分库分表实现方式Client和Proxy,性能和维护性该怎么选?
大家好,我是【架构摆渡人】,一只十年的程序猿。这是分库分表系列的第一篇文章,这个系列会给大家分享很多在实际工作中有用的经验,如果有收获,还请分享给更多的朋友。
其实这个系列有录过视频给大家学习,但很多读者反馈说看视频太慢了。也不好沉淀为文档资料,希望能有一系列文字版本的讲解,要用的时候可以快速浏览关键的知识点。那么它就来了,我再花点时间写成几篇连续的文章供大家学习。
分库分表的手段
手动路由
如果没有复杂的操作,手动路由相对来说是简单的方式。比如你的操作只根据分片键操作,那么通过分片键你可以计算出这条数据的库和表,从而将你的SQL路由到指定的库进行执行。
这里主要是要在执行SQL的时候,动态获取对应的数据源,获取到数据源之后就用这个数据源进行SQL的执行。至于SQL在哪张表即SQL拼接的时候就已经知道了。
这也是最简单的实现分库分表的方式,但是实际业务中,我们不可能只根据分片键进行查询,假设有非分片键的查询,就还涉及到数据聚合,分页的问题,如果每个业务都要自己处理,这复杂度就太高了,所以我们需要一款中间件来支撑分库分表的需求。
中间件
分库分表中间件的出现,降低了分库分表的门槛,也极大的提升了开发效率。中间件内部会回SQL进行校验,解析,路由,聚合等逻辑。同时也会考虑到可用性,易用性等方面。
目前中间件主要分为两种类型,一种是Client方式的中间件,比如Sharding-JDBC,Ctrip DAL,TSharding等优秀的中间件。
一种是Proxy方式的中间件,比如ShardingSphere,Mycat等优秀的中间件。
Client和Proxy方式对比
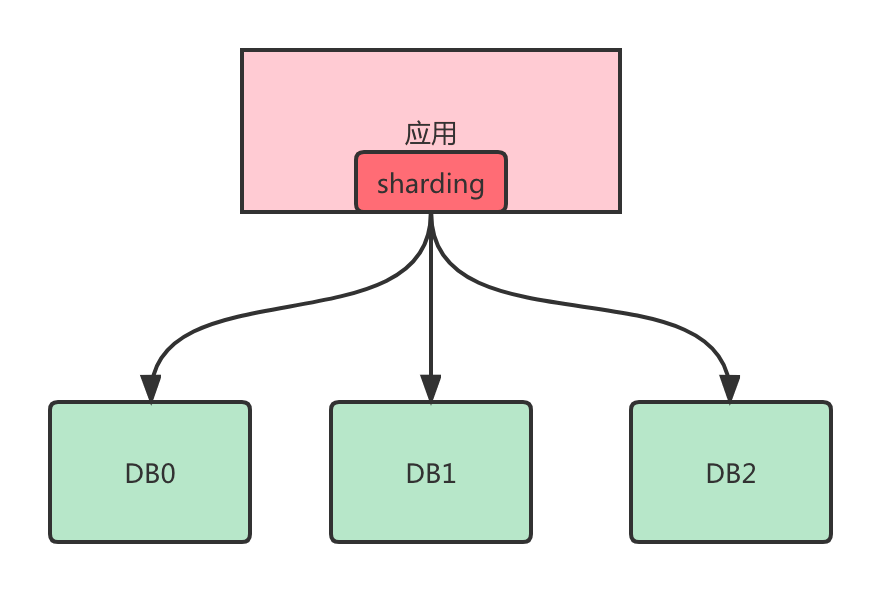
Client方式是指分库分表的逻辑都在应用本地进行控制,应用本地会直连多个数据库进行操作,然后本地进行数据的聚合汇总等操作逻辑。
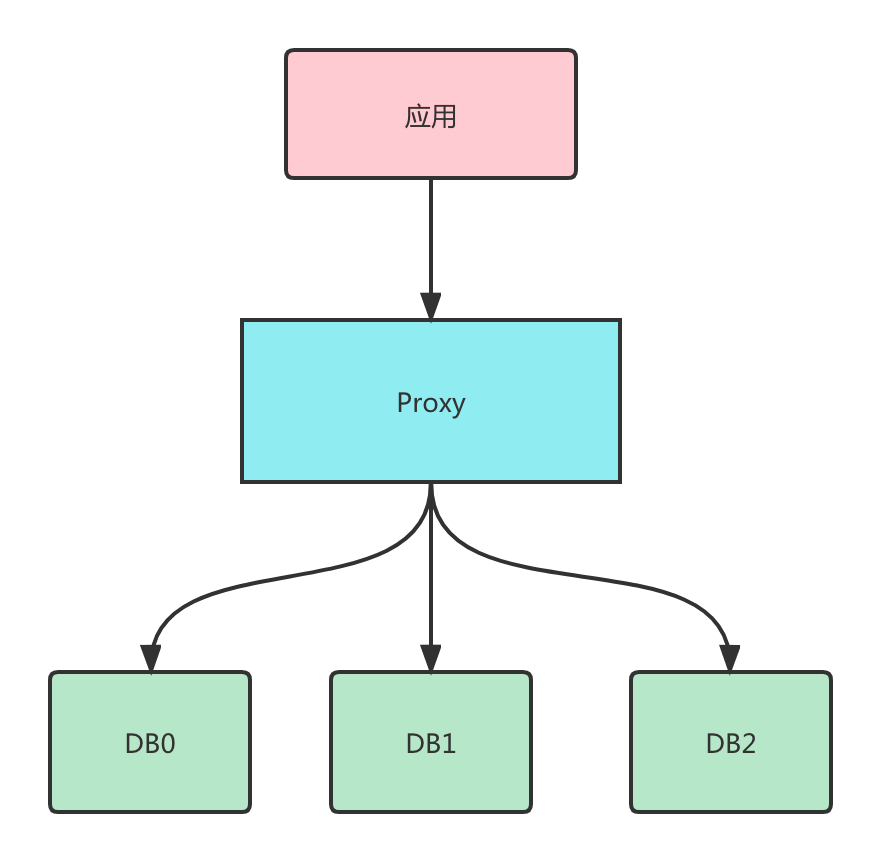
Proxy方式是指挥有一个独立的应用,这个应用实现了Mysql的协议,可以对外提供服务。业务方的应用不需要直接连接数据库,而是连接这个Proxy的应用,把这个Proxy就当做一个数据库使用。Proxy会将Sql分发到具体的数据库进行执行,并返回结果。
性能方面比较
从性能这块去比较多的话,Client方式性能更好。Client方式采用的是应用直连数据库的形式,一条SQL直达数据库,拿到结果直接就可以用了,基本上跟我们没分库分表之前差不了多少。
Proxy方式在性能方法会有一点损耗,因为中间多了一次路由操作。就是SQL由应用到Proxy,Proxy再将SQL路由到具体的数据库,拿到结果,再响应给应用。
内存方面比较
从内存占用这块去比较的话,Client方式不是很好。Client方式拿到数据库响应的内容后要在应用本地进行聚合操作,内存,cpu等都是占用当前应用的资源。
