LRU 缓存
力扣题目 146. LRU 缓存
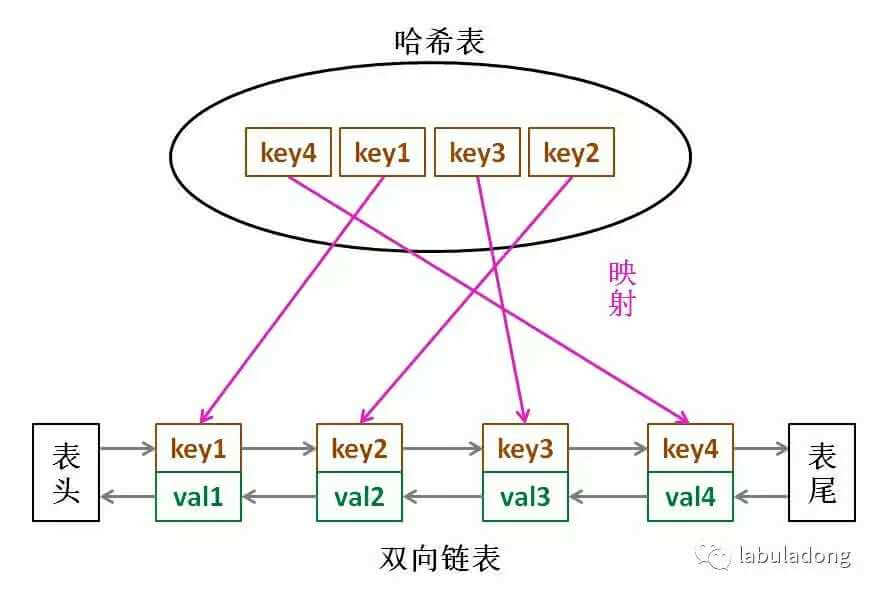
实现 LRU 缓存需要用到哈希链表 LinkedHashMap。
LinkedHashMap 是由哈希表和双链表结合而成的,它的结构如下所示。
用自带的 LinkedHashMap 实现
利用 Java 语言自带的 LinkedHashMap 很容易实现 LRU 缓存。
class LRUCache {
// 缓存容量
int cap;
// 哈希链表
LinkedHashMap<Integer, Integer> cache = new LinkedHashMap<>();
// 初始化
public LRUCache(int capacity) {
this.cap = capacity;
}
public int get(int key) {
// 如果不存在这个 key, 返回 -1
if(!cache.containsKey(key)){
return -1;
}
// 存在这个 key
// 将该元素提升为最近使用过的
makeRecently(key);
return cache.get(key);
}
public void put(int key, int value) {
// 已经存在这个 key
if(cache.containsKey(key)){
// 修改 value 值
cache.put(key, value);
// 将该元素提升为最近使用过的
makeRecently(key);
return;
}
// 不存在这个 key
// 如果容量满了
if(cache.size() == cap){
// 删除链表头第一个元素(最不常使用的)
int oldKey = cache.keySet().iterator().next();
cache.remove(oldKey);
}
// 插入新元素
cache.put(key, value);
}
// 将该元素提升为最近使用过的
private void makeRecently(int key){
int value = cache.get(key);
// 删除该元素
cache.remove(key);
// 新增该元素
cache.put(key, value);
}
}
由于该题是面试高频考点,而面试官希望面试者能自己实现哈希链表,因此下面自己实现一下。
自己实现哈希链表
实现 MyLinkedHashMap
考虑写一个 MyLinkedHashMap 代替 LinkedHashMap。
下面是用 MyLinkedHashMap 代替 LinkedHashMap 的代码,为简化起见,不考虑泛型了,初始化就变成了 MyLinkedHashMap cache = new MyLinkedHashMap<>();
大部分 LinkedHashMap 的方法都保留了,将删除双链表的首元素封装成一个新方法 cache.removeEldest();
class LRUCache {
// 缓存容量
int cap;
// 哈希链表
MyLinkedHashMap cache = new MyLinkedHashMap();
public LRUCache(int capacity) {
this.cap = capacity;
}
public int get(int key) {
// 如果不存在这个 key, 返回 -1
if(!cache.containsKey(key)){
return -1;
}
// 存在这个 key
// 将该元素提升为最近使用过的
makeRecently(key);
return cache.get(key);
}
public void put(int key, int value) {
// 已经存在这个 key
if(cache.containsKey(key)){
// 修改 value 值
cache.put(key, value);
// 将该元素提升为最近使用过的
makeRecently(key);
return;
}
// 不存在这个 key
// 如果容量满了
if(cache.size() == cap){
// 删除链表头第一个元素(最不常使用的)
cache.removeEldest();
}
// 插入新元素
cache.put(key, value);
}
// 将该元素提升为最近使用过的
private void makeRecently(int key){
int value = cache.get(key);
// 删除该元素
cache.remove(key);
// 新增该元素
cache.put(key, value);
}
}
因此我们要实现 MyLinkedHashMap 的以下方法
class MyLinkedHashMap {
// 获取 key 对应的 value
public int get(int key) {}
// 新增一对 key, value 或修改 key 对应的 value
public void put(int key, int value) {}
// 删除 value 对应的元素
public void remove(int key) {}
// 删除链表首元素(也就是最近不被使用的元素)
public void removeEldest() {}
// 返回是否存在该 key
public boolean containsKey(int key) {}
// 返回当前容量
public int size() {}
}
MyLinkedHashMap 是有哈希表和双链表结合而成的,类中自然有这两个数据结构。
class MyLinkedHashMap {
// 哈希表
HashMap<Integer, Node> map = new HashMap<>();
