图来概况:
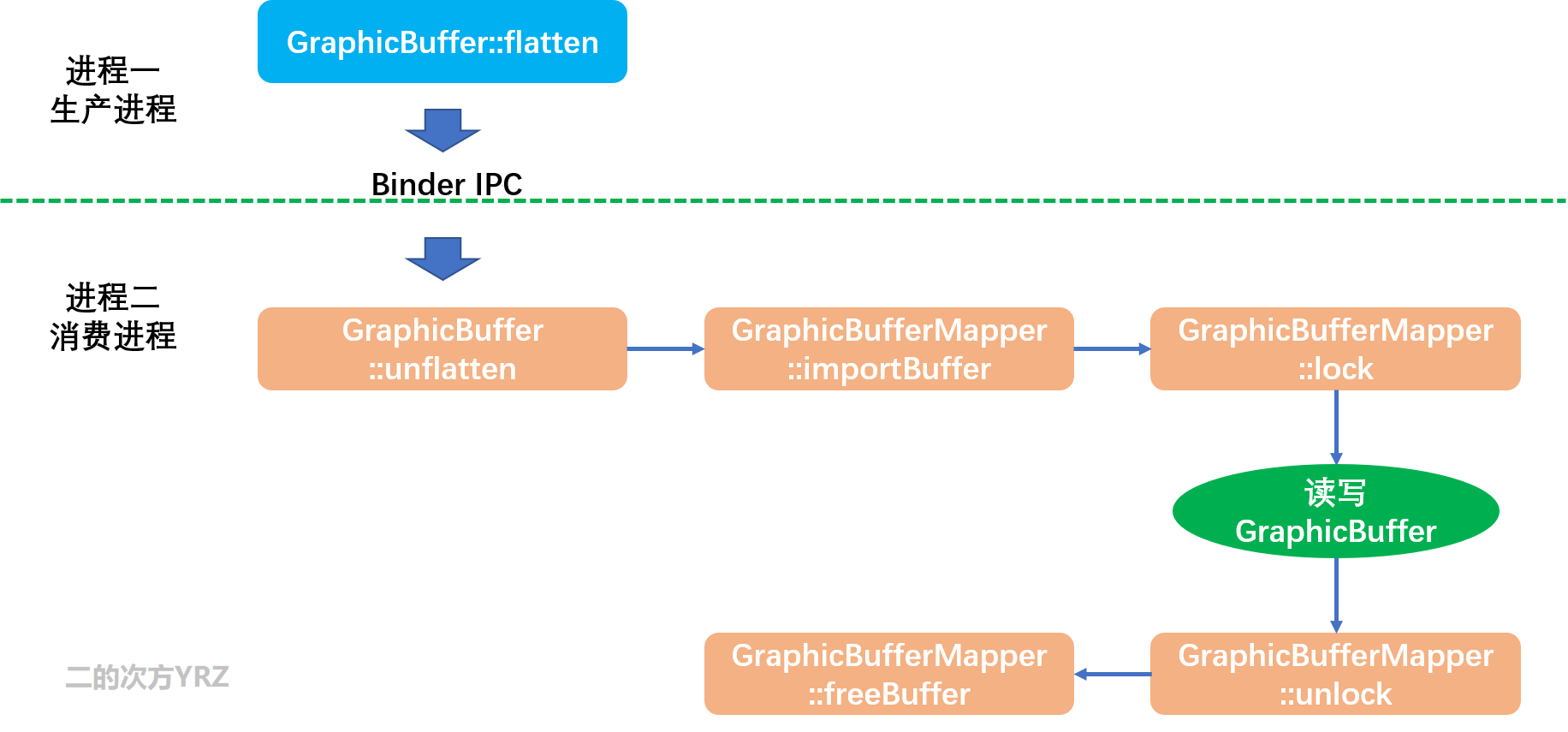
1. 首先,生产进程通过GraphicBuffer::flatten把ANativeWindowBuffer关键属性保存在两个数组中:buffer和fds,其实就是 Binder 数据传输前的序列化处理;
2. 其次,跨进程传输buffer和fds,这里一般就是 Binder IPC 跨进程通信;
3. 然后,消费进程通过GraphicBuffer::unflatten在自己的进程中重建ANativeWindowBuffer,关键是重建ANativeWindowBuffer.handle这个结构体成员,相当于把生产进程的GraphicBuffer映射到了消费进程;
4. 最后,遵循 importBuffer->lock->读写GraphicBuffer->unlock->freeBuffer 的基本流程操作GraphicBuffer。
ANativeWindowBuffer属性(width,height,stride...),真正的底层图形显存(内存)是进程间共享的。 从上下文可以看出,GraphicBufferAllocator负责在生产进程申请和释放GraphicBuffer,GraphicBufferMapper负责在消费进程操作GraphicBuffer。GraphicBufferMapper对GraphicBuffer的所有操作最后都是通过 gralloc mapper HAL 模块实现的。感兴趣的的可以去参考源码中 IMapper的定义:/hardware/interfaces/graphics/mapper/4.0/IMapper.hal,还有一些厂商的实现 Open Source Mali GPUs Android Gralloc Module
根据上面的流程,我们看看一些关键的代码:
[/frameworks/native/libs/ui/GraphicBuffer.cpp]
// 计算传输GraphicBuffer需要的Size,字节数
size_t GraphicBuffer::getFlattenedSize() const {
return static_cast<size_t>(13 + (handle ? mTransportNumInts : 0)) * sizeof(int);
}
// 获取native_handle_t中需要传输的文件描述符数量
size_t GraphicBuffer::getFdCount() const {
return static_cast<size_t>(handle ? mTransportNumFds : 0);
}
// 把GraphicBuffer关键属性保存在buffer和fds中,以进行Binder传输
// size表示buffer数组可用长度,count表示fds数组可用长度
status_t GraphicBuffer::flatten(void*& buffer, size_t& size, int*& fds, size_t& count) const {
size_t sizeNeeded = GraphicBuffer::getFlattenedSize();
if (size < sizeNeeded) return NO_MEMORY; // 判断buffer可用长度是否足够
size_t fdCountNeeded = GraphicBuffer::getFdCount();
