python字符编码与文件操作
字符编码
字符编码是什么
人与计算机交互时,使用的都是人类能够读懂的语言,而计算机只能理解0和1两个数字的组合,字符编码就是相当于将人类能够理解的语言翻译成计算机能够理解的数字。

字符编码的发展史
字符编码大概可以分为三个阶段。
阶段一:一家独大
计算机是由美国人,所以一开始只有他们的字符编码,只记录了英文字符和数字的对应关系,也就是ASCII码,用1bytes来表示一个英文字符。
记忆点:ASCII码中A-Z对应65-90,a-z对应97-122
阶段二:群雄割据
计算机传到其他国家后,其他国家使用计算机时发现ASCII对于有些语言来说不好使,于是各个国家发明了各自的字符编码。
中国发明的是GBK编码,用1bytes存储英文,2bytes存储中文。
阶段三:天下一统
由于各个国家各自的字符编码不同,不同国家之间在传输信息的时候就会出现乱码的情况,于是就发明了万国码(Unicode),但是它所有的字符都是2bytes起步存储,会浪费空间和输入输出时间。

字符编码实际应用
编码与解码
编码(encode)
将人类能够读懂的字符翻译成计算机能够读懂的字符
# 编码
print('我是帅比'.encode('gbk'))
# 输出结果:b'\xce\xd2\xca\xc7\xcb\xa7\xb1\xc8'
解码(decode)
将计算机能够读懂的字符翻译成人类能够读懂的字符
# 编码
res = '我是帅比'.encode('gbk')
# 解码
print(res.decode('gbk'))
# 输出结果:我是帅比
乱码问题
当一组数据用不同的字符编码进行编码解码时,就会出现乱码的情况。
# 编码
res = '我是帅比'.encode('utf8')
# 解码
print(res.decode('gbk'))
# 输出结果:鎴戞槸甯呮瘮
为了防止乱码的情况,我要用什么进行编码时就要用什么来进行解码。
python解释器层面
python2解释器默认的编码是ASCII码,所以为了python解释器可以识别中文和其他语言,我们在使用python2时一般会进行2个操作。
在代码的最上方添加一段注释
# coding:utf8
或者
# -*- coding:utf8 -*-
在定义字符串时习惯在前面加u
name = u'张三'
文件操作
文件操作简介
文件
文件是操作系统暴露给用户可以直接操作硬盘的快捷方式。
用代码进行文件操作的流程
用代码进行文件操作有四个步骤:
- 打开文件或是创建文件
- 编辑文件内容
- 保存文件内容
- 关闭文件
基本语法结构
# 用python操作文件有2中语法
# 第一种(不推荐)
f1 = open(文件路径,模式,编码类型)
f1 = close()
# 第二种(推荐),f是变量名
with open(文件路径,模式,编码类型) as f:
pass
"""
使用第一种是需要手动写关闭文件的代码
而第二种方法会在运行完子代码后自动关闭文件
"""
补充
在填写路径的时候我们会用到反斜杠符号,为了防止转义,我们会在路径前面加上一个英文字母r
文件的内置方法
数据类型有它的内置方法,文件当然也有。
