Hash冲突以及解决
哈希函数:它把一个大范围的数字哈希(转化)成一个小范围的数字,这个小范围的数对应着数组的下标。使用哈希函数向数组插入数据后,这个数组就是哈希表。
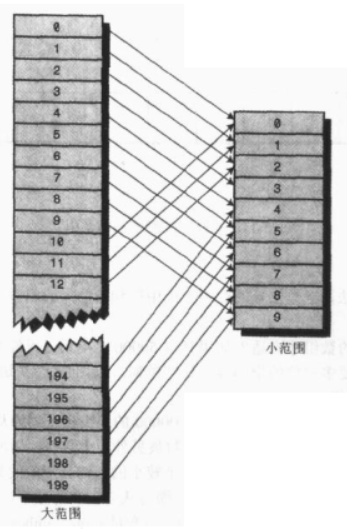
冲突
当冲突产生时,一个方法是通过系统的方法找到数组的一个空位,并把这个单词填入,而不再用哈希函数得到数组的下标,这种方法称为开放地址法。
组的每个数据项都创建一个子链表或子数组,那么数组内不直接存放单词,当产生冲突时,新的数据项直接存放到这个数组下标表示的链表中,这种方法称为链地址法。
开放地址法
线性探测: 它沿着数组下标一步一步顺序的查找空白单元。
二次探测: 思想是探测相距较远的单元,而不是和原始位置相邻的单元。
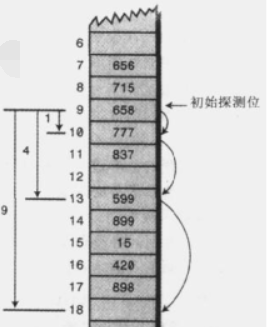
再哈希法:再来一次Hash找位置
链地址法
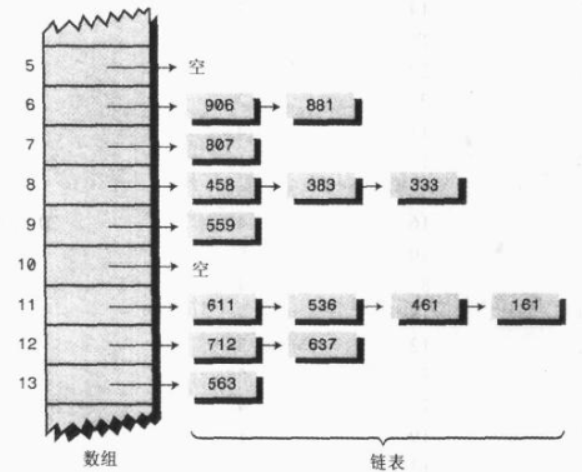
自己写“Hash”
线性探测
public class MyHashTable {
private DataItem[] hashArray; //DataItem类,表示每个数据项信息
private int arraySize;//数组的初始大小
private int itemNum;//数组实际存储了多少项数据
private DataItem nonItem;//用于删除数据项
public MyHashTable(int arraySize){
this.arraySize = arraySize;
hashArray =new DataItem[arraySize];
nonItem =new DataItem(-1);//删除的数据项下标为-1
}
//判断数组是否存储满了
public boolean isFull(){
return (itemNum == arraySize);
}
//判断数组是否为空
public boolean isEmpty(){
return (itemNum ==0);
}
//打印数组内容
public void display(){
System.out.println("Table:");
for(int j =0 ; j < arraySize ; j++){
if(hashArray[j] !=null){
System.out.print(hashArray[j].getKey() +" ");
}else{
System.out.print("** ");
}
}
}
//通过哈希函数转换得到数组下标
public int hashFunction(int key){
return key%arraySize;
}
//插入数据项
public void insert(DataItem item){
if(isFull()){
//扩展哈希表
System.out.println("哈希表已满,重新哈希化...");
extendHashTable();
}
int key = item.getKey();
int hashVal = hashFunction(key);
while(hashArray[hashVal] !=null && hashArray[hashVal].getKey() != -1){
++hashVal;
hashVal %= arraySize;
}
hashArray[hashVal] = item;
itemNum++;
}
/**
* 数组有固定的大小,而且不能扩展,所以扩展哈希表只能另外创建一个更大的数组,然后把旧数组中的数据插到新的数组中。
* 但是哈希表是根据数组大小计算给定数据的位置的,所以这些数据项不能再放在新数组中和老数组相同的位置上。
* 因此不能直接拷贝,需要按顺序遍历老数组,并使用insert方法向新数组中插入每个数据项。
* 这个过程叫做重新哈希化。这是一个耗时的过程,但如果数组要进行扩展,这个过程是必须的。
*/
public void extendHashTable(){
int num = arraySize;
itemNum =0;//重新计数,因为下面要把原来的数据转移到新的扩张的数组中
arraySize *=2;//数组大小翻倍
DataItem[] oldHashArray = hashArray;
hashArray =new DataItem[arraySize];
for(int i =0 ; i < num ; i++){
insert(oldHashArray[i]);
}
}
//删除数据项
public DataItem delete(int key){
if(isEmpty()){
System.out.println("Hash Table is Empty!");
return null;
}
int hashVal = hashFunction(key);
while(hashArray[hashVal] !=null){
if(hashArray[hashVal].getKey() == key){
DataItem temp = hashArray[hashVal];
hashArray[hashVal] = nonItem;//nonItem表示空Item,其key为-1
itemNum--;
return temp;
}
++hashVal;
hashVal %= arraySize;
}
return null;
}
//查找数据项
public DataItem find(int key){
int hashVal = hashFunction(key);
while(hashArray[hashVal] !=null){
if(hashArray[hashVal].getKey() == key){
return hashArray[hashVal];
}
++hashVal;
hashVal %= arraySize;
}
return null;
}
public static class DataItem{
private int iData;
public DataItem(int iData){
this.iData = iData;
}
