NLP之基于Seq2Seq的单词翻译
Seq2Seq
1.理论
1.1 基本概念
在RNN模型需要解决的问题中,有一类M to N的问题,即输入输出不等长问题,例如机器翻译和生成概述。这种结构又叫做Seq2Seq模型,或者叫Encoder-Decoder模型。
1.2 模型结构
1.2.1 Encoder
Encoder可以直接用一个RNN网络,它的主要任务是把输入数据编码并输出一个上下文向量\(c\),可以直接用RNN的输出或最后一个隐状态向量\(h_t\)来得到\(c\)
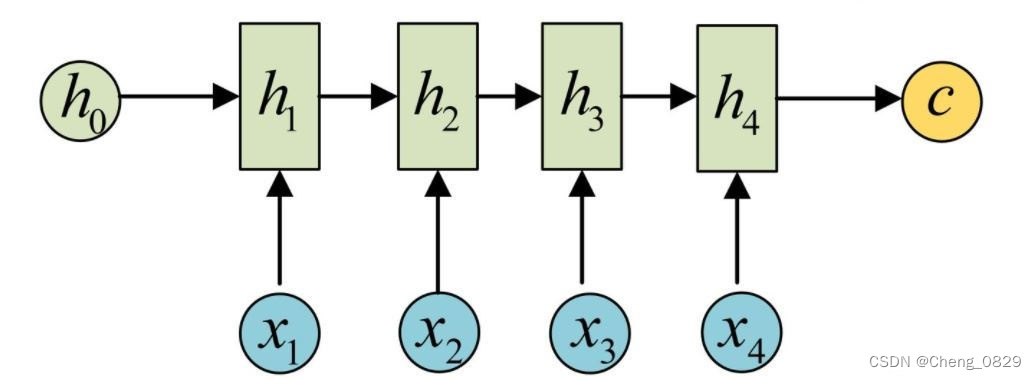
1.2.2 Decoder
Decoder也是一个RNN网络,它的主要任务是解码,把Encoder得到的上下文向量\(c\)作为其初始隐状态向量\(h_0\),再根据输入\(x\),得到输出结果
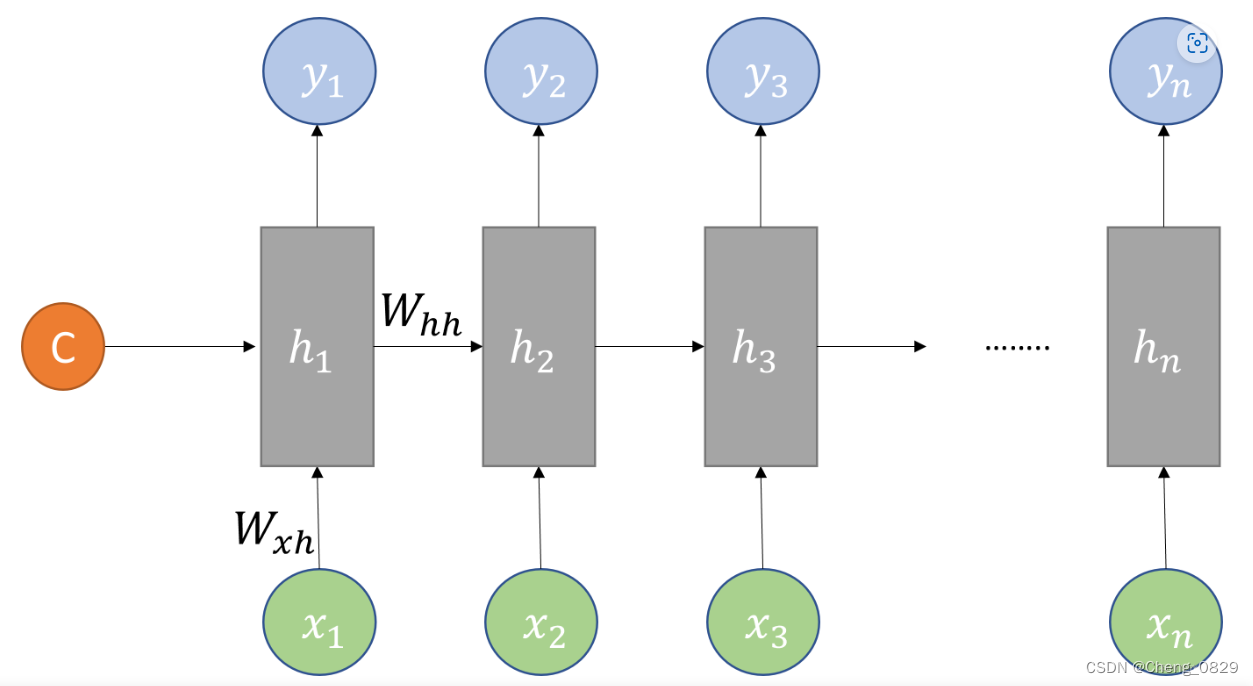
1.3 特殊字符
在序列模型的处理中,我们往往会在解码器的输入添加开始符\(S\),在输出添加结束符\(E\),同时用空白符\(P\)把所有词/句填充至相同长度
空白符: 填充至等长,便于统一操作;
开始符: 添加开始符是因为解码器Decoder的第一个时间步没有来自上一个解码器时间步的输入(虽然Decoder的第一个时间步有编码器Encoder的输出作为输入,但并不是来自解码器Decoder的),为了各个时间步处理的统一性,选择了一个可学习的特殊字符进行填充,这样的效果比单纯的空白字符更好;
结束符: 添加结束符是为了在预测单词时告诉模型终止输出.在训练集数据很多时,句子显然不可能都是等长的,翻译结果也应该不等长,为了控制翻译结果的长度,我们会在训练数据的target末尾加入结束符,这样翻译短句时,模型看见了结束符也就不会继续翻译了.(当然也可以不设置终止符,而设置一个最大输出长度,超过长度自动结束翻译输出)
开始符和结束符在训练时都被当做普通的一个单词或者字符进行训练,而他们的位置是固定的,开始符\(S\)只出现在解码器的输入,结束符\(E\)只出现在解码器的输出.当预测时,我们只在编码器Encoder中有输入,而解码器Decoder的输入就是'SPPP···'
2.实验
2.1 实验步骤
- 数据预处理,得到字典、样本数等基本数据
- 构建Seq2Seq模型,分别设置编解码器的输入
- 训练
- 代入数据,输入编码器,然后输入解码器
- 得到模型输出值,取其中最大值的索引,找到字典中对应的字母,即为模型预测的下一个字母.
- 把模型输出值和真实值相比,求得误差损失函数,运用Adam动量法梯度下降
- 测试
2.2 算法模型
"""
Task: 基于Seq2Seq的单词翻译
Author: ChengJunkai @github.com/Cheng0829
