使用selemium被反爬解决方法
使用selenium进行自动化的时候,如csdn登录时可能会遇到检测反爬,从而需要验证
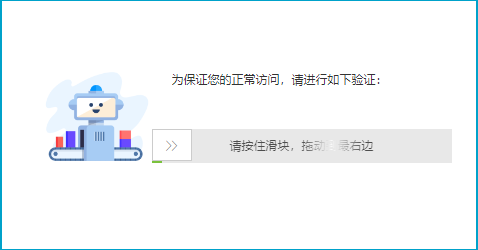

稍微有一点反爬经验的工程师利用上面的差别,很容易判断访问对象是否为一个爬虫,然后对其做反爬处理,返回一堆脏数据或各种验证码。
from selenium.webdriver import Chrome
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
# 打开参数
option.add_experimental_option('excludeSwitches',?['enable-automation'])
driver = Chrome(options=option)
driver.implicitly_wait(10)
driver.get("http://www.google.com")
# 待执行的 JS 代码,修改 window.navigator.webdriver 的值
js_exec = 'Object.defineProperties(navigator,{webdriver:{get:() => false}});'
# 重写 response,截获网络请求,js注入
def response(slef,flow: mitmproxy.http.HTTPFlow):
if 'google' in flow.request.url:
flow.response.text = js_exec + flow.response.text
# 启动mitmproxy
mitmdump -p 8888 -s 111.py
# 配置ChromeOptions
option.add_argument("--proxy-server=http://127.0.0.1:8888")
from selenium.webdriver import Chrome
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
# 打开参数
# option.add_argument("--proxy-server=http://127.0.0.1:8888")
# driver = Chrome(options=option)
driver = Chrome()
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
driver.implicitly_wait(10)
driver.get("http://www.google.com")
使用selemium被反爬解决方法的更多相关文章
- python反爬虫解决方法——模拟浏览器上网
之前第一次练习爬虫的时候看网上的代码有些会设置headers,然后后面的东西我又看不懂,今天终于知道了原来这东西是用来模拟浏览器上网用的,因为有些网站会设置反爬虫机制,所以如果要获取内容的话,需要使用 ...
- Python | 常见的反爬及解决方法,值得收藏
我们都知道Python用来爬数据,为了不让自家的数据被别人随意的爬走,你知道怎么反爬吗?今天播妞带着大家一起见识见识常见的反爬技术. 很多人学习python,不知道从何学起.很多人学习python,掌 ...
- Python3爬取起猫眼电影实时票房信息,解决文字反爬~~~附源代码
上文解决了起点中文网部分数字反爬的信息,详细链接https://www.cnblogs.com/aby321/p/10214123.html 本文研究另一种文字反爬的机制——猫眼电影实时票房反爬 虽然 ...
- k 近邻算法解决字体反爬手段|效果非常好
字体反爬,是一种利用 CSS 特性和浏览器渲染规则实现的反爬虫手段.其高明之处在于,就算借助(Selenium 套件.Puppeteer 和 Splash)等渲染工具也无法拿到真实的文字内容. 这种反 ...
- python干货:5种反扒机制的解决方法
前言 反爬虫是网站为了维护自己的核心安全而采取的抑制爬虫的手段,反爬虫的手段有很多种,一般情况下除了百度等网站,反扒机制会常常更新以外.为了保持网站运行的高效,网站采取的反扒机制并不是太多,今天分享几 ...
- sharepoint2013用场管理员进行文档库的爬网提示"没有权限,拒绝"的解决方法
爬网提示被拒绝,场管理员明明可以打开那个站点的,我初步怀疑是:环回请求(LoopbackRequest)导致的 解决方法就是修改环回问题.修改注册表 具体操作方法: http://www.c-shar ...
- java爬虫爬取的html内容中空格( )变为问号“?”的解决方法
用java编写的爬虫,使用xpath爬取内容后,发现网页源码中的 全部显示为?(问号),但是使用字符串的replace("?", ""),并不能替换,网上找了一 ...
- Python爬虫实战——反爬机制的解决策略【阿里】
这一次呢,让我们来试一下"CSDN热门文章的抓取". 话不多说,让我们直接进入CSND官网. (其实是因为我被阿里的反爬磨到没脾气,不想说话--) 一.URL分析 输入" ...
- Python3爬取起点中文网阅读量信息,解决文字反爬~~~附源代码
起点中文网,在“数字”上设置了文字反爬,使用了自定义的文字文件ttf通过浏览器的“检查”显示的是“□”,但是可以在网页源代码中找到映射后的数字正则爬的是网页源代码,xpath是默认utf-8解析网页数 ...
- Scrapy———反爬蟲的一些基本應對方法
1. IP地址驗證 背景:有些網站會使用IP地址驗證進行反爬蟲處理,檢查客戶端的IP地址,若同一個IP地址頻繁訪問,則會判斷該客戶端是爬蟲程序. 解決方案: 1. 讓Scrapy不斷隨機更換代理服務器 ...
随机推荐
- C# 开源NuGet插件
ExcelDataReader 开源免费,Excel读取插件 GitHub - ExcelDataReader/ExcelDataReader: Lightweight and fast libra ...
- VS不能生成moc_XXX文件的问题解决
环境:VS2010 + QT 4.8 问题:写好QT代码文件(XXX.h和XXX.cpp)后,发现不能像其它QT文件那样自动生成moc_XXX文件. 解决: 1.参考网文,将XXX.h文件的属性配置成 ...
- C语言-Windows定时关机小程序
整理文件发现以前写的定时关机小程序(Windows下) 1-效果 2-程序 #include <stdio.h> #include <stdlib.h> #include &l ...
- SATA硬盘的数据和电源接口定义(转)
现在 SATA设备越来越普及,包括STAT硬盘和光驱基本都已经是 SATA接口的了,以前的老式电源输出接口一般都是20针供主板加上4针的电源供硬盘也就是说以前的电脑电源给硬盘供电没有设计15针 SAT ...
- phaclon 初学者遇到的问题!
1,框架安装 需要安装PHALCON扩展. 2,Nginx伪静态 配置 3,app.ini 常量配置等配置 4,主体目录结构 互相调用及 类的注册服务 依赖注入 自动加载项问题. 5,数据库相关操 ...
- WebService 客户端上传图片,服务器端接收图片并保存到本地
需求:如题,C#本地要调用Webservice接口,上传本地的照片到服务器中: 参考:客户端: https://blog.csdn.net/tiegenZ/article/details/799276 ...
- 2022-3-16内部群每日三题-清辉PMP
1.项目经理正在为客户管理一个跨国项目,拟采用最新技术替换其电信基础设备.项目经理得知,在某些国家,必须遵循特定的环境规定来处置被替换的硬件.在制定商业论证时,未考虑到这些规定,项目经理应该怎么做? ...
- Software--电商平台系统--P1 需求分析
2018-01-11 13:58:43 电商平台 需求 1. 网站的页面展示 页面的布局: Product Catalog (商品目录浏览功能): 首页显示"置顶" 商品: ...
- 047_SOQL 基本查询总结
User currentUser = [SELECT Id, Profile.Name,UserRole.Name FROM User WHERE Id = :UserInfo.getUserId() ...
- HCIA-ICT实战基础10-广域网技术PPP
HCIA-ICT实战基础-广域网技术PPP 目录 早期广域网技术概述 PPP协议原理与配置 1 早期广域网技术概述 1.1 什么是广域网 广域网是连接不同地区局域网的网络, 通常所覆盖的范围从几十公里 ...