public int getKey(){
return iData;
}
}
}
再Hash
public class HashDouble {
private DataItem[] hashArray; //DataItem类,表示每个数据项信息
private int arraySize;//数组的初始大小
private int itemNum;//数组实际存储了多少项数据
private DataItem nonItem;//用于删除数据项
public HashDouble(){
this.arraySize =13;
hashArray =new DataItem[arraySize];
nonItem =new DataItem(-1);//删除的数据项下标为-1
}
//判断数组是否存储满了
public boolean isFull(){
return (itemNum == arraySize);
}
//判断数组是否为空
public boolean isEmpty(){
return (itemNum ==0);
}
//打印数组内容
public void display(){
System.out.println("Table:");
for(int j =0 ; j < arraySize ; j++){
if(hashArray[j] !=null){
System.out.print(hashArray[j].getKey() +" ");
}else{
System.out.print("** ");
}
}
}
//通过哈希函数转换得到数组下标
public int hashFunction1(int key){
return key%arraySize;
}
public int hashFunction2(int key){
return 5 - key%5;
}
//插入数据项
public void insert(DataItem item){
if(isFull()){
//扩展哈希表
System.out.println("哈希表已满,重新哈希化...");
extendHashTable();
}
int key = item.getKey();
int hashVal = hashFunction1(key);
int stepSize = hashFunction2(key);//用第二个哈希函数计算探测步数
while(hashArray[hashVal] !=null && hashArray[hashVal].getKey() != -1){
hashVal += stepSize;
hashVal %= arraySize;//以指定的步数向后探测
}
hashArray[hashVal] = item;
itemNum++;
}
/**
* 数组有固定的大小,而且不能扩展,所以扩展哈希表只能另外创建一个更大的数组,然后把旧数组中的数据插到新的数组中。
* 但是哈希表是根据数组大小计算给定数据的位置的,所以这些数据项不能再放在新数组中和老数组相同的位置上。
* 因此不能直接拷贝,需要按顺序遍历老数组,并使用insert方法向新数组中插入每个数据项。
* 这个过程叫做重新哈希化。这是一个耗时的过程,但如果数组要进行扩展,这个过程是必须的。
*/
public void extendHashTable(){
int num = arraySize;
itemNum =0;//重新计数,因为下面要把原来的数据转移到新的扩张的数组中
arraySize *=2;//数组大小翻倍
DataItem[] oldHashArray = hashArray;
hashArray =new DataItem[arraySize];
for(int i =0 ; i < num ; i++){
insert(oldHashArray[i]);
}
}
//删除数据项
public DataItem delete(int key){
if(isEmpty()){
System.out.println("Hash Table is Empty!");
return null;
}
int hashVal = hashFunction1(key);
int stepSize = hashFunction2(key);
while(hashArray[hashVal] !=null){
if(hashArray[hashVal].getKey() == key){
DataItem temp = hashArray[hashVal];
hashArray[hashVal] = nonItem;//nonItem表示空Item,其key为-1
itemNum--;
return temp;
}
hashVal += stepSize;
hashVal %= arraySize;
}
return null;
}
//查找数据项
public DataItem find(int key){
int hashVal = hashFunction1(key);
int stepSize = hashFunction2(key);
while(hashArray[hashVal] !=null){
if(hashArray[hashVal].getKey() == key){
return hashArray[hashVal];
}
hashVal += stepSize;
hashVal %= arraySize;
}
return null;
}
public static class DataItem{
private int iData;
public DataItem(int iData){
this.iData = iData;
}
public int getKey(){
return iData;
}
}
}
参考链接
https://www.cnblogs.com/ysocean/p/8032656.html
Hash冲突以及解决的更多相关文章
- hash 冲突及解决办法。
hash 冲突及解决办法. 关键字值不同的元素可能会映象到哈希表的同一地址上就会发生哈希冲突.解决办法: 1)开放定址法:当冲突发生时,使用某种探查(亦称探测)技术在散列表中形成一个探查(测)序列.沿 ...