if (count < fdCountNeeded) return NO_MEMORY; //判断fds数组长度是否足够
// 把当前GraphicBuffer的关键属性存储在buffer中
int32_t* buf = static_cast<int32_t*>(buffer);
buf[0] = 'GB01';
buf[1] = width;
buf[2] = height;
buf[3] = stride;
buf[4] = format;
buf[5] = static_cast<int32_t>(layerCount);
buf[6] = int(usage); // low 32-bits
buf[7] = static_cast<int32_t>(mId >> 32);
buf[8] = static_cast<int32_t>(mId & 0xFFFFFFFFull);
buf[9] = static_cast<int32_t>(mGenerationNumber);
buf[10] = 0;
buf[11] = 0;
buf[12] = int(usage >> 32); // high 32-bits
if (handle) {
buf[10] = int32_t(mTransportNumFds); // 存储传递的文件描述符数量
buf[11] = int32_t(mTransportNumInts); // 存储传递的int数据的数量
// copy文件描述符数组到fds
memcpy(fds, handle->data, static_cast<size_t>(mTransportNumFds) * sizeof(int));
// copy int数组到buffer
memcpy(buf + 13, handle->data + handle->numFds,
static_cast<size_t>(mTransportNumInts) * sizeof(int));
}
// 修改buffer地址和可用长度
buffer = static_cast<void*>(static_cast<uint8_t*>(buffer) + sizeNeeded);
size -= sizeNeeded;
if (handle) {
fds += mTransportNumFds; // 修改fds地址和可用长度
count -= static_cast<size_t>(mTransportNumFds);
}
return NO_ERROR;
}
// 根据Binder传输的buffer和fds中,把创建进程的GraphicBuffer映射到使用进程
status_t GraphicBuffer::unflatten(void const*& buffer, size_t& size, int const*& fds,
size_t& count) {
// Check if size is not smaller than buf[0] is supposed to take.
if (size < sizeof(int)) {
return NO_MEMORY;
}
int const* buf = static_cast<int const*>(buffer);
// NOTE: it turns out that some media code generates a flattened GraphicBuffer manually!!!!!
