pandas-数据结构转换-纵转横
如下代码,亲测有效,后面会附上入口以及出口数据结构截图
def test_func(file_path):
"""
把pandas数据结构-dataframe,横向的索引,转成纵向的
:return:
"""
pd_obj = pandas.read_excel(file_path, engine="openpyxl")
groupby_df = pd_obj.groupby(["任务状态", "团队名称"]).agg(
{"团队名称": "count"}
)
# 拿到分组后,第一层数据,团队名称字典下面的value
sys_team = groupby_df.get("团队名称")
# 二次分组,拿到每个任务状态下的所有团队名称数据
sys_team_type_df = sys_team.groupby("任务状态")
li = []
for name, group_ in sys_team_type_df:
# 拿到每个分组的数据,每个分组就是每个任务状态下的所有团队名称数据
each_group_dic = {"team": [], }
# 拿到每个分组的索引list,每个list里面是一个个tuple,
# 每个tuple---('In Review', 'A团队')
each_group_index_li = group_.index
type_li = []
for each_index_row in each_group_index_li:
# 拿到每个tuple中,任务状态值以及团队名称值
current_team_value = each_index_row[-1]
current_type_value = each_index_row[0]
# 把每个group里面的团队名称,按照顺序,添加到字典的team里面
each_group_dic["team"].append(current_team_value)
# 把每个分组中的具体count值,提取出来,根据二维索引提取,
# 二维索引就是任务状态索引和团队名称索引
type_team_matched_value = group_.loc[current_type_value, current_team_value]
# 把每个分组中提取出来的具体的count值,存入一个type-list
type_li.append(type_team_matched_value)
# 把type-list,作为一组键值对:key是团队名称,value是该团队对应的count值,
# update到上面构件的each_group_dic字典中,
each_group_dic.update({current_type_value: type_li})
# 把构件完成的each_group_dic字典,转成dataframe数据结构
each_group_df = pandas.DataFrame(each_group_dic)
# 把每个分组构件完成的dataframe,存入一个list中
li.append(each_group_df)
# 最后把最外层的list里面的所有dataframe拼接起来,得到转换成功的数据结构
merge_test_df = reduce(
lambda left, right: pandas.merge(left, right, on="team", how="outer"),
li)
# 把dataframe的空值都填充为0
df_ = merge_test_df.fillna(0)
# 拿到所有应该要转换成数字的列名
integer_cols = merge_test_df.columns[1:]
for each_col in integer_cols:
# 把所有float类型的列,都转换成数字
df_[each_col] = pandas.to_numeric(df_[each_col], downcast='integer')
return df_
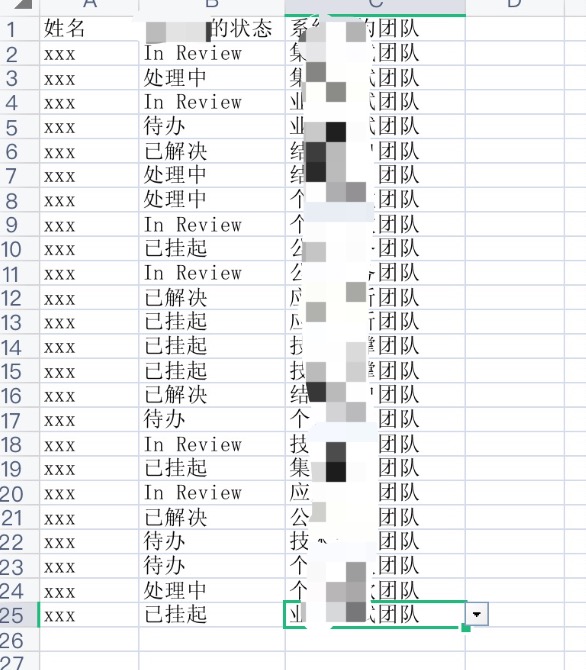
输入的文件结构如下截图:
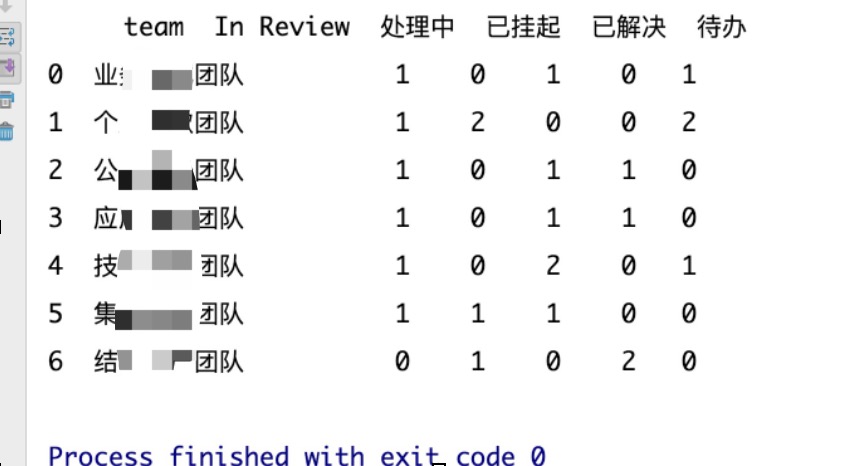
输出的结构截图:
pandas-数据结构转换-纵转横的更多相关文章
- pandas教程1:pandas数据结构入门
pandas是一个用于进行python科学计算的常用库,包含高级的数据结构和精巧的工具,使得在Python中处理数据非常快速和简单.pandas建造在NumPy之上,它使得以NumPy为中心的应用很容 ...