- Hash冲突的解决--暴雪的Hash算法
Hash冲突的解决--暴雪的Hash算法https://usench.iteye.com/blog/2199399https://www.bbsmax.com/A/kPzOO7a8zx/
- Cuckoo Hash——Hash冲突的解决办法
参考文献: 1.Cuckoo Filter hash算法 2.cuckoo hash 用途: Cuckoo Hash(布谷鸟散列).问了解决哈希冲突的问题而提出,利用较少的计算换取较大的空间.占用空间 ...
- Hash冲突的解决方法
虽然我们不希望发生冲突,但实际上发生冲突的可能性仍是存在的.当关键字值域远大于哈希表的长度,而且事先并不知道关键字的具体取值时.冲突就难免会发 生.另外,当关键字的实际取值大于哈希表的长度时,而且表中 ...
- 关于hash冲突的解决
分离链接法:public class SeparateChainingHashTable<AnyType>{ private static final int DEFAULT_TABLE_ ...
- hash冲突解决和javahash冲突解决
其实就是四种方法的演变 1.开放定址法 具体就是把数据的标志等的对长度取模 有三种不同的取模 线性探测再散列 给数据的标志加增量,取模 平方探测再散列 给数据的标志平方,取模 随机探测再散列 把数据的 ...
- Map之HashMap的get与put流程,及hash冲突解决方式
在java中HashMap作为一种Map的实现,在程序中我们经常会用到,在此记录下其中get与put的执行过程,以及其hash冲突的解决方式: HashMap在存储数据的时候是key-value的键值 ...
- hash冲突随笔
一:hash表 也叫散列表,以key-value的形式存储数据,就是将需要存储的关键码值通过hash函数映射到表中的位置,可加快访问速度. 二:hash冲突 如果两个相同的关键码值通过hash函数映射 ...
- 链表法解决hash冲突
/* @链表法解决hash冲突 * 大单元数组,小单元链表 */ #pragma once #include <string> using namespace std; template& ...
随机推荐
- Java学习笔记:04面向对象-内部类_访问修饰符_final
04面向对象-内部类/访问修饰符/final 1.static的介绍 static:关键字,静态的 static的作用是用来修饰类中的成员 2.访问一个类中的某一个成员变量 方法一: _1.创建对象 ...
- 软件工程homework-003
软件工程第三次作业 博客信息 沈阳航空航天大学计算机学院2020软件工程作业 作业要求 软件工程第三次作业 课程目标 熟悉一个"高质量"软件的开发过程 作业目标 熟悉代码规范及结对 ...
- 关于dotnet动态生成controller的问题
一些动态生成controller的问题 前言 最近在写包, 一开始封装了仓储Repository用于操作数据库, 然后为了快速开发一些业务简单的接口, 通过QueryController , Modi ...
- python关于openpyxl的二次开发
from openpyxl import load_workbook class Excel_util: def __init__(self,path): self.path=path # 加载输入路 ...
- react核心?
虚拟DOM, Diff算法, 遍历key值 react-dom: 提供了针对DOM的方法,比如:把创建的虚拟DOM,渲染到页面上 或 配合ref来操作DOM react-router
- 为什么Java不支持运算符重载?
另一个类似棘手的Java问题.为什么 C++ 支持运算符重载而 Java 不支持? 有人可能会说+运算符在 Java 中已被重载用于字符串连接,不要被这些论据所欺骗.与 C++ 不同,Java 不支持 ...
- 指出在 spring aop 中 concern 和 cross-cutting concern 的不同之处?
concern 是我们想要在应用程序的特定模块中定义的行为.它可以定义为我们想 要实现的功能. cross-cutting concern 是一个适用于整个应用的行为,这会影响整个应用程序. 例如,日 ...
- 区分构造函数注入和 setter 注入?
构造函数注入 setter 注入 没有部分注入 有部分注入 不会覆盖 setter 属性 会覆盖 setter 属性 任意修改都会创建一个新实例 任意修改不会创建一个新实例 适用于设置很多属性 适用于 ...
- mybatis 和 hibernate 本质区别和应用场景
Hibernate: 是一个标准 ORM 框架(对象关系映射).入门门槛较高,不需要程序员写 SQL,SQL语句自动生成. 对 SQL 语句进行优化.修改比较困难. 应用场景: 适用于需求变化不多的中 ...
- 『忘了再学』Shell基础 — 6、Bash基本功能(输入输出重定向)
目录 1.Bash的标准输入输出 2.输出重定向 (1)标准输出重定向 (2)标准错误输出重定向 (3)正确输出和错误输出同时保存 3.输入重定向 1.Bash的标准输入输出 我们前边一直在说,在Li ...