// 双链表
DoubleList doubleList = new DoubleList();
}
下面一一实现上述方法
get 方法
由于 LRUCache 中调用 get 方法时已经考虑了 key 不存在的情况,调用 MyLinkedHashMap 中的 get 方法时 key 一定时存在的,因此就不用考虑 key 不存在的情况了。
// 获取 key 对应的 value
public int get(int key) {
return map.get(key).value;
}
put方法
由于 LRUCache 中调用 put 方法时可以新增,也可以修改,因此要在 MyLinkedHashMap 中的 put 方法考虑这两种情况
新增和删除要在哈希表和双链表中同时操作,保持一致性
// 新增一对 key, value 或修改 key 对应的 value
public void put(int key, int value) {
// 已经存在该 key, 修改
if(containsKey(key)) {
map.get(key).value = value;
return;
}
// 不存在该 key, 新增
Node node = new Node(key, value);
doubleList.addLast(node);
map.put(key, node);
}
remove 方法
// 删除 value 对应的元素
public void remove(int key) {
Node node = map.get(key);
doubleList.remove(node);
map.remove(key);
}
removeEldest 方法
这个方法也体现了为什么双链表中的节点应该同时保存 key 和 value ,因为需要删除双链表的首元素,还要删除 map 中对应的 key,因此要返回被删除的首元素节点,从首元素节点中获取 key。
// 删除链表首元素(也就是最近不被使用的元素)
public void removeEldest() {
Node node = doubleList.removeFirst();
map.remove(node.key);
}
containsKey 方法
直接调用 map 的 containsKey() 方法。
// 返回是否存在该 key
public boolean containsKey(int key) {
return map.containsKey(key);
}
size 方法
直接调用 map 的 size 方法。
// 返回当前容量
public int size() {
return map.size();
}
这样,MyLinkedHashMap 就写完了,该类的完整代码如下
class MyLinkedHashMap {
// 哈希表
HashMap<Integer, Node> map = new HashMap<>();
// 双链表
DoubleList doubleList = new DoubleList();
// 获取 key 对应的 value
public int get(int key) {
return map.get(key).value;
}
// 新增一对 key, value 或修改 key 对应的 value
public void put(int key, int value) {
// 已经存在该 key, 修改
if(containsKey(key)) {
map.get(key).value = value;
return;
}
// 不存在该 key, 新增
Node node = new Node(key, value);
doubleList.addLast(node);
map.put(key, node);
}
// 删除 value 对应的元素
public void remove(int key) {
Node node = map.get(key);
doubleList.remove(node);
map.remove(key);
}
// 删除链表首元素(也就是最近不被使用的元素)
public void removeEldest() {
Node node = doubleList.removeFirst();
map.remove(node.key);
}
// 返回是否存在该 key
public boolean containsKey(int key) {
return map.containsKey(key);
}
// 返回当前容量
public int size() {
return map.size();
}
}
实现双链表
由于 MyLinkedHashMap 中 map 是调用 java 现成的,而 DoubleList 不是 java 现成的,因此需要自己实现 DoubleList
DoubleList 的基本结构如下
class DoubleList {
// 虚拟头节点、虚拟尾节点
Node head, tail;
// 双链表长度
int size;
// 构造方法
public DoubleList() {
head = new Node(-1, -1);
tail = new Node(-1, -1);
head.next = tail;
tail.pre = head;
size = 0;
}
}
综合 MyLinkedHashMap 调用 DoubleList 的情况,需要实现 DoubleList 以下方法
class DoubleList {
// 在链表尾部新增一个元素
public void addLast(Node node) {}
// 从双链表中删除指定元素
public void remove(Node node) {}
// 删除首元素