Email: chengjunkai829@gmail.com
Date: 2022/09/11
Reference: Tae Hwan Jung(Jeff Jung) @graykode
"""
import numpy as np
import torch, time, os, sys
import torch.nn as nn
# S: 表示开始进行解码输入的符号。
# E: 表示结束进行解码输出的符号。
# P: 当前批次数据大小小于时间步长时将填充空白序列的符号
'''1.数据预处理'''
def pre_process(seq_data):
chars = 'SEPabcdefghijklmnopqrstuvwxyz'
char_arr = [char for char in chars]
word_dict = {i:n for i,n in enumerate(char_arr)}
# 字符字典
num_dict = {n:i for i,n in enumerate(char_arr)}
# 字符种类
n_class = len(num_dict)
# 样本数
batch_size = len(seq_data)
return char_arr, word_dict, num_dict, n_class, batch_size
'''根据句子数据,构建词元的嵌入向量及目标词索引'''
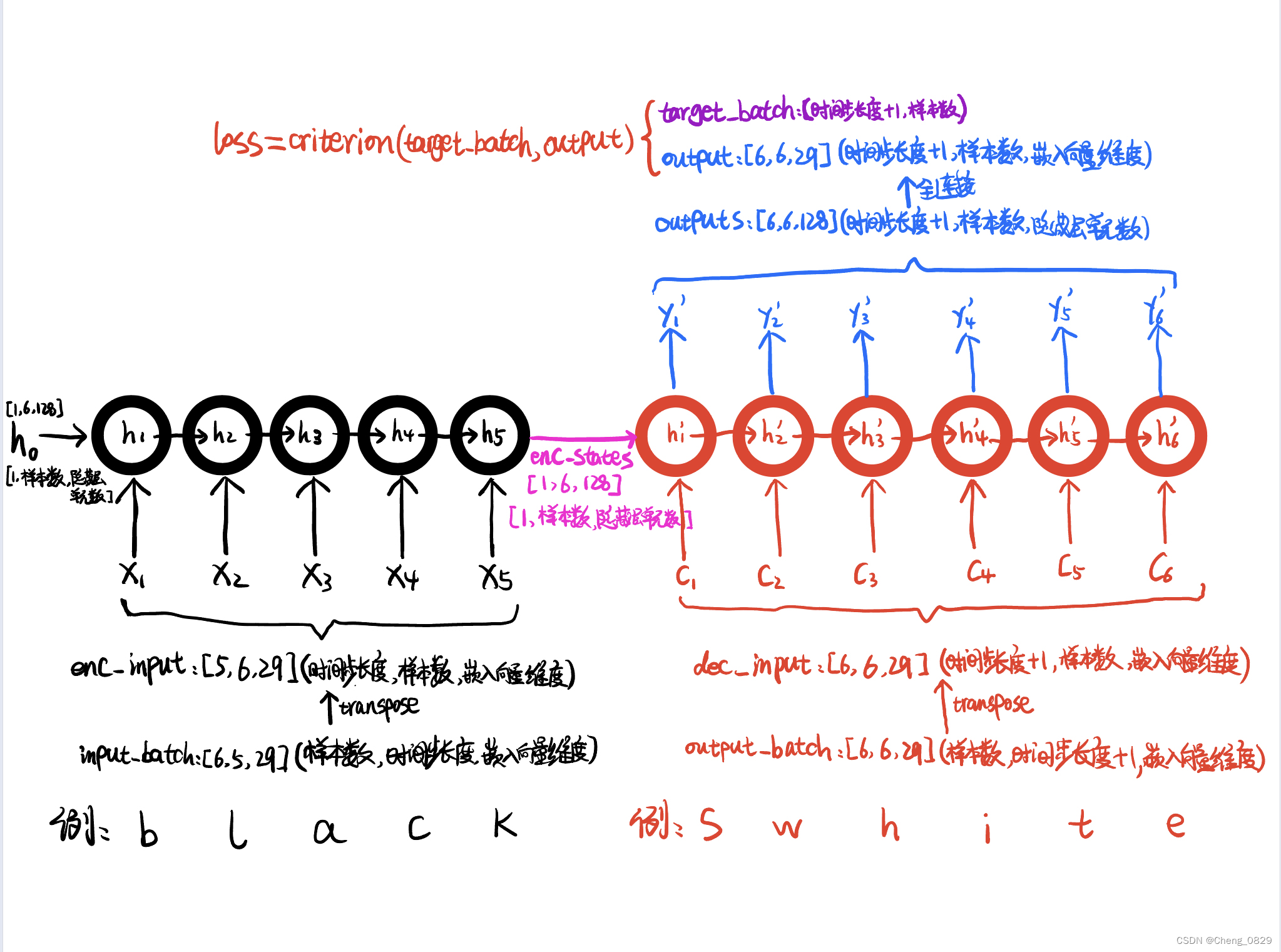
def make_batch(seq_data):
input_batch, output_batch, target_batch = [], [], []
for seq in seq_data:
for i in range(2):
# 把每个单词补充到时间步长度
seq[i] = seq[i] + 'P' * (n_step - len(seq[i]))
input = [num_dict[n] for n in seq[0]]
# output是decoder的输入,所以加上开始解码输入的符号
output = [num_dict[n] for n in ('S' + seq[1])]
# target是decoder的输出,所以加上开始解码输出的符号
target = [num_dict[n] for n in (seq[1] + 'E')]
input_batch.append(np.eye(n_class)[input])
output_batch.append(np.eye(n_class)[output])
target_batch.append(target) # not one-hot
'''input_batch用于编码器输入, output_batch用于解码器输入, target_batch用于比较计算误差'''