// see H2BGraphicBufferProducer.cpp
uint32_t flattenWordCount = 0;
if (buf[0] == 'GB01') {
// new version with 64-bits usage bits
flattenWordCount = 13;
} else if (buf[0] == 'GBFR') {
// old version, when usage bits were 32-bits
flattenWordCount = 12;
} else {
return BAD_TYPE;
}
// 判断buffer的正确性
if (size < 12 * sizeof(int)) {
android_errorWriteLog(0x534e4554, "114223584");
return NO_MEMORY;
}
// 取出文件描述符和int数组的数量
const size_t numFds = static_cast<size_t>(buf[10]);
const size_t numInts = static_cast<size_t>(buf[11]);
// Limit the maxNumber to be relatively small. The number of fds or ints
// should not come close to this number, and the number itself was simply
// chosen to be high enough to not cause issues and low enough to prevent
// overflow problems.
const size_t maxNumber = 4096;
if (numFds >= maxNumber || numInts >= (maxNumber - flattenWordCount)) {
width = height = stride = format = usage_deprecated = 0;
layerCount = 0;
usage = 0;
handle = nullptr;
ALOGE("unflatten: numFds or numInts is too large: %zd, %zd", numFds, numInts);
return BAD_VALUE;
}
const size_t sizeNeeded = (flattenWordCount + numInts) * sizeof(int);
if (size < sizeNeeded) return NO_MEMORY; // 判断buffer长度是否正确
size_t fdCountNeeded = numFds;
if (count < fdCountNeeded) return NO_MEMORY; // 判断fds长度是否正确
if (handle) {
// free previous handle if any
free_handle(); // 如果有,先释放之前的ANativeWindowBuffer.handle
}
if (numFds || numInts) {
width = buf[1];
height = buf[2];
stride = buf[3];
format = buf[4];
layerCount = static_cast<uintptr_t>(buf[5]);
usage_deprecated = buf[6];
if (flattenWordCount == 13) {
usage = (uint64_t(buf[12]) << 32) | uint32_t(buf[6]);
} else {
usage = uint64_t(usage_deprecated);
}
native_handle* h = // 创建ANativeWindowBuffer.handle,native_handle_create定义在native_handle.c
native_handle_create(static_cast<int>(numFds), static_cast<int>(numInts));
if (!h) {
width = height = stride = format = usage_deprecated = 0;
layerCount = 0;
usage = 0;
handle = nullptr;
ALOGE("unflatten: native_handle_create failed");
return NO_MEMORY;
}
// 从fds和buffer中copy文件描述符和int数组到ANativeWindowBuffer.handle结构体
memcpy(h->data, fds, numFds * sizeof(int));
memcpy(h->data + numFds, buf + flattenWordCount, numInts * sizeof(int));
handle = h;
} else {
width = height = stride = format = usage_deprecated = 0;
layerCount = 0;
usage = 0;
handle = nullptr;
}
// 从buffer中恢复其他字段
mId = static_cast<uint64_t>(buf[7]) << 32;
mId |= static_cast<uint32_t>(buf[8]);
mGenerationNumber = static_cast<uint32_t>(buf[9]);
// 表示GraphicBuffer是从其他进程映射过来的,决定了释放GraphicBuffer的逻辑
mOwner = ownHandle;
if (handle != nullptr) {
// 调用importBuffer,把GraphicBuffer映射到当前进程
buffer_handle_t importedHandle;