public void removeFirst() {}
}
下面一一实现这些方法。
addLast 方法
在双链表尾部新增一个元素,要修改四个指针,注意顺序,防止指针丢失,先要修改不容易获得的节点的指针。
// 在链表尾部新增一个元素
public void addLast(Node node) {
node.pre = tail.pre;
node.next = tail;
tail.pre.next = node;
tail.pre = node;
size++;
}
remove 方法
从这个方法可以看出为什么选择双链表而不是单链表,因为需要在 O(1) 时间内删除任意位置的某个节点,删除一个节点需要它的前驱节点,单链表无法实现。
// 从双链表中删除指定元素
public Node remove(Node node) {
node.pre.next = node.next;
node.next.pre = node.pre;
size--;
}
removeFirst 方法
由于调用 removeFirst() 方法的只有 removeEldest() 方法,而 removeEldest() 方法被调用时 cache.size() == cap,而 cap 容量至少为1,因此双链表中是存在元素的,可以不用考虑双链表为空的情况。
// 删除首元素
public Node removeFirst() {
// 考虑双链表为空的情况
if(head.next == tail){
return null;
}
// 双链表不为空
// 获取双链表首元素
Node node = head.next;
remove(node);
return node;
}
因此 DoubleList 的完整代码如下
class DoubleList {
// 虚拟头节点、虚拟尾节点
Node head, tail;
// 双链表长度
int size;
// 构造方法
public DoubleList() {
head = new Node(-1, -1);
tail = new Node(-1, -1);
head.next = tail;
tail.pre = head;
size = 0;
}
// 在链表尾部新增一个元素
public void addLast(Node node) {
node.pre = tail.pre;
node.next = tail;
tail.pre.next = node;
tail.pre = node;
size++;
}
// 从双链表中删除指定元素
public void remove(Node node) {
node.pre.next = node.next;
node.next.pre = node.pre;
size--;
}
// 删除首元素
public Node removeFirst() {
// 考虑双链表为空的情况
if(head.next == tail){
return null;
}
// 双链表不为空
// 获取双链表首元素
Node node = head.next;
remove(node);
return node;
}
}
再补一下双链表的节点类
class Node {
// key, value
int key, value;
// 前驱节点, 后继节点
Node pre, next;
public Node() {}
public Node(int key, int value) {
this.key = key;
this.value = value;
}
}
自己实现的完整代码
最后,LRUcache 的完整代码如下
class LRUCache {
// 缓存容量
int cap;
// 哈希链表
MyLinkedHashMap cache = new MyLinkedHashMap();
public LRUCache(int capacity) {
this.cap = capacity;
}
public int get(int key) {
// 如果不存在这个 key, 返回 -1
if(!cache.containsKey(key)){
return -1;
}
// 存在这个 key
// 将该元素提升为最近使用过的
makeRecently(key);
return cache.get(key);
}
public void put(int key, int value) {
// 已经存在这个 key
if(cache.containsKey(key)){
// 修改 value 值
cache.put(key, value);
// 将该元素提升为最近使用过的
makeRecently(key);
return;
}
// 不存在这个 key
// 如果容量满了
if(cache.size() == cap){
// 删除链表头第一个元素(最不常使用的)
cache.removeEldest();
}
// 插入新元素
cache.put(key, value);
}
// 将该元素提升为最近使用过的
private void makeRecently(int key){
int value = cache.get(key);
// 删除该元素
cache.remove(key);
// 新增该元素
cache.put(key, value);
}
}
class MyLinkedHashMap {
// 哈希表
HashMap<Integer, Node> map = new HashMap<>();
// 双链表
DoubleList doubleList = new DoubleList();
// 获取 key 对应的 value
public int get(int key) {
return map.get(key).value;
}