Proxy方式也是会占用内存,但是它的内存不是当前应用的内存,而是Proxy这个应用的内存,Proxy应用是单独部署的,所以是隔离的状态。同时Proxy是会集群部署的,所以会更好点。
连接数方面比较
Client方式在连接数方面会占用的比较多,每个应用都会直接连接每个库,每个库也就是一个连接池。
Proxy方式连接数会相对较少一点,每个库只需要一个连接池即可。应用连接Proxy占用的就不是数据库的连接了。当然如果Proxy集群的节点多的话,连接数也是会相应的增多。
架构复杂度比较
Client方式在架构方面比较简单,通常是依赖一个Jar包,不会出现单点故障问题。
Proxy方式需要单独部署一个独立的服务,并且这个服务也要考虑高可用,整体的架构复杂度还是比较高的,所以小团队建议大家用Client方式。
从升级方面比较
Client方式每个项目都要依赖Jar包,一但版本有什么问题,出了新的修复版本,所有项目都得跟着升级。小公司还好,就那么几个项目,大公司的项目成百上千,而且都是属于不同团队下的,这种中间件是属于基础架构团队的,要推动业务团队升级其实很困难的,没个半年基本上很难全部都升级完。
Proxy方式在这方面的优势就提现出来了,有什么新功能或者修复了什么Bug,只需要Proxy集群重新发布一遍即可,使用方完全不需要关心,也就不存在推动升级的问题了。但是需要做好一点:发布过程中必须无损。这边应用时刻都在执行SQL,你发布不能导致应用执行SQL报错。
统一管控方面比较
Client方式要做统一管控,必须得进行升级,但是升级又是一个很耗时的推动过程。
Proxy方式在统一管控方式就容易的多,比如对SQL的限流,监控,告警等管控,是不需要客户端关心的。除了这些管控,还有一些其他的管控,比如异地多活场景下的禁写,禁读操作,都是管控的点。如果用Client方式确实不太好统一处理。
总结
今天主要给大家介绍了如何进行分库分表中间件的选型,不同的阶段其实适合不同的中间件。规模不大时建议用Client方式的中间件,使用简单,也没什么维护成本。规模大了后建议用Proxy方式的中间件,更方便统一管控和维护。
原创:架构摆渡人(公众号ID:jiagoubaiduren),欢迎分享,转载请保留出处。
本文已收录至学习网站 http://cxytiandi.com/ ,里面有Spring Boot, Spring Cloud,分库分表,微服务,面试等相关内容。
分库分表实现方式Client和Proxy,性能和维护性该怎么选?的更多相关文章
- Docker安装Mycat和Mysql进行水平分库分表实战【图文教学】
一.前言 小编最近公司有个新的需求,数据量比较大,要涉及到分库分表.大概了解了一些主流的中间件,使用和网上资料比较多的是Mycat和sharding-jdbc,小编比较倾向于Mycat.原因很简单就是 ...