# [样本数,时间步长度,嵌入向量维度] -> [6,5,29]
input_batch = torch.FloatTensor(np.array(input_batch)).to(device)
# [样本数,时间步长度+1,嵌入向量维度] -> [6,6,29]
output_batch = torch.FloatTensor(np.array(output_batch)).to(device)
# [样本数,时间步长度+1] -> [6,6]
target_batch = torch.LongTensor (np.array(target_batch)).to(device)
return input_batch, output_batch, target_batch
'''2.构建模型'''
class Seq2Seq(nn.Module):
def __init__(self):
super().__init__()
self.encoder = nn.RNN(input_size=n_class, hidden_size=n_hidden, dropout=0.5)
self.decoder = nn.RNN(input_size=n_class, hidden_size=n_hidden, dropout=0.5)
self.fc = nn.Linear(n_hidden, n_class)
'''编码器5个时间步,解码器六个:一个时间步对应一个单词字母'''
def forward(self, encoder_input, encoder_hidden, decoder_input):
'''
encoder_input: input_batch
encoder_hidden: hidden
decoder_input: output_batch
'''
# encoder_input: [n_step, batch_size, n_class] -> [5,6,29]
encoder_input = encoder_input.transpose(0, 1)
# decoder_input: [n_step, batch_size, n_class] -> [6,6,29]
decoder_input = decoder_input.transpose(0, 1)
'''编码器输出作为解码器输入的hidden'''
# hidden最后只从一个单元里输出,所以第一维是1
# encoder_states : [num_layers(=1)*num_directions(=1), batch_size, n_hidden] # [1,6,128]
_, encoder_states = self.encoder(encoder_input, encoder_hidden)