status_t err = mBufferMapper.importBuffer(handle, uint32_t(width), uint32_t(height),
uint32_t(layerCount), format, usage, uint32_t(stride), &importedHandle);
if (err != NO_ERROR) {
width = height = stride = format = usage_deprecated = 0;
layerCount = 0;
usage = 0;
handle = nullptr;
ALOGE("unflatten: registerBuffer failed: %s (%d)", strerror(-err), err);
return err;
}
// 关闭释放映射前的handle
native_handle_close(handle);
native_handle_delete(const_cast<native_handle_t*>(handle));
// 赋值为importedHandle,这个handle即可以在当前进程使用了
handle = importedHandle;
mBufferMapper.getTransportSize(handle, &mTransportNumFds, &mTransportNumInts);
}
// 调整buffer和fds数组的地址和可用长度
buffer = static_cast<void const*>(static_cast<uint8_t const*>(buffer) + sizeNeeded);
size -= sizeNeeded;
fds += numFds;
count -= numFds;
return NO_ERROR;
}七、GraphicBuffer的释放
前面讲了 GraphicBuffer 的创建,那它是怎样被释放的呢?先看看析构函数的定义:
[/frameworks/native/libs/ui/GraphicBuffer.cpp]
GraphicBuffer::~GraphicBuffer()
{
ATRACE_CALL();
if (handle) {
free_handle(); // handle不是null,需要free
}
for (auto& [callback, context] : mDeathCallbacks) {
callback(context, mId);
}
}
void GraphicBuffer::free_handle()
{
if (mOwner == ownHandle) {
// 仅仅持有handle句柄, 表示图形Buffer不是自己创建的,
// 而是从生产进程映射过来的,即当前处于消费进程
mBufferMapper.freeBuffer(handle);
} else if (mOwner == ownData) {
// 拥有数据,表示图形Buffer是自己创建的,需要自己释放,即处于生产进程
GraphicBufferAllocator& allocator(GraphicBufferAllocator::get());
allocator.free(handle);
}
handle = nullptr;
}指向同一块图形Buffer的GraphicBuffer可以存在多个实例,但是底层的图形Buffer是同一个。讲到这里突然有个疑问:生产进程和消费进程是如何做到同步的?即会不会出现生产进程把GraphicBuffer释放掉了,而消费进程还在访问这个GraphicBuffer的状况?
八、小结
本篇文章分析了GraphicBuffer相关的组件、概念及创建释放的流程。包括 Gralloc HAL模块,以及libui库中的主要组件的逻辑。文中观点也是本人边学习,边输出的,难免有错误之处。部分内容的细节也没有深入刨析,后续在学习中会再陆续补充。
下一篇文中中会讲讲 Binderized HAL 和 Passthrough HAL 的一点知识,加深对 IMapper 和 IAllocator 模块的理解。

Android 12(S) 图形显示系统 - 解读Gralloc架构及GraphicBuffer创建/传递/释放(十四)的更多相关文章
- Android 12(S) 图形显示系统 - SurfaceFlinger的启动和消息队列处理机制(四)
1 前言 SurfaceFlinger作为Android图形显示系统处理逻辑的核心单元,我们有必要去了解其是如何启动,初始化及进行消息处理的.这篇文章我们就来简单分析SurfaceFlinger这个B ...
- Android 12(S) 图形显示系统 - createSurface的流程(五)
题外话 刚刚开始着笔写作这篇文章时,正好看电视在采访一位92岁的考古学家,在他的日记中有这样一句话,写在这里与君共勉"不要等待幸运的降临,要去努力的掌握知识".如此朴实的一句话,此 ...
- Android 12(S) 图形显示系统 - BufferQueue/BLASTBufferQueue之初识(六)
题外话 你有没有听见,心里有一声咆哮,那一声咆哮,它好像在说:我就是要从后面追上去! 写文章真的好痛苦,特别是自己对这方面的知识也一知半解就更加痛苦了.这已经是这个系列的第六篇了,很多次都想放弃了,但 ...
- Android 12(S) 图形显示系统 - 基本概念(一)
1 前言 Android图形系统是系统框架中一个非常重要的子系统,与其它子系统一样,Android 框架提供了各种用于 2D 和 3D 图形渲染的 API供开发者使用来创建绚丽多彩的应用APP.图形渲 ...
- Android 12(S) 图形显示系统 - 应用建立和SurfaceFlinger的沟通桥梁(三)
1 前言 上一篇文章中我们已经创建了一个Native示例应用,从使用者的角度了解了图形显示系统API的基本使用,从这篇文章开始我们将基于这个示例应用深入图形显示系统API的内部实现逻辑,分析运作流程. ...