read() # 一次性读取文件的全部内容 ps:文件过大易内存溢出
readline() # 一次只读一行内容
readlines() # 将文件一行行的内容存储到列表中
readable() # 判断文件是否可读
write() # 将内容写到文件中
writelines() # 将列表中的多个元素写到文件中
writable() # 判断文件是否可写
flush() # 将文件保存一下
补充:文件还支持for循环,可以一行行读取内容,内存中同一时刻只会有一行内容,有效防止内存溢出。
文件的读写模式
python对于文本的操作模式有三种:只读模式(r)、只写模式(w)、只追加模式(a)。
- 只读模式(r模式)
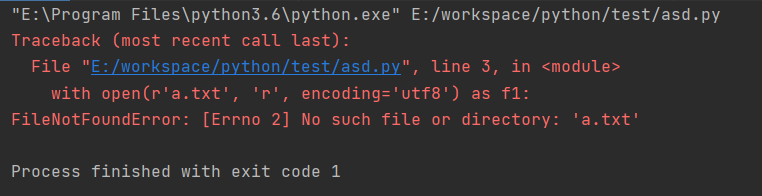
# 路径不存在时,会直接报错
with open(r'a.txt', 'r', encoding='utf8') as f1:
pass
# 路径存在时,正常打开文件并等待内容读取
with open(r'a.txt', 'r', encoding='utf8') as f1:
pass
# 注意:r模式只能读取,不能写入,不然会报错
- 只写模式(w模式)
# 路径不存在时,会自动创建文件
with open(r'a.txt', 'w', encoding='utf8') as f1:
pass
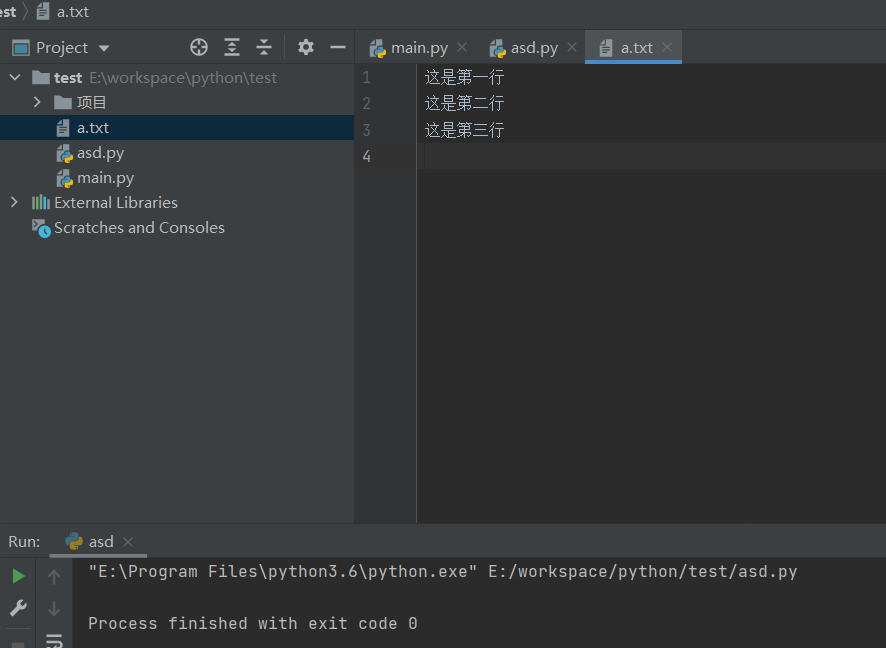
# 路径存在时,会先清空文件内容,之后在写入数据
with open(r'a.txt', 'w', encoding='utf8') as f1:
f1.write('这是第一行\n')
f1.write('这是第二行\n')
f1.write('这是第三行\n')
- 只追加模式(a模式)
# 只追加模式和只写模式基本一致
# 唯一的区别就是文件存在时它不会清空数据在添加内容,而是会在内容末尾添加内容
with open(r'a.txt', 'a', encoding='utf8') as f1:
f1.write('这是追加内容')
文件的操作模式
文件的操作模式有两种t模式和b模式。
t模式是默认的模式,在读写模式中,它的t被省略了,完整的写的话应该是'rt'、'wt'、'at'。
注意事项:
- 只能操作文本文件
- 必须指定encoding参数
- 该模式读写都是以字符串为最小单位
b模式也称二进制模式,是可以操作任意类型的文件的。
注意事项:
- 不需要指定encoding参数
- 可以操作任意类型的文件
- 该模式读写都是以bytes类型为最小单位
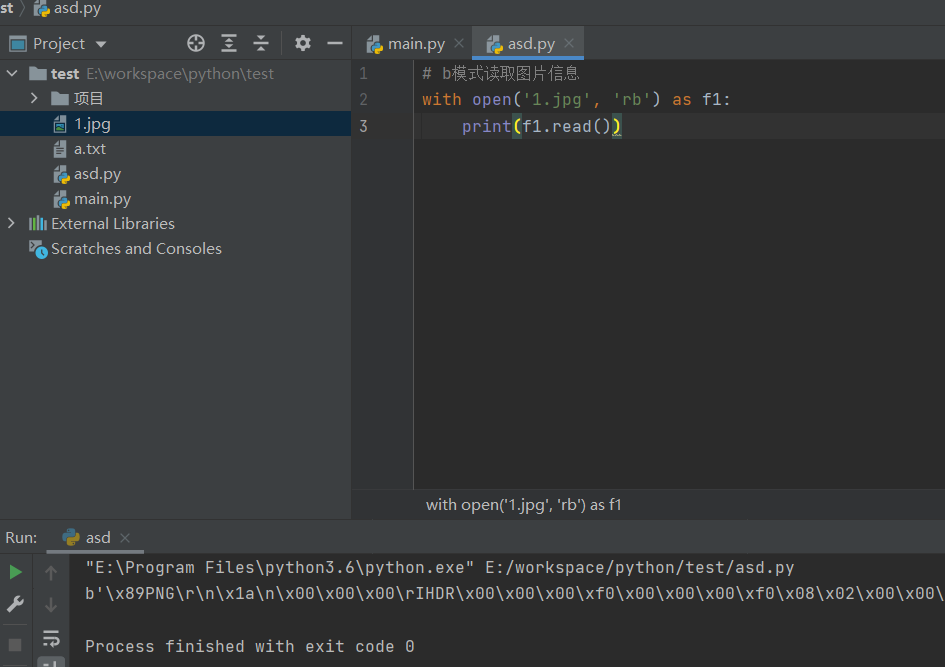
# b模式读取图片信息
with open('1.jpg', 'rb') as f1:
print(f1.read())
作业
- 编写一个简易版本的拷贝程序,路径全部自定义
- 结合文件编写用户注册登录功能,提前先创建一个空的userinfo.txt,用户注册数据保存到文件中,用户登录 数据来源于文件
- 必要要求
单用户注册登录 - 拔高练习
多用户注册登录