encoder_states = encoder_states.to(device)
'''解码器输出'''
# outputs : [n_step+1(=6), batch_size, num_directions(=1)*n_hidden(=128)] # [6,6,128]
outputs, _ = self.decoder(decoder_input, encoder_states)
outputs = outputs.to(device)
'''全连接层'''
# output : [n_step+1(=6), batch_size, n_class]
output = self.fc(outputs) # [6,6,29]
return output
def translate(input_word):
input_batch, output_batch = [], []
# 把每个单词补充到时间步长度
input_word = input_word + 'P' * (n_step - len(input_word))
# 换成序号
input = [num_dict[n] for n in input_word] #
# 除了一个表示开始解码输入的符号,其余均为空白符号
output = [num_dict[n] for n in 'S'+'P'*n_step]
input_batch = np.eye(n_class)[input]
output_batch = np.eye(n_class)[output]
input_batch = torch.FloatTensor(np.array(input_batch)).unsqueeze(0).to(device)
output_batch = torch.FloatTensor(np.array(output_batch)).unsqueeze(0).to(device)
'''样本集为1'''
# hidden : [num_layers*num_directions, batch_size, n_hidden] [1,1,128]
hidden = torch.zeros(1, 1, n_hidden).to(device)
'''output : [n_step+1(=6), batch_size, n_class] [6,1,29]'''
output = model(input_batch, hidden, output_batch) # [6,1,29]
'''torch.tensor.data.max(dim,keepdim) 用于找概率最大的输出值及其索引
Args:
dim (int): 在哪一个维度求最大值
keepdim (Boolean): 保持维度.