- Android 12(S) 图形显示系统 - BufferQueue的工作流程(九)
题外话 Covid-19疫情的强烈反弹,小区里检测出了无症状感染者.小区封闭管理,我也不得不居家办公了.既然这么大把的时间可以光明正大的宅家里,自然要好好利用,八个字 == 努力工作,好好学习 一.前 ...
- Android 12(S) 图形显示系统 - 示例应用(二)
1 前言 为了更深刻的理解Android图形系统抽象的概念和BufferQueue的工作机制,这篇文章我们将从Native Level入手,基于Android图形系统API写作一个简单的图形处理小程序 ...
- Android 12(S) 图形显示系统 - 初识ANativeWindow/Surface/SurfaceControl(七)
题外话 "行百里者半九十",是说步行一百里路,走过九十里,只能算是走了一半.因为步行越接近目的地,走起来越困难.借指凡事到了接近成功,往往是最吃力.最艰难的时段.劝人做事贵在坚持, ...
- Android 12(S) 图形显示系统 - BufferQueue的工作流程(八)
题外话 最近总有一个感觉:在不断学习中,越发的感觉自己的无知,自己是不是要从"愚昧之巅"掉到"绝望之谷"了,哈哈哈 邓宁-克鲁格效应 一.前言 前面的文章中已经 ...
随机推荐
- Win10 装好 Hyper-V 又要将其卸载方法记录
现需要在 windows 上安装虚拟机使用 linux 系统,遂想起来 win10 本身就有 Hyper-V 虚拟工具,但是 win10 家庭版并没有这个服务,百度之,找到了方法(Win10家庭版怎么 ...
- Hook(钩子技术)基本知识讲解,原理
一.什么是HOOK(钩子) API Windows消息传递机制,当在应用程序进行相关操作,例如点击鼠标.按下键盘,操作窗口等,操作系统能够感知这一事件,接着把此消息放到系统消息队列,然后到应用程序的 ...
- win7重装系统过程关机 电脑开机黑屏 硬盘无法识别 无法使用u盘启动
问题:win7重装系统中强制重启导致硬盘无法识别,开机后无法选择使用u盘启动盘启动,电脑黑屏,将硬盘拆掉可以使用u盘启动,使用SATA转接口在win7中有反应但无法识别 无法识别原因:重装系统过程中断 ...
- Eclipse Debug 调试步骤及注意事项
debug方法 第一步:打开java代码文件,在左侧双击鼠标设置断点,或者在左侧右键点击Toggle Breakpoint 第二步:点击eclipse上方的"蜘蛛"按钮,点击deb ...
- ts转js运行报错:“tsc : 无法加载文件
一.在typescript.ts转换成.js运行时报错解决办法: 1.第一步:鼠标在vscode软件上右击打开属性–>兼容性–>以管理员的身份运行此程序,如下图: 2.第二步:打开vsco ...
- VS 返回值被忽略的解决方法
•问题 用 Visual Studio 编写 C++ 代码的时候,一旦用到 scanf , freopen 等函数的时候,编译器总会不合时宜的给你提示 "返回值被忽略",那么该如何 ...
- Leaflet:LayerGroup、FeatureGroup
LayerGroup(Layer) Layer 用法:把一些Layer集中到一个组Group中,以便作为一个整体进行操作.如果把该Group加入到了Map中,任何从这个Group增加或者移除Layer ...
- JZ-069-在 O(1) 时间内删除链表节点
在 O(1) 时间内删除链表节点 题目描述 在 O(1) 时间内删除链表节点. 方案:如果该节点不是尾节点,那么可以直接将下一个节点的值赋给该节点,然后令该节点指向下下个节点,再删除下一个节点,时间复 ...
- nginx 配置 https,及加载配置文件夹
首先需要去申请一个域名签名证书,在腾讯云,阿里云都有免费版,然后下载下来按如下配置,请根据自己路径更改 server { listen 80; server_name xxx.xxx.cn; root ...
- Netty异步Future源码解读
本文地址: https://juejin.im/post/5df771ee6fb9a0161d743069 说在前面 本文的 Netty源码使用的是 4.1.31.Final 版本,不同版本会有一些差 ...