// 新增一对 key, value 或修改 key 对应的 value
public void put(int key, int value) {
// 已经存在该 key, 修改
if(containsKey(key)) {
map.get(key).value = value;
return;
}
// 不存在该 key, 新增
Node node = new Node(key, value);
doubleList.addLast(node);
map.put(key, node);
}
// 删除 value 对应的元素
public void remove(int key) {
Node node = map.get(key);
doubleList.remove(node);
map.remove(key);
}
// 删除链表首元素(也就是最近不被使用的元素)
public void removeEldest() {
Node node = doubleList.removeFirst();
map.remove(node.key);
}
// 返回是否存在该 key
public boolean containsKey(int key) {
return map.containsKey(key);
}
// 返回当前容量
public int size() {
return map.size();
}
}
class DoubleList {
// 虚拟头节点、虚拟尾节点
Node head, tail;
// 双链表长度
int size;
// 构造方法
public DoubleList() {
head = new Node(-1, -1);
tail = new Node(-1, -1);
head.next = tail;
tail.pre = head;
size = 0;
}
// 在链表尾部新增一个元素
public void addLast(Node node) {
node.pre = tail.pre;
node.next = tail;
tail.pre.next = node;
tail.pre = node;
size++;
}
// 从双链表中删除指定元素
public void remove(Node node) {
node.pre.next = node.next;
node.next.pre = node.pre;
size--;
}
// 删除首元素
public Node removeFirst() {
// 考虑双链表为空的情况
if(head.next == tail){
return null;
}
// 双链表不为空
// 获取双链表首元素
Node node = head.next;
remove(node);
return node;
}
}
class Node {
// key, value
int key, value;
// 前驱节点, 后继节点
Node pre, next;
public Node() {}
public Node(int key, int value) {
this.key = key;
this.value = value;
}
}
总结
通过自己阅读别人的题解,再自己实现了几遍,写出了这篇题解,也是为了帮助自己更好的理解。然而在实现的过程中仍然出了一些bug,可想在面试的时候把上述代码无bug一次写出还是比较困难的。通过自己实现这道题,也理解了东哥所说的“算法就像搭乐高”,比如先用 MyLinkedHashMap 去实现 LRUcache,再去补 MyLinkedHashMap 中的方法实现,而 MyLinkedHashMap 中又用到 DoubleList 中的一些方法,用到了哪些方法再去补,这样对我来说比较容易记忆,以后只要会用自带的 LinkedHashMap 做,就能一步步改成自己实现的了,需要哪个就去造哪个。如果对整个流程用到哪些类都比较清晰,也可以先写 Node 类,再用 Node 类实现 DoubleList,再用DoubleList 类实现 MyLinkedHashMap ,最后用 MyLinkedHashMap 类实现 LRUcache,这不就像搭乐高了吗?
参考资料
LRU 缓存的更多相关文章
- LRU缓存实现(Java)
LRU Cache的LinkedHashMap实现 LRU Cache的链表+HashMap实现 LinkedHashMap的FIFO实现 调用示例 LRU是Least Recently Used 的 ...
- 转: LRU缓存介绍与实现 (Java)
引子: 我们平时总会有一个电话本记录所有朋友的电话,但是,如果有朋友经常联系,那些朋友的电话号码不用翻电话本我们也能记住,但是,如果长时间没有联系了,要再次联系那位朋友的时候,我们又不得不求助电话本, ...
- volley三种基本请求图片的方式与Lru的基本使用:正常的加载+含有Lru缓存的加载+Volley控件networkImageview的使用
首先做出全局的请求队列 package com.qg.lizhanqi.myvolleydemo; import android.app.Application; import com.android ...
- 如何用LinkedHashMap实现LRU缓存算法
阿里巴巴笔试考到了LRU,一激动忘了怎么回事了..准备不充分啊.. 缓存这个东西就是为了提高运行速度的,由于缓存是在寸土寸金的内存里面,不是在硬盘里面,所以容量是很有限的.LRU这个算法就是把最近一次 ...
- 面试挂在了 LRU 缓存算法设计上
好吧,有人可能觉得我标题党了,但我想告诉你们的是,前阵子面试确实挂在了 RLU 缓存算法的设计上了.当时做题的时候,自己想的太多了,感觉设计一个 LRU(Least recently used) 缓存 ...