keepdim=True:当tensor维度>1时,得到的索引和输出值仍然保持原来的维度
keepdim=False:当tensor维度>1时,得到的索引和输出值为1维
'''
'''dim=2:在第2维求最大值 [1]:只需要索引'''
predict = output.data.max(2, keepdim=True)[1] # select n_class dimension
'''由于predict中元素全为索引整数,所以即使有几个中括号,仍可以直接作为char_arr的索引'''
decoded = [char_arr[i] for i in predict] # ['m', 'e', 'n', 'P', 'P', 'E']
'''清除特殊字符'''
'''训练集的target均以E结尾,所以模型输出最后一个值也会是E'''
if 'E' in decoded:
end = decoded.index('E') # 5
decoded = decoded[:end] # 删除结束符及之后的所有字符
else:
return # 报错
while(True):
if 'P' in decoded:
del decoded[decoded.index('P')] # 删除空白符
else:
break
# 把列表元素合成字符串
translated = ''.join(decoded)
return translated
if __name__ == '__main__':
chars_print = '*' * 30
n_step = 5 # (样本单词均不大于5,所以n_step=5)
n_hidden = 128
device = ['cuda:0' if torch.cuda.is_available() else 'cpu'][0]
# 单词序列
seq_data = [['man', 'men'], ['black', 'white'], ['king', 'queen'], \
['girl', 'boy'], ['up', 'down'], ['high', 'low']]
'''1.数据预处理'''
char_arr, word_dict, num_dict, n_class, batch_size = pre_process(seq_data)
input_batch, output_batch, target_batch = make_batch(seq_data)
'''2.构建模型'''
model = Seq2Seq()
model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
if os.path.exists('model_param.pt') == True:
# 加载模型参数到模型结构
model.load_state_dict(torch.load('model_param.pt', map_location=device))
'''3.训练'''
print('{}\nTrain\n{}'.format('*'*30, '*'*30))
loss_record = []
for epoch in range(10000):
# make hidden shape [num_layers * num_directions, batch_size, n_hidden] [1,6,128]
hidden = torch.zeros(1, batch_size, n_hidden).to(device)
optimizer.zero_grad()
# input_batch : [样本数, 时间步长度, 嵌入向量维度]
# output_batch : [样本数, 时间步长度+1, 嵌入向量维度]
# target_batch : [样本数, 时间步长度+1]
output = model(input_batch, hidden, output_batch) # [6,6,29]
# output : [max_len+1, batch_size, n_class]
output = output.transpose(0, 1) # [batch_size, max_len+1(=6), n_class] [6,6,29]
'''
criterion的输入应该是output二维,target_batch一维,此实验不是这样,
一个单词样本分为几个字母,每个字母指定一个字母输出,因此target_batch是二维
所以要遍历相加.
'''
loss = 0
for i in range(0, len(target_batch)):
'''output: [6,6,29] target_batch:[6,6]'''
loss = loss + criterion(output[i], target_batch[i])
loss.backward()
optimizer.step()
if loss >= 0.0001: # 连续30轮loss小于0.01则提前结束训练
loss_record = []
else:
loss_record.append(loss.item())
if len(loss_record) == 30:
torch.save(model.state_dict(), 'model_param.pt')
break
if (epoch + 1) % 1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'Loss = {:.10f}'.format(loss))
torch.save(model.state_dict(), 'model_param.pt')
'''4.测试'''
print('{}\nTest\n{}'.format('*'*30, '*'*30))
test_words = ['man','men','king','black','upp']
for word in test_words:
print('%s ->'%word, translate(word))
NLP之基于Seq2Seq的单词翻译的更多相关文章
- NLP之基于Seq2Seq和注意力机制的句子翻译
Seq2Seq(Attention) @ 目录 Seq2Seq(Attention) 1.理论 1.1 机器翻译 1.1.1 模型输出结果处理 1.1.2 BLEU得分 1.2 注意力模型 1.2.1 ...
- NLP之基于Transformer的句子翻译
Transformer 目录 Transformer 1.理论 1.1 Model Structure 1.2 Multi-Head Attention & Scaled Dot-Produc ...
- 基于Seq2Seq和注意力机制的句子翻译
Seq2Seq(Attention) 目录 Seq2Seq(Attention) 1.理论 1.1 机器翻译 1.1.1 模型输出结果处理 1.1.2 BLEU得分 1.2 注意力模型 1.2.1 A ...