- mysql 分表实现方法详解
如果你需要进行mysql分表了我们就证明你数据库比较大了,就是把一张表分成N多个小表,分表后,单表的并发能力提高了,磁盘I/O性能也提高了.并发能力为什么提高了呢,因为查寻一次所花的时间变短了,如果出 ...
- 转载:mysql 对于百万 千万级数据的分表实现方法
一般来说,当我们的数据库的数据超过了100w记录的时候就应该考虑分表或者分区了,这次我来详细说说分表的一些方法.目前我所知道的方法都是MYISAM的,INNODB如何做分表并且保留事务和外键,我还不是 ...
- ShardingSphere-proxy-5.0.0部署之分表实现(一)
一.说明 环境准备:JDK8+ mysql 5.x 官网:https://shardingsphere.apache.org/ 下载地址:https://archive.apache.org/ ...
- Sharding-JDBC 按日期时间分库分表
简介 Sharding-JDBC 定位为轻量级Java框架,在Java的JDBC层提供的额外服务. 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完 ...
- Java实战:教你如何进行数据库分库分表
摘要:本文通过实际案例,说明如何按日期来对订单数据进行水平分库和分表,实现数据的分布式查询和操作. 本文分享自华为云社区<数据库分库分表Java实战经验总结 丨[绽放吧!数据库]>,作者: ...
- 《MyCat分库分表策略详解》
在我们的项目发展到一定阶段之后,随着数据量的增大,分库分表就变成了一件非常自然的事情.常见的分库分表方式有两种:客户端模式和服务器模式,这两种的典型代表有sharding-jdbc和MyCat.所谓的 ...
- Sharding-JDBC基本使用,整合Springboot实现分库分表,读写分离
结合上一篇docker部署的mysql主从, 本篇主要讲解SpringBoot项目结合Sharding-JDBC如何实现分库分表.读写分离. 一.Sharding-JDBC介绍 1.这里引用官网上的介 ...
- mysql分库分表(一)
mysql分库分表 参考: https://blog.csdn.net/xlgen157387/article/details/53976153 https://blog.csdn.net/cleve ...
随机推荐
- Java的jmap命令使用详解
jmap命令简介 jmap(Java Virtual Machine Memory Map)是JDK提供的一个可以生成Java虚拟机的堆转储快照dump文件的命令行工具.除此以外,jmap命令还可以查 ...
- 使用SymPy
最近工作的原因,需要进行一些积分运算,通过一些搜索得知了SymPy,记录一下使用历程. 1. SymPy介绍 SymPy是关于Symbolic Mathematics的Python库,它旨在成为一个功 ...
- DDOS流量攻击
0x01 环境 包含2台主机 attact 作为攻击方,使用Centos7.2 windows_server ,用于被攻击,同时抓包分析流量 ,任意版本均可.安装wireshark,用于抓包 0x02 ...
- CVE-2017-12635(Couchdb垂直权限绕过漏洞)
简介 Apache CouchDB是一个开源数据库,专注于易用性和成为"完全拥抱web的数据库".它是一个使用JSON作为存储格式,JavaScript作为查询语言,MapRedu ...
- python 发送GET请求
# #博客地址:https://blog.csdn.net/qq_36374896 # 特点:把数据拼接到请求路径的后面传递给服务器 # # 优点:速度快 # # 缺点:承载的数据量小,不安全 imp ...
- djinn
靶机准备 将靶机ova文件导入虚拟机,并将网络设置为NAT 开机获得ip:192.168.164.188 kali:192.168.164.137 渗透测试 扫描端口 nmap -sS -sV -T5 ...
- maven常用命令含义
今天在开发过程中,对一个mapper.xml文件的sql进行了改动,重启tomcat后发现没有生效,首先考虑是不是远程服务开启着,导致代码没有走本地,确认远程服务是关闭的,的确是本地修改没有生效,于是 ...
- MySQL 中有哪些不同的表格?
共有 5 种类型的表格: 1.MyISAM 2.Heap 3.Merge 4.INNODB 5.ISAM
- 如何通过HibernateDaoSupport将Spring和Hibernate 结合起来?
用 Spring 的 SessionFactory 调用 LocalSessionFactory.集成过程分三步: 配置 the Hibernate SessionFactory. 继承 Hibern ...
- 并发包中automic类的原理
提到同步,我们一般首先想到的是lock,synchronized,但java中有一套更加轻量级的同步方式即atomic类.java的并发原子包里面提供了很多可以进行原子操作的类,比如: AtomicI ...