- Pandas数据结构
Pandas处理以下三个数据结构 - 系列(Series) 数据帧(DataFrame) 面板(Panel) 这些数据结构构建在Numpy数组之上,这意味着它们很快. 维数和描述 考虑这些数据结构的最 ...
- python之pandas学习笔记-pandas数据结构
pandas数据结构 pandas处理3种数据结构,它们建立在numpy数组之上,所以运行速度很快: 1.系列(Series) 2.数据帧(DataFrame) 3.面板(Panel) 关系: 数据结 ...
- typescript 深层次对象内层(N)转外层(N),支持多层级递归转换,多应用于多语言数据结构转换
如下数据结构转换 var a = { b: { en: 1, zh: 2, }, c: { en: 3, zh: 4, }, } //===> var b = { en: { b: 1, c: ...
- 读书笔记一、pandas数据结构介绍
pandas数据结构介绍 主要两种数据结构:Series和DataFrame. Series Series是一种类似于一维数组的对象,由一组数据(各种NumPy数据类型)+数据标签(即索引)组 ...
- 初探pandas——安装和了解pandas数据结构
安装pandas 通过python pip安装pandas pip install pandas pandas数据结构 pandas常用数据结构包括:Series和DataFrame Series S ...
- 03. Pandas数据结构
03. Pandas数据结构 Series DataFrame 从DataFrame中查询出Series 1. Series Series是一种类似于一维数组的对象,它由一组数据(不同数据类型)以及一 ...
- pandas 数据结构基础与转换
pandas 最常用的三种基本数据结构: 1.dataFrame: https://pandas.pydata.org/pandas-docs/stable/generated/pandas.Data ...
- pandas.DataFrame.astype数据结构转换
网易云课堂该课程链接地址 https://study.163.com/course/courseMain.htm?share=2&shareId=400000000398149&cou ...
- pandas 学习(2): pandas 数据结构之DataFrame
DataFrame 类型类似于数据库表结构的数据结构,其含有行索引和列索引,可以将DataFrame 想成是由相同索引的Series组成的Dict类型.在其底层是通过二维以及一维的数据块实现. 1. ...
随机推荐
- antDesign 【NG-ZORRO、Angular】日期选择框时间段nz-range-picker设置默认选择日期及限制日期可选范围
下面的代码包含 1.只可以选择今天以后 2.只可以选择今天开始一周内 3.只能选择今天之前的 import { Component } from '@angular/core'; import dif ...
- Backbone前端框架解读
作者: 京东零售 陈震 一. 什么是Backbone 在前端的发展道路中,前端框架元老之一jQuery对繁琐的DOM操作进行了封装,提供了链式调用.各类选择器,屏蔽了不同浏览器写法的差异性,但是前端开 ...
- FAQ 关于pip你应该知道的一些技巧
pip简介 pip是安装了python之后的一个应用程序,包管理程序,有点类似于yum.npm.apt等工具 物理位置一般是python.exe所在目录下的scripts下 以我为例,我Python安 ...
- Java-Integer好大一坑,一不小心就掉进去了
遛马少年,一个代码写的很6的程序员,专注于技术干货分享 最近,在处理线上bug的时候,发现了一个奇怪的现象 业务代码大概是这样的 public static boolean doSth(Integer ...
- Nginx09 http的keepalive及在nginx的配置使用
1 为什么要有Connection: keep-alive? 在早期的HTTP/1.0中,每次http请求都要创建一个连接,而创建连接的过程需要消耗资源和时间,为了减少资源消耗,缩短响应时间,就需要重 ...
- CMakeList汇总
cmake_minimum_required(VERSION 2.8.3) PROJECT (HELLO) #工程名 set(CMAKE_BUILD_TYPE "Debug")se ...
- Spring(认识、IOC的开发过程、创建bean的方式)
spring框架(spring全家桶) spring FrameWork springBoot+springCloud+springCloud Data Flow 一:spring的两大核心机制: I ...
- [java安全基础 03]CC1
Commons-Collerctions链条 Apache Commons-Collections简介 Apache Commons Collections是一个扩展了Java标准库里的Collect ...
- 云小课|MRS数据分析-通过Spark Streaming作业消费Kafka数据
阅识风云是华为云信息大咖,擅长将复杂信息多元化呈现,其出品的一张图(云图说).深入浅出的博文(云小课)或短视频(云视厅)总有一款能让您快速上手华为云.更多精彩内容请单击此处. 摘要:Spark Str ...
- HTML5基本网页结构以及标签的改变
转载csdn:https://blog.csdn.net/z983002710/article/details/76300327