- python制作查找单词翻译的脚本
本人由于英语渣,在linux底下经常看文档,但是有没有想有道词典这种软件,所以遇到不懂的单词只能手动复制粘贴在网上查找,这样就很不方便,学了python之后,就试着自己尝试下个在命令行下查找单词翻译的 ...
- 制作属于自己的翻译软件(基于PyQt5+Python+实时翻译)
目录 制作属于自己的翻译软件(基于PyQt5+Python+实时翻译) 翻译软件上传到github上. 软件截图 主要的思想 界面方面 程序方面 制作属于自己的翻译软件(基于PyQt5+Python+ ...
- 基于PYQT5的截图翻译工具
基于PYQT5的截图翻译工具 功能介绍 翻译功能 截图功能(快捷键 + 截图存储到剪切板中) 文字识别OCR(基于百度API的文字识别) UI 界面 截图 截图可以使用第三方截图 或 使用PyQt5截 ...
- NLP之基于Bi-LSTM和注意力机制的文本情感分类
Bi-LSTM(Attention) @ 目录 Bi-LSTM(Attention) 1.理论 1.1 文本分类和预测(翻译) 1.2 注意力模型 1.2.1 Attention模型 1.2.2 Bi ...
- 【NLP】基于自然语言处理角度谈谈CRF(二)
基于自然语言处理角度谈谈CRF 作者:白宁超 2016年8月2日21:25:35 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务 ...
- 【NLP】基于机器学习角度谈谈CRF(三)
基于机器学习角度谈谈CRF 作者:白宁超 2016年8月3日08:39:14 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务中都 ...
随机推荐
- WPF 实现带蒙版的 MessageBox 消息提示框
WPF 实现带蒙版的 MessageBox 消息提示框 WPF 实现带蒙版的 MessageBox 消息提示框 作者:WPFDevelopersOrg 原文链接: https://github.com ...
- Docker 13 Dockerfile
参考源 https://www.bilibili.com/video/BV1og4y1q7M4?spm_id_from=333.999.0.0 https://www.bilibili.com/vid ...
- openstack 安装neutron网络服务安装 报错:Unknown operation 'enabled'
注:这个脚本文件有一个地方是错误的,最后一行需要修改一下 # vim /usr/local/bin/iass-install-neutron-controller-gre.sh # 改systemc ...
- Redis进阶篇:发布订阅模式原理与运用
"65 哥,如果你交了个漂亮小姐姐做女朋友,你会通过什么方式将这个消息广而告之给你的微信好友?" "那不得拍点女朋友的美照 + 亲密照弄一个九宫格图文消息在朋友圈发布大肆 ...
- 【java】学习路径45-多线程-线程生命周期
线程分为五大状态:新建.就绪.运行.阻塞.死亡. New,Runnable,Running,Blocked,Terminated. 新建状态(New: 创建好一个系统对象,在调用start()之前,线 ...
- 部署nfs
NFS可以让服务端跟客户端通过网络共享主机磁盘上的一些数据,主要是在unix和linux系统上实现的一种文件共享方式. 我们可以简单的将NFS看做是一个文件服务器 (file server) ...
- metasploit进行局域网远控
用metasploit进行局域网远程控制 Metasploit是一款开源的安全漏洞检测工具,可以帮助安全和IT专业人士识别安全性问题,验证漏洞的缓解措施,并管理专家驱动的安全性进行评估,提供真正的安全 ...
- Html飞机大战(八):子弹的移动和管理
好家伙,这应该是这个小游戏最难的几个点之一了 现在我们要做出子弹射击的效果我们应该如何处理? 1.首先我们要确定几个变量和方法的关系 变量: 子弹 bullet 弹夹(用来装子弹的东西)bulle ...
- Python入门系列(九)pip、try except、用户输入、字符串格式
pip 包含模块所需的所有文件. 检查是否安装了PIP $ pip --version 安装包 $ pip install package_name 使用包 import package_name 删 ...
- Python数据科学手册-机器学习: 支持向量机
support vector machine SVM 是非常强大. 灵活的有监督学习算法, 可以用于分类和回归. 贝叶斯分类器,对每个类进行了随机分布的假设,用生成的模型估计 新数据点 的标签.是属于 ...