- 必要要求
答案
第一题:
点击查看代码
file_from = input("请输入你要复制的文件路径:")
file_to = input("请输入你要粘贴的文件路径:")
# 将文件数据读取出来
with open(file_from, 'rb') as ff:
data = ff.read()
# 创建文件并写入
with open(file_to, 'wb') as ft:
ft.write(data)
第二题
点击查看代码
while True:
# 注册功能实现
while True:
print('是否注册?(y/n)')
cmd = input()
if cmd == 'n':
break
register_username = input("请输入注册的用户名:").strip()
register_password = input("请输入注册的密码:").strip()
# 将注册信息存储到当前路径的文本文件中
with open('userinfo.txt', 'a', encoding='utf8') as ff:
ff.write(register_username + '|' + register_password + ',')
# 登录功能实现
while True:
username = input("请输入用户名:").strip()
password = input("请输入密码:").strip()
# 获取文本中的内容并将每个用户信息分隔开以列表存储
with open('userinfo.txt', 'r', encoding='utf8') as ff:
login_msg_list = ff.read().split(',')
# 判断用户名和密码
for login_msg in login_msg_list:
if login_msg.split('|')[0] == username:
if login_msg.split('|')[1] == password:
print('登录成功!!')
break
else:
print('用户名或密码错误!!')
break
else:
print('用户名不存在!!')
python字符编码与文件操作的更多相关文章
- Python 字符编码及其文件操作
本章节内容导航: 1.字符编码:人识别的语言与机器机器识别的语言转化的媒介. 2.字符与字节:字符占多少个字节,字符串转化 3.文件操作:操作硬盘中的一块区域:读写操作 注:浅拷贝与深拷贝 用法: d ...
- Python之字符编码与文件操作
目录 字符编码 Python2和Python3中字符串类型的差别 文件操作 文件操作的方式 文件内光标的移动 文件修改 字符编码 什么是字符编码? ''' 字符编码就是制定的一个将人类的语言的字符与二 ...
- Python 入门基础6 --字符编码、文件操作1
今日内容: 1.字符编码 2.字符与字节 3.文件操作 一.字符编码 了解: cpu:将数据渲染给用户 内存:临时存放数据,断电消失 硬盘:永久存放数据,断电后不消失 1.1 什么是编码? 人类能够识 ...