- Java集合详解5:深入理解LinkedHashMap和LRU缓存
今天我们来深入探索一下LinkedHashMap的底层原理,并且使用linkedhashmap来实现LRU缓存. 摘要: HashMap和双向链表合二为一即是LinkedHashMap.所谓Linke ...
- 04 | 链表(上):如何实现LRU缓存淘汰算法?
今天我们来聊聊“链表(Linked list)”这个数据结构.学习链表有什么用呢?为了回答这个问题,我们先来讨论一个经典的链表应用场景,那就是+LRU+缓存淘汰算法. 缓存是一种提高数据读取性能的技术 ...
- LRU缓存原理
LRU(Least Recently Used) LRU是近期最少使用的算法,它的核心思想是当缓存满时,会优先淘汰那些近期最少使用的缓存对象. 采用LRU算法的缓存有两种:LrhCache和DisL ...
- 链表(上):如何实现LRU缓存淘汰算法?
一.什么是链表 和数组一样,链表也是一种线性表. 从内存结构来看,链表的内存结构是不连续的内存空间,是将一组零散的内存块串联起来,从而进行数据存储的数据结构. 链表中的每一个内存块被称为节点Node. ...
- [Leetcode]146.LRU缓存机制
Leetcode难题,题目为: 运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制.它应该支持以下操作: 获取数据 get 和 写入数据 put . 获取数据 get(key ...
随机推荐
- python创建icon图标
def extension_replace(path,extension): for i in range(1,len(path)): if (path[-i] == '.'): new_path = ...
- Codeforces Round #751 (Div. 2)/CodeForces1602
CodeForces1602 Two Subsequences 解析: 题目大意 给你一个字符串 \(s\).你需要两个非空字符串 \(a\) 和 \(b\) 并且满足下面的条件: 字符串 \(a\) ...
- 【MySQL】04_约束
约束 概述 为了保证数据的完整性,SQL规范以约束的方式对表数据进行额外的条件限制.从以下四个方面考虑: 实体完整性(Entity Integrity) :例如,同一个表中,不能存在两条完全相同无法区 ...
- Linux软件安装方式 - Tarball&RPM&YUM
软件安装 简介 概念详解 # 概念详解 - 开放源码: 程序码, 写给人类看的程序语言, 但机器并不认识, 所以无法执行; - 编译器: 将程序码转译成为机器看的懂得语言, 就类似翻译者的角色; - ...
- 两个行内元素在一起,会出现一定的间距,即使将border、padding、margin都设置为零也无济于事,那么怎么才能去除这些间距呢?
首先这里的div设置为了行内块元素,span本身为行内元素,并且设置了* {padding: 0; margin: 0;},那怎么清除元素之间的空白缝隙呢?? (1)给元素加浮动 <!DOCTY ...
- Linux正则表达式与grep
bash是什么 bash是一个命令处理器,运行在文本窗口中,并能执行用户直接输入的命令 bash还能从文件中读取linxu命令,称之为脚本 bash支持通配符.管道.命令替换.条件判断等逻辑控制语句 ...
- Python基础阶段总结:ATM项目实战
目录 ATM逻辑描述 三层框架简介 1.第一层(src.py) 2.第二层(interface文件夹下内容) 3.第三层(db_hanlder) 启动函数 用户注册功能 用户登录 common中的小功 ...
- PGL图学习之图神经网络GraphSAGE、GIN图采样算法[系列七]
0. PGL图学习之图神经网络GraphSAGE.GIN图采样算法[系列七] 本项目链接:https://aistudio.baidu.com/aistudio/projectdetail/50619 ...
- NLP手札1. 金融信息负面及主体判定方案梳理&代码实现
这个系列会针对NLP比赛,经典问题的解决方案进行梳理并给出代码复现~也算是找个理由把代码从TF搬运到torch.Chapter1是CCF BDC2019的赛题:金融信息负面及主体判定,属于实体关联的情 ...
- ES文件浏览器局域网传输文件分析
软件下载链接 1.前言 我之前从手机上传输到电脑上一些apk进行分析,都是使用es文件浏览器这款软件获取 app,传输方面使用QQ,这样很麻烦,走外网流量暂且不提,总是感觉浪费掉了局域网这个环境.简单 ...