- Python-字典、集合、字符编码、文件操作整理-Day3
1.字典 1.1.为什么有字典: 有个需求,存所有人的信息 这时候列表就不能轻易的表示完全names = ['stone','liang'] 1.2.元组: 定义符号()t = (1,2,3)tupl ...
- python学习道路(day3note)(元组,字典 ,集合,字符编码,文件操作)
1.元组()元组跟列表一样,但是不能增删改,能查.元组又叫只读列表2个方法 一个 count 一个 index2.字典{}字典是通过key来寻找value因为这里功能比较多,所以写入了一个Code里面 ...
- Python全栈开发之路 【第三篇】:Python基础之字符编码和文件操作
本节内容 一.三元运算 三元运算又称三目运算,是对简单的条件语句的简写,如: 简单条件语句: if 条件成立: val = 1 else: val = 2 改成三元运算: val = 1 if 条件成 ...
- Python基础之字符编码,文件操作流与函数
一.字符编码 1.字符编码的发展史 阶段一:现代计算机起源于美国,最早诞生也是基于英文考虑的ASCII ASCII:一个Bytes代表一个字符(英文字符/键盘上的所有其他字符),1Bytes=8bit ...
- python基础——6(字符编码,文件操作)
今日内容: 1.字符编码: 人识别的语言与机器识别的语言转化的媒介 ***** 2.字符与字节: 字符占多少字节,字符串转化 *** 3.文件操作: 操作硬盘中的一块区域:读写操作 ...
- python基础--字符编码以及文件操作
字符编码: 1.运行程序的三个核心硬件:cpu.内存.硬盘 任何一个程序要是想要运算,肯定是先从硬盘加载到当前的内存中,然后cpu根据指定的指令去执行操作 2.python解释器运行一个py文件的步骤 ...
随机推荐
- html5知识点补充—mark元素的使用
使用mark元素高亮文本 利用mark元素,文档作者可以高亮显示文档中的某些文本以达到醒目的效果. 如果用户在站点进行搜索,搜索页面中的关键字可以高亮显示.这时,就可以很好的利用到mark元素.不选用 ...
- 根据地理信息绘画的html5 小游戏 - 简单实现
好久没写文章了,之前一直有一个想法,就是做一个根据用户行走的路线,获取地理位置,然后把它们绘制出来,最后产生的效果,类似蜗牛行走留下的痕迹. 最近思考了一下,搭了一个https,简单实现了一下,提供一 ...
- ubantu14.04系统设置无法正常使用
方法一:执行命令: sudo apt-get install ubuntu-desktop方法二:如果系统设置打不开,请重新安装gnome-control-centersudo apt-get ins ...
- eclipse/myeclipse注释模板的修改
本文转自:http://kaminlee.iteye.com/blog/1101938 Window --> Java --> Code Style --> Code Templat ...
- Ncrystal Skill设计
在使用allegro时一般都会听说过skill,使用合适的Skill会使事情事半功倍.但是现阶段所能看到的个人白嫖的Skill都有一些通病.所以我才开发符合自己操作习惯的Skill. 当前我们所能找的 ...
- SSM实现个人博客-day04
项目源码免费下载:SSM实现个人博客 有问题询问vx:kht808 3.项目搭建(SSM整合) (1)创建maven工程,导入相应的依赖 <properties> <project. ...
- SpringCloud Function SpEL注入
SpringCloud Function SpEL注入 漏洞分析
- 7.Docker容器使用辅助工具汇总
原文地址: 点击直达 more information: https://docs.docker.com/engine/security/security/#docker-daemon-attack- ...
- 【深入理解TcaplusDB技术】扫描数据接口说明——[List表]
摘要 实现扫描指定表格中的数据. 示例代码 同步调用参见章节:[List表]扫描数据示例代码. 异步调用参见章节:[List表]异步扫描数据示例代码. Client对象方法说明 注:如有未列出来的Cl ...
- 面试突击41:notify是随机唤醒吗?
做 Java 开发的小伙伴,对 wait 方法和 notify 方法应该都比较熟悉,这两个方法在线程通讯中使用的频率非常高,但对于 notify 方法的唤醒顺序,有很多小伙伴的理解都是错误的,